'03.HTML 4.X, HTML5, XML...'에 해당되는 글 234건
- 2009.04.04 HTML Codes
- 2009.04.03 location.replace() 와 location.href 의 차이
- 2009.03.31 XML 실전 프로그래밍
- 2009.03.18 jsp, 자바스크립트, 다음부터 이 창을 띄우지 않음
- 2009.03.10 XHTML/CSS를 이용한 구조화 및 개발방법론 2
- 2009.01.30 html 입력모드 : ime-mode 1
- 2009.01.29 div 모든것...
- 2009.01.28 Mysql 자동 백업 하기
- 2009.01.28 스크립트 태그의 CDATA 사용에 대해서
- 2009.01.28 input type="file"에서 찾아보기 버튼 바꾸기
- 2009.01.28 잘못된 Javascript의 사용에 대해서....
- 2009.01.28 팝업 또는 새창에 관한 정리
- 2009.01.28 XHTML 사용에 대한 정리
- 2009.01.28 제발 a href="#" 좀 쓰지 말자.... 1
- 2009.01.28 괜찮은 클라이언트사이드 IDE : aptana Studio 1
- 2009.01.28 외부 Javascript 파일 압축하기
- 2009.01.28 괜찮은 클라이언트사이드 IDE : aptana Studio
- 2009.01.28 script.aculo.us의 Sortable로 드래그앤드롭(DragNDrop) 사용하기
- 2009.01.28 jQuery로 작업하기, 3부: jQuery와 Ajax로 RIA 만들기
- 2009.01.23 도메인이 다른 경우 자바스크립트 연동
- 2009.01.23 cookie 정보 확인 스크립트
- 2009.01.23 xerces를 사용한 dom 방식의 xml parser lib
- 2009.01.23 SUN JAVA STREAMING XML PARSER 소개
- 2009.01.23 //인터넷 XML 날씨 정보를 파싱 (DomParser.java) : dom,parser,java
- 2009.01.23 XML Parser 함수들
- 2009.01.23 Parser 와 DOM 기초
- 2009.01.23 http://xerces.apache.org/xerces2-j/samples.html
- 2009.01.23 Apache parser
- 2009.01.23 xml 파서 jsp 버전
- 2009.01.23 xml 스트링 로드하고 분석하기

1번페이지에서 2번페이지로와서 2번 페이지에서 링크를 클릭했다고 하자 링크는 2개이다.
location.replace("www.naver.com")과
location.href="www.naver.com"
이다.
replace의 경우 네이버에서 뒤로가기를 눌렀을경우 뒤로가는페이지는 1번페이지가 된다.
href의 경우 2번페이지이다.
replace는 히스토리를 덮어버리는 기능을 하는것이다.
history.length를 참조해보자.
---------- 테스트 -------
<a href="#" onclick='document.location.replace("http://www.naver.com");return false;'> replcae</a>
<a href="#" onclick='document.location.href="http://www.naver.com";return false;'> href</a>
위에걸 html 페이지를 생성해서
넣은후 각각 클릭해보자
href는 누른후에 뒤로가기가 활성화돼지만
replace는 활성화가 돼지 않는다.
XML Article
XML Beans : XMLBeans는 스키마 기반으로 XML 인포셋 전체에 커서 기반으로 접근할 수 있도록 하는 XML-Java binding tool이다. BEA Systems에 의해 개발 되었으며 2003년에 아파치 프로젝트에 기증 되었다. 기존의 SAX와 Dom등의 방식으로 XML 코딩을 하다 보니 코드 자체가 길어져 개발 및 유지보수하는데 어려움이 많았다. 이 같은 단점은 보완하기 위한 새로운 방법을 제시하고 있다.
XML 라이브러리
- Xstream : 눈여겨 볼만한 놈.
XML 실전 프로그래밍
- 1장 관계형 데이터를 XML로 만들기 1
- 1장 관계형 데이터를 XML로 만들기 2
- 1장 관계형 데이터를 XML로 만들기 3
- 2장 XSLT 적용 1
- 2장 XSLT 적용 2
- 2장 XSLT 적용 3
- 2장 XSLT 적용 4
- 3장 XSLT 확장을 이용한 게시판 완성
- 4장 관계형 데이터를 XML화하는 다른 방법 1
- 4장 관계형 데이터를 XML화하는 다른 방법 2
- 5장 XSLT 작성시의 문제 해결 방법과 실행 속도 향상 방법
- 6장 XSLT 변환기
- 7장 강좌용 게시판 만들기 1
- 7장 강좌용 게시판 만들기 2
- 8장 강좌를 PDF와 플래시로 만들기
- 9장 쿼리 관리기 생성을 통한 XML 문서 파싱 1
- 9장 쿼리 관리기 생성을 통한 XML 문서 파싱 2
- 10장 웹에서 XML로 쿼리와 메뉴 관리하기 1
- 10장 웹에서 XML로 쿼리와 메뉴 관리하기 2
- 11장 XML을 이용한 쇼핑몰 만들기 1
- 11장 XML을 이용한 쇼핑몰 만들기 2
- 11장 XML을 이용한 쇼핑몰 만들기 3
다음부터 이 창을 띄우지 않음
2001. 4. 9.
개 요
어느 정도 규모가 있는 사이트에서는(심지어는 개인 홈페이지에서도) 중요한 공지사항이 있을 때에는 별도의 작은 창을 띄워서 해당 내용을 표시하는 경우가 많다. 이러한 별도의 창은 처음 접속하는 사용자인 경우에는 필요한 경우가 많지만, 같은 내용을 여러 번 보는 것을 방지하기 위하여 자체적으로 "다음부터 이 창을 띄우지 않음"과 같은 선택 옵션을 제공하는 경우가 많다. 이러한 기능을 구현하기 위하여 CGI와 DB를 사용하는 경우도 있지만, 쿠키와 자바스크립트만을 이용해서도 같은 효과를 거둘 수 있다.
쿠키 다루기
쿠키를 제어하는 함수를 제작하기 전에, 쿠키의 구조부터 살펴보도록 하겠다. 쿠키는 일반적으로 다음과 같은 형태를 가지는 일련의 문자열로 구성되어 있다.
쿠키변수=쿠키값; path=유효한디렉토리; expires=만료일
쿠키를 참조하는 객체는 자바스크립트에서 document.cookie 객체이며, 이를 이용하여 쿠키를 설정하고 값을 참조하는 함수를 다음과 같이 범용적인 용도로 작성할 수 있다.
function setCookie (name, value, expires) {
document.cookie = name + "=" + escape (value) +
"; path=/; expires=" + expires.toGMTString();
}
function getCookie(Name) {
var search = Name + "="
if (document.cookie.length > 0) { // 쿠키가 설정되어 있다면
offset = document.cookie.indexOf(search)
if (offset != -1) { // 쿠키가 존재하면
offset += search.length
// set index of beginning of value
end = document.cookie.indexOf(";", offset)
// 쿠키 값의 마지막 위치 인덱스 번호 설정
if (end == -1)
end = document.cookie.length
return unescape(document.cookie.substring(offset, end))
}
}
}
쿠키로 제어하는 공지창 호출
이제, 특정 쿠키의 값에 따라서 새 창을 열 것인지의 여부를 결정하여 수행하는 함수를 작성해보자. 쿠키변수의 이름은 notice로 하고, 이 notice의 값이 deny이면 공지 창을 띄우지 않는 기능을 가진 openNotice() 함수를 만든다.
function openNotice() {
if (getCookie("notice") != "deny") {
window.open("notice.htm","notice",
"width=320,height=240,resizable=yes");
}
}
위의 함수는 첫 페이지에서 onLoad 이벤트 핸들러에 연결하여 사용할 수 있다. 이제 열리는 대상 창에서 사용자가 앞으로 이 창을 띄우지 않는 것을 선택하는 폼을 구성한다.
<form name="notice"> <input type="checkbox" name="neveropen"> 다음부터 이 창을 열지 않음 <input type="submit" value="확 인" onClick="Setting(document.notice)"> </form>
Setting() 함수의 용도는 쿠키변수인 notice에 deny라는 값을 대입시켜서 쿠키를 설정하는 기능이며, 쿠키가 설정된 다음에는 해당 창을 닫는다.
function Setting(form) {
var expdate = new Date();
expdate.setTime(expdate.getTime() + 1000 * 3600 * 24 * 365); // 365일
if (form.neveropen.checked) {
setCookie('notice', "deny", expdate);
}
window.close();
}
만료일의 경우에는 현재 시각을 기준으로 하여 1년 이후까지를 유효일로 설정하였다. 이 수치를 조정하여 공지사항을 띄우지 않을 기간을 마음대로 조정할 수 있다. 또한, 새로운 공지사항인 경우에는 deny가 아닌 새로운 값이나 새로운 쿠키 변수명을 사용하여 활용할 수도 있으므로, 실제로 이 코드를 참조하여 적용할 때에는 쿠키변수명과 쿠키의 값을 용도에 맞게 변경해서 사용해야 할 것이다.
최종 소스파일
지금까지 설명한 메인화면 코드와 공지창 코드 전체를 정리하면 다음과 같다.
메인 화면
<html>
<head>
<title>쿠키를 이용한 새창 제어</title>
<script language="javascript">
function getCookie(Name) {
var search = Name + "="
if (document.cookie.length > 0) { // 쿠키가 설정되어 있다면
offset = document.cookie.indexOf(search)
if (offset != -1) { // 쿠키가 존재하면
offset += search.length
// set index of beginning of value
end = document.cookie.indexOf(";", offset)
// 쿠키 값의 마지막 위치 인덱스 번호 설정
if (end == -1)
end = document.cookie.length
return unescape(document.cookie.substring(offset, end))
}
}
}
function openNotice() {
if (getCookie("notice") != "deny") {
window.open("notice.htm","notice",
"width=320,height=240,resizable=yes");
}
}
</script>
</head>
<body onLoad="openNotice()">
<h1>쿠키를 이용한 새창 제어</h1>
</body>
</html>
공지사항 화면
<html>
<head>
<title>공지사항</title>
<script language="JavaScript">
function setCookie (name, value, expires) {
document.cookie = name + "=" + escape (value) +
"; path=/; expires=" + expires.toGMTString();
}
function Setting(form) {
var expdate = new Date();
expdate.setTime(expdate.getTime() + 1000 * 3600 * 24 * 365); // 365일
if (form.neveropen.checked) {
setCookie('notice', "deny", expdate);
}
window.close();
}
</script>
</head>
<body>
<h1>공지사항</h1>
<form name="notice">
<input type="checkbox" name="neveropen">
다음부터 이 창을 열지 않음
<input type="submit" value="확 인" onClick="Setting(document.notice)">
</form>
</body>
</html>
XHTML/CSS를 이용한 구조화 및
개발방법론
이성노 (eouia0819@gmail.com)
1. 들어가며
이 강연은 청중들이 XHTML 및 CSS에 대 한 기본적인 선행학습이 된 상태임을 전제로 진행된다.
접근성, 웹표준화, CSS 기법 등은 다른 시간에 다루게 될 것이므로 이 시간은 실제 XHTML과 CSS를 이용한 웹사이트 개발을 위한 개발 방법론에 중점을 둘 예정이다.
2. 구조화
CSS를 이용한 디자인의 장점은 다음과 같다.
* 간결하고 읽고 이해하기 쉬운 코드의 생성
* 수정, 유지보수의 용이
* 디자인과 분리된 개발 가능
* 트래픽 절감효과
* 크로스 브라우저/크로스 플랫폼
* 접근성 확보
* 기타 (스킨시스템 구축 용이,
DHTML 기법 사용 용이, JavaScript와의 궁합,
빠른 개발-agile방법론 가능 등.. 기타등등..)
그러나 이러한 CSS의 장점은 엄밀히 말하자면 구조화된 XHTML의 장점이라고 말할 수도 있다. CSS에 대해 피상적으로 이해하고 처음 입문하는 사람들이 흔히 범하는 오류가, CSS에 대해서만 알면, 위와 같은 장점들을 맘껏 누릴 수 있다고 착각하는 점이다. 이것은 매우 흔히 일어나는 일이며 상당히 우려스러운 점으로써, 구조화된 XHTML(혹은 HTML)에 대한 이해가 없을 경우, 오히려 어렵거나 불필요한 CSS 기법을 사용함으로써 위에서 예로 들은 여러가지 장점을 십분 발휘할 수 없게 된다.
따라서, “ quirk모드에서 IE의 box모델 오류를 해결하기 위한 CSS hack ” 같은 실질적인 기법들보다 (이런 것은 검색해보면 다 알 수 있다.) 먼저 구조화된 XHTML 작 성방법에 대해 충분히 익혀둘 필요가 있다.
“ 구조화 ” 란 용어는 임의로 붙인 용어이며, 보다 널리 알려진 표현은 “ well-formed document ” 라고 할 수 있다.
“ well-f ormed document ” 의 필수조건은 다음과 같다.
-
의미론적이며 용도에 맞는 태그를 사용한다.
-
문서의 물리적/논리적 구조가 체계적이다.
2-1. XHTML의 태그 사용법
XHTML은 HTML과 크게 다르지 않지만, HTML의 XML버전이므로 XML의 규격에 준하여 몇 가지 주의 사항이 있다.
-
모든 태그들은 반드시 완벽하게 중첩되어야 한다.
<b><i>틀린 경우</b></i>
<b><i>맞는 경우</i></b>
-
모든 태그와 속성 예약어/지시어에는 소문자를 사용한다.
<A HREF= ” http://sample.com ” >틀린 경우</A>
<a href= ” http://sample.com ” >맞는 경우</a>
-
E mpty tag들도 반드시 “ 닫겨야 ” 한다.
<img src= ” http://sample.com/wrong.jpg ” >
<img src= ” http://sample.com/right.jpg ” />
-
속성값은 반드시 겹따옴표( “ )를 사용해야한다.
<div class= ’ wrong ’ >틀린 경우</div>
<div class=wrong>틀린 경우</div>
<div class= ” right ” >맞는 경우</div>
-
단축형 속성값을 사용할 수 없다.
<option value= ” wrong ” selected>틀린 경우</option>
<option value= ” right ” selected= ” selected ” >맞는 경우</option>
-
name대신 id속성을 사용한다.
<input type= ” text ” name= ” field1 ” value= ” 틀린 경우 ” />
<input type = ” text ” id= ” field1 ” value= ” 맞지만 문제있음 ” />
<input type= ” text ” id= ” field1 ” name= ” field1 ” value= ” 유효한 대안 ” />
-
lang 속성을 사용한다.
<div lang="no" xml:lang="no">Heia Norge!</div>
-
Doctype을 명시한다.
Strict :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http:// www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
Transitional :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Frameset :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
이 밖에 XHTML이 HTML과 다른 점으로 다음 사항들도 주의해야한다.
-
presentational tag들을 사용하지 않는다.
<basefont>, <center>, <font>, <s>, <strike>, <u>
-
폐기된 tag들을 사용하지 않는다.
<applet>, <dir>, <isindex>, <menu>, <xmp>
-
DTD에 맞는 tag를 사용한다.
<frame>, <frameset>, <iframe>
이러한 부분들은 명확히 스펙에 명시되어 있으므로 조금만 숙달되면 준수하기 쉽다 . 그러나 이렇게 문법 만 지키는 코딩이 XHTML문서의 충분조건은 아니 다. 이러한 하드코딩 문법규칙이 숙달되었다면, 의미론적인 태깅을 익혀야한다. 이 과정은 딱히 정해진 가이드라인이 존재한다기보다는, 개인의 역량과 이해도에 따라 달라지므로, 여기에서는 가장 기본적인 부분들만 짚도록 한다.
-
잘못 사용하고 있는 태그들
<br>은 문단 구분을 위한 태그가 아니다. (<p>를 사용)
<quote>는 들여쓰기/박스처리를 위한 태그가 아니다.
<table>은 웹페이지 레이아웃을 잡는데 사용하는 태그가 아니다.
<b>는 “ 중요한 어휘 ” 를 표현하는데 사용하는 태그가 아니다.
<h1>은 “ 굵은 글씨 ” 를 표현하는데 사용하는 태그가 아니다.
기타등등 잘못 사용되고 있는 태그들이 많다.
-
의미와 목적에 맞는 태그
“ 중요한 어휘 ” 를 표현하고 싶다면 <strong>또는 <em>을 사용하고 , 중요도와는 상관없는 “ 굵은 글씨 ” 를 표현하고 싶다면 <b>를 사용한다. 이 차이는 무엇인가?
가장 기본적인 질문이지만, 이것이 “ 구조화된 XHTML ” 을 이해하는 가장 근본적인 질문이다.
예를 들어 “ 텍스트 배너광고 ” 안에 표시된 어떠한 문자열(예를 들어 “ 가습기 총출동! ” 같은)이 “ 굵은 글씨 ” 로 표현되어 있다고 가정하자. 이것이 이 페이지 내에서 어떠한 중요도를 가지는가?

만약 중요하지 않다면 <b>로 표현하는 것이 맞다. 그러나 이 문자열이 중요한 어휘라면, <strong>이나 <em>을 사용하도록 한다. 이것이 중요한지, 중요하지 않은지를 판단하는 것은 차후 설명할 개발방법론의 기획/분석 단계에서 이루어져야 하며, 이 판단을 올바르게 할 수 있어야 진정한 XHTML 구조화 역량을 갖출 수 있다. 실제로, 위의 이미지 같은 경우라면, <b>를 사용하는 것마저도 아깝다(?). 더 좋은 방법은 적당한 class를 부여한 후, CSS에서 font-weight:bold;를 사용하는 것이다. <b>는 문자그대로 “ 굵은글씨 ” 를 표현하는 것이지만, 위의 예에서는 “ 굵은글씨 ” 로 “ 표현해야만 ” 하는 당위성마저도 없기 때문이다.
Q. <em>을 사용했더니 기울어진 글씨체로 나와요. 그냥 <b>로 쓸래요.
A. <em>을 사용하고, 대신 표현은 CSS를 사용하세요. 그것이 올바른 XHTML/CSS 사용법입니다.
이러한 판단은 지금까지 낡은 방식의 HTML 코딩 스타일에 익숙해져있던 사람들에게는 거의 모든 부분에서 걸림돌이 될 것이다.
게시판의 게시물 리스트는 “ 순서가 없는 리스트(<ul><li>) ” 인가, “ 순서가 있는 리스트(<ol><li>) ” 인가, 아니면 “ 표의 일부분(<table><tr><td>) ” 인가, 이도저도 아닌 “ 독립된 여러 줄들의 모임(<p>또는<br>) ” 인가?
이미지를 이용한 테두리나 박스는 “ 컨텐트 (<img>) ” 인가, 아니면 의미없는 “ 단순한 장식요소(CSS::backgrund-image) ” 인가?
입력 폼에서 사용된 “ 비밀번호 ” 는 “ 문자열 ” 인가, “ 테이블의 한 셀의 내부텍스트 ” 인가, “ form control의 label ” 인가?

소소한 예 몇가지만으로도 충분히 머리아플 것이다. 더 골치아픈 것은, 이러한 문제에 정답 혹은 모범답안은 없다는 점이다. 처음 예에서 “ 가습기 총출동! ” 이 “ 중요한 어휘 ” 인지, “ 그저 굵은 글씨 ” 인지는 문서 전체를 놓고 파악해야만 알 수 있다. 심지어 어떤 문서에서는 저 문자열이 “ 소제목 ” 일 수도 있다. 이런 경우에는 이것, 저런 경우에는 저것.이라고 딱 떨어지는 답이 없고 문서 전체의 문맥과 목적에 따라 그때그때 맞는 태깅을 해야한다는 점이다.
너무 막연하게 들릴 수 있으므로 몇가지 일반적인 가이드라인을 제시해본다.
-
아주 특별한 경우를 제외하고, 모든 문서에는 “ 제목 ” 이 존재한다. 제목에는 <h1>태그를 사용한다.
-
아주 특별한 경우를 제외하고, 모든 문서는 한 페이지 안에서 좀더 작은 단위의 컨텐트 들로 분할될 수 있다. 이렇게 분할된 컨텐트 들은 의미상 “ chapter ” 라고 부를 수 있으며, 따라서 <h2>~<h6>까지의 태그를 사용하여 “ chapter단계별 소제목 ” 을 붙일 수 있다. (chapter대신 content block, content region.. 어떤 용어를 쓰던간에. 이해가 쉽다면 자신만의 용어를 만들어 붙여도 좋다.)
-
어떤 “ 컨텐트(들) ” 의 “ 범위/영역 ” 을 분리할 수 있다면 이를 둘러싸기 위해 <div>를 사용할 수 있다. 이것은 시각적 디자인과는 아무 관계없으며, 임의로 어떠한 컨텐트(들)과 다른 컨텐트(들)을 의미적으로 분리할 필요가 있을 때(그리고 분리 가능할 때) 사용한다.
-
이미지가 “ 컨텐트 ” 일 경우에만 <img>태그를 사용한다. 장식적인 요소일 경우에는 CSS의 background-image로 돌린다.
어떤 이미지가 “ 컨텐트 ” 인지 아닌지 알아보는 가장 쉬운 방법은, 해당 이미지가 삭제되어도 정보전달 및 이용에 영향이 있는지 없는지를 살펴보는 것이다. 대체로 다음과 같은 것들은 “ 컨텐트인 이미지 ” 일 가능성이 높다. .
신문기사의 사진 / 프로필에 포함된 개인사진 / 링크가 걸린 이미지 배너 / 이미지로 표현된 도표, 수식 등 / 의미를 전달하는 그림문자, 심볼 / 이미지 자체가 목적인 것들(갤러리 등)
대체로 다음과 같은 것들은 “ 컨텐트인 이미지 ” 가 아닐 가능성이 높다.
박스테두리 / 배경패턴 / 장식이미지 / 뷸릿 이미지 / 버튼(예외있음) / 정보와는 상관없는 장식성 심볼 등 / spacer 이미지
버튼과 이미지링크는 헷갈리기 쉽다. 간단히 구별하는 방법은, 이미지링크는 URL을 이용한 GET방식을 통해 값을 전달한다. 버튼은 form의 일부분으로써, form을 컨트롤할 때 쓴다. 다음은 상당히 안 좋은 코딩 예이다.
<form id= ” formA ” method= ” post ” >
…
<im g src= ” img/button1.jpg ” onclick= ” doSubmit(); ” />
</form>
javascript 의존적인 코드를 만들었으므로 좋지 않고, form의 제어를 버튼이 아닌 이미지링크로 하려한다. (DOM을 무시하는 스크립트 코드는 말할 것도 없다.)
다음과 같은 코드를 권장한다.
<form id= ” formA ” method= ” post ” action= ” logic.asp ” >
…
<input type= ” submit ” class= ” img_button1 ” value= ” ok ” />
또는
<input type= ” image ” src= ” img/button1.jpg ” alt= ” ok ” />
</form>
javascript binding을 통해 별도로 javascript와 tag를 묶어주고, 되도록이면 body내의 소스에서는 javascript 사용을 자제한다. 아주 특별한 경우를 제외하고는 body내에 javascript가 사용될 필요는 없다.
-
비슷한 성격의 아이템이 반복되어 나열되거나 나열될 가능성이 있는 경우 리스트를 사용한다. 이때, 순서가 중요하다면 <ol>을, 순서가 중요하지 않다면 <ul>을 사용한다. 대체로 다음과 같은 것들을 리스트로 표현한다.
메뉴 (일단 혹은 다단 메뉴) / 무언가의 “ 목록 ”
“ 게시물 목록 ” 은 약간 애매하다. 예를 들어 “ 인덱스 페이지에서 보이는 XX게시판의 최근 등록글 X개의 모음 ” 같은 경우 “ 리스트 ” 로 표현하는 것이 적당하다. 그러나, “ 게시판 목록 페이지에서 보이는 게시물 목록 ” 의 경우 , “ 리스트 ” 로 볼 수도 있지만, “ 표 ” 라고 해석할 수도 있다. 왜냐하면, 대개의 경우 “ 목록 ” 은 “ 제목/작성자/조회수 ” 따위의 “ 헤더 ” 를 포함하고, 그밖의 네비게이션링크, form버튼 들을 포함한 하나의 컨텐트 단위라고 볼 수 있기 때문이다. 따라서 <li>로 표현하는 것은 부적절할 수도 있다. 이 역시 그때그때 다른 것이므로, 문서 전체에서 해당 부분의 성격에 따라 결정해야할 문제이다.
-
무조건 <table>을 배척할 필요는 없다. 표현하고자 하는 것이 “ 표 ” 인지 아닌지만 판단할 수 있으면 된다.

이런 것은 “ 표 ” 다. 공연히 <table>을 자제한다고 이런 것마저 <div>로 어떻게 해보려고 하지 말자. J
어떤 것이 “ 표 ” 인가? 대개의 경우, “ 헤더 ” 가 존재하면 “ 표 ” 다. 게시판을 예로 든다면 “ 번호/제목/작성자/작성일/조회수/추천수 ” 가 “ 표 ” 의 column header가 될 것이고,
“ 게시물번호 ” 가 “ 표 ” 의 row header가 될 것이다. H eader는 생략될 수도 있다. 그러므로 그러한 점도 감안해야 한다. 위의 일기예보 표에서 column header는 생략되어있다.(아마도 “ 항목 / 내용 ” 일 것이다. 중첩된 “ 표 ” 로 표시할 경우, “ 3일예보/주간예보 ” 가 가장 상위 테이블의 column header일테고, row header는 역시 생략되었다고 해석할 수 있다. )
-
그 결과 태그 사용량의 변화
이렇게 의미와 용도에 맞게 태그를 사용하게 되면, 사용되는 태그 의 빈도가 이전 방식과 크게 달라지게 된다 .
<div> 가장 많이 사용될 태그 중 한가지로, 컨텐트들의 그루핑, 분리를 위해 사용된다.
<span> inline(줄바꿈 하 지 않은, 최소의 컨텐트 단위) 영역에서 컨텐트의 “ 성격 ” 을 부여하므로 많이 쓰인다. 이전에 <font>, <b>, <u>등등의 자리를 대체하게 될 것이다.
<li> 생각보다 “ 목록 ” 이 컨텐트의 많은 부분을 차지한다는 것을 깨닫게 될 것이다.
<h1>~<h6> 하나의 문서에서 6depth보다 더 잘게 분류된 컨텐트에는 제목이 필요할 가능성이 적다.
<img> 그동안 생각보다 “ 불필요한 img태그 ” 가 많았음을 깨닫게 될 것이다.
<table> 확실히 테이블의 개수가 준다. 하나도 없을 수도 있다. 당연히 table안에 table.. 같은 것도 없다. 코드를 알아보기 쉬우므로 개발자들은 기뻐한다.
-
class와 id의 사용
의미론적인 태깅을 했다면, 이제 CSS를 이용해 디자인을 표현할 수 있도록 해주어야 한다. 기껏 의미론적인 태깅을 했어도 다음과 같은 식이면 곤란하다.
<div style= ” color:#FF0000;bord er-bottom:2px solid #EFEFEF;background-image: … >
<img border= ” 1 ” border-color= ” red ” onmouseover= ” showBorder() ” … >
이 경우 다음처럼 “ 의미 ” 를 부여한다.
<div class= ” article_box ” >
<img id= ” site_logo ” />
class와 id의 용법에 대해서는 XHTML/CSS의 기본이므로 이 자리에서 따로 설명하지는 않는다. 바람직한 class/id의 selector naming에 대한 가이드라인은 이어지는 개발방법론 시간에 다루도록 한다.
2-2. 문서의 구조화 를 시작하기 전에
의미와 용도에 맞는 태깅이 숙달되면 이제 시야를 넓혀 문서 자체의 구조화를 생각해야 할 시간이다. 사실상, 문서의 구조화 자체는 위에 설명한 가이드라인을 제대로 준수했다면 거의 완성된 셈이다. 다만 미시적 관점에서는 간과하는 부분이 있을 수 있으므로 같은 목적을 거시적 관점에서 생각해보자.
일반적인 웹 문서는 어떻게 생겼는가? 시간 관계상 거두절미하고 모범적인(?) XHTML 문서의 일례를 살펴보도록 하자.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<!-- Meta Tags -->
<meta http-equiv="content-t ype" content="application/xhtml+xml; charset=utf-8" />
<meta name="robots" content="index, follow" />
<meta name="description" content="" />
<meta name="keywords" content="" />
<meta name="author" content="" />
<!-- Favicon -->
<link rel="shortcut icon" href="" />
<!-- CSS -->
<link rel="stylesheet" href="" media="screen,projection" type="text/css" />
<link rel="stylesheet" href="" media="print" type="text/css" />
<!-- RSS -->
<link rel="alternate" href="" title="RSS Feed" type="application/rss+xml" />
<!-- JavaScript : Include and embedded version -->
<script src="" type="text/javascript"></script>
<title> 문서의 타이틀 </title>
</head>
<body>
<div id="container">
<div id="navigation">
</div><!-- navigation -->
<div id="primaryContent">
</div><!-- primaryContent -- >
<div id="secondaryContent">
</div><!-- secondaryContent -->
<div id="footer">
</div><!-- footer -->
</div><!-- container -->
</body>
</html>
<body> 안쪽은 문서의 구조화에 따라 달라지므로 신경쓰지 말자. 여기에서는 전형적인 구조화된 XHTML문서의 형태를 보도록 한다.
흔히들 <head>안쪽을 무성의하게 작성하는데, 본문만큼이나 중요하다. 절대로, 그냥 한번 만들어두고 다른 파일들에서 기계적으로 include해서 사용하지 않도록 하자. 모든 페이지마다 <head>는 각각의 페이지에 맞게 적절히 구성되어야 한다.
되도록이면 CSS는 외부파일로 만들어두고 link해서 사용하는 것이 좋다. 필요하다면 @media같은 CSS 고급활용기법을 쓰는 것도 좋다. 가장 안 좋은 것은 <body>내의 태그에서 inline스타일로 사용하는 것이며(유연한 디자인을 불가능하게 한다.), <style>~</style>을 사용하는 것도 사이트 통일성을 유지하는 데 걸림돌이 된다.
<script>는 가능한 한 <head>안에 위치하게 한다. 이는 자바스크립트를 해석할 수 없는 기계들을 위한 배려이다.
잠깐 다른 주제로 빠져서, 절대로 스크립트 의존적인 기능에만 의지하지 말아야 한다. 예를 들어 “ 주민등록번호 확인 ” 같은 경우, javascript상에서만 체크하고 form을 submit하는 경우 javascript를 사용하지 않거나 막아둔 브라우저등에서 이용시 해당 기능을 무력화시킬 수 있다. 이러한 경우를 위해 서버사이드에서도 유효값체크를 해주어야만 한다.
비슷한 의미로, 스크립트를 사용할 때에는 스크립트를 사용할 수 없는 경우를 위한 동등한 기능이나 정보를 fallback해주어야 한다. (<noscript> 참고)
<title>의 경우 캐릭터셋의 영향을 받을 수 있으므로, 메타태그들이 끝난 후 선언해준다.
<head>에 쓰이는 메타태그들은 위에 표시된 내용 외에도 더 있으므로, 문서의 목적과 필요에 따라 적절히 사용해준다.
본격적인 <body>내에서의 구조화는 새로운 웹개발방법론과 밀접한 연관이 있으므로 이에 대해 먼저 설명 후 다시 살펴보도록 한다.
3. 표준화를 위한 새로운 웹 개발 방법론실제 현장에서 웹표준화/접근성/XHTML/CSS(모두 같은 이야기라고 할 수 있다.)를 적용하는 데에는 초기에 많은 어려움이 있었다. 원인을 살펴보니, 개념 및 이해부족도 큰 문제였으며 그와 더불어 개발 공정 자체에 구조적인 문제가 있었다.
1) 기존방식의 문제점

화살표대로 순차 진행되며, 어느 한 단계에서 지연될 경우 병목현상이 발생하게 된다. 무엇보다도, 디자인까지 나온 후에야 코딩이 이루어지므로 인력의 효율적 관리가 어렵고, 구조화된 문서, CSS적용이 힘들다.
이렇게 된 이유는 크게
a) 과도한 스토리보드
b) 디자이너의 역량부족
을 들 수 있겠다.
스토리보드라는 것은 “ 계륵 ” 같은 존재이다. 상세하면 상세한 대로, 부실하면 부실한 대로 짐이 된다.
애초에 스토리보드란, use-case scenario의 한 표현방법 일 뿐이다. 동선의 흐름(스토리)을 기술하는 일종의 모델링 방법이다. 그런데 언제부터인가, 웹 개발의 필수 문서가 되어버렸다. 디자이너는 스토리보드가 없으면 페이지 한 장 그려낼 수 조차 없다. 개발자도 스토리보드가 없으면 비즈니스로직을 만들 수 없다.
게다가 스토리보드는 상당히 “ 품 ” 이 많이 드는 작업이다. 그나마 쓸만한 스토리보드가 되기 위해서는 디자인 레이아웃 부터 사용자 액션에 이르기까지 모든 것을 전부 기술해야 한다. 좀 더 친절하려면 DB/프로그램설계에 도움이 될 수 있도록 내/외부에서 사용될 각종 “ 값 ” 들에 대한 정의도 포함되어야 한다. 가능한 일일까? 본인은 완벽한 스토리보드를 구경해본 적도, 만들어 본 적도 없다.( 시도는 했었으나 배보다 배꼽이 더 큰 작업이었고, 스토리보드의 구조적 한계를 깨달은 계기였다.)


전형적인 스토리보드의 예 - 좀더 친절한(?) 기획자라면 각 영역의 사이즈, 색상, 사용되는 이미지에 대한 묘사, UI 전반에 대한 지시, 프로그래밍 지시사항 등을 꼼꼼하게 서술할 것이다.
아울러, 불성실한(?) 디자이너, 개발자라면 “ 스토리보드에는 그런 내용 없었는데요? ” 라는 발언을 달고 살 터이고, 자존심 센(?) 기획자라면 그런 발언이 안나오도록 스토리보드를 아주 상세히 작성할 것이다. 결국, 스토리보드가 완성될 사이트의 실연동영상 스틸컷 모음 수준이 되어야 완벽하다(?)는 평가를 받게 된다.
스토리보드가 세세하면 세세할수록 작성에 들어가는 시간이 늘어나며, 세세하면 세세할수록 디자이너와 개발자는 스토리보드에 의존할 수 밖에 없으니 스토리보드가 완성되기 전까지는 하고 싶어도 별로 할 일이 없다. (물론.. 아마도 인력관리라는 명목으로 다른 프로젝트 작업을 열심히 하고 있겠지만.)
문제는, 여러 개의 문서로 나뉘어져야 할 것을 하나의 스토리보드로 해결하려는 성향 및 기획자 절대 주의이다.

개발자에게는 구구절절한 스토리보드보다 이런 깔끔한 비즈니스로직 프로세스 플로우 한 장이 더 필요하다. (물론, “ 스토리보드 ” 를 보고 이러한 프로세스 플로우를 쳐내는 것이 skilled 개발자의 조건일 수도 있다. 그러나 애초에 이정도 기본적인 프로세스는 기획자가 작업하는 것이 더 효율적이다. 기획자의 머리에서 시나리오가 만들어지 므로.)
디자이너 입장에서 보면 웹디자인이란 “ 파워포인트로 된 ‘ 그림 ’ 을 포토샵으로 옮긴 후, 드림위버에서 최종저장하는 것 ” 이나 다름없다.
천기누설을 하자면 이렇다. 기획자들은 디자이너들을 믿지 않는다. 그래서 일일이 위치나 크기나 색상이나 컨셉이나 … 지정해주지 않으면 제대로 된 디자인이 안나온다고 믿는다. “ 스토리보드대로의 디자인 ” 이 아니면 분명히 귀찮게 굴 것이다. 왜냐하면, 기획자가 가장 “ 사용자의 의도/접근/동선/행동 ” 을 잘 알고 있다고 믿기 때문이다. UI 전문 기획자라면 모를까, 어불성설이다. User Interface는 디자이너가 가장 잘 안다.
그러나, 현실적으로, 가장 잘 알아야 함에도 불구하고 현업 디자이너들은 솔직히 잘 모른다. “ 디자이너 ” 일지언정 “ 웹디자이너 ” 는 아니기 때문이다. 별로 알고 싶어하는 것 같지도 않아보인다.
“ 예뻐보여서 로그인 박스를 여기에 두었어요. ” <- 이런 설명은 하나마나.
“ 이 페이지에 접속하면 사용자의 시선이 제일 처음 머무는 곳은 XX이며, 그에 따라 시선은 이러한 방향을 따라 흐르게 됩니다. 컨텐트는 컨셉과 무게에 따라 이러이러하게 배분되어 있으므로 마우스의 동선은 이러저러한 단계를 거치게 됩니다. 따라서 로그인 박스는 이 곳에 위치하는 것이 사용자 편의를 위해 바람직합니다. ” <- 예쁘기까지하니 금상첨화.
반드시 이러한 잘난척하는 이론을 늘어놓으란 소리는 아니다. 적어도 웹디자이너라면 이론적인 뒷받침이 있든 없든 간에 이러한 요소가 고려된 디자인을 만들어낼 수 있어야 한다는 뜻이다. 그렇지 못한다면 5년차, 7년차등의 년차수는 의미없는 일이다. (더불어 포토샵 단축키와 타블렛으로 캐릭터그리기 스킬들도.)
너무 이상적인 디자이너상인지도 모르겠다. 게다가 웹 UI란 단지 포토샵 작업물 이상의 것 (구조화된 문서/DHTML/기타등등) 이기 때문에 디자이너에게 너무 과중한 짐을 지우는 것일 수도 있다. 개인적인 소견으로는, 디자이너가 정말 “ 뛰어난 디자인 ” 만 산출해낸다면 다른 모든 짐은 덜어줘도 괜찮다고 본다.
2) 새 방법론 제안
그래서 새로운 방법론이 필요한 시점이다.

앞의 도표에 비하면 상당히 복잡해보인다. 실제로는 가장 굵은 화살표만 따라보면 된다. 차례대로 따져보자.
* 분석/기획은 공동작업
물론, 이전에도 기획회의는 해왔다. 다른 점이 있다면, 이전에는 회의 후 결과물은 기획자가 알아서 스토리보드로 녹여내는 것이라는 암묵적 동의가 있었다면, 새로운 방법론에서는 각자 해야할 일들이 생겼다.
우선 디자이너는 기획회의 결과 “ UI 스타일 가이드라인 ” 을 산출해야한다. (위 표의 “ 컨셉 가이드라인 ” 은 오타입니다. -_-a) 어렵게 들리지만, 구식으로 표현하자면 “ 시안작업 ” 이다. 그런데 “ 시안 ” 이란 무엇인가? 클라이언트에게 보여줄 사지선다용 샘플 이미지 몇장?
“ UI 스타일 가이드라인 ” 이란 말 그대로 “ UI 디자인을 위한 스타일 및 그에 대한 가이드라인 ” 이다. 여기에 들어갈 내용은 전체적인 레이아웃구조, 사이즈, 사용될 색상들, 텍스트 스타일, 링크 스타일, 박스 스타일, 버튼 스타일 등등을 미리 정의해 둔다. 나중에 실제 페이지 디자인 시에는 이렇게 미리 정의된 요소들을 조합/응용하기만 하면 자동으로 한 페이지가 완성될 수 있도록. 이 정의가 잘되어있다면 굳이 디자이너가 아니더라도, 이 요소들을 조합하기만 하면 별도의 디자인작업 없이도 디자인이 적용된 페이지를 만들 수 있다는 뜻이다.
눈치 빠른 이들은 감잡았겠지만, 이 스타일 가이드라인이라는 물건이 바로 CSS다. (물론 CSS로 바로 작성해버리면 나중에 알아보기가 어려우니까 쉽게 볼 수 있는 문서형식으로 작성하는 것이 좋다.) 스타일 가이드라인만 잘 작성해도 전체 CSS 작업의 절반 이상이 완료되는 셈이다.
기획자와 개발자는 기획회의 결과 프로세스 플로우를 먼저 뽑아낸다. 공동작업이래도 좋고, 어느 한쪽이 맡아해도 좋다. 그러나 대개의 경우 기획자 쪽이 좀더 용이할 것이다. 아무래도 전체적인 흐름을 잡고 있을 테니.
역시 형식은 다양하겠지만 개인적으로는 UML내지 그 에 준하는 방법들을 추천한다. 잘 설계된 UML문서는 그 자체로 프로그램 코드를 대체할 수도 있다. 회의하는 동안 노트북 가져다 놓고 UML케이스툴로 슥슥 회의과정을 정리해놓으면 그자리에서 바로 프로그램 코드를 산출해주기도 한다. 개발자의 할 일이 반으로 준다.
물론 그 정도는 아니더래도, 프로세스 플로우가 먼저 나오면, 팀 내/외부 인원들이 사이트의 흐름을 파악하기 쉽다. 또 개발자는 이를 바탕으로 비즈니스 로직을 분석해내거나, 프레임워크 에 적용 하거나, MVC모델 을 적용하는데 큰 도움이 된다. 즉, HTML코드가 직접 필요한 “ 뷰 ” 영역을 제외한 로직 모델링 작업을 먼저 마칠 수 있게 된다. (구조적 개발 스킬이 없는 저급개발자에게는 그림의 떡일수도..)
* 기획자
UML이니 하는 것들, 기획자들도 계속 공부해야 한다는 소리다.
대신 스토리보드는 만들어도, 안만들어도 상관없다. 어차피 스타일가이드가 나오므로 굳이 모든 페이지에 시시콜콜 디자인 간섭할 이유도 없고, 프로세스 플로우에 “ 뷰 ” 페이지 및 “ 로직 ” 프로세스에 대한 선언도 되어있다. 필요한 것은 이렇게 선언된 각 “ 뷰 ” 페이지마다 출력되어야할 컨텐트들만 상세화하면 된다.
예컨데, “ 이 페이지에는 이러저러한 메뉴가 있고, 이러저러한 내용 들이 보여야 하며 이러저러한 기능들이 있어야 한다 . ” 라는 것만 명확히 기술해주면 충분하다.
* 구조화
“ 이 페이지에는 이러저러한 메뉴가 있고, 이러저러한 내용들이 보여야 하며, 이러저러한 기능들이 있어야 한다. ” 라는 컨텐트 명세서가 있다면, 이것을 깔끔하게 정리하는 과정이 구조화라 할 수 있다. 애초에, 컨텐트 명세서를 작성할 때 구조화시켜 작성한다면 별도의 구조화 과정마저도 필요없다.
실제로 컨텐트 명세와 이에 따른 구조화를 연습해보자.
페이지 명세서
페이지 이름 : 영화 정보 서비스 공통 구성요소
설명 :
영화 정보 서비스의 모든 페이지에 대해 다음 요소들을 공통으로 포함한다.
-
사이트 메뉴 (메일/카페/플래닛/블로그/쇼핑/뉴스/검색/전체보기/로그인)
-
서비스 로고
-
서비스 메뉴 (영화홈/상영정보/예매/매거진/재밌는DB/커뮤니티/시사이벤트/마이무비)
-
검색 (영화검색, 인물검색, 통합검색), 인기검색어 4-5건, 재밌는DB 신규 등록내용 1-2건을 같이 보여준다.
-
영화 클릭 순위 : daily(default)/weekly 변경가능, 5건 정도 제목과 링크 제공. 상위 1건에 대해 이미지 썸네일 제공
-
영화기사목록 : 요즘뜨는이영화/Photo & Talk/뉴스매거진 각 5개씩 최근 등록 순서로, 상위 1건에 이미지가 있을 경우 이미지 썸네일 포함.
-
P oll
-
서비스 크레딧
-
카피라이트
-
프로모션 배너 1
-
프로모션 배너 2
-
프로모션 배너 3
-
프로모션 배너 4
페이지 이름 : 개별 영화 정보 보기
URL : /movieinfo?mkey=영화id
설명 :
이 페이지는 개별 영화 정보 보기 페이지로 검색결과 및 개별 영화 정보의 기본 링크가 된다.
전체 화면배치는 영화사이트 기본 레이아웃을 따른다 . ( 공통 구성요소 및 UI 스타일 가이드 참고)
컨텐트 :
-
각 영화 정보 보기 페이지 및 그 서브 페이지에 공통으로
전체보기/동영상,포토/영화지식/매거진/네티즌평
의 서브메뉴를 제공한다.
-
영화 타이틀, 원제, 제작년도, 제작국가의 정보 제공
-
영화 정보 제공
포스터 / 감독 / 출연 / 관람점수 / 장르 / 개봉일 / 상영시간 / 관람등급 / 관련정보 / 사이트 등
-
동영상 프리뷰 및 스틸컷 썸네일 4~5장 제공 -> 갤러리 페이지로 링크
-
평점
-
관람포인트 : 200자 내외의 텍스트 설명
-
줄거리 : 400자 내외의 텍스트로 된 줄거리
-
영화지식 : 해당 지식검색으로 연결되는 링크 모음
-
매거진 : 해당 뉴스 기사로 연결되는 링크 모음(종류, 기사제목, 출처, 날짜 등 부가 정보 필요)
-
네티즌리뷰 : 해당 네티즌 리뷰로 연결되는 링크 모음(제목, 작성자, 날짜등 부가 정보 필요)
-
400자평 보기 : 생략 …
-
간략하게 적은 것이고, 반드시 이런 형식이어야 한다는 것은 아니다. 각 회사의 사정에 따라 내부 문서 규격도 있을 터이고. 디자이너의 창의성과 퍼블리셔의 구조화를 저해하지 않는다면 기존의 스토리보드 형태의 파워포인트 문서래도 상관없다.
이제, 이 명세서를 기반으로 구조화를 해보자.
구조화의 요점은, “ 덩어리로 분할해서 나누어 공략한다. ” Divide & Conquer라는 오래된 – 그러나 확실한 전략이다. 효율적인 작업을 위해서 공통 레이아웃 등은 별도로 작업하는 것이 좋겠지만, 여기에서는 예시를 위해 한번에 다룬다.
명세서를 받은 퍼블리셔 (혹은 디자이너, 혹은 개발자, 혹은 기획자 … ) 는 해당 페이지의 목적과 컨셉 과 스타일 에 맞게 내용을 묶어 분할하기 시작한다. 우선, 디자이너가 처음 잡은 스타일 가이드에 따르면 전형적인 2단 레이아웃 구조를 지시했으므로 크게 보아 이 문서는 다음과 같이 러프하게 구조화할 수 있을 것이다. (2단 레이아웃이 아니더라도 사실 대부분 1단계 분할은 다음 형태처럼 되기 마련이다.)
|
* Header 영역 * Content 영역 * Footer 영역 |
2단 레이아웃을 지시했으므로, Content영역은 좀 더 나눌 필요가 있겠다.
|
* Header * Content * MainContent * SideContent * Footer |
퍼블리셔가 파악하기에, 위의 명세서에 들어간 내용 들 중 Header에 속하는 것은 다음과 같다.
* Header
* SiteMenu
* ServiceLogo
* ServiceMenu
* Search
* Promotion_1
* MovieRank
같은 방식으로 나머지들을 구조화한다.
* Header
* SiteMenu
* ServiceLogo
* ServiceMenu
* Search
* Promotion_1
* MovieRank
* Content
* MainContent
* SideContent
* Promotion_2
* ArticleBox
* Poll
* Promotion_3
* Footer
* Credit
* Copyright
이제 대략적인 공통 페이지 구조는 다 잡은 셈이다. MainContent에 들어갈 내용만 페이지 별로 상세화하면 된다.
이 페이지는 크게 “ 제목 ” , “ 메뉴 ” 와 “ 내용 ” 으로 나뉘어진다. 그러므로 그에 맞게 구조화하자.
* MainContent
* ContentTitle
* ContentMenu
* ContentBody
ContentBody에 들어갈 내용은 다음과 같다.
* ContentBody
* MovieInfo
* Poster
* Director
* Casting
* MovieField_1
* MovieField_2
* MovieField_3
…
* Score
* Point
* Synopsis
* Knowhow
…
이 구조가 정답이라는 소리는 아니다. 이런 식으로 계층적으로 내용을 분할해 들어갈 수 있다면 다른 방식의 구조화도 가능하다.
어쨌거나, 보면 알겠지만, 결국 명세서에 써있는 내용을 잘 정리한 것 뿐이다. 애초에, 명세서에 내용을 이런 식으로 정리해놓았다면 별도의 구조화도 거의 필요없다.
이제 XHTML 코딩을 해보자.
…
<body>
<div id= ” header ” >
<div id= ” sitemenu ” ></div>
<div id= ” servicelogo ” ></div>
<div id= ” servicemenu ” ></div>
<div id= ” search ” ></div>
<div id= ” promotion_1 ” ></div>
<div id= ” movierank ” ></div>
</div>
<div id= ” content ” >
<div id= ” maincontent ” >
<div id= ” contenttitle ” ></div>
<div id= ” contentmenu ” ></div>
<div id= ” contentbody>
<div id= ” movieinfo ” >
<div id= ” poster ” ></div>
<div id= ” director ” ></div>
<div id= ” casting ” ></div>
<div id= ” moviefield_1 ” ></div>
…
</div>
<div id= ” score ” ></div>
<div id= ” point ” ></div>
<div id= ” synopsis ” ></div>
<div id= ” knowhow ” ></div>
</div>
</div>
<div id= ” sidecontent ” >
<div id= ” promotion_2 ” ></div>
<div id= ” articlebox ” ></div>
<div id= ” poll ” ></div>
<div id= ” promotion_3 ” ></div>
</div>
</div>
<div id= ” footer ” >
<div id= ” credit ” ></div>
<div id= ” copyright ” ></div>
</div>
</body>
</html>
이 정도 결과가 나오면 절반 이상 도달한 셈이다. 보면 알겠지만, 위에 “ 구조화 ” 의 결과를 그대로 HTML코드만 써서 붙인 셈이다.
이런 결과가 나올 것인데, 아예 기획자들이 파워포인트로 명세서를 쓰는 대신 처음부터 이런 HTML 코드를 짜주는 것이 바람직하겠으나 현실적으로 기획자들이 그런 수고를 해줄 것 같지 않다. 대개 기획자들의 직급이 대체로 높은 것도 한 몫 할지도. J
이제 남은 것은 아직도 비어있는 각 블록의 안쪽을 세세하게 컨텐트에 맞춰 채워넣는 것이다. 원리는 위와 상동.
예를 들어 sitemenu를 채워보자.
이 사이트 및 패밀리 사이트들이 공유하는 최상위 메뉴(메뉴라기보다는 링크모음이겠으나.)는 다음과 같다.
메일, 카페, 플래닛, 블로그, 쇼핑, 뉴스, 검색, 전체보기, 로그인
메일~뉴스까지는 패밀리사이트 링크들의 모음이므로 하나의 목록으로 묶을 수 있겠다.
검색은 form이 들어가므로 별도.
전체보기는 사이트맵으로 가는 링크이니 앞의 메일~뉴스 링크들과는 성격이 다르고,
로그인 역시 사용자 계정과 관련있는 링크이므로 별도로 분리하는 것이 낫겠다.
해서 대충 묶어보면 다음 같은 구조가 되는 것이다.
|
<div id= ” sitemenu ” > <ul id= ” familysite> <li><a href= ”” >메일</a></li> <li><a href= ”” >카페</a></li> <li><a href= ”” >플래닛</a></li> <li><a href= ”” >블로그</a></li> <li><a href= ”” >쇼핑</a></li> <li><a href= ”” >뉴스</a></li> </ul> <form id= ” form_search ” action= ”” method= ”” > <input type= ” text ” id= ” txt_search ” name= ” txt_search ” value= ”” /> <input type= ” image ” src= ”” alt= ” 검색 ” id= ” btn_search ” name= ” btn_search ” /> </form> <div id= ” link_sitemap ” > <a href= ”” >전체보기</a> </div> <div id= ” link_login ” > <a href= ”” ><img src= ”” alt= ” 로그인 ” /></a> </div> </div> |
믿기지 않겠지만, sitemenu 부분의 코딩은 이걸로 끝났다. 나머지 부분들도 이런 식으로 상세화해나가면 된다.
자, 여기까지 오는 동안 중요한 포인트가 있다면, “ 디자인된 화면 ” 이 전혀 필요없다는 점이다. 즉, “ 디자인 ” 과는 별개로 “ 코드 ” 가 완성된다. 이것이 가능한 이유는, 충분히 기획회의를 거쳤고, 대강의 디자인구조가 녹아있는 스타일가이드가 있으며, 페이지 명세서가 상세히 작성되었기 때문이다. 기획이 끝나자마자 바로 코드가 생산된다는 뜻이다.
이것은 어떤 이득을 가져다줄까?
사실, 프로그래머들에게는 “ 코드 ” 만 있으면 되지, 그것이 어떤 “ 디자인 ” 이냐는 전혀 중요하지 않다. 기획이 끝나자마자(기획자가 능숙하다면 기획단계부터 동시에 코드가 생산될 수도 있다.) 바로 생산되는 코드는 프로그래머 입장에서는 매우 반가운 일이다. 게다가 디자인 요소가 없으므로 인해 코드는 오죽 읽기 쉬운가. 또 한참 작업도중에 디자인 변경되었다고 코드 뜯어고칠 일도 없다. 웹 프로그래머, 비로소 할만한 직업이 되는 것 같다. :)
디자이너들도 코드 생산의 압박에 시달릴 필요없다. 그저 생산된 코드를 스윽 보고, 각 블록단위에 필요한 “ 백그라운드용 이미지 ” 들, “ 버튼 이미지들 ” 만 그려내면 된다. 전반적인 건 이미 스타일가이드 작성 때 만들어두었으니까 할 일은 별로 많지도 않다. 또 디자인 변경 때문에 밤새 코드 뒤적거려가며 찾기/바꾸기 단축키를 연타할 필요도 없다. 좀 한가해졌으니 인터페이스공학 에 대해 연구 해 볼 시간이 생기리라 믿는다.
기획자들도 행복 하다. 적어도 몇백페이지짜리 스토리보드 편집은 안해도 되니까.
관리자들도 만족한다. 개발기간이 단축되었고, 유지보수,수정변경이 더 쉬워졌으며, 트래픽 절감효과로 서버 및 회선 비용을 아낄 수 있다.
사용자들도 마찬가지. 사이트가 빨리 열린다. Firefox사용자도, 매킨토시 사용자도 따로 구분할 필요없다. 심지어 핸드폰이나 PDA나 웹TV나 기타 등등 어떠한 장비-그것이 웹표준을 준수하기만 한다면 냉장고에 붙은 웹브라우저에서도 정상적인 이용이 가능하다. 시각장애인들도 불편없이 사용할 수 있다.
그밖에 검색엔진 친화성이라든가, 리팩토링, 머신피드용이 등의 부가효과들에 대해서는 더 이야기할 것도 없다.
잠깐, 중요한 것을 빼먹었다 고?

아까 만든 sitemenu, 이런 식으로 내버려두면 어쩌냐는 불안의 목소리가 있을 듯 하여 원래 강의 목표와는 상관없 지만, 완성된 XHTML에 CSS를 입히는 부분에 대한 보너스를 덧붙인다.
<div id="sitemenu">
<ul id="familysite">
<li><a href="">메일</a></li>
<li><a href="">카페</a></li>
<li><a href="">플래닛</a></li>
<li><a href="">블로그</a></li>
<li><a href="">쇼핑</a></li>
<li><a href="">뉴스</a></li>
</ul>
<form id="form_search" action="" method="">
<input type="text" id="txt_search" name="txt_search" value="" />
<input type="image" src="http://image.hanmail.net/hanmail/temp/b_search.gif" alt="검색" id="btn_search" name="btn_search" />
</form>
<div id="link_sitemap">
<a href="">전체보기</a>
</div>
<div id="link_login">
<a href=""><img src="http://image.hanmail.net/hanmail/temp/b_login.gif" alt="로그인" /></a>
</div>
</div>
아까와 같은 소스인데, 이미지 url만 붙였다. 여기에 아래의 CSS를 적용해보라.
* {
font-family:tahoma, gulim, sans-serif;
font-size:12px;
}
a {
color:#333;
text-decoration:none;
}
a:hover {text-decoration:underline;}
a img {
border:none;
}
#sitemenu {
float:right;
}
#familysite {
float:left;
margin:0px;
padding:0px;
}
#familysite li {
float:left;
list-style-type:none;
background-image:url("http://image.hanmail.net/hanmail/temp/dot.gif");
background-position:center right;
background-repeat:no-repeat;
padding-left:5px;
padding-right:5px;
display:block;
}
#form_search {
float:left;
margin-left:5px;
}
#form_search input {
float:left;
height:11px;
margin-right:5px;
}
#form_search input#btn_search {
height:16px;
}
#link_sitemap {
float:left;
}
#link_login {
float:left;
margin-left:5px;
}
그 결과는 놀랍게도 다음과 같을 것이다.

마무리를 해보자.
CSS가 대세 … 이긴 한데, CSS만 익히는 것은 아무런 소용이 없다. 구조화된 XHTML문서를 생성해낼 수 있어야만 비로소 CSS를 적용할 수 있게 된다.
웹표준화, 접근성의 확보에 CSS가 필수인 것만큼 당연히 XHTML에 대한 완벽한 이해가 선행되어야 한다.
XHTML문서의 구조화는 디자인과는 상관없이 온전히 내용만 가지고 이루어야하며, 나중에 CSS를 이용하여 디자인을 씌울 때에도 무리없이 적용되도록 잘 구조화되어야 한다.
그러나 이 과정은 기존의 개발공정으로는 제대로 담아낼 수 없어서 새 공정을 필요로 한다. 여기에서 든 내용들은 개인의 역량, 조직사정 등에 의해 유연하게 적용되어야겠지만, 중요한 것은 단지 어떤 기법을 쓸 것인가가 아니라, 왜 웹 표준화를 해야하는가, 왜 웹 접근성을 지켜야 하는가, 무엇이 의미론적인 웹을 만드는가 … 이러한 부분들을 확실히 이해한다면 XHTML의 구조화, CSS를 위한 디자인이 한결 현실감있게 다가올 것이다.
Ref. 2.
-
Reference-Sites
한국소프트웨어진흥원 http://www.software.or.kr/kipahome/kipaweb
크로스 브라우징 가이드
http://www.mozilla.or.kr/docs/web-developer/standard/crossbrowsing.pdf
홈페이지 구축운영 표준 지침
http://www.mogaha.go.kr/warp/webapp/sys/dn_attach?id=1c0bdf783dc19fce1e2facc
웹접근성을 고려한 콘텐츠 제작기법
http://www.mozilla.or.kr/docs/web-developer/content_authoring_for_accessibility.pdf
웹사이트 가이드 (미국)
http://www.usability.gov/guidelines/Usability_guidelines.pdf
css ZenGarden http: //csszengarden.com
A List Apart http://alistapart.com
W3School http://www.w3school.com
C ross-browser http://www.cross-browser.com
한국 모질라 포럼 웹표준화 프로젝트 http://forums.mozilla.or.kr/viewforum.php?f=9
CSS 디자인 코리아 http://css.macple.com
신승식님 http://gregshin.pe.kr/bbs/zboard.php?id=ud
박민권 님 http://ani2life.egloos.com/
Tabula Rasa http://eouia0.cafe24.com
박수만님 http://www.sumanpark.com/
윤석찬 님 http://channy.creation.net/blog/
kukie.net http://kukie.net/resources/benefits/
hochan.net http://hochan.net/archives/cat_aii_aissa.html
daybreaker http://www.daybreaker.x-y.net
별주부뎐 http://blog.webservices.or.kr/hollobit/
-
Reference-Books
Web Standard Solution : The Markup and Style Handbook / 댄 씨더홈
(8월중 번역 출간 by 박수만님)
Web Designer's Reference : An Integrated Approach to Web Design with XHTML and CSS / 크랙 그라넬
The CSS Anthology / 레이첼 앤드류
Bulletproof Web Design : Improving flexibility and protecting against worst-case scenarios with XHTML and CSS / 댄 씨더홈
Cascading Style Sheets: The Definitive Guide / 에릭 마이어 (번역판 있음)
HTML & XHTML : The Definitive Guide / 척 머스키아노 (번역판 있음)
-
Tools
NVU
Rapid CSS Editor
Topstyle
PSPad
CSSedit
X-Edit
StyleMaster
Adobe Golive CS2
DreamWeaver 8
FF용 플러그인들. (CSS 셀렉터, 그리스몽키, … 너무 많아 일일이 적을 수가 없네요. ^_^)
물론 XHTML, CSS 모두 텍스트 기반이므로 손에 익기만 하다면 아무 텍스트 에디터라도 상관없습니다. 저는 주구장창 VIM과 UltraEdit만 쓰고 있습니다.
평가/인증
W 3C HTML Validator : http://validator.w3.org/
W3C CSS Validator : http://jigsaw.w3.org/css-validator/
Webxact Accessibility Validator : http://webxact.watchfire.com
<script language='javascript'>
function hangul()
{
if((event.keyCode < 12592) || (event.keyCode > 12687))
event.returnValue = false
}
</script>
<input type="text" name="Name" size="10" maxlength="15" class=ad onKeyPress="hangul();">
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
input text 한영 한글/영문 입력 설정
<FORM>
<input style="ime-mode:active;">
<input style="ime-mode:inactive;">
</FORM>
ime-mode:active 이면 한글입력
ime-mode:inactive 이면 영문입력
익스플로러 6에서만 작동
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
한글 전환 모드 안 되게 하기
<input type="text" style="ime-mode:disabled;">
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
한영 한글/영문 전환 버튼
<html>
<head>
<script language="javascript">
<!--
function Kren(form)
{
if(form.test.style.imeMode == "active")
form.test.style.imeMode = "inactive";
else
form.test.style.imeMode = "active";
}
//-->
</script>
</head>
<body>
<form name=form1 action="">
<input type="text" name="test">
<input type="button" onClick="Kren(this.form)" value="한/영전환">
</form>
익스플로러 6이상에서만 작동합니다.
</body>
</html>
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
숫자만 입력받기
<script>
function num_only(){
if((event.keyCode<48) || (event.keyCode>57)){
event.returnValue=false;
}
}
</script>
<form name='test'>
<input type=text name='numInputField' OnKeyPress="num_only()" style="ime-mode:disabled">
</form>
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
전화번호 포맷으로 숫자만 입력하면 (02)123-3423 이런식으로 바꿔줍니다
<SCRIPT LANGUAGE="JavaScript">
<!--
///
var n;
var p;
var p1;
function ValidatePhone(){
p=p1.value
if(p.length==3){
pp=p;
d4=p.indexOf('(')
d5=p.indexOf(')')
if(d4==-1){
pp="("+pp;
}
if(d5==-1){
pp=pp+")";
}
document.frmPhone.txtphone.value="";
document.frmPhone.txtphone.value=pp;
}
if(p.length>3){
d1=p.indexOf('(')
d2=p.indexOf(')')
if (d2==-1){
l30=p.length;
p30=p.substring(0,4);
p30=p30+")"
p31=p.substring(4,l30);
pp=p30+p31;
document.frmPhone.txtphone.value="";
document.frmPhone.txtphone.value=pp;
}
}
if(p.length>5){
p11=p.substring(d1+1,d2);
if(p11.length>3){
p12=p11;
l12=p12.length;
l15=p.length
p13=p11.substring(0,3);
p14=p11.substring(3,l12);
p15=p.substring(d2+1,l15);
document.frmPhone.txtphone.value="";
pp="("+p13+")"+p14+p15;
document.frmPhone.txtphone.value=pp;
}
l16=p.length;
p16=p.substring(d2+1,l16);
l17=p16.length;
if(l17>3&&p16.indexOf('-')==-1){
p17=p.substring(d2+1,d2+4);
p18=p.substring(d2+4,l16);
p19=p.substring(0,d2+1);
pp=p19+p17+"-"+p18;
document.frmPhone.txtphone.value="";
document.frmPhone.txtphone.value=pp;
}
}
setTimeout(ValidatePhone,100)
}
function getIt(m){
n=m.name;
p1=m
ValidatePhone()
}
function testphone(obj1){
p=obj1.value
p=p.replace("(","")
p=p.replace(")","")
p=p.replace("-","")
p=p.replace("-","")
if (isNaN(p)==true){
alert("Check phone");
return false;
}
}
//-->
</script>
전화번호보단 다른 데 응용하시면 좋을 듯..<br>태그인넷 tagin.net<br>
<form name=frmPhone>
<input type=text name=txtphone maxlength="13" onclick="javascript:getIt(this)" >
</form>
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
입력박스 폼안의 숫자 1000단위로 자동 ,콤마 찍어주기
<SCRIPT LANGUAGE="JavaScript">
<!--
function Number_Format(fn){
var str = fn.value;
var Re = /[^0-9]/g;
var ReN = /(-?[0-9]+)([0-9]{3})/;
str = str.replace(Re,'');
while (ReN.test(str)) {
str = str.replace(ReN, "$1,$2");
}
fn.value = str;
}
//-->
</SCRIPT>
<FORM name=fm METHOD=POST ACTION="">
<INPUT TYPE="text" NAME="money" Onkeyup="Number_Format(this)";>
</FORM>
-------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------
특수문자 입력금지
<center>
<form onSubmit="return false;">
<a href="http://tagin.net">특수문자를 입력 할 수 없습니다: (예 !@#$%^&* etc)<br>
<textarea rows=2 cols=20 name=comments onKeypress="if ((event.keyCode > 32 && event.keyCode < 48) || (event.keyCode > 57 && event.keyCode < 65) || (event.keyCode > 90 && event.keyCode < 97)) event.returnValue = false;"></textarea>
<br>
<br>
홋(겹)따옴표를 입력 할 수 없습니다:<br>
<input type=text name=txtEmail onKeypress="if (event.keyCode==34 || event.keyCode==39) event.returnValue = false;">
<br>
<br>
숫자만 입력가능합니다:<br>
<input type=text name=txtPostalCode onKeypress="if (event.keyCode < 45 || event.keyCode > 57) event.returnValue = false;">
</a></form>
</center>
DIV에 스크롤바 나타내기
overflow-x x축(가로)
overflow-y y축(세로)
overflow:visible 레이어 크기를 키워서 보여준다 (* 디폴트)
overflow:hidden 레이어 크기만큼만 보여준다
overflow:auto 내용에 따라 자동으로 스크롤을 만든다
overflow:scroll 무조건 스크롤바를 생성한다
스크롤바 꾸미기
<style type="text/css">
scrollbar-face-color:#FFFFFF; 스크롤바 전체 색상
scrollbar-track-color: #FFFFFF; 스크롤바가 없는 스크롤바 아래에 위치한 부분의 색상
scrollbar-arrow-color: #666666; 위 아래 화살표 색상
scrollbar-highlight-color: #FFFFFF; 왼쪽과 위쪽의 하이라이트 색상
scrollbar-3dlight-color: #cfcfcf; 입체감을 위한 왼쪽 위 색상
scrollbar-shadow-color: #FFFFFF; 오른쪽과 아래쪽의 그림자 색상
scrollbar-darkshadow-color: #cfcfcf; 바의 오른쪽, 밑쪽에 들어가는 얇은 색
</style>
==================================================================================================================
div Style속성
overflow: ######;
visible : 레이어 크기를 키워서 출력.
hidden : 레이어 크기만큼 출력.
auto : 내용에 따라 자동 스크롤.
scroll : 스크롤바 생성.
ex) overflow-x:값; overflow-y:값; overflow:값;
position: ######;
static : 기본값.
relative : 하위에 div가 있을 경우엔 하위의 div를 absolute 배열.
absolute : div에 top, right, bottom, left 값을 지정해서 원하는 위치에 고정.
fixed : 스크롤에 상관없이 지정한 위치에 고정.
inherit : 상위에서 지정한 값을 상속.
visibility: ######;
visible : 보임.
hidden : 감춤.
z-index: #; :: #값에 따라 우선순위 정의.
left: ##px;
top: ##px;
width: ###px;
height: ###px;
text-align: center;
center , left, right ...
background-color: #######;
border-style: ######;
solid , dotted .....
border-color: ######;
border-width: ##px;
border: ###px;
==================================================================================================================
div 상하로 정렬 하기 (상단, 중앙, 하단)

div가 상단, 중앙, 하단으로 있을 때 하단 div를 bottom으로 붙이는 방법
------------------------------------------------------------------------------------------
<style type="text/css">
#Box {position:relative; width:300px; height:300px;}
#head {float:left; width:300px; height:50px;}
#body {clear:left; float:left; width:300px;}
#foot {position:
</style>
<div id="Box">
<div id="head">상단</div>
<div id="body">중앙<br />내용1<br />내용2</div>
<div id="foot">하단</div>
</div>
------------------------------------------------------------------------------------------
겉에 감싸는 div에 position을 relative로 주고
하단으로 붙이고 싶은 div의 position을 absolute로 주면 하단 div는 겉의 div안에서 움직이게 된다.
하단 div에 left:0과 bottom:0으로 주어야 하단으로 딱 붙게 된다.
==================================================================================================================
div 가운데 정렬
테이블을 사용할 때는 td에 align을 center로 주면 그 안에 들어가는 내용이 딱딱 가운데 정렬이 됐었는데..
div를 가운데 정렬하려니 도통 안되는 것이다..
몇번의 검색과 이것 저것 찾다보니 알게 된 것이 margin:0 auto 를 사용하면 된다는 것..
align의 center가 되는 것은 block레벨이 아닌 것에만 적용이 된다고 한다.
div는 block 레벨이니 당연히 div 자체에는 align이 먹히지 않는 것..
------------------------------------------------------------------------------------------
<style type="text/css">
#BoxCenter {margin:0 auto; width:300px; height:100px; background-color:#33CCFF;}
</style>
<div id="BoxCenter">div 중앙 정렬</div>
------------------------------------------------------------------------------------------
==================================================================================================================
body 레이어의 onresize 이벤트에서 처리 해주시면 됩니다..
간단하게 예제 올립니다.
스타일정의 - 레이어의 외곽선을 보이기 위해 정의 했습니다.
<style>
.Layer{
position:absolute;
BORDER-BOTTOM: 1px solid;
BORDER-LEFT: 1px solid;
BORDER-RIGHT: 1px solid;
BORDER-TOP: 1px solid;
FONT-FAMILY: "돋움"; FONT-SIZE: 20pt
}
</style>
자바스크립트 정의 - LayerBody 의 onresize 이벤트에서 처리 했습니다.
그리고 window.onload 이벤트에서 LayerBody의 Height를 변경하여
테스트 하였습니다.
<SCRIPT ID=clientEventHandlersJS LANGUAGE=javascript>
<!--
function LayerBody_onresize() {
//LayerLeft 의 height 를 변경된 LayerBody의 height의 값을 대입
document.getElementById("LayerLeft").style.height = document.getElementById("LayerBody").style.height;
//LayerRight 의 height 를 변경된 LayerBody의 height의 값을 대입
document.getElementById("LayerRight").style.height = document.getElementById("LayerBody").style.height;
//LayerBottom의 top 을 LayerBody의 (top + height)을 대입하여 LayerBody의
//끝부분에 위치하게 한다.
document.getElementById("LayerBottom").style.top = document.getElementById("LayerBody").offsetTop + document.getElementById("LayerBody").offsetHeight;
}
function window_onload() { //테스트를 위해 window객체의 onload 이벤트에서 LayerBody의 height를 1000px로 변경 하였다.
document.getElementById("LayerBody").style.height = "1000px";
}
//-->
</SCRIPT>
body 부분 정의
<body onload="return window_onload()">
<div id="LayerLeft" class=Layer style="width:133px; height:325px; z-index:1"></div>
<div id="LayerBody" class=Layer style="width:301px; height:325px; z-index:2; left: 145px; top: 15px;" onresize="return LayerBody_onresize()"></div>
<div id="LayerRight" class=Layer style="width:188px; height:325px; z-index:3; left: 448px;"></div>
<div id="LayerBottom" class=Layer style="width:629px; height:115px; z-index:4; left: 9px; top: 341px;"></div>
</body>
==================================================================================================================
웹 페이지가 상당히 길 때 사용자로 하여금 특정 부분만 인쇄할 수 있는 인터페이스를 제공해 주고 싶은 경우들이 종종 있다. 하지만 일반 브라우저는 페이지의 특정 부분만을 인쇄할 수 있는 메쏘드를 제공하고 있지 않다. 물론, 브라우저의 인쇄 대화 상자에서 일부 페이지를 인쇄할 수 있기는 하지만 우리가 원하는 것은 그런 기능이 아니다.
백문이 불여일견! 아래 있는 "소스실행하기"버튼을 클릭한 후 나타난 화면에서 원하는 인쇄 영역을 선택한 다음 "특정 부분 인쇄" 버튼을 클릭해 보기 바란다.
<DIV> 태그를 잘 이용하면 특정 DIV 영역만 인쇄할 수가 있다.
인 터넷 익스플로러는 window.onbeforeprint와 window.onafterprint 이벤트 핸들러를 지원하는데, 이들은 인쇄 전과 후의 웹 페이지 내용을 변경할 수 있도록 도와준다. 이 기능을 이용하여 특정 DIV 영역은 보이게 하고 나머지 영역은 숨길 수가 있다. (불행히 넷스케이프는 이 이벤트 핸들러를 지원하지 않는다. 하지만 여기서는 약간의 제약이 있긴 하지만 넷스케이프에서도 약간의 보이기 속성을 조절하여 비슷하게 구현해 보기로 한다.)
<HTML>
<HEAD>
<STYLE>
DIV { position: relative; }
</STYLE>
<SCRIPT>
var div2print;
function printDiv (id) {
if (document.all && window.print) {
div2print = document.all[id];
window.onbeforeprint = hideDivs;
window.onafterprint = showDivs;
window.print();
}
else if (document.layers) {
div2print = document[id];
hideDivs();
window.print();
}
}
function hideDivs () {
if (document.all) {
var divs = document.all.tags('DIV');
for (var d = 0; d < divs.length; d++)
if (divs[d] != div2print)
divs[d].style.display = 'none';
}
else if (document.layers) {
for (var l = 0; l < document.layers.length; l++)
if (document.layers[l] != div2print)
document.layers[l].visibility = 'hide';
}
}
function showDivs () {
var divs = document.all.tags('DIV');
for (var d = 0; d < divs.length; d++)
divs[d].style.display = 'block';
}
</SCRIPT>
</HEAD>
<BODY>
<DIV>
<FORM>
<SELECT NAME="divSelect">
<OPTION>첫 번째 영역만 인쇄
<OPTION>두 번째 영역만 인쇄
<OPTION>세 번째 영역만 인쇄
</SELECT>
<INPUT TYPE="button"
ONCLICK="var s = this.form.divSelect;
var divID = s.options[s.selectedIndex].text;
printDiv(divID);"
VALUE="특정 부분 인쇄"
>
</FORM>
</DIV>
<DIV ID="d1">
<b>[첫 번째 영역]</b><br>
첫 번째 영역입니다!<br><br>
</DIV>
<DIV ID="d2">
<b>[두 번째 영역]</b><br>
두 번째 영역입니다!<br>
두 번째 영역을 선택하여 인쇄해 보세요!<br><br>
</DIV>
<DIV ID="d3">
<b>[세 번째 영역]</b><br>
세 번째 영역입니다!<br>
세 번째 영역을 선택하여 인쇄해 보세요!<br>
From 코리아인터넷닷컴
</DIV>
</BODY>
</HTML>
출처 : 코리아인터넷닷컴
==================================================================================================================
div는 무엇일까? 어떻게 사용해야 할까?
HTML에서의 div는 Division Marker의 줄임말로서 영역을 구분짓거나 무리(구분)지어주는 엘리먼트이다.
div는 div를 열고 닫은 앞뒤로 줄바꿈이 되는 블럭 레벨 항목 block level element이다.
div의 앞 뒤에 있는 항목들이 가로줄로 흐르지 않고, 엔터값을 입력한 것 처럼 아래로 줄 지어진다는 말이다.
div로 레이아웃이나 박스를 구성하기 위해, CSS에서 가장 많이 쓰는 속성인 position 값으로는 static, relative, absolute, fixed, inherit가 있다.
Position 속성
static
CSS로 특별한 값을 지정해 주지 않아도 적용되는 기본값이다.
HTML 파일에서 중첩되지 않은 여러개의 div를 작성하면, 위에서 부터 차곡 차곡 쌓이는 기본적인 형태이다.
relative
한개의 div가 있고 relative로 설정할 경우엔 static과 큰 차이는 없다. 하위에 div가 있을 경우엔 하위의 div를 absolute 배열 할 수 있다.
absolute
흔히 레이어라는 개념으로 알고 있는 값이다. div에 top, right, bottom, left 값을 지정해서 원하는 위치에 고정되게 띄울 수 있다.
fixed
기본적으로 absolute와 같다. absolute는 canvas의 스크롤에 따라 올라가고 내려가지만 fixed의 경우는 스크롤에 상관없이 지정한 위치에 고정된다.
inherit
상위에서 지정한 값을 상속한다.
div를 설명하자면, 레이아웃layout 또는 박스모델 boxmodel을 빼놓고 말할 수 없다.
위에도 적었듯이 컨텐츠를 묶어주는 역할을 하는데, 컨텐츠를 묶어서 배열 하는 것이 곧 레이아웃layout이기 때문이다.
컨텐츠 안에서의 div는 사용자가 사용하기 나름일테고, 컨텐츠를 묶어주는 역할의 div는, 위치를 지정함(positioning)으로써 자신의 진정한 역할을 하게 된다.
여기서는 컨텐츠를 묶어주는 가장 크고 바깥의 영역을 담당하는 div에 대해 얘기하도록 하자.
positioning하는 것은 div를 float 시키거나 절대값으로 위치absolute positioning 하는 등 사용자가 원하는 위치에 위치시키는 것을 말한다.
positioning하기 위해서는 위에 나열한 position 속성을 사용하거나, float를 사용하여야 한다.
기본 적인 형태의 Layout
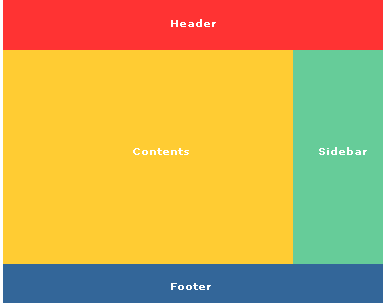
XHTML code
<!doctype html public "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ko" >
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=euc-kr">
<title> New Document </title>
<link rel="stylesheet" type="text/css" href="css/left.css">
</head>
<body>
<div id="header">헤더</div>
<div id="container">
<div id="contents">컨텐츠</div>
<div id="sidebar">사이드바</div>
</div>
<div id="footer">푸터</div>
</body>
</html>
CSS code (float 사용)
body {
margin: 0;
padding: 10px;
background-color: #FFF;
}
#container {
width: 380px;
}
#header {
background-color: #FF4A4D;
height: 50px;
}
#contents {
float: left;
background-color: #FFC64A;
width: 290px;
height: 214px; /* 임의 지정 */
}
#sidebar {
float: right;
background-color: #85C69D;
width: 90px;
height: 214px; /* 임의 지정 */
}
#footer {
clear: both;
background-color: #3B83B1;
height: 40px;
}
boxmodel의 예제는 Little Boxes에서 자세히 살펴볼 수 있다. 하단에 몇 개 더 소개하도록 하겠다.
절대값 위치absolute positioning에 대한 개념은 좌표를 지정하여 div를 배열하는 방식이기 때문에 기존의 레이어layer 개념을 알고 있다면 정확하게 익히는 것이 어렵지 않을 것이라고 본다.
그럼 float에 대해 좀 더 알아보자.
float의 값으로는 left, right, none, inherit가 있다.
float 속성
left
left로 설정된 엘리먼트가 HTML 코드에서 바로 다음 엘리먼트의 왼쪽에 위치하게 된다.
right
right로 설정된 엘리먼트는 바로 다음 엘리먼트의 우측에 위치하게 된다.
none
float 하지 않는다.static의 상태로 자연스럽게 박스가 쌓이는 형태라고 보면 된다.
inherit
상위에서 지정한 값을 상속한다.
float를 사용할 때는 clear에 대해서도 알아야 하겠다.
위에서 어떠한 항목에 대해 float:left; 혹은 float: right;를 설정하였을 경우 그 아래에 있는 것들도 영향을 받게 된다. 그것들에 대해 다시 초기화를 시켜주는 것이 clear이다.
left, right 각각 해당 정렬에 대한 영향을 없애주고 both는 둘 다 없애준다.
div의 width, height
특별히 width나 height를 정해주지 않으면 컨텐츠의 길이와 넓이에 따라 자동적으로 늘어나고 줄어든다.
만약에 width를 지정했는데, 끊기지 않는 텍스트나 커다란 이미지 혹은 링크로 인해 고정한 width보다 컨텐츠가 넓어질 경우에는 overflow 속성을 지정해서 해결 할 수 있다.
(FF에서는 박스는 고정되어 있고 컨텐츠만 삐져나오고, IE에서는 컨텐츠에 따라 박스가 함께 넓어 지기 때문에 레이아웃이 엄청 깨지는 것을 볼 수 있다. height를 고정한 경우에는 height에도 함께 적용 된다.)
overflow에 지정할 수 있는 속성으로는 visible, hidden, scroll, auto등이 있다.
visible
내용을 자르지 않고 블럭 밖까지 가도록 허용한다.
hidden
박스를 넘어갈 경우, 넘어가는 부분을 감추어 버린다. (잘림부분의 크기와 모양은 ‘clip’ 속성에 의하여 결정된다.)
scroll
박스에 기본적으로 scroll을 제공하게 된다. - print나 projection CSS에서 해당 div안의 넘치는 컨텐츠도 인쇄 해준다.
auto
박스는 고정해 두고, 박스보다 컨텐츠가 커질 경우 스크롤을 만들어 준다.
만약에 height를 지정했는데 FF에서 컨텐츠가 삐져나온다면, min-height를 이용하여 해결 할 수 있다.
고정된 값을 지정했다면, 컨텐츠가 많이 지더라도 div의 높이 값은 고정되어 있는 것이 맞다.
IE 는 자체지능적;으로 컨텐츠에 따라 높이를 마음대로 높혀 버리는데, IE처럼 컨텐츠에 따라 div의 높이가 변해주길 바란다면 min-height라는 속성을 지정해 주면 된다. IE에서는 적용되지 않으므로 * html #id { height: 200px; } 같은 hack도 함께 써주어야 한다.
결론적으로 layout을 위해 div를 사용할 때에는 position, float에 대해서는 기본적으로 알아야 하고, 부가적으로 overflow를 알아두면 더욱 적절히 사용할 수 있겠다.
[출처] div는 무엇일까? 어떻게 사용해야 할까?|작성자 김둘
Mysql 자동 백업 하기 - Rsync와 연계하면 좋음
/root아래에 backup.sh 이라는 파일을 만들어 놓고 백업 명령어를 다음과 같이 주었다.
#!/bin/bash
/usr/local/mysql/bin/mysqldump -uroot -p***** mysql > mysql_db_bak_$(date +%Y%m%d).sql
/usr/local/mysql/bin/mysqldump -uyanemone -p***** yanemone > yanemone_db_bak_$(date +%Y%m%d).sql
mv *.sql /backup
tar cvfpz /backup/html_bak.tar.gz /var/www/html
tar cvfpz /backup/yanemone_html_bak.tar.gz /home/yanemone/public_html
tar cvfpz /backup/dichang_html_bak.tar.gz /home/dichang/public_html
WEEKAGO=`date -d "-30 days" +%Y%m%d`
rm -f /backup/*${WEEKAGO}.sql
귀찮으니까 한달 지난건 지워버리죠.
백업할 내용이라던지 파일 이름은 자신의 상황에 맞게 주면 되겠다.
이렇게 하고 나면 backup.sh파일을 chmod 100 backup.sh로 단단히 무장하라.
그리고 crontab -e 명령으로 cron 작업을 명시하자
그럼 vi가 열리면서 편집이 가능하다
00 06 * * * /root/backup.sh
를 추가하고 :x 로 저장하고 나오자.
위의 작업은 매일 새벽 6시에 /root/backup.sh을 실행하라 라는 말이다.
그리고 /var/spool/cron/root가 있는지 확인해보자. 있다면 정상적으로 수행할 것이다.
Crontab 의 메일 안받기/etc/crontab이라는 파일을 열어보자
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=ROOT
HOME=/부분이 있다. MAILTO=ROOT를 다음과 같이 고쳐보자
MAILTO=""크론에 등록시 아래와 같이 하면 메일이 날아오지 않는다.
위에꺼는 전체 메일이 다 날아오지 않으므로 주의 해야 한다.
그러므로 아래꺼 사용하믄 된당...
00 06 * * * /root/backup.sh >/dev/null 2>&1
저장할 파일의 크기가 클경우 분할하여 압축할수 있다.
백업을 하다보면 기가단위가 넘을때가 많습니다.
그때는 분할백업(CD 1장 단위가 좋겠죠...)
tar -zcvpf - /압축할dir | split -b 670mb - 압축파일.tar.gz그러면 압축파일.tar.gzaa
압축파일.tar.gzab순으로 파일이 생깁니다.-b 670mb는 압축파일을 670mb단위로 분할 하라는 옵션입니다.
압축풀라고 할때는 (쿠쿠 바로 답해 주셔서 캄솨함다.)
cat test.tar.gza* > test.tar.gz
로 하여 tar.gz파일로 만들어서 풀면 된다.
예전에 만들어진 페이지들을 보면 스크립트부분을
//<!--
//-->
로 묶어 놓은 것을 볼 수 있다. 솔직히 이게 필요하게 느껴본적은 전혀 없지만(그땐 개발도 안했긴 하지만..) 이건 오작동을 막는다는 개념으로 알고 있다. 스크립트가 안먹는 곳에서 스크립트 때문에 오작동을 막기 위해서 html태그로 묶어 놓은 것이다. 하지만 실제로 저게 필요한 경우가 이제는 거의 없는 것 같고 안해도 되기 때문에 요즘은 거의 쓰지 않는 것 같다.
대신 요즘에는
//<![CDATA[
스크립트.....
//]]>
로 묶어준다. 먼가 있어 보여서 쓰긴 했는데 이것에 대해서 정확한 이해를 한지는 얼마 되지 않았다. 이건 DOCTYPE를 XHTML로 사용할 때 써주는 것이다. (내가 HTML 4.01 Tranditional을 거의 쓰지 않아서 그쪽은 잘 모르겠다.) CDATA... XML을 해본 사람은 많이 보던 거란걸 느낄것이다.
XHTML은 기본적으로 형식이다. 스크립트 부분을 CDATA 속성으로 넣어줌으로써 XHTML 파서가 스크립트 부분에 들어간 html부분을 파싱하지 않도록 막아주는 것이다. 물론 대개의 경우 없어도 되지만 이렇게 함으로써 완전히 차단하는 것이다.
유효성검사를 통과하려면 반드시 CDATA로 스크립트를 묶어 주어야 한다. 저 형식은 왠지 잘 외워지지가 않아서... ㅋㅋ CDATA로 묶어 주는데 이부분은 스크립트 문법에 맞지 않지 때문에 //로 주석표시를 해준 것이다.
ps. //<
input type=file은 약간의 특징이 있다. 파일을 업로드하는 기능을 가진 특성때문에 다른 input타입과는 다르게 약간의 제약이 있다. 그건 스크립트를 이용해서 제어하는 것을 막고 있는 것인데 그것 때문에 다루기가 좀 쉽지 않다. 하지만 그것보다 문제되는게 저 "찾아보기..."버튼이다. 점점 디자인이 강조되고 있는 가운데 기본적으로 뜨는 찾아보기 버튼은 웹디자이너에게는 걸리적거리는 것 같다.
항상 디자인을 받을 때마다 찾아보기 버튼대신에 이미지버튼으로 된 디자인이 왔었는데 이번에 여러가지 테스트를 해보았다. 결론적으로 말하자면 찾아보기버튼은 바꿀수 없다.(적어도 내 지식 수준에서는...) 물론 이에대한 태클도 있을꺼라고 생각한다.
가장 쉽게 생각할 수 있는 것이 input type=file을 input type=text와 이미지버튼의 조합으로 대치하는 것이다.
- <input type="text" size="30" id="txt" />
- <img src="" onclick="document.getElementById('file').click();" />
- <input type="file" size="30" id="file" style="display:none;" onchange="document.getElementById('txt').value=this.value;" />
위와같은 모양이다. 인풋파일은 보기에는 인풋텍스트와 버튼의 조합형태이기 때문에 앞에 인풋텍스트를 넣어놓고 그옆에 디자인된 이미지 버튼을 넣은 뒤에 인풋파일은 스타일을 주어서 보이지 않게 하는 것이다. 이미지 버튼을 onclick했을 때 인풋타입의 객체에 click()이벤트를 주는 구조이다. 파일선택하는 창도 아주 잘 뜬다. 인풋파일에 onchange이벤트를 주어서 파일선택해서 값이 들어갈때 인풋텍스트로 값을 복사해서 넣어서 찾아보기버튼을 이미지로 교체한 듯한 효과를 주는 것이다.
실제적으로 인터넷을 찾아보면 찾아보기 버튼 교체에 대한 위의 소스가 엄청 많다. 잘못된 정보의 대표적인 예라고 할 수가 있다. 서버쪽은 제대로 돌려보지도 않고 클라이언트쪽만 테스트 해보고 잘된다고 올려진 소스를 서로 계속 퍼나르고 있는 상황이다. ㅡ..ㅡ
인풋파일은 보안문제상 Read Only이기 때문에 스트립트로 값을 입력하는 것을 허용하지 않는다. 소스상으로는 아주 잘 돌아가는 거서럼 보이지만 막상 submit버튼을 누르면 전송이 되는 것이 아니라 인풋파일의 값이 clear되어 버린다. 스크립트로 실행한 것은 초기화 시켜버리고 다시한번 submit버튼을 눌러야 POST전송이 일어난다.
쉽게 말하면 이구조로는 절대 파일 업로드를 받을 수가 없다.
그래서 다른 방법을 찾기 시작했다.
- <input type="text" size="30" id="txt" />
- <span style="overflow:hidden; width:61; height:20; background-image:url(/images/button.gif);">
- <input type='file' id="file" style="width:0; height:20; filter:alpha(opacity=0);" onchange='document.getElementById('txt').value=this.value;'>
- </span>
그래서 찾은 방법이 위의 방법이다. 방법은 앞에서 얘기했던것과 거의 비슷하다. 파일명을 보여줄 인풋텍스트를 하나 보여주고 그 뒤에 span을 둔다. span은 찾아보기 버튼을 대체해 주는 역할을 한다. 크기를 정해주고 배경색으로 버튼 이미지를 지정해 준다. 그리고 그 span안에 인풋파일을 넣어주는데 여기서 스타일로 width를 0px를 주고 alpha값으로 투명도를 0을 준 것이다.
이렇게 하면 인풋파일의 파일명이 나타나는 부분의 width가 0px가 되기 때문에 나타나지 않고 찾아보기 버튼의 크기는 조절할 수가 없기 때문에 앞에 넣은 인풋파일뒤에 바로 찾아보기 버튼이 위치한다. 하지만 투명도가 0이기 때문에 실제 위치하고 있기는 하지만 보이지가 않고 span의 배경인 버튼 이미지가 보이는 구조이다.
하지만 여기에 약간의 문제가 있다. 일단 여기서 중요한 역할인 투명도를 나타내는 alpha값은 IE에서만 유효한 스타일값이다. Firefox에서는 투명도를 -moz-opacity:0; 를 사용해야 하는데 이걸 사용해도 Firefox에서는 IE같은 효과가 나지 않는다. 배경으로 지정된 이미지버튼이 나오지 않는다. 머 이것만으로도 요즘같은 분위기에서는 의미가 없다고 본다. 그리고 눈에 보이는 버튼이 실제버튼이 아니고 실제버튼은 투명하게 있는 버튼이기 때문에 클릭을 하면 실제 버튼보다 작게 점선이 생겨서 보기에 별로이다. 또한 저 소스에서는 width가 61로 설정이 되어있는데 브라우저마다 다른지는 모르겠지만 IE7에서는 찾아보기 버튼이 103px이기 때문에 이미지버튼도 103에 맞추어 져야 크기에 맞출수 있을것 같다.
앞의 방법보다는 좀 낫긴 하지만 이 방법에도 확실히 문제가 있다.
하지만 이런 방식으로 실제 구현해서 사용하려고 하면 더 큰 문제에 부딪히게 된다. 인풋파일의 경우 파일을 선택했다가 올리기가 싫어지면 그냥 지워주면 되는데 여기서는 편법을 써서 인풋텍스트를 눈앞에 보여주었기 때문에 지워도 인풋텍스트만 지워질뿐 실제 인풋파일의 내용이 지워진것이 아니다. 결국은 아예 한번 선택하면 지우지 못하도록 막아주던가(이렇게 할수는 있지만 기존의 사용자경험을 깨버린다고 생각하기에 별로 하고싶지 않았다.) 인풋텍스트의 값을 지우면 인풋파일의 값도 지워줘야 한다.
그럴려면 천상 스크립트로 값을 지워져야 하는데 보안문제 때문에 인풋파일은 스크립트가 값을 바꿔버리는 것을 허용하지 않는다. 다른거에 하던 식으로
document.getElementById("file").value = "";
는 아예 먹지도 않는다. 대신에...
- document.getElementById("file").select();
- //document.execCommand('Delete');
- document.selection.clear();
위와 같은 자바스크립트 코드를 이용하면 해당 인풋파일의 값을 지워줄 수 있다. 2번줄에 주석처리한 부분은 3번줄 대신 2번줄을 사용해도 된다. 둘줄 하나로 하면 된다. 물론 이 소스
(어찌된 일인지 글을 여기까지만 작성된채 공개됐다. 그럴리가 없는데 약간의 문제가 있었던듯.. 기억을 더듬어 글을 마무리 한다. 2008.7.17)
도 돌아가지 않는다. 위에 말한대로 보안문제 때문에 submit()할 때 문제가 생긴다.
인터넷을 찾아보다 보면 CSS를 이용해서 수십줄로 바꾸는 것도 있긴 한데 해보진 않았다. 버튼 하나 바꿀려고 여러문제는 가지게 되거나 아니면 수십줄의 코드를 넣는게 과연 의미가 있을까 하는 생각이 든다.
차라리 그 노력이면 요즘 게시판 등에서 많이 하는 추세대로 플래시 컴포넌트를 이용해서 바로바로 파일을 올릴수 있게 만드는 것이 훨씬 좋은 선택이라고 생각된다. 찾아보기 버튼은 왠만하면 그냥 쓰자.
제목이 좀 거창하기는 한데(ㅡ..ㅡ) 을 아예 이해를 못한채 개발된 코드를 좀 보게 된다. 개발이라는 것이 순수 자기 머릿속에 있는 것만 가지고 처음부터 끝까지 개발하는 사람이 어디 있겠는가... 요즘 같으면 개발능력이 검색 능력이라고 농담할 정도로 소스가 인터넷에 널려있고 그걸 갔다가 잘 조합하다보면 그럭저럭 돌아간다. 또한 사수나 이전에 구축되어 있는 사이트들도 있고.... 근데 여기서 돌아가는 동작을 이해하지 못하면 결국 잘못된 소스가 나올 경우가 많다.
실용주의 프로그래머에 보면 "디버깅을 하지 못하는 것은 원래 어떻게 돌아갔는지 몰랐기 때문이다."라는 말이 있다. 철저히 공감한다.
최근에 본 소스에 대해서 얘기를 해보려고 한다. 머 그녀석이 작성한 소스는 아니었지만 이런 내용을 보면 프로젝트의 일원으로써 기분나쁠수도 있지만 머 잘못된 것은 잘못된거다. 약간 상황상 초기단계에도 그 프로젝트의 소스를 좀 보았었는데 초반에도 많이 잘못된 부분이 있었는데 내가 관여할 상황이 아니기 때문에 그냥 나뒀다. 몇달만에 다시 보았을때는 괜찮은 사이트의 모습을 갖추고 있었지만 내부는 영 부실했다. 로그인 체크가 이런식으로 되어 있었다.
- if (isLogin) {
- // 로그인되었을 때의 동작
- } else {
- // 로그인 안되었을때의 동작
- }
동작은 중요하지 않으므로 그냥 한글로 처리했다. 아이디/패스워드를 입력하면 서블릿을 호출해서 결과값을 xml로 가져와서 파싱한다. 그리고 결과값을 isLogin에 넣어서 로그인 여부를 보여준다. 아마 작성자는 로그인을 하지 않았을때 권한이 없는 메뉴에 대해서 페이지가 넘어갔다가 오는 것도 낭비라고 생각한것 같다. Ajax로 할때 많이 하듯이 로그인 처리도 현재 페이지에서 바로 처리했고 권한이 없는 메뉴에 대해서 isLogin이라는 자바스크립트 변수로 접근하지 못하게 막고 있다.
이건 완전히 잘못됐다. 이건 브라우저 주소창에 다음과 같은 한줄만 입력하면 isLogin의 값을 접속자 맘대로 바꿔버릴 수 있다.
javascript:isLogin=true;void 0;
정확히는 모르겠지만 내가 보기엔 이건 해킹도 아니고 XSS(크로스 사이트스크립팅)도 아니다. 그냥 잘못만든거다. 보안 문제는 서버쪽에서 체크해야지 클라이언트단이 자바스크립트에서 하겠다는 생각은 잘못 된것이다.(물론 자바스크립트에서도 신경써야하는 보안문제가 있지만...) 자바스크립트는 유저 편의성과 HTML강화를 위해서 제공하는 것이지 자바스크립트로 모든 걸 다 할 수는 없다. Ajax를 쓰다보면 자바스크립트에서 처리해야 하는 부분도 있지만 이부분은 UI를 위한 부분이지 검증을 위한 부분이 아니기 때문에 검정을 Javascript에 의존하지 말고 당연히 서버쪽에서도 재확인 해주어야 한다.
여기서 또하나를 보자
- <script type="text/javascript">
- var usrId = "<% session.getAttribute("userId") %>";
- if (userid != null) {
- 로그인에 대한 동작
- } else {
- <% <STRONG>session</STRONG>.<EM><STRONG>remove</STRONG></EM>("userId"); %>
- <% <STRONG>session</STRONG>.<EM><STRONG>remove</STRONG></EM>("memberType"); %>
- }
- </script>
위 코드가 로그인하고 메뉴에 들어간 페이지에 들어있던 자바스크립트 코드이다. 무엇이 잘못된지 알겠는가.... 해당부분만 잘라온 라서 약간 헷갈릴수도 있지만 이건 JSP와 자바스크립트의 동작을 전혀 이해하지 못한 것이다. 그냥 보면 뭘 하고 싶었는지 까지는 이해할 수 있다. 세션에 값이 있으면 로그인하고 세션에 값이 없으면 로그인에 문제가 있었다고 생각하고 세션을 초기화 해주겠다는 것이다. 결론적으로 이 코드는 돌아가지 않는다.
아주 단순한 원리인데 인터넷에서 사람들이 질문하는 것을 봐도 이걸 이해하지 못하는 사람들을 꽤 많이 볼 수 있다.
이게 간단히 요약한 동작방식이다. 위에서 보듯이 jsp코드와 자바스크립트는 그 수행시점과 장소가 완전히 다르다. 그 순서로 보면 저위의 코드는 if문의 참여부의 상관없이 무조건 session.remove()가 동작한다. WAS는 jsp의 <% %>안에 있는 스크립틀릿 코드만 수행하지 그 외의 부분은 전혀 신경쓰지 않기 때문에....
그렇기 때문에 저 사이트는 첫페이지에서 세션을 심고는 두번째 페이지에서 무조건 세션을 날려버린다. 이런 동작방식을 이해하고 있어야 개발할 때 헷갈리지 않고 많이 나오는 질문중에 하나인 자바스크립트의 변수에 있는 값을 jsp의 변수에 넣으려고 하는 것이 불가능한지를 이해할 수 있다. (물론 js와 jsp간에 서로 값을 주고 받을 수 있는 프레임워크는 존재하지만 여기선 그 얘기가 아니므로....)
항상 어디서나 기본적인 개념이 중요하다는 생각......
window.open(URL, 윈도우명, 옵션);
이라고 하면 팝업을 띄울 수 있다. 네번재 파라미터도 있는데 네번째 파라미터는 이미 존재하는 창의 이름을 지정할때만 사용하며 브라우저 열어본 페이지 목록에 덮어씌울 것인지 새로 추가할 것인지를 지정한다. 기본값인 false는 새로 추가하는 것이다.
ex) window.open("http://blog.outsider.ne.kr", "" , "width=800,height=600,toolba=no");
dependent 부모의 종속된 윈도우를 연다(부모 닫으면 같이 닫힌다.)(no)
directories 개인북마크 or 링크바를 표시(yes)
height 높이(Min 100px)
width 넓이(Min 100px)
top 팝업의 위쪽 위치
left 팝업의 왼쪽 위치
menubar 메뉴바 표시 여부
toolbar 툴바 표시여부
location 주소표시줄 표시 여부
status 하단 상태표시줄 표시여부
resizable 크기변경 여부
scrollbars 스크롤바 표시 여부(내용이 창보다 클 경우)
modal 모달윈도우를 연다
minimizable 윈도 최소화 버튼 추가
window.open()은 해당 윈도우 객체를 리턴한다. 그러므로 팝업을 열고 팝업창을 제어하려면 객체로 받아서 핸들링 해주면 된다.
var popup = window.open("http://blog.outsider.ne.kr", "" , "width=800,height=600,toolba=no");
popup.moveTo(0,0);
moveTo() 창의 좌측 상단 모서리를 지정된 좌표로 이동
moveBy() 창을 지정된 픽셀 수만큼 상하좌우로 이동
resizeTo() 창의 크기를 절대적인 크기로 조절
resizeBy() 창의 크기를 상대적인 크기로 조절
focus() 창을 활성화한다
blur() 포커를스를 잃게 한다.
close() 창을 닫는다.
자신을 닫을 때는 window.close()나 self.close()를 사용하면 된다. 팝업에서 부모창에 접근하려면 opener를 이용하면 된다. 또한 name프로퍼티를 이용해서 target으로 사용할 수 있다.
popup에 관련해서 몇가지 보안관련 사항들이 있는데 자바스크립트는 자신이 연 창만 다시 닫을수 있고 다른 창을 닫으려면 사용자의 승인이 필요하다. 보이지 않는 팝업을 띄워서 악의적인 사용을 막기 위해서 너무 작은 크기(보통은 100px미만)로 축소할 수 없고 화면밖으로 이동시킬 수 없다.
팝업에 대한 자세한 정보는 모질라의 Dom Reference
 에 자세히 나와있다
에 자세히 나와있다퍼블리셔라는 영역이 생기면서 약간 애매해 진것은 사실이지만 퍼블리셔를 따로 두고 있는 회사는 그렇게 많아보이지 않는다. 일단 웹표준을 지키려고 하는 회사도 그리 많지 않지만... 어쨌든 이전의 방식과 호환성을 가지기 위해 사용하던 HTML 4.01이 지나 이제는 XHTML 1.0으로 가는게 맞다고 생각하고 있다. 논쟁을 하고자 하는 건 아니고 새기술이 좋다고 생각하는 전제를 깔고 있고 더 엄격한 규칙을 가지고 더 좋은 웹을 만들수 있는 것은 확실하다.
XHTML을 사용하기 위한 문서의 기본 구조는 전에 올린 XHTML 1.0 Transitional 문서 템플릿 포스트를 참고하고 여기에 적용되는 몇가지 XHTML의 규칙을 설명하고자 한다. 이 규칙들은 이전 HTML에서는 유효했지만 XHTML에서는 유효하지 않은 규칙들이다. 정의된 문서를 먼저 설명하면(위 템플릿 참고)
XHTML은 DOCTYPE을 무조건 선언해 준다. 이 문서가 어떤 문서인지를 정의 하는 것은 반드시 해야하는 것이고 DOCTYPE없으면 XHTML 유효성 검사를 할 수 없다.(HTML 4.01에서도 반드시 쓰라) 브라우저는 DOCTYPE이 있으면 표준모드로 없으면 호환모드로 돌아간다. XHTML은 Transitional, Strict, Frameset 3가지 DTD가 있는데 유연한 Transitional이 과도기인 현재로써는 가장 맞다고 생각한다. Strict는 상당히 쓰기가 어렵고 Frameset은 써본적도 없고 써보려고 해본적도 없다. 그리고 DOCTYPE은 HTML문서의 최상단에 있어야 한다.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.0 Transitional
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Frameset
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
XHTML 1.1 Strict
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
참고)그 다음에는 네임스페이스를 선언해 주는데 그냥 위 템플릿이라는 포스팅에 써진대로 복사해서 쓰면 된다.
XHTML에서 지켜야 할 몇가지 규칙을 정리해보자.(W3C 문서 참고
)모든 태그는 소문자로 적는다. 과거에는 대문자로 쓰는게 일반적이었지만 XHTML에서는 반드시 소문자로만 작성해야 한다. 단 속성값이나 내용은 대소문자에 상관없다.
<body><body> - (O)
모든 속성값은 인용부호 안에 사용하고 속성들 사이에는 띄어쓰기를 해야한다.
<img src="banner.gif" alt="배너" /> - (O)
모든 속성에는 값이 있어야 한다. 값을 지정안하고 선언하는 속성들이 있었지만 XHTML에서는 보기에는 어색하더라도 모두 속성을 지정해 주어야 한다.
<input type="text" readonly="readonly" /> - (O)
모든 태그는 닫아준다. 이전에는 안닫아주었지만 모든 태극는 닫혀햐 한다. 여는 태그가 있으면 닫는 태그가 있어야 하고 단독적으로 쓰이는 태그(img, input, br 등등)도 반드시 닫아준다. 보통 단독태그에 닫아주는 표시를 할때는 슬래시(/)앞에 한칸을 띄워준다.
<p>내용</p> - (O)
<br> - (X)
<br /> - (O)
주석안에는 더블대시를 사용하지 않는다.
<!--====================--> - (O)
모든 <와 &는 변환을 해주어야 한다. 내용중에 <, &는 < 와 & 로 바꾸어 주어야 한다.
<div>you & me < test</div> - (O)
id 사용 - 링크태그의 타겟으로 사용되던 name을 대체한다.(하위호환을 위해 name도 동시 사용)
모든 img태그에는 alt태그를 반드시 사용해 준다. alt는 이미지를 보여주지 못할때 이미지를 대체해서 보여줄 대체택스트로 이미지에 대한 설명을 뜻한다. 브라우저가 툴팁으로 보여주어서 잘못 사용하고 있기는 하지만 툴팁은 title속성을 사용하여야 한다.
좀 다른 얘기로 스크립트 얘기를 하자만 한 문서에는 여러 스트립트가 가능하므로 기본적인 사용 스크립트를 메타태그를 이용해서 지정할 수 있다.
<meta http-equiv="Content-Script-Type" content="text/javascript">
라고 작성하면 된다 보통 이 메타태그가 없으면 브라우저는 자바스크립트가 기본이라고 생각한다.
<script type="text/javascript"></script> 가 정상적이다. MIME타입으로 text/script가 많이 사용된다는 이유로 RFC 4329가 승인했다. application/javascript를 더 권장하고 있지만 실제 브라우저에서 잘 지원되지 않고 있다. 또한 스크립트 코드에 language="javascript"로 작성된 것을 많이 볼 수 있는데 이것은 type이 지원되지 않을 때의 잔재인데 하위 호환성을 위해서 사용할 수도 있다.
참고로 CSS의 경우는
<meta http-equiv="Content-Style-Type" content="text/css" />
코드를 통해서 문서의 CSS스타일을 정의할 수 있다.
아래 부분은 XHTML에 해당되는 내용은 아니지만 XHTML을 사용할 때 구조적인 HTML을 구성하려는 의도가 더 강하다고 생각했을 때나 웹접근성을 생각했을 때 고려해야 할 부분
- <b>보다는 <strong>를, <i>보다는 <em>을 사용한다.
- 텍스트의 경우는 div가 아닌 <p> 태그를 사용한다.
- 해드라인의 경우 div에 적당한 클래스를 주는 것이 아니라 <h1>, <h2>태그 등을 사용한다.
- table태그에는 summary 속성을 지정할 수 있다. 대부분의 브라우저는 summary를 보여주지 않지만 시각장애인용 스크린리더등에서는 summary를 읽어준다.
- 태그에 accesskey 속성을 주면(ex: accesskey="1") 사용자가 단축키로 사용할 수 있게 해준다.(하지만 대부분의 브라우저는 이를 사용자에게 보여주지 않기 때문에 사용법에 대한 것을 따로 알려주어야 한다.)
- tabindex를 사용하면(ex: tabindex="1", tabindex="2") 사용자가 탭을 눌렀을 때 옮겨지는 form 컨트롤를 지정할 수 있다. tabindex가 없으면 소스에 나와있는 순서로 옮겨진다.
<a href="#"><img src="경로" alt="" /></a>
이런 형태이다. 나도 회사처음 들어왔을때 내 바로 윗사람이 이렇게 쓰는것을 권고하기도 했었고 대부분의 사람들이 이런 형태로 이미지 버튼을 만들고 있는데 이건 정말 잘못된 형태의 html이다. 무엇보다 이렇게 써서 얹을 수 있는 잇점이 단 한개도 없다고 생각한다.
저렇게 허위 a태그를 거는 상황은 100% 이미지를 버튼으로, 즉 클릭용으로 사용하기 위함이다. 그래서 img에 onclick 속성을 사용하고 있다.
<a href="#"><img src="경로" alt="" onclick="clickBtn();" /></a>
이렇게 이벤트까지 추가된 형태가 일반적이다.(물론 onclick도 인라인으로 하지 않고 따로 빼는게 표현과 기능의 분리면에서 더 낫기는 하지만 이건 여기서 논할 얘기는 아니니...) IMG태그 만으로도 클릭은 되는데 굳이 이렇게 A태그를 걸어준 단하나의 이유는 다른이미지랑 다르게 버튼처럼 보이게 하기 위해서 이다. 즉 이미지위로 마우스 커서가 이동했을때 클릭이 가능하다는 걸 사용자에게 알려주기 위해서 마우스 커서가 화살표에서 손모양으로 바뀌게 하기 위함이다. 그냥 이미지태그만 있어도 되는걸 커서바꾸자고 a태그로 감싸버린 것이다.
그럼 이렇게 하면 끝이냐... 브라우저마다 특성이 있긴 하지만 기본적으로 이미지에 A태그를 걸면 IE에서는 보기싫은 파란색의 테두리가 생겨버린다. 하이퍼링크가 달렸다는 것을 알려주기 위해서인데 요즘은 이걸 쓰는 사람이 없기 때문에 대부분은 border="0"을 주어서 해결한다.
<a href="#"><img src="경로" alt="" onclick="clickBtn();" border="0" /></a>
그럼 코드가 이렇게 되어버린다. 이미지버튼하나인데 코드가 너무 길어져버렸다. 단지 커서 바꾸자고???
이건 CSS를 사용하면 금방 해결할 수 있다.
- <style>
- .btn {cursor:pointer;}
- </style>
- <img src="경로" alt="" class="btn" onclick="clickBtn(); />
커서의 모양을 바꾸는 것은 스타일로 해버리면 된다. (보통은 img에도 border:0을 기본적으로 주기는 하지만 이 상황에서 꼭 필요한건 아니다.) 그리고 심플한 img태그만 사용하면 된다. CSS를 사용한게 훨씬 많아 보인다면 웹사이트에 버튼이 한 100개쯤 있다고 생각해봐라. CSS는 공통적으로 쓸수 있으니 이미지 태그부분만 작성하면 끝이다.
A태그를 이미지를 감싸줄 필요가 없음을 얘기했고 그냥 하던대로만 하기에도 A태그를 사용했을 때의 문제가 있다. 좀 원론적인 웹표준얘기대로 A태그는 하이퍼링크를 위한 것이기 때문에 A태그는 하이퍼링크만 사용해 주는 것이 좋다. 이건 머 웹표준을 동의하지 않는 사람들에게는 그리 통하지 않을 논리고....
A태그의 구조를 보면 Anchor를 사용한 것임을 할 수 있다. Anchor는 다들 알고 있을꺼라고 생각하지만 간단히 설명하자면
<a href="#title">제목으로 이동</a>
........중간내용.............
<h3 id="title">제목</h3>
과 같이 사용하는 것이 Anchor이다. #과 같이 사용하며 #이 있으면 해당경로로 페이지를 이동시키는 것이 아니라 현재페이지에서 해당 id를 가지고 있는 엘리먼트를 찾아서 이동한다. 이걸 이용해서 #은 주고 id는 null을 주어버린 것이다. 그래서 페이지는 다른페이지로 이동하지 않고 현재 페이지에서 Anchor를 찾지만 찾지 못하는 허위 Anchor를 사용한 것이다.
말했듯이 Anchor는 현재 페이지의 해당위치로 이동하는데 이건 스크롤이 있어도 이동된다. 여기서 문제가 발생하는데 href="#"을 해 놓으면 무조건 페이지 최상단으로 이동한다. 이미지 버튼이 윗쪽에 있을 경우에는 상관없지만 스크롤 내려서 아래에 있다고 생각하면 버튼을 누를때마다 페이지 스크롤은 맨위로 올라가고 다시 스크롤 내려서 다른걸 해야하는 사용자의 편의성을 무진장 해친다...
거기에다가 Anchor도 URL에 포함되기 때문에 저 버튼을 누르면 주소맨뒤에 #가 붙게 된다. 크게 문제가 있다고 할 수는 없지만 보기에 좋지 않은건 사실이다. 그리고 자바스크립트 펑션을 호출해서 location.href로 페이지 이동만 할꺼라면 그냥 A태그에 경로를 주자!!
별거 아닌 내용으로 은근 길게 작성해 버렸다. 그냥 작업하는데 버튼마다 계속 A태그 달려있는거 보다가 짜증나서.. ㅎㄷㄷ
덧) 약간은 도전적인 제목이었는데 역시나 내 영역은 아니라 약간의 논란이 있었다. 보통 작성뒤에 잘못된 내용은 빨리 수정하는 편이지만 이번에는 애매모호한 면이 있어서 이 포스트를 읽으시는 분들은 아래 댓글들도 꼭 읽어주시기 바람. 위에 얘기한대로는 링크이동이 아닌 버튼의 경우에 a를 안쓸경우 선택할때 점선이 생기지 않아서 접근성을 해칠우려가 있음. 명확한 결론을 내리기 어려운 관계로 나라디자인의 정찬명님의 포스트
를 참고로 건다. 많이 고민해 보아야 할 문제... 2008. 11. 11다. 전에부터 한번 하려고 했는데 IDE를 소개한다는 것은 기능이 워낙 많기 때문에 만만치 않은 일인데 머 간단히 소개정도만 하고 그 뒤로는 새로운 기능파악할 때마다 포스팅해야할 듯 하다.(전체소개 없이 각 기능 소개하기도 좀 머해서....)
제목에는 클라이언트 사이드 IDE라고 소개하기는 했지만 이곳에 중점이 되어 있을 뿐 PHP, Python도 개발이 가능하다. RadRails라고 해서 플러그인을 깔면 Ruby on Rails개발도 할 수 있다. 툴을 이것 저것 써보았지만 클라이언트 사이드(자바스크립트, CSS, HTML)에서는 aptana Studio만큼 맘에 드는 것을 아직 발견하지 못해서 클라언트사이드 개발에는 메인 IDE로 사용하고 있다. (흔히 괜찮은 자바스크립트 에디터가 없다고 하는데 aptana Studio는 그 이상이다.)
aptana사이트에서 다운로드
를 받을수 있고 무료이기 때문에 맘편히 사용할 수 있다. 초기에 나올때는 Communication버전과 Pro버전이 나뉘어져 있었는데 이번에 보니까 커뮤니케이션 버전이라는 말은 아예 사라진듯하다. 기본적으로 무료로 이용할 수 있도록 제공하고 있고 추가 기능이 필요한 사람들을 위해서 aptana Studio Pro(Pro의 추가 기능 )를 위한 구매메뉴를 제공하고 있다. (Jaxer와 Cloud도 있는데 둘다 사용해 보지는 않은데 내가 대충 개념잡기로는 Jaxer는 서버이고 Cloud는 호스팅서비스 같은거다.)08년 12월 31일 현재 1.2.1버전까지 나와있고 Standalone과 Eclipse 플러그인 2가지 타입으로 다운을 받을 수 있다. 난 Standalone타입을 선호하는 편인데 취향에 따라 쓰면 되겠다. OS는 Windows, Linux, Mac을 모두 제공하고 있다. Linux나 Mac에서는 안서봤지만 다양한 플랫폼을 지원한다는 것은 무조건 좋은거다.. ㅎㅎㅎ 현재는 Standalone로 풀인스톨러로 받으면 130MB정도 한다. 다운받아서 그냥 설치해주면 된다.

자바개발자라면 너무나도 익숙한 인터페이스이다. 위에서 플러그인 형태로 제공하는 걸 보고 눈치챘겠지만 Aptana Studio는 오픈소스 IDE인 Eclipse
를 가지고 만든것이기 때문에 이클립스와 거의 흡사하다. 이클립스기반이기 때문에 이클립스가 요구하는 Requirements 는 그대로 요구하고 있다. 1.5이상의 JRE가 필요하다는 얘기이다. 자바런타임환경만 있으면 달리 구성할 환경은 별로 없다.나는 툴 사용의 효율성에 관심을 많이 가지고 있는데 개발의 속도를 높이려면 툴의 익숙함이 상당히 중요하다고 생각한다. 그런면에서 이클립스를 사용하는 개발자라면 서버사이드와 클라이언트 사이드의 개발툴이 통일화되어서 따로 익숙해지는 과정이 필요없다는 것은 매우 큰 장점이다. 물론 이클립스를 쓴다면 특별히 클라이언트사이드의 코딩이 엄청나지 않는 이상은 이클립스에서 코딩하기도 하지만 지원하는 면에서 비교가 안된다고 생각한다. 나도 일일이 벌갈아가면서 하지는 않지만 aptana Studio의 기능이 이클립스에서 안되서 답답한 적이 많다.(물론 플러그인형태로도 제공하니까 플러그인을 쓰면 된다.)
그리고 또하나의 장점은 이클립스에서 사용하는 플러그인을 그대로 사용할 수 있다는 것이다. 오픈소스 이클립스를 지원하는 방대한 양의 플러그인의 규모는 엄청난데 SVN, MyLyn등등 그대로 다 쓸수 있는 것이다.
그럼 aptana Studio의 몇가지 기능을 살펴보자. 머 거창한건 아니고 간단한 기본기능들 위주로....이클립스를 안써본 사람도 있겠지만 기본적인 프로젝트 생성같은거는 이클립스랑 동일하기 때문에 굳이 언급하지 않겠다.
IDE의 기본 기능이면서도 개발자에게 가장 크게 와닿는 것중 하나가 코드 어시스트이다. 클라이언트 사이드에서 aptana Studio가 제공하는 코드어시스트는 강력하다. 많은 툴을 다뤄본 것은 아니지만 내가 만져본 것들 중에는 aptana Studio가 제공하는 코드 어시스트가 가장 강력한것 같다.
 |
 |
 |
html, CSS, javascript할 꺼 없이 거의 완벽하게 코드어시스트를 제공해주고 있다. CSS경우는 각 속성에 대한 이름뿐만 아니라 사용할 수 있느 값들까지도 제공하고 있으면 자바스크립트의 경우는 키워드, 함수명, DOM을 다 제공해 줄뿐만 아니라 위의 이미지처럼 사용자가 만든 function까지도 파라미터값까지도 보여준다. 사용할수 있는 키워드를 타이핑할 때마다 직관적으로 보여주고 그 오른쪽에는 지원되는 브라우저가 아이콘으로 표시되기 때문에 크로스브라우징에 맞추어서 개발하는데 정말 편하다. 오른쪽에는 해당 키워드에 대한 간단한 설명까지 나오기 때문에 부족함이 없을 정도이다.
html, css, javascript에서 자주 사용하는 엘리먼트를 바로 추가할 수 있도록 상단에는 아이콘들이 있는데 마우스를 써야 되니까 잘 쓰게 되지는 않는것 같다. ㅎ

코드 어시스트에서 보여주는 브라우저 호환에 대한 부분은 [window] - [Preferences]에 들어가서 [Aptana] - [Browsers/User Agents]에서 설정해 줄 수 있다. 여기서 필요한 브라우저를 체크할 수 있다. (아직 크롬은 없다. ㅎ) 이렇게 설정하면 아래처럼 선택한 브라우저의 호환성을 코드어시스트에서 제공 받을 수 있다.

위에서 본 에디터 부분에서 기본적으로 소스창을 보지만 따로 브라우저를 띄우지 않고 aptana Studio안에서 IE와 FF에서 미리보기를 해 볼 수 있다.
아래쪽 탭을 선택하면 바로 볼 수 있으면 추가를 누르면 미리보기 셋팅을 추가해 볼 수 있다.(현재는 브라우저는 IE, FF만 제공하고 있다.) 여기서 볼때도 스크립트 에러가 나는 경우는 바로 표시가 된다.
CSS파일을 만들때도 preview를 제공하고 있는데(HTML에 들어가는 스타일부분 말고 확장자가 .css로 된 파일들....)
CSS파일을 편집할때는 하단쪽 탭이 Preview로 나오게 되는데 실제 html에 적용된걸 보려면 html을 실행시켜서 봐야하기는 하지만 내가 작성한 css를 바탕으로 기본으로 제공되는 텍스트를 통해서 각 엘리먼트가 어떤식으로 보여지는 지를 간단하게 미리볼 수 있다. 오른쪽 톱니바퀴 아이콘을 눌러서 Edit Default preview template를 누르면 CSS preview에서 제공하는 텍스트를 수정해서 사용할 수 있다. file preview setting을 클릭해서 현재 프로젝트의 html파일을 선택해주면 프리뷰를 원하는 형태로 볼 수도 있다.

그리고 이게 코드어시스트말고 내가 aptana Studio를 좋아하는 큰 이유중 하나인데 html파일에서(jsp, asp, php같은 서버측코드는 해석할 수 없으므로...) Run AS - JavaScript Web Application을 시작하면 aptana Studio 내부의 Jaxer서버가 시작되면서 해당 페이지를 구동시켜준다.(정확히는 프로젝트째..)
http://127.0.0.1:8000/Test/new_file.html 와 같은 형태의 주소로 구동되기 때문에 주소를 이용해서 다양한 브라우저에서 쉽게 테스트해볼 수 있다. 수정하면 바로바로 확인해 볼 수 있고 프로젝트 이름이 붙기는 하지만 적대주소도 사용할 수 있기 때문에 아주 유용하다. ㅎㅎ

Run As에서 Run을 눌러서 설정창을 띄우면 서버실행할 때 자동으로 구동시킬 웹브라우저 및 여러가지 설정사항을 지정해 줄 수 있다.
이렇게 개발하는데 도움이 될만한 대략적인 기능들을 살펴봤다. IDE이기 때문에 그 기능은 엄청나고 많이 알면 알수록 개발의 효율은 높아질 것이다.
이외에도 클라이언트사이드개발을 위해서 많은 기능들을 가지고 있다.
프로젝트를 생성할 때 다양한 자바스크립트 프레임워크들을 선택해서 기본적으로 프로젝트에 포함 시킬수 있고 FTP연결연결하거나 Outline뷰에서 DOM트리를 보거나 js파일에서 함수구조를 본다던가 하는 등 많은 기능을 가지고 있다. aptana Studio 짱좋아.. ㅎㅎㅎ
가 나왔다는 기사가 떴길래 겸사겸사해서 정리해서 올린다.자바스크립트 압축(Minification)이란 것은 보통 자바스크립트 코딩을 할 때 가독성을 위해서 들여쓰기등 공백이 많이 들어가게 되어 있는데 이런 것을 없애고 코드를 다닥다닥 붙혀서 크기를 줄여주는 것이다. 압축은 말그대로 크기를 줄여주는 것이고 암호화(obfuscation)라는 것도 있는데 이것은 변수나 함수명을 이상하게 바꾸어서 코드를 읽기 어렵게 만든다. 당연히 둘다 함께 할수도 있다.
하지만 암호화의 경우는 자바스크립트의 특성상 약각 읽기만 어렵게 만들어 놓은것 뿐이고 해독툴들을 써서 다시 어느정도 보기좋게 할 수도 있기 때문에 결과적으로 암호화라는 큰 의미는 없다. "웹사이트 최적화 기법"을 보면 사이즈면에서 압호화의 효과는 미비하기 때문에 별로 추천하고 있지 않고 있는데 선택은 각자 나름이고 혹 관심이 있다면 YUI의 글
을 참고바란다.내가 아는 것으로는 3가지 서비스가 있다.
JSMIN
JSMIN
부터 보자. 자바스크립트계의 요다라고도 불리는 JSON 을 창시한 더글라스 크록포드(Douglas Crockford)가 만든 JavaScript Minifier이다. 
JSMIN은 JS파일을 압축하는 기능을 가지고 있는 간단한 프로그램(?)형태로 제공되고 있다. 위에 보는다와 같이 사이트에서 다양한 언어로 제공되고 있기 때문에 취향에 따라서 가져다가 사용할 수 있다. 일반적인 윈도우 환경에서는 MS-DOS.exe형태로 배포되는 JSMIN을 가져다가 사용하면 된다.

JSMIN.EXE를 받아서 js파일이 있는 곳에 놓고는 위와같이 실행하면 된다. 명령어는
와 같은 형태로 사용하면 된다. 뒤에 주석부분을 적지 않아도 되고 적을 경우는 새로만들 js파일 최상단에 주석에 넣은 부분이 주석형태로 추가된다.
- /*********** before Minification **************/
- var checker = false; // 체커
- function test() {
- alert(checker);
- }
- test(); // 실행
- /*********** after Minification **************/
- var checker=false;function test(){alert(checker);}
- test();
JSMIN으로 prototype.js를 압축한 모습이다. 보는바와 같이 주석과 공백등은 모두 없애고 특정단위별로 한줄씩 적어주어 용량을 줄여주고 있다.
/packer/
Dean Edwards
가 만든 자바스크립트 압축기 packer 이다. 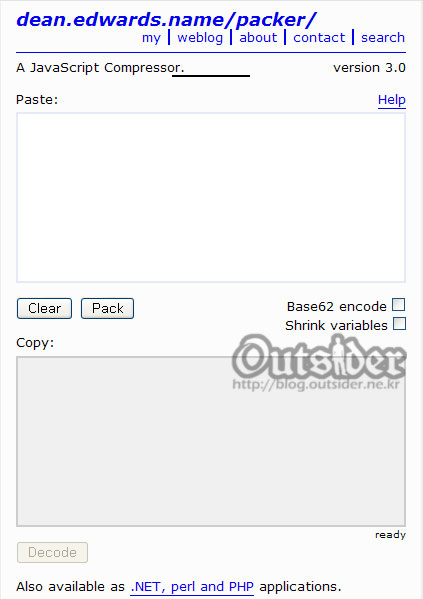
웹상에서 간단하게 사용할 수 있다는게 큰 장점이고 옵션으로 Base62 압호화와 변수이름 축소(Shrink variables)를 적용할 수 있다.
- /*********** before Minification **************/
- var checker = false; // 체커
- function test() {
- alert(checker);
- }
- test(); // 실행
- /*********** after Minification **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Base62 encode **************/
- eval(function(p,a,c,k,e,r){e=String;if(!''.replace(/^/,String)){while(c--)r[c]=k[c]||c;k=[function(e){return r[e]}];e=function(){return'\\w+'};c=1};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p}('2 0=3;4 1(){5(0)}1();',6,6,'checker|test|var|false|function|alert'.split('|'),0,{}))
- /*********** after Minification : Shrink variables **************/
- var checker=false;function test(){alert(checker)}test();
예제소스가 짧아서 Shrink variables가 차이가 없게 나타나버렸다 ㅡ..ㅡ 암호화는 코드읽는 능력이 좋아서 읽을수 있다면 어쩔수 없지만 저 간단한 코드를 도저희 머하겠다는 건지 모를 코드로 만들어 놓았다. 하지만 딘에드워즈가 친절하게 unpacker
도 만들어주었고 변수이름까지 고대로 잘 디코딩 된다는거~~YUI Compressor
Yahoo User Interface Library에서 제공하는 YUI Compressor
이다. jar파일 형태로 제공되고 있고 사용하려면 자바 1.4이상이 필요하다. 그냥 사용하기는 좀 불편한것 같고(사용까진 안해봤다.) 이걸 이용해서 만든 서비스들이 있다.
이 포스팅의 계기를 만들어 준 Rodolphe STOCLIN
가 만든 YUI Compressor Online 이다. 깔끔한 인터페이스에 얼마나 압축이 되었는지도 시각적으로 표시해 준다. - /*********** before Minification **************/
- var checker = false; // 체커
- function test() {
- alert(checker);
- }
- test(); // 실행
- /*********** after Minification **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Minify only, do not obfuscate **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Preserve all semicolons **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Disable all micro optimizations **************/
- var checker=false;function test(){alert(checker)}test();
먼 차이냐 ㅡ..ㅡ 소스가 간단해서 그런가... 어쨌든 이녀석은 약간 문제가 있다. 한글이 들어갈 경우는 EUC-KR이든 UTF-8이든 한글이 모두 ?로 깨져버린다. 코드에 한글이 들어가 있으면 사용못한다는 얘기다.
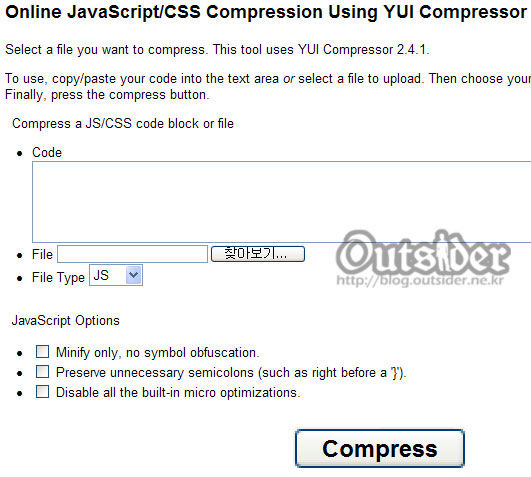
Online JavaScript/CSS Compression Using YUI Compressor
는 디자인이 평이해서 그렇지 완성도가 더 좋은편이다. 웹상에서 직접 압축하는 것과 파일로 하는 것을 모두 지원하면 js뿐만아니라 CSS의 압축까지도 지원하고 있다. 압축후에는 용량이 어떻게 어떻게 달라졌고 몇퍼센트가 달라졌는지 표시해 주고 있다. - /*********** before Minification **************/
- var checker = false; // 체커
- function test() {
- alert(checker);
- }
- test(); // 실행
- /*********** after Minification **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Minify only, do not obfuscate **************/
- var checker=false;function test(){alert(checker)}test();
- /*********** after Minification : Preserve unnecessary semicolons **************/
- var checker=false;function test(){alert(checker);}test();
- /*********** after Minification : Disable all the built-in micro optimizations **************/
- var checker=false;function test(){alert(checker)}test();
여기서는 Preserve all semicolons 옵션이 적용되는군....
한꺼번에 툴을 여러개 소개하다보니 포스팅이 좀 길어지긴 했는데 얼마나 줄어드나 보자. 테스트는 2가지 파일로 했다. 소스를 작성하는 형태가 각자 다르기 때문에 압축률에서도 상황에 따라 달라질것으로 생각한다. 내가 최근 프로젝트에서 만들고 있는 49KB짜리 script.js랑 보편화된 127KB짜리 prototype.js를 가지고 테스트 했다.
JSMIN
script.js -> 36KB/packer/
prototype.js -> 94KB
script.js -> 36KBYUI Compressor Online
script.js -> 22KB (Base62 encode)
script.js -> 32KB (Shrink variables)
prototype.js -> 93KB
prototype.js -> 51KB (Base62 encode)
prototype.js -> 76KB (Shrink variables)
script.js -> 33KBOnline JavaScript/CSS Compression Using YUI Compressor
script.js -> 35KB (Minify only, do not obfuscate)
script.js -> 35KB (Preserve all semicolons)
script.js -> 35KB (Disable all micro optimizations)
prototype.js -> 74KB
prototype.js -> 93KB (Minify only, do not obfuscate)
prototype.js -> 94KB (Preserve all semicolons)
prototype.js -> 94KB (Disable all micro optimizations)
script.js -> 34KB
script.js -> 36KB (Minify only, do not obfuscate)
script.js -> 34KB (Preserve unnecessary semicolons)
script.js -> 34KB (Disable all the built-in micro optimizations)
prototype.js -> 75KB
prototype.js -> 94KB (Minify only, do not obfuscate)
prototype.js -> 75KB (Preserve unnecessary semicolons)
prototype.js -> 75KB (Disable all the built-in micro optimizations)
다양하게 테스트한건 아니라서 절대성능비교라고 하기는 좀 그렇고 그냥 참고용이다.
압축화할때는 조심해야 할게 있다. 보면 약간 걱정되는 것처럼 이게 돌아갈까? 하는 생각인데 생각대로 이건 조심해야 된다. 공백이 없어지는 바람에 소스가 달라붙어서 의도하지 않은 오류가 나지 않아야 한다. 이건 충분히 일어날 수 있는 일이기 때문에 평소 코딩습관을 잘 들이는게 좋다고 생각한다. 더글라스 크록포드는 이런 자바스크립트 검증을 위해서 Javascript Varifier인 JSLint
를 제공하고 있다.압축을 하고 난 다음에는 솔직히 유지보수를 할수 없는 지경이기 때문에 개발소스는 그대로 유지하고 배포할때 압축하는 게 맞는 방법인것 같다. 그래서 다들 Java파일 같은 라이브러리로 쓸수 있는 형태로 제공하는 것으로 보인다.
이렇게 할때 가장 큰 문제가 자바스크립트 초기화 코드이다. 항상 바꿔치기할 contents부분은 <body>의 정중앙에 들어있는데 보통 스크립트는 <head>안에 있거나 <body>맨아래 있단 말이지. contents부분에 들어갈 페이지에 스크립트코드를 같이 써줘도 되기는 하지만 완성된 html에서 중간에 스크립트 코드가 들어가기 때문에 별로 좋은 방법은 아니라고 본다.
여기서 초기화코드라는 것은 머 여러가지가 될수 있는데 쉽게 페이지 로딩후(onload)에 자동으로 수행할 함수를 말한다. 가장 많이 쓰는데 이벤트 핸들러 등록이라던가 하는거고 onload후에 focus를 어디에 둔다던지 하는등의 코드를 말한다. 페이지가 다 다르게 생겼으므로 이런 코드도 다 다를 수 밖에 없는데 contents에 들어갈 페이지에서는 이걸 다룰수가 없다는게 고민거리였다. 물론 if-else문으로 해당 엘리먼트가 있는지 라든가 페이지 주소를 이용해서 억지로 할수야 이겠지만 쓸데없이 검사해야 하기 때문에 성능도 떨어지고 별로 알흠답지 못한 방법같았다. 이벤트 핸들러의 경우 html 엘리먼트에 직접 써넣는게 일반적이지만(<input type="button" onclick="test();"> 이렇게...) 요즘 추세는 자바스크립트도 완전히 분리하는 것이기 때문에 이걸 분리하자면 초기화코드가 꽤 많아진다. (이게 Unobtrusive Javascript.... 이렇게 하면 디자인 바뀌어도 많이 손 안대도 된다. 물론 Unobtrusive Javascript가 말하고자 하는건 저게 중점은 아니지만 개인적으로는 큰범주에서 보면 같은 흐름이라고 생각한다.)
어쨌든 이번에 플젝하면서는 이걸 좀 해결해 보고 싶었기 때문에 OKJSP
에 질문글을 올렸더니 임은천님이 답변 을 해 주셨다.(거의 익명사이트긴 하지만 도움얻은걸 혼자한척 하진 않는다.. ㅡ..ㅡ) 딱 내가 기다리던 명쾌한 답변.... 너무 자세하게 답변을 주셔서 구현하는데 별로 어렵지 않았다.- document.observe('dom:loaded', function() {
- <% if (request.getAttribute("jsDispatcher") != null && !request.getAttribute("jsDispatcher").equals("")) { %>
- var dispatcher = new Dispatcher();
- var jdName = "<%= request.getAttribute("jsDispatcher") %>";
- eval(dispatcher.get(jdName));
- <% } %>
- });
위의 코드를 Template의 부모(?)가 되는 페이지의 스크립트 부분에 넣어준다. 물론 저 코드는 Prototype Framework의 코드이다. 쉽게 가자면 window.onload에다가 이벤트를 건거다. 여기선 JSP코드니까 JSP로 jsDispatcher이 파라미터로 넘어왔는지를 검사하고 jsDispatcher값이 있으면 디스패쳐를 실행한다. 물론 템플릿에 어떤 페이지를 contents부분에 띄워줄지 파라미터로 넘겨줄때 jsDispatcher의 값도 같이 넘겨주어야 한다. 어차피 템플릿으로 구성되는게 구현되어 있을테니까 파라미터 하나 더 넘겨주는건 그리 어렵지 않은 일이다.
디스패쳐가 각 jdName별로 실행할 함수목록을 가지고 있고 파라미터로 넘겨받은 jsDispatcher의 이름으로 디스패쳐에다가 조회해서(get) 해당 실행할 함수들을 가져오고 그자리에서 eval()해서 실행해 버리는거다. 이것 자체가 window.onload때 실행되니까(Prototype.js의 dom:loaded는 약간은 다른의미지만 여기선 별로 중요하지 않다.) 디스패쳐로 가져온 값도 페이지 초기화코드로 실행된다. 물론 여기서 Dispatcher은 이어서 만들 클래스이다. 원래 제공되는게 아니라...
그럼 Dispatcher클래스를 보자.
- var Dispatcher = Class.create();
- Dispatcher.prototype = {
- initialize : function() {},
- get : function(name) {
- return this.map[name];
- },
- map : { listform: 'ListenerCollection.registEventListFrom()',
- writeform: 'ListenerCollection.registEventWriteFrom()',
- modifyform: 'ListenerCollection.registEventModifyForm()'
- }
- }
- var ListenerCollection = {
- registEventListFrom: function() {
- // 리스트 페이지의 초기화 코드들
- },
- registEventWriteFrom: function() {
- // 작성 페이지의 초기화 코드들
- },
- registEventModifyForm: function() {
- // 수정 페이지의 초기화 코드들
- }
- }
여기에는 Dispatcher와 ListenerCollection 2가지 클래스가 있다.(Prototype.js의 관점에서는 Dispatcher만 클래스이지만 그냥 넘어가자.)
Dispatcher클래스는 3가지 매서드가 있다. initialize는 보는바와같이 아무것도 없는데 prototype.js의 클래스에선 필수로 만들어주어야 하는거라서 신경안써두 되고 get하고 map이사용할 메서드이다. map은 넘겨받은 이름과 함수가 쌍으로 맵핑되어 있고 get에서 넘겨받은 name으로 map에서 찾아서 해당 함수를 돌려준다.
ListenerCollection은 등록할 이벤트리스너(꼭 이벤트리스너일 필욘 없지만)의 코드목록을 담는 곳이다. map내애서 funcion(){}으로 바로 적어줄 수도 있지만 코드량이 많아서 분리했다. 약간 꼬아놔서 그렇지 구조는 별로 어렵지 않다.
이렇게 하면 템플릿을 유지하면서도 페이지별로 초기화 자바스크립트 코드를 따로 둘 수 있다. 모든 페이지에서 이코드가 들어가긴 하지만 위쪽에서 onload로 이벤트를 건 곳을 제외하고는 외부 js파일로 빼면 어차피 캐시가 되기 때문에 성능면에서는 별로 신경안써도 될듯하다. prototype.js를 기반으로 작성되서 prototype.js를 안써본 사람은 약간 코드이해에 어려움이 있을까 좀 걱정되긴 한다...
위 코드이 Sortable
을 사용하는 기본 문법이다. id_of_container에 드래그앤드롭을 가능하게 할 엘리먼트의 id를 주고 options에 드래그앤드롭에 대한 옵션을 JSON형태로 던져주면 바로 정렬가능한 드래그앤드롭을 사용가능하다. id_of_container이라고 쓴 것처럼 드래그할 객체가 아니라 드래그할 객체들을 담고 있는 container의 id를 주면 되고 options는 안주면 디폴트옵션으로 동작하게 된다.예를 들어
- <ul id="contailner">
- <li id="dnd_1">Test 1</li>
- <li id="dnd_2">Test 2</li>
- <ul>
- <script type="text/javascript">
- Sortable.create("contailner");
- </script>
위와같이 작성하면 dnd_1, dnd_2객체가 바로 드래그앤드롭이 가능하다. (이 얼마나 간단하단 말인가. ㅎㅎㅎ)
이제 옵션을 보자. 자유롭게 사용하려면 옵션을 주어서 원하는 형태로 사용하여야 한다. 옵션은 Draggable과 공통적인 것도 있고 아닌것들도 있다.(아직 Script.aculo.us의 API리스트는 솔직히 좀 아쉽다.) API와 내가 테스트해본걸 바탕으로 적었지만 빠진 부분이 있을수도 있다.
only : 이 옵션을 주고 여기서 class명을 지정하면 tag에 설정한 태그명이라고 할지라도 only에서 준 class명과 맞지 않으면 드래그앤드롭이 동작하지 않는다.
overlap : 가로 리스트는 horizontal, 세로 리스트는 vertical로 설정하라는데 정확한 동작은 잘 모르겠다.
constraint : horizontal, vertical, false 3가지가 있고 드래그앤드롭의 방향을 설정한다. horizontal/vertical로 설정할 경우에는 가로/세로로만 이동하며 false나 옵션을 주지 않았을 경우에는 어떤 방향이든지 이동이 가능하다.
containment : 이곳에 container 리스트를 지정하고 이곳에 지정한 container간에는 드래그앤드롭이 가능하다.
handle : 드래그앤드롭을 할 엘리먼트에서 전체가 아닌 특정부분만을 이용해서 드래그앤드롭이 가능하도록 하고 싶을때 handle이용한다. 이곳에 id 혹은 class명을 지정하면 핸들러로 사용할 수 있다.
delay : 드래그앤드롭으로 반응할 시간을 미리세컨단위로 설정할 수 있고 기본은 0이다. 너무 민감하게 반응하지 않기를 바랄때는 delay의 숫자를 크게 지정할 수 있다.
dropOnEmpty : true로 설정하면 container가 비어있을때도 drop이 가능하다. false일 경우에는 container에 다른 드래그앤드롭객체가 있을때만 드롭이 가능하다. 기본은 false
scroll : 기본으로는 지정되어 있지 않으며 window로 설정할 경우에는 드롭할 container가 화면밖에 있을경우에 드래그객체가 화면밖으로 나가면 자동으로 스크롤한다.
scrollSensitivity : 기본은 20이고 스크롤이 되게 하기 위해서 넘어가야하는 크기를 지정한다.
scrollSpeed : 스크롤 속도이고 픽셀로 지정하면 기본은 15이다.
onChange : 콜백함수로 드래그앤드롭을 시작하는 등 객체의 위치가 변경되면 계속 발생한다.
onUpdate : 콜백함수로 드래그앤드롭을 하여 실제 순서의 변화가 생겼을때만 발생한다.
아주 간단한 예제를 만들었다. 동작과 소스코드를 보면 쉽게 이해할 수 있을꺼라고 생각한다. 최근 작업을 하면서 몇가지 주의점(?)을 발견한 거라면...
- container의 id에 언더바(_)가 들어가면 동작하지 않는다.
- Sortable.serialize를 사용하려면 드래그앤드롭 엘리먼트의 아이디가 언더바(_)로 이어져야 한다. 언더바 뒤쪽에 있는 문자만 표시된다.
- IE에서는 왼쪽 콘테이너에서 오른쪽 콘테이너로 갈때 드래그엘리먼트가 컨테이너 뒤쪽으로 가는 문제가 생긴다. 드롭하기 위해서 반이상 넘어갈 경우에는 위로 올라오는데 이건 IE의 z-index버그때문에 생기는 문제로 예상되는데 정확한 해결책은 아직 찾지 못했다.
그리고 예제의 소스를 보면 알겠지만 기본적으로는 드래그앤드롭을 할 때 해당위치의 공간은 표시하지만 따로 표시되지는 않는다. 이 문제를 해결하기 위해 더미 엘리먼트를 만들었다. OnChage가 발생할 때 해당 엘리먼트의 바로 앞쪽에 더미엘리먼트를 만들어서 insert한다. 이렇게 함으로써 드롭했을때 떨어질 위치가 명시적으로 보일수 있도록 하고 OnChange는 계속 발생하기 때문에 처음에 더미엘리먼트를 지우고 다시 넣어주기 때문에 다른 컨테이너로
jQuery로 작업하기, 3부: jQuery와 Ajax로 RIA 만들기: JQuery: 내일 나올 웹 응용을 오늘 구현해보자Effects 모듈과 Ajax |
난이도 : 중급 Michael Abernethy, 제품 개발 관리자, Optimal Auctions 원문 게재일 : 2008 년 10 월 28 일 JQuery는 동적 RIA를 쉽게 개발하는 방법에 목마른 개발자를 위한 자비스크립트 라이브러리로 각광을 받고 있습니다. 브라우저 기반 응용이 데스크톱 응용을 계속 대체하고 있기에, 이런 라이브러리 활용 역시 꾸준히 증가 추세에 있습니다. jQuery 연재물에서 jQuery로 웹 응용 프로젝트를 구현하는 방법을 살펴봅시다. jQuery는 지난 몇 개월 동안에 웹 개발자를 위한 유력한 자바스크립트 라이브러리로 급속도로 세를 넓혀가고 있다. 이런 현상은 브라우저 기반 응용으로 데스크톱 응용을 교체하기 위한 RIA(Rich Internet Application) 활용과 필요성이 급격하게 늘어나는 상황과 맞물려 돌아간다. 스프레드시트부터 급여 계산에서 전자편지 응용에 이르기까지 브라우저로 데스크톱 응용을 교체해 나가는 현실이다. 이런 응용 개수가 많아지고 복잡해지면서 자바스크립트 라이브러리는 응용을 만드는 튼튼한 기초로 더욱 더 중요성이 높아질 것이다. jQuery는 개발자를 위한 필수 라이브러리가 되었다. 이 연재물에서는 jQuery를 깊숙하게 탐험하며, 개발자가 RIA를 빠르고 쉽게 만들기 위한 튼튼한 토대를 제공한다. 직전 기사에서 RIA를 만드는 세 가지 기본 구성 요소와 페이지에 상호 작용을 추가하는 방법을 배웠다. 첫 번째로 살펴본 Event 모듈은 페이지에서 사용자가 일으킨 사건을 잡아서 프로그램 상에서 반응하도록 만들었다. 이런 기능을 사용해 버튼 누르기, 마우스 이동과 같은 사용자 행동 처리용 코드를 붙인다. 다음으로 살펴본 Attributes 모듈은 페이지 엘리먼트에서 값을 얻고 엘리먼트에 값을 설정하는 방법과 변수값을 포함한 자료 객체로 취급하는 방법을 설명했다. 이런 변수값은 사용자에게 어떤 반응을 보일지 결정하는 과정에 필요한 정보 대다수를 포함한다. 마지막으로 CSS 조작 방법을 살펴보고 페이지를 다시 읽어들이지 않고서도 배치, 색상, 글꼴 등을 변경하는 방법을 익혔다. 이런 세 가지 모듈에 익숙해지면, 상호대화식 웹 페이지를 구성하는 세 가지 기초 구성 요소를 익힌 셈이다. 사용자 반응을 잡아(Event), 정보를 획득하고(Attributes), 사건과 정보를 조합한 내용을 토대로 피드백을 제공한다(CSS). 이 기사에서 동적인 웹 페이지를 구성하는 세 가지 기본 요소를 사용한다. 이런 요소는 오늘날 볼 수 있는 좀 더 첨단 웹 응용의 일부로 자리잡은 "화끈한" 효과와 기능을 제공한다. 추가 모듈이 RIA에 핵심은 아니지만, 사용자가 기억할 만한 추가 기능을 제공하며 RIA에서 사용 가능한 범위와 기능을 엄청나게 넓혀준다. 살펴볼 첫 모듈은 Effects 모듈로 엘리먼트 감추기, 엘리먼트 이동, 페이드 인/아웃과 같은 기능을 포함한다. 다시 말해 웹 페이지를 화끈하게 만드는 기능이다. 이 기사에서 설명하는 마지막 모듈은 비동기식 자바스크립트 + XML(Ajax) 모듈이다. Ajax는 RIA 하면 가장 먼저 떠오르는 단어다. Ajax는 웹 응용에 서버와 통신하는 능력을 부여해 페이지를 다시 읽어들이지 않고서도 정보를 전달하고 인출하는 기능을 제공한다(웹에 떠도는 잘못된 의견과는 달리 AJax는 단순히 멋진 자바스크립트 애니메이션 기능은 아니다). jQuery가 믿기 어려울 정도로 손쉬운 AJax 도구를 제공하며, 실제로 Ajax 사용을 자바스크립트 메서드 호출 수준으로 단순하게 만들어준다. 이 기사에서 소개하는 예제 응용은 Effects와 Ajax 모듈을 데모 웹 응용인 웹 메일로 집어넣는 방법을 보여주면서 끝을 맺는다. 몇 가지 Effects를 데모에 추가해 활력을 불어넣고, 더욱 중요하게 몇 가지 Ajax 코드를 추가해 웹 메일이 페이지를 다시 읽지 않고서도 메시지를 출력하도록 만든다. Effects 모듈은 이름처럼 "심각한" 웹 페이지가 회피해야 하는 애니메이션과 특수 효과만 포함한다고 지레짐작하기 쉽다. 하지만 이런 기능으로 끝나지 않는다. 거의 모든 응용에서 특정 페이지 엘리먼트를 가리거나 다른 페이지 엘리먼트 상태에 맞춰 끄고 켤 필요가 있다. 이런 변화 유형이 RIA에 중요한 이유는 페이지를 한 번만 읽으면서 모든 페이지 엘리먼트를 가져온 다음에 특정 엘리먼트를 표시하고 가리는 방식으로 필요한 정보만 보여주기 때문이다. 페이지를 다시 읽는 대안은 좋은 해법이 아니다. div를 감추고 보여주는 두 가지 선택이 가능한 콤보 박스를 생각해보자. 명백히 콤보 박스가 바뀔 때마다 div를 감추고 보여주려고 페이지를 다시 읽어들이는 것보다 클라이언트 쪽 코드에서 단순히 div를 감추고 보여주는 방식이 훨씬 더 쉽고 효율적이다. 단순히 감추고 보여주느냐 페이드 인/아웃 효과를 주느냐는 설계자 마음이다. 위에서 언급한 바와 같이 가장 기초적인 효과는 Listing 1. show()와 hide() 함수
이런 기본적인 기능 이외에, 몇 가지 예제를 살펴보기 앞서, 잠시 한 걸음 물러서서 Effects 함수에 인수를 전달하는 방법을 살펴보자. (일반적인 Listing 2. 복잡한 효과
Effects 모듈은 페이지 엘리먼트를 완전히 감추거나 보여주지 않는 흥미로운 함수가 하나 더 있다. Listing 3. 멋진 효과를 추가하기 위해 fadeTo() 활용하기
Effects 모듈에서 소개하고픈 마지막 함수는 가장 멋지지만 가장 실수도 저지르기 쉬운 함수다. 이는 전용 애니메이션 메서드로 애니메이션에 필요한 모든 매개변수를 지정하면 나머지는 jQuery가 알아서 처리한다. 매개변수 배열에 최종값으로 넘기면 jQuery는 배열에 정의된 값을 판단해 역시 매개변수로 넘긴 속력을 적용해서 마지막 값에 이를 때까지 페이지 엘리먼트를 부드럽게 움직여준다. Listing 4는 전용 애니메이션 메서드 예를 보여준다. 말하지 않아도 알겠지만 이 함수 응용 분야는 제한이 없으므로, 독자적인 전용 애니메이션이 필요하다고 느낄 때 유용하게 써먹기 바란다. Listing 4. 전용 애니메이션 메서드
최근에 "Ajax를 사용합니까?"라는 유행어가 모든 웹 페이지에 등장하고 있지만, 모든 사람이 Ajax가 진짜로 무엇을 의미하는지 아는 건 아니다. "Ajax"를 구글에서 검색해 보면 (다른 검색 결과와 마찬가지로) 수백만 건에 이르는 결과가 나타나지만 Ajax 용어가 품고 있는 사상이 무엇인지를 혼동하고 있다는 증거처럼 보인다. Ajax는 몇몇 페이지에서 보여주는 진짜 멋진 애니메이션도 아니며 진짜 멋진 그림자가 아래에 깔린 팝업 창도 아니다. 단지 Ajax가 멋지기 때문에 웹 페이지에서 보여주는 모든 흥미로운 효과를 Ajax라고 부르지는 않는다. Ajax의 핵심은 간단하게 말해 클라이언트 쪽 웹 페이지가 페이지를 다시 읽어들일 필요 없이 서버와 정보를 주고받는 수단일 따름이다. Ajax가 페이지에서 화끈한 효과를 주지는 못하지만, 웹 응용이 데스크톱 응용을 흉내내기 위한 수단을 제공한다. 따라서 Ajax를 둘러싼 소문은 근거가 있다. Ajax를 광범위하게 사용하는 관례는 오늘날 볼 수 있는 RIA 부문의 급격한 성장을 견인하고 있다. jQuery는 Ajax를 엄청나게 쉽게 만들어준다! 과장해 추켜세울 의도는 없다. 자바스크립트 라이브러리의 도움 없이 Ajax로 작업한다면 독자적인 Ajax 코드를 만드는 데 가장 널리 사용하는 함수인 Listing 5. Ajax post()와 get() 메서드
두 예제를 보면 알겠지만, 해당 함수는 다른 jQuery 함수와 거의 흡사하며, 자바스크립트 라이브러리 없이 Ajax 프로그램을 작성하는 경우와 비교해 훨씬 더 사용하기 쉽다. Ajax 호출 함수를 확장하기 위해 사용 가능한 몇 가지 인수가 있다. 첫 번째 인수는 두말할 필요없이 호출할 URL이 되어야 한다. PHP 파일, JSP 파일, 서블릿이 될 수 있으며, 실제로 요청을 처리할 수만 있다면 뭐든 가능하다. (나중에 예제 응용을 보면 알겠지만) 요청에 반드시 반응할 필요도 없다. 두 번째 인수는 옵션으로 post/get으로 넘길 자료를 담는다. 이 인수는 배열 형태다. 일반적으로 페이지에서 사용자 ID 등 Form 엘리먼트에 들어있는 정보를 넘길 때 사용한다. 서버 쪽 파일에서 요청을 처리하는 데 필요한 모든 내용을 담고 있다. 세 번째 인수는 역시 옵션이며 Ajax 함수가 성공적으로 끝나고 나서 호출할 함수다. 이 함수는 일반적으로 서버에서 전달하는 정보 결과를 처리하는 코드를 포함한다. Listing 6은 네 번째 인수 설명에 앞서 첫 세 인수를 활용하는 예제를 보여준다. Listing 6. 추가 인수를 받아들이는 post 메서드
지금까지 jQuery로 Ajax를 다루는 방법은 아주 직관적이고 쉽다는 사실을 확인했다. 하지만 단순히 텍스트 문자열이 아니라 서버에서 좀 더 복잡한 정보를 다루기 시작하면 일이 꼬이기 시작한다. 더 많은 Ajax 호출이 걸려있는 좀 더 복잡한 웹 페이지에서 반환 자료는 XML 형태도 가능하다. 반환 자료는 또한 JSON 객체 형태가 될 수도 있다(JSON은 기본적으로 자바스크립트 코드에서 사용 가능한 객체를 정의하는 프로토콜이다). jQuery는 네 번째 옵션 인수로 서버에서 기대하는 반환 값 유형을 미리 정의하는 get/post 메서드에 넘기도록 허용한다. XML 문자열을 위해 Listing 7. Ajax에서 반환 유형 명세하기
설명에 시간을 들일 만한 또 다른 Ajax 함수는 Listing 8. load() 함수 예
Ajax 모듈에서 소개할 마지막 두 함수는 Ajax 작업을 훌륭하게 보조해 주는 진짜 유틸리티 함수다. 이미 여러 차례 지적한 바와 같이 클라이언트와 서버 사이에서 일어나는 상호 작용 대다수는 폼과 폼이 포함하는 엘리먼트를 둘러싸고 일어난다. 이런 통신 유형이 아주 일반적이므로 jQuery에는 두 가지 유틸리티 함수가 있어서 HTTP 질의 문자열이거나 JSON 문자열 형태로 서버 쪽에 전달할 매개변수 생성을 도와준다. Ajax가 요구하는 조건에 맞춰 지원하는 유틸리티 함수를 골라 활용한다. 활용법이 아주 간단한 이유는 전체 폼을 캡슐화하므로 개발 도중에 자유롭게 엘리먼트를 추가, 삭제, 변경할 수 있기 때문이다. Listing 9는 이런 예제를 보여준다. Listing 9. serialize()와 serializeArray() 함수
모든 내용을 하나로 합쳐서 만든 데모 웹 응용인 웹 메일을 마지막으로 살펴보자. 이미 지난 연재물에서 충분히 익숙하게 살펴보았을 것이다. 정보 획득을 위해 클라이언트 쪽에서 서버 쪽으로 여러 Ajax 호출을 수행한다. 여기서는 메시지를 읽고 메시지를 지울 때 AJax를 활용한다. 그러고 나서 Effects를 활용해 사용자가 메시지를 지울 때 즉시 화면에서 메시지를 사라지게 만든다. 심지어 사용자가 페이지를 다시 읽지 않으며 Ajax 호출을 활용해 비동기식으로 실제 삭제가 일어나지만 이런 삭제 동작이 즉시 일어난다. 직접 만든 웹 응용에서 Ajax 호출이 얼마나 쉬운지를 살펴보고 데스크톱 응용을 진짜로 흉내내기 위해 Ajax를 활용하는 방법을 살펴보고, Effects를 활용해 응용 프로그램 사용성을 높이는 방법을 예제를 보면서 최종적으로 확인한다. Listing 10. 예제 웹 응용: 메시지 삭제하기
두 번째 예제로, 메시지를 읽는 방법을 살펴보자. jQuery에서 Ajax를 활용하는 예를 보여준다. Listing 11. 예제 웹 응용: 메시지 읽기
jQuery와 같은 자바스크립트 라이브러리는 데스크톱에서 브라우저로 응용 프로그램을 이식함에 따라 점점 더 중요해진다. 이런 응용은 점점 더 복잡해지므로, 웹 응용 프로젝트에서 jQuery와 같은 튼튼한 교차 브라우저 해법을 필수로 요구한다. jQuery는 다른 자바스크립트 라이브러리와 격차를 벌이기 시작했으며, 필요한 모든 작업을 수행하는 능력과 함께 손쉬운 개발 특성 때문에 많은 개발자가 jQuery를 핵심 라이브러리로 선택하고 있다. 연재물 세 번째 기사에서, 응용에 풍부함을 더해 데스크톱 응용과 웹 응용 사이에 경계를 허무는 두 가지 모듈을 익혔다. 이번 기사에서 가장 강력하게 추가한 내용은 Ajax 모듈로, 다른 jQuery 메서드 호출처럼 간단하고 직관적인 인터페이스를 제공함으로써 Ajax를 아주 쉽게 활용하도록 만든다. 페이지를 다시 읽느라 지연되는 짜증을 겪지 않고서 응용 프로그램 반응 속력을 높이는 훌륭한 도구로 몇 가지 예제를 곁들여 Ajax의 위력도 살펴보았다. Effects 패키지에 대한 내용도 빠지지 않았다. 애니메이션과 페이지 엘리먼트 감추기/보여주기 기능을 적절하게 사용한다면 좋은 UI 디자인이라는 강력한 지원군을 얻게 된다. Ajax와 Effect를 결합해 효율적으로 활용하면 웹 사이트에 동적인 능력을 상당히 강화할 수 있다. 마지막으로 웹 응용 예제를 다시 한번 살펴보았고, AJax 모듈을 추가해 페이지를 다시 읽어들이지 않고도 메시지를 읽고 삭제하는 방법을 익혔다. 그러고 나서 Ajax와 Effect 조합으로 페이지를 다시 읽어들이지 않고도 사용자 페이지와 DB 웹 응용에서 메시지를 삭제하는 방법을 익혔다. 사용자에게 메시지 삭제는 투명한 과정이며, 미리 정해진 방식에 맞춰 프로그램 상에서 동작한다. 이 기사는 모든 jQuery 배포판에 따라오는 핵심 라이브러리에 대한 소개 내용으로 마무리를 한다. 연재물에서 jQuery에 포함된 모든 모듈을 살펴보았으며, jQuery로 작업하는 과정이 쉽고 직관적이라는 사실을 보여줬다. 또한 어떤 웹 응용을 만들거나 jQuery는 RIA 유형에 무관하게 제 자리를 잡고 있다는 사실을 확인했다. 자바스크립트가 요구하는 수준에 맞춰 튼튼한 토대를 제공하기 때문이다. 연재물은 직접 코드를 작성하는 과정에서 jQuery를 아주 자연스럽게 활용하는 수준에 이르도록 독자들을 이끌었다. 첫 번째 기사는 jQuery 동작 방식, 페이지 엘리먼트 탐색을 위한 활용 방법, 엘리먼트를 순회하는 방법, Array 객체와 같은 방식으로 접근하는 방법을 설명했고, 두 번째 기사는 풍부함을 제공하는 토대로 세 가지 모듈을 소개했다. 마지막으로 세 번째 기사는 완벽하고 복잡한 웹 응용을 만들기 위한 프레임워크를 위한 마지막 퍼즐 조각을 보여줬다.
| |||||||||||||||||||||||||||||||||||||||||||||||||
도메인이 다른 경우
도메인 a1
도메인 a2
a1에서 a2를 호출해서 popup을 띄운다.
a2 버튼 클릭 후 a1을 reload 하고 a2를 close 시키려면 문제가 생긴다.
window.opener.location.reload(); 호출 시 도메인이 달라서 opener를 못찾기 때문이다.
<script>document.domain="도메인 명";</script>
==> cross domain 이라고 검색하면 나옴..
전체 쿠키 정보를 Text 로 출력한다 . 모든 쿠키에 대한 정보를 알아볼려면 document.cookie 를 호출하면 된다. 집어 넣는 곳은 cookieOut 이라는 DIV 내에 Text 를 출력하는 로직이다.
// 모든 쿠키출력
function viewCookie()
{
if( document.cookie.length > 0 )
cookieOut.innerText = document.cookie;
else
cookieOut.innerText = "저장된 쿠키가 없습니다.";
}
// 출력화면
<DIV id = "cookieOut"></DIV>
저장된 쿠키값을 쿠키명으로 검색해서 넘겨주는 함수이다.
// param : 쿠키명
// return : 쿠키값
function getCookie( cookieName )
{
var search = cookieName + "=";
var cookie = document.cookie;
// 현재 쿠키가 존재할 경우
if( cookie.length > 0 )
{
startIndex = cookie.indexOf( cookieName );// 해당 쿠키명이 존재하는지 검색후 위치정보를 리턴.
if( startIndex != -1 ) // 존재한다
{
startIndex += cookieName.length;// 값을 얻어내기 위해 시작 인덱스 조절
endIndex = cookie.indexOf( ";", startIndex );// 값을 얻어내기 위해 종료 인덱스 추출
if( endIndex == -1) endIndex = cookie.length; // 만약 종료 인덱스 못찾으면 쿠키 전체길이로 설정
return unescape( cookie.substring( startIndex + 1, endIndex ) );// 쿠키값을 추출하여 리턴
} else {
return false; // 존재하지 않을때
}
} else {
return false; // 쿠키 아예없을때
}
}
쿠키값을 설정한다. 파라미터로는 쿠키명, 쿠키값, 쿠키날짜를 넘긴다
function setCookie( cookieName, cookieValue, expireDate )
{
var today = new Date();
today.setDate( today.getDate() + parseInt( expireDate ) );
document.cookie = cookieName + "=" + escape( cookieValue ) + "; path=/; expires=" +
today.toGMTString() + ";"
}
쿠키명을 넘겨 해당하는 쿠키를 삭제한다
function deleteCookie( cookieName )
{
var expireDate = new Date();
//어제 날짜를 쿠키 소멸 날짜로 설정한다.
expireDate.setDate( expireDate.getDate() - 1 );
document.cookie = cookieName + "= " + "; expires=" + expireDate.toGMTString() + "; path=/";
}
첨부파일이 아니라 내용에 붙였습니다
xmls x = new xmls(...)에서
x.domLoad(...);
....
x.domWrite(...);
이런 방식으로 사용하시면 됩니다
자세한 설명은 생략하겠습니다
xml의 구조에 대해서 조금만 아신다면 금방 파악이 되실 겁니다
상용으로 잘 사용하고 있습니다
붙이다 보니 tab이 먹지 않아서 정렬이 안되어 있는데
copy해서 editor에서 정리한 다음 보십시오
import java.io.*;
import java.util.*;
import javax.xml.parsers.*;
import javax.xml.transform.*;
import javax.xml.transform.dom.*;
import javax.xml.transform.stream.*;
// xercesImpl.jar를 복사한다
// java_home/jre/lib/src.zip에 있음
import org.apache.xpath.*;
import org.w3c.dom.*;
import org.xml.sax.*;
/*****
XML 문서의 구조
- 최상위 요소를 root라고 한다
XML 문서는 단 하나의 root요소만을 가질 수 있다. 이를 흔히 top level이라고 한다
root요소가 2개 이상일 경우에는 에러가 발생한다
- root요소 앞에는 XML 선언을 담고 있는 프롤로그가 올 수 있다
XML 문서마다 사용된 XML 버전 정보를 프롤로그에 넣어주는것이 좋다
<?xml version="1.0" ?>과 같이 버전 정보가 포함될 수 있다
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" encoding="euc-kr"?> encoding정보도 포함될 수 있다
반드시 <?xml... 은 붙여야 한다
- 요소는 반드시 <와 >로 둘러싼 tag로 구성된다
element와 attribute로 나뉘어 진다
<tag>text</tag>
<tag attribute="text">
<tag attribute="text"></tag>
<tag attribute="text"/>
<tag></tag>
<tag/>
- 주석은 <!-- -->이다
DOM (Document Object Model)
- XML문서를 메모리상에 올려놓은 다음 데이타를 찾아 들어가는 방식을 사용한다
- 큰 문서일경우 무조건 다 읽기 때문에 로드 시간이 걸리거나 메모리를 낭비하게 된다
- 문서 편집을 할 수 있다
- 데이타를 저장되어 있는 순서대로 받는다
SAX (Simple API for XML)
- 큰 문서를 효율적으로 분석하기 위해서 사용한다
- 이벤트가 발생하면 그에 해당하는 데이타를 추출한다. 속도가 DOM에 비해서 빠르다
- 읽기 전용이다. 문서를 편집할 수 없다
- 데이타를 SAX가 주는 순서대로 받는다. 파서가 문서를 탐색하는 순서에 대해서 어떠한 작업도 할 수 없다
- 원하는 요소만 골라서 읽을 수 있다
-----------------------------------------------------------------------------------------
현재 Java SAX Parser의 종류
- Xerces (Apache Foundation DOM & SAX)
SAX와 DOMahen를 다룰 수 있게하는 XML API를 위하여 Apache Group의 프로젝트이다
org.apache.xerces.parser를 사용한다
- Crimson (Sun Project X, JAXP Default Parser)
Sun ProjectX의 일환으로 JAXP의 default parser로 채택되어져 있으며 XMLReader 인터페이스를 구현하므로
SAX API를 이용하여 여러가지 다양한 파싱기능을 사용할 수 있다
- JAXP (Sun, Java API for XML Processing)
Xerces처럼 DOM과 SAX 둘 다를 사용할 수 있도록 지원해주는 API이다
한가지 다른점은 SAX API의 인터페이스를 직접 구현한 클래스를 제공하는것이 아니라
abstract 계층을 한단계 얹은 형태를 제공한다
- Xalan은 xslt 프로세서이다. xsl을 이용하기 위해 필요하다
*****/
public class Xmls
{
public static final int NONE = 0;
public static final int DOM = 1;
public static final int SAX = 2;
// DOM
private DocumentBuilderFactory dbFactory;
private DocumentBuilder dBuilder;
private Document document = null;
private TransformerFactory tFactory;
private Transformer transformer;
// SAX
private javax.xml.parsers.SAXParserFactory spFactory;
private javax.xml.parsers.SAXParser sParser;
private org.xml.sax.helpers.DefaultHandler defHandler;
// private SAXDbHandler defHandler = null;
// type이 DOM이면 DOM방식으로 아니면 SAX 방식으로 처리한다
public Xmls (int Type, boolean valid, org.xml.sax.helpers.DefaultHandler defHandler) throws Exception
{
if (Type == DOM)
{
dbFactory = DocumentBuilderFactory.newInstance();
dbFactory.setValidating(valid); // check를 넘겨주어도 된다
dBuilder = dbFactory.newDocumentBuilder();
// 출력할때 사용한다
tFactory = TransformerFactory.newInstance();
transformer = tFactory.newTransformer();
}
else
{
this.defHandler = defHandler;
spFactory = javax.xml.parsers.SAXParserFactory.newInstance();
sParser = spFactory.newSAXParser();
// xslt 출력
// TransformerFactory factory = TransformerFactory.newInstance();
// Transformer transformer = factory.newTransformer(new SAXSource(new InputSource(stylesheetFile)));
// transformer.transform(new SAXSource(new InputSource(XMLFilename)), new StreamResult(resultFilename));
}
}
//******************** DOM 방식의 method
// xml 문서를 읽는다
// 버전 정보는 반드시 <?xml... 은 붙여야 한다. 아니면 에러가 발생한다
public void domLoad (InputStream in) throws Exception
{
document = dBuilder.parse(in);
}
public void domLoad (String xmlPath) throws Exception
{
document = dBuilder.parse(new File(xmlPath));
}
public Document domGetDocument ()
{
return document;
}
// xml 문자열을 parsing한다
// x.domParse("<node>가</node>");
public void domParse (String xmlString) throws Exception
{
StringReader sr = new StringReader(xmlString);
InputSource is = new InputSource(sr);
document = dBuilder.parse(is);
}
// encoding이 null이거나 ""으면 setting하지 않는다
public void domWrite (OutputStream out, String encoding) throws Exception
{
setEncoding(encoding);
// javax.xml.transform.dom.
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(out);
transformer.transform(source, result);
}
public void domWrite (PrintWriter out, String encoding) throws Exception
{
StringWriter sw = new StringWriter();
setEncoding(encoding);
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(sw);
transformer.transform(source, result);
out.print(sw.toString());
}
// setEncoding("euc-kr");
public void domWrite (String xmlPath, String encoding) throws Exception
{
setEncoding(encoding);
// javax.xml.transform.dom.
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(new File(xmlPath));
transformer.transform(source, result);
}
// 모든 처리가 끝난 다음 마지막에 부른다
public void domClose ()
{
this.document = null;
}
// element와 attribute를 새로 만들고 싶으면 아래의 순서대로 부른다
// x.domAppendElement("personnel/person", "nation", "korea");
// x.domAppendAttribute("personnel/person/nation", "capital", "서울");
// node마다 각각의 값을 주기 위해서 String[] elementValue를 넘긴다
public void domAppendAttribute (String xpath, String attrName, String[] attrValue) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Element element;
// append하기 때문에 attribute는 반드시 unique한 값을 가져야 하기 때문에 갯수가 맞지 않으면 에러를 발생시킨다
if (nodes.getLength() != attrValue.length) throw new Exception("node 갯수와 value 갯수가 맞지 않습니다.");
for (int i = 0; i < nodes.getLength(); i++)
{
element = (Element)nodes.item(i);
element.setAttribute(attrName, attrValue[i]);
}
}
// 해당 attribute node를 삭제하고 싶으면 domDeleteElement를 사용한다
public void domDeleteAttribute (String xpath, String attrName) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Element element;
for (int i = 0; i < nodes.getLength(); i++)
{
element = (Element)nodes.item(i);
element.removeAttribute(attrName);
}
}
// elementValue가 없으면 text node를 append하지 않는다
// x.domAppendElement("personnel/person", "nation", String[] k = { "korea" });
// node마다 각각의 값을 주기 위해서 String[] elementValue를 넘긴다
public void domAppendElement (String xpath, String elementName, String[] elementValue) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Element element, element2;
Text node;
for (int i = 0; i < nodes.getLength(); i++)
{
// loop안에서 선언한다. 모든 node에 append가 된다
element = document.createElement(elementName);
// nodes의 갯수와 elementValue의 갯수가 달라도 된다
if (i < elementValue.length && Codes.checkNull(elementValue[i]) == false)
{
node = document.createTextNode(elementValue[i]);
element.appendChild(node);
}
element2 = (Element)nodes.item(i);
element2.appendChild(element);
}
}
// x.domDeleteElement("personnel/person")
// 하위 node 전체가 삭제된다
public void domDeleteElement (String xpath) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Node node;
for (int i = 0; i < nodes.getLength(); i++)
{
node = nodes.item(i);
node.getParentNode().removeChild(node); // 부모 노드에서 자식 노드(자신)를 삭제
}
}
// xml 문자열을 파싱해서 해당 노드에 child로 붙인다
// x.domAppendParse("personnel/person", "<node2><node3></node3></node2>");
// x.domAppendAttribute("personnel/person/node2", "id", new String[] { "1", "2", "3", "4", "5", "6" });
// x.domAppendParse("personnel/person", "<node2><node3 id=\"1\">가</node3></node2>");
public void domAppendParse (String xpath, String xmlString) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Document tempDoc = makeTempDoc(xmlString);
Node node;
for (int i = 0; i < nodes.getLength(); i++)
{
// loop안에 선언해야 한다.
node = tempDoc.getDocumentElement();
node = document.importNode(node, true);
nodes.item(i).appendChild(node);
}
}
// 기존의 노드에 값만 추가 시킨다
// x.domAppendTextNode("personnel/person/node2/node3", "가");
public void domAppendTextNode (String xpath, String[] txtValue) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
Text node;
for (int i = 0; i < nodes.getLength(); i++)
{
// nodes의 갯수와 txtValue의 갯수가 달라도 된다
if (i < txtValue.length && Codes.checkNull(txtValue[i]) == false)
{
node = document.createTextNode(txtValue[i]);
nodes.item(i).appendChild(node);
}
}
}
// xpath="personnel/person/email"
// attr, element 모두 xpath로 지정하면 갯수를 돌려준다
public int domGetNodeCount (String xpath) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
return nodes.getLength();
}
// xpath="personnel/person", attr="id"
// 해당 값의 index 값을 돌려준다. 중복값이 있으면 처음 발견되는 값의 index를 돌려준다
public int domGetIndexAttribute (String xpath, String attrName, String attrValue) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
NamedNodeMap map;
Node node, node2;
String value = null;
int idx = -1;
for (int i = 0; i < nodes.getLength(); i++)
{
node = nodes.item(i);
map = node.getAttributes();
node2 = map.getNamedItem(attrName);
if (node2 != null && Codes.checkNull(attrValue) == false)
{
value = node2.getNodeValue();
if (attrValue.equals(value)) { idx = i; break; }
}
}
return idx;
}
public ArrayList domGetAttribute (String xpath, String attrName) throws Exception
{
return getAttribute(xpath, attrName, -1);
}
//** attr과 value의 갯수가 다를 수 있기 때문에 원하는 index의 attribute값이 아닐수도 있다
// dom일 경우는 xml의 순서대로 읽어오기 때문에 index로의 처리가 가능하다
public String domGetAttribute (String xpath, String attrName, int index) throws Exception
{
return (String)getAttribute(xpath, attrName, index).get(0);
}
// xpath="personnel/person", attr="id"
public void domSetAttribute (String xpath, String attrName, String attrValue) throws Exception
{
setAttribute(xpath, attrName, null, new String[] { attrValue }, -1, 0);
}
// attribute는 unique하기 때문에 origs, news가 가능하다. index로 변경하지 않아도 된다
// origValue는 원래 값, newValue는 새로운 값. origValue 값이 null이거나 ""이면 전체를 newValue 값으로 setting한다
// 대소문자를 구분하고 싶지 않으면 외부에서 대소문자로 변환해서 넘겨준다
public void domSetAttribute (String xpath, String attrName, String origValue, String newValue) throws Exception
{
setAttribute(xpath, attrName, origValue, new String[] { newValue }, -1, 0);
}
// 해당 index의 attribute를 수정한다
public void domSetAttribute (String xpath, String attrName, String attrValue, int index) throws Exception
{
setAttribute(xpath, attrName, null, new String[] { attrValue }, index, 0);
}
// 기존의 attribute값을 변경한다
public void domSetAttribute (String xpath, String attrName, String[] attrValue) throws Exception
{
setAttribute(xpath, attrName, null, attrValue, -1, attrValue.length);
}
// xpath에 해당하는 값이 여러개이면 여러개 하나면 하나만 돌려준다
// xpath="personnel/person/email"
public ArrayList domGetValue (String xpath) throws Exception
{
return getValue(xpath, -1);
}
//** attr과 value의 갯수가 다를 수 있기 때문에 원하는 index의 attribute값이 아닐수도 있다
// dom일 경우는 xml의 순서대로 읽어오기 때문에 index로의 처리가 가능하다
public String domGetValue (String xpath, int index) throws Exception
{
return (String)getValue(xpath, index).get(0);
}
// domSetAttribute하고 다르다. attribute는 unique하기 때문에 origs, news가 가능하다
// xpath="personnel/person/email"
public void domSetValue (String xpath, String value) throws Exception
{
setValue(xpath, new String[] { value }, -1, 0);
}
//** attr과 value의 갯수가 다를 수 있기 때문에 원하는 index의 attribute값이 아닐수도 있다
// dom일 경우는 xml의 순서대로 읽어오기 때문에 index로의 처리가 가능하다
public void domSetValue (String xpath, String value, int index) throws Exception
{
setValue(xpath, new String[] { value }, index, 0);
}
public void domSetValue (String xpath, String[] value) throws Exception
{
setValue(xpath, value, -1, value.length);
}
// domWrite할때 사용한다
// setEncoding("euc-kr");
private void setEncoding (String encoding)
{
if (Codes.checkNull(encoding)) return;
transformer.setOutputProperty(OutputKeys.ENCODING, encoding);
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
}
private Document makeTempDoc (String nodeString) throws Exception
{
StringReader sr = new StringReader(nodeString);
InputSource is = new InputSource(sr);
return dBuilder.parse(is);
}
private ArrayList getAttribute (String xpath, String attrName, int index) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
NamedNodeMap map;
Node node, node2;
ArrayList al = new ArrayList();
String value = null;
for (int i = 0; i < nodes.getLength(); i++)
{
if (index >= 0 && i != index) continue;
node = nodes.item(i);
map = node.getAttributes(); // 같은 node를 찾는다
node2 = map.getNamedItem(attrName);
if (node2 != null)
{
value = node2.getNodeValue();
al.add(value);
}
}
return al;
}
private void setAttribute (String xpath, String attrName, String attrValue, String[] setValue, int index, int length) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
NamedNodeMap map;
Node node, node2;
String value = null;
int off;
for (int i = 0; i < nodes.getLength(); i++)
{
if (length > 0 && i >= length) break;
if (index >= 0 && i != index) continue;
node = nodes.item(i);
map = node.getAttributes();
node2 = map.getNamedItem(attrName);
off = (length > 0) ? i : 0;
if (node2 != null)
{
if (index > -1 || Codes.checkNull(attrValue)) node2.setNodeValue(setValue[off]);
else
{
value = node2.getNodeValue();
if (attrValue.equals(value)) { node2.setNodeValue(setValue[off]); break; }
}
}
}
}
private ArrayList getValue (String xpath, int index) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
NodeList children;
Node node;
Node childNode;
ArrayList al = new ArrayList();
// value를 리턴하기 위해서 string 변수를 선언
String value = null;
// 여러개의 element에서 하나의 태그가 빠지면 nodes.getLength()의 갯수가 아예 줄어든다
// al.add(Integer.toString(nodes.getLength()));
for (int i = 0; i < nodes.getLength(); i++)
{
if (index >= 0 && i != index) continue;
node = nodes.item(i);
if (node.hasChildNodes())
{
// child node가 있는 node type은 element와 document뿐이다
if (node.getNodeType() == Node.ELEMENT_NODE)
{
// Element 인 경우에는 자식노드를 검색해서 자식 노드중 텍스트 노드, 그러니까
// 태그 사이의 텍스트 값을 리턴하자 일단.
children = node.getChildNodes();
for (int j = 0; j < children.getLength(); j++)
{
childNode = children.item(j);
if (childNode.getNodeType() == Node.TEXT_NODE)
{
// 자식노드를 순환하다가 TextNode 발견하면 value로 세팅.
// out.println(childNode.getNodeName());
value = childNode.getNodeValue();
al.add(value);
}
}
}
else
{
/*
<personnel>
<person id="Big.Boss">
<name><family>Boss</family> <given>Big</given></name>
<email>chief@foo.com</email>
<link subordinates="one.worker two.worker three.worker four.worker five.worker"/>
</person>
</personnel>
-- person이나 name일 경우 값이 없다.
*/
// Document 인 경우에는 Node value라는 개념이 애매하니까..
// 전체 String 을 리턴하거나 null값을리턴해야 하는데 일단 null을 리턴하기로 하자.
// Do nothing
}
}
else
{
// 자식노드가 없는 Attribute나 Text노드, CDATASection등의 값을 질의한 경우. getNodeValue를 이용.
value = node.getNodeValue();
al.add(value);
}
}
return al;
}
private void setValue (String xpath, String[] value, int index, int length) throws Exception
{
NodeList nodes = XPathAPI.selectNodeList(document, xpath);
NodeList children;
Node node;
int off;
for (int i = 0; i < nodes.getLength(); i++)
{
if (length > 0 && i >= length) break;
if (index >= 0 && i != index) continue;
off = (length > 0) ? i : 0;
node = nodes.item(i);
if (node.hasChildNodes())
{
// 기존 Text노드를 삭제하고 다시 setting해야 한다
// 삭제하지 않으면 기존값에 새로운값이 붙여서 처리된다
children = node.getChildNodes();
for (int j = 0; j < children.getLength(); j++)
{
if (children.item(j) instanceof Text) node.removeChild(children.item(j));
}
if (node.getNodeType() == Node.ELEMENT_NODE) node.appendChild((Text)document.createTextNode(value[off]));
else node.setNodeValue(value[off]);
}
else
{
/*
자식노드가 없는 Attribute나 Text노드, CDATASection등의 값을 질의한 경우.
person, link인 경우에 해당
<personnel>
<person id="Big.Boss">
<name><family>Boss</family> <given>Big</given></name>
<email>chief@foo.com</email>
<link subordinates="one.worker two.worker three.worker four.worker five.worker"/>
</person>
</personnel>
*/
if (node.getNodeType() == Node.ELEMENT_NODE) node.appendChild((Text)document.createTextNode(value[off]));
else node.setNodeValue(value[off]);
}
}
}
//******************** SAX 방식의 method
// defHandler는 saxLoad를 부를때 외부에서 받는다
// overriding을 해야 하기 때문에 외부에서 defHandler를 control을 할 수 있게 한다.
public void saxLoad (InputStream in) throws Exception
{
sParser.parse(in, defHandler);
}
public void saxLoad (String xmlPath) throws Exception
{
sParser.parse(new File(xmlPath), defHandler);
}
public org.xml.sax.helpers.DefaultHandler saxGetDefHandler ()
{
return defHandler;
}
}
[출처] xerces를 사용한 dom 방식의 xml parser lib |작성자 yc7497
이 글에서는 Java 2 Java 2, Enterprise Edition, v 1.4 를 사용합니다. 다운로드
SUN JAVA STREAMING XML PARSER 소개
XML을 사용하는 대부분의 Java 개발자는 SAX (Simple API for XML) 라이브러리와 DOM(Document Object Model) 라이브러리에 익숙할 것이다. SAX는 이벤트 기반의 API이며, 이는 일반적으로 프로그래머가 파서와 몇 개의 리스너를 등록하고, 특정 XML 문법 생성자(예를 들어 요소나 속성)가 도착되면 리스너 메소드가 호출된다는 의미이다. 그 반대로 DOM은 트리 기반의 아케텍처를 가지며, 전체 문서를 스캔하여 마주치는 각각의 문법 생성자의 오브젝트 트리를 구축한다. 프로그래머는 스캔이 완료된 후 오브젝트 트리에 접근하여 수정할 수 있다
이 두 방법 모두 각각의 결점을 가지고 있다: 리스너를 이용하는 이벤트 기반의 API는 일반적으로 다루기 힘들다. 리스너들이 파서에 의해 조종되기 때문이다. 트리 기반의 API는 스캔되는 문서의 양에 비해 과도한 양의 메모리를 소모할 수 있다. 이제 Java 개발자들이 XML 을 스캔하는데 이용할 수 있는 세 번째 API가 등장하였다. StAX (Streaming API for XML parse)가 그것이다.
SJSXP란?
SJSXP(Sun Java Streaming XML Parser)는 StAX를 빠른 속도로 구현한다. 썬마이크로시스템즈와 협력하고 있는 BEA Systems, XML-guru James Clark, Stefan Haustein, Aleksandr Slominski (XmlPull 개발자들), 그리고 JCP의 다른 멤버들은 JSR 173를 구현하는 것으로써 StAX를 개발하였다. StAX은 공유 인터페이스들에 기반하는, 파서(parser) 독립적인 Java API이다.
SJSXP는 Java Web Services Developer Pack v1.5에 포함되어있다. SJSXP에 대해 처음으로 알아차릴만한 것은 이것이 스트림 API에 기반한다는 것이다. 즉, 개발자가 어느 한 노드에 접근하기 위해 전체 문서를 읽을 필요가 없다. 또한, 파서를 시작하여 파서가 데이터를 이벤트 리스너 메소드에 "push"하도록 허용하는 법칙을 따르지 않는다. 대신에 SJSXP는 "pull" 메소드를 구현하며, 이 메소드는 정렬 포인터를 문서에서 현재 스캔되고 있는 지점에 유지한다. 이는 종종 커서(cursor)라고 불린다. 사용자는 단순히 커서가 현재 가리키고 있는 노드에 대한 파서를 요청하면 된다.
XML 문서 파싱에 SJSXP 이용하기
SJSXP를 이용하여 XML 문서를 읽는 것은 아주 쉽다. 대부분의 작업은 javax.xml.stream.XMLStreamReader 인터페이스를 구현하는 오브젝트를 통해 이뤄진다. 이 인터페이스는 XML 문서의 첫 부분에서 마지막까지 이동되는 커서를 나타낸다. 몇 가지 명심해야할 것이 있다. 커서는 항상 하나의 아이템(시작 태그 요소, 진행 명령, DTD 선언 등)만을 가리켜야 한다. 또한 커서는 항상 앞으로 움직여야 하며 (뒤로 움직일 수 없다), 다음에 무엇이 나타나는지 미리 보기를 실행할 수 없다. 다음의 코드 발췌에서 파일로부터 XML을 읽는 XMLStreamReader를 얻을 수 있다.
URL url = Class.forName("MyClassName").getResource(
"sample.xml");
InputStream in = url.openStream();
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(in);
그 후 다음 코드를 이용하여 XML 파일을 반복할 수 있다.
while(parser.hasNext()) {
eventType = parser.next();
switch (eventType) {
case START_ELEMENT:
// Do something
break;
case END_ELEMENT:
// Do something
break;
// And so on ...
}
}
XMLStreamReader의 hasNext() 메소드는 XML 파일에서 또다른 유효한 아이템이 있는지 확인한다. 만약 있다면, 커서가 다음 아이템으로 넘어가게하기 위해 next() 메소드를 사용할 수 있다. next() 메소드는 만나게되는 문법상 생성자(아이템)의 타입을 가리키는 인티거 코드를 리턴한다.
XMLInputStreamReader에는 몇 개의 get 메소드가 있어서 커서가 가리키는 XML 아이템의 내용을 얻는 데 사용할 수 있다. 첫번째 메소드는 getEventType()이다:
public int getEventType()
메소드는 커서가 있는 곳에서 파서가 찾은 아이템의 타입을 식별하는 integer 코드를 리턴한다. next() 메소드에 의해 리턴되는 것과 같은 코드이다. 아이템은 XMLInputStream 상수 중 하나에 의해 식별된다.
XMLStreamConstants.START_DOCUMENT XMLStreamConstants.END_DOCUMENT XMLStreamConstants.START_ELEMENT XMLStreamConstants.END_ELEMENT XMLStreamConstants.ATTRIBUTE XMLStreamConstants.CHARACTERS XMLStreamConstants.CDATA XMLStreamConstants.SPACE XMLStreamConstants.COMMENT XMLStreamConstants.DTD XMLStreamConstants.START_ENTITY XMLStreamConstants.END_ENTITY XMLStreamConstants.ENTITY_DECLARATION XMLStreamConstants.ENTITY_REFERENCE XMLStreamConstants.NAMESPACE XMLStreamConstants.NOTATION_DECLARATION XMLStreamConstants.PROCESSING_INSTRUCTION
만약 아이템에 이름이 있는 경우, getName()과 getLocalName() 메소드를 사용하여 이름을 얻을 수 있다. 후자는 어떤 다른 정보(예; 확인된 네임스페이스가 없는 요소의 이름) 없이 이름 자체를 산출한다.
public Qname getName() public String getLocalName()
만약 당신이 현재 아이템의 네임스페이스를 식별하고 싶다면 getNamespaceURI() 메소드를 사용 할 수 있다.
public String getNamespaceURI()
만약 DTD 선언 내의 텍스트나 요소 안의 텍스트 등과 같은 동반되는 텍스트가 있을 때에는 다음 메소드들을 사용하여 얻을 수 있다.(후자는 요소를 위해 단독으로 사용 될 수 있다)
public String getText() public String getElementText()
만약 요소가 그것과 관계 되는 속성을 가진다면 getAttributeCount() 메소드를 사용하여 현재 요소가 가진 속성들의 갯수를 얻을 수 있다. 그 후 getAttributeName() 와 getAttributeValue() 메소드를 사용하여 각각의 정보를 검색 할 수 있다.
public int getAttributeCount() public Qname getAttributeName(int index) public String getAttributeValue(int index)
만약 속성의 로컬 이름과 요소의 네임스페이스 URI를 안다면, 또한 다음의 메소드를 이용하여 속성값을 얻을 수 있다.
public String getAttributeValue(
String elementNamespaceURI, String localAttributeName)
추측했겠지만, 모든 접근자 메소드가 특정 상태에 적용가능한 것이 아니다. 예를 들어, 현재 DTD를 프로세싱 중이라면 getElementText()을 호출할 수 없다. 만약 이를 호출한다면, 파서가 충돌하는 이벤트 타입을 식별했다는 XMLStreamException을 얻게 되거나 메소드가 스스로 널(null) 값을 리턴하게 될 것이다.
XMLInputFactory 클래스의 setProperty() 메소드를 사용하여 몇 가지 파서 속성을 시작할 수 있다. 예를 들어, 다음은 파서와 마주치는 엔티티 레퍼런스는 교체될 것이라고 지정한다.
factory.setProperty(
XMLInputFactory.IS_REPLACING_ENTITY_REFERENCES,
Boolean.TRUE);
파서가 외부 엔티티를 지원하는 것을 막기 위해 다음과 같이 설정한다.
factory.setProperty(
XMLInputFactory.IS_SUPPORTING_EXTERNAL_ENTITIES,
Boolean.FALSE);
파서가 네임스페이스를 알아차리게하기 위해 다음과 같이 설정한다.
factory.setProperty(
XMLInputFactory.IS_NAMESPACE_AWARE, Boolean.TRUE);
SJSXP의 현재 버전에서는 다음의 명령은 허용되지만 파서는 확인되지 않는다는 것을 유의하기 바란다.
factory.setProperty(XMLInputFactory.IS_VALIDATING,
Boolean.TRUE);
만약 이 XMLInputFactory 특성들 중 어느 하나라도 가능하게 된다면 setXMLReporter() 메소드를 사용하여 파서가 만나게되는 오류를 제어할 수 있다. 파서가 만나는 오류의 타입을 가장 빨리 정확하게 결정할 수 있는 방법은 setXMLReporter() 메소드와 상호 작용하는 익명의 이너 클래스를 사용하는 것이다. 이는 다음과 같다.
factory.setXMLReporter(new XMLReporter() {
public void report(String message, String errorType,
Object relatedInformation, Location location) {
System.err.println("Error in "
+ location.getLocationURI());
System.err.println("at line "
+ location.getLineNumber()
+ ", column " + location.getColumnNumber());
System.err.println(message);
}
});
XML 문서 작성에 SJSXP 사용하기
XML 결과를 작성하는 것은 SJSXP를 이용하면 쉽다. 이 경우, XMLStreamReader 인터페이스 대신에 XMLStreamWriter 인터페이스를 사용할 수 있다. XMLStreamWriter 인터페이스는 작성하는 요소, 속성, 코멘트, 텍스트를 비롯해 XML 문서의 모든 부분을 작성하기 위한 직접적인 메소드를 제공한다. 다음의 예제에서는 어떻게 이 인터페이스를 얻어서 XML 문서를 작성하는데 사용하는지 보여준다.
XMLOutputFactory xof = XMLOutputFactory.newInstance();
XMLStreamWriter xtw =
xof.createXMLStreamWriter(new FileWriter("myFile"));
xtw.writeComment(
"all elements here are in the HTML namespace");
xtw.writeStartDocument("utf-8","1.0");
xtw.setPrefix("html", "http://www.w3.org/TR/REC-html40");
xtw.writeStartElement(
"http://www.w3.org/TR/REC-html40","html");
xtw.writeNamespace(
"html", "http://www.w3.org/TR/REC-html40");
xtw.writeStartElement(
"http://www.w3.org/TR/REC-html40","head");
xtw.writeStartElement(
"http://www.w3.org/TR/REC-html40","title");
xtw.writeCharacters("Java Information");
xtw.writeEndElement();
xtw.writeEndElement();
xtw.writeStartElement(
"http://www.w3.org/TR/REC-html40","body");
xtw.writeStartElement("http://www.w3.org/TR/REC-html40","p");
xtw.writeCharacters("Java homepage is ");
xtw.writeStartElement("http://www.w3.org/TR/REC-html40","a");
xtw.writeAttribute("href","http://java.sun.com");
xtw.writeCharacters("here");
xtw.writeEndElement();
xtw.writeEndElement();
xtw.writeEndElement();
xtw.writeEndElement();
xtw.writeEndDocument();
xtw.flush();
xtw.close();
각 요소를 작성하는 것이 끝나면 사용자는 라이터(writer)를 날려보내고 닫아야한다.
이전의 코드는 다음의 XML로 결과가 나타난다.(여기서는 쉽게 읽을 수 있게 라인 별로 나타내었다.)
<!--all elements here are explicitly in the HTML namespace--> <?xml version="1.0" encoding="utf-8"?> <html:html xmlns:html="http://www.w3.org/TR/REC-html40"> <html:head> <html:title>Java Information</html:title> </html:head> <html:body> <html:p> Java information is <html:a href="http://frob.com">here</html:a> </html:p> </html:body> </html:html>
XML 문서 필터링
만약 각각의 아이템 타입을 스캔하고 싶지 않다면 들어오는 XML 문서에 대한 필터를 생성할 수 있다. 이를 위해서는 javax.xml.stream.StreamFilter 인터페이스를 구현하는 클래스를 생성한다. 이 인터페이스는 단지 accept() 메소드만으로 구성된다. 이 메소드는 XMLStreamReader 오브젝트를 허용하고 원시 Boolean을 리턴한다. StreamFilter의 일반적인 구현은 다음과 같다.
public class MyStreamFilter implements StreamFilter {
public boolean accept(XMLStreamReader reader) {
if(!reader.isStartElement() && !reader.isEndElement())
return false;
else
return true;
}
}
그 다음으로 XMLInputFactory의 createFilteredReader() 메소드를 호출하여 필터링된 리더(reader)를 생성하고 이를 원래 XML 스트림 리더와 StreamFilter 구현에 모두 전달한다. 다음과 같다.
factory.createFilteredReader(
factory.createXMLStreamReader(in), new MyStreamFilter());
SJSXP의 더 자세한 정보는 Sun Java Streaming XML Parser release notes를 참고하기 바란다.
Sun Java Streaming XML Parser 예제 코드 구동하기
- 이번 테크팁에 대한 샘플 아카이브(ttfeb2005sjsxp.jar)를 다운로드한다.
- Java Web Services Developer Pack Downloads page에서 Java WSDP 1.5를 다운로드, 설치한다.
- 예제 압축파일을 다운로드 받은 디렉토리를 변경하고, 다음과 같이 샘플 아카이브에 대한 JAR 파일의 압축을 푼다.
jar xvf ttfeb2005sjsxp.jar
- 사용자의
classpath가ttfeb2005sjsxp.jar와jsr173_api.jar를 포함하도록 설정한다. 이들은 Java WSDP 1.5 installation의sjsxp/lib디렉토리에 위치하고 있다.
SJSXPInput를 컴파일하고 구동한다.
다음의 각각의 XML 아이템과 유사한 엔트리가 나타날 것이다.Event Type (Code=11): DTD Without a Name With Text: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1- transitional.dtd"> -----------------------------
SJSXPOutput를 컴파일하고 구동한다. 결과는XMLOutputFile라는 이름의 파일에 보내지며, 위의 결과 예제에 보여지는 요소들을 포함할 것이다.
//인터넷 XML 날씨 정보를 파싱 (DomParser.java)
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomParser {
private static Document xmlDoc = null;
private static String XML_URL = "http://weather.unisys.com/forexml.cgi?seoul";
private static String XML_NODE = "observation";
private static String XML_CITY = "city";
private static String XML_TIME = "time";
private static String XML_SKIES = "skies";
private static String XML_TEMP = "temp.C";
public static void main(String[] args) {
printXmlFromUrl(XML_URL);
}
private static void printXmlFromUrl(String urlString) {
try {
URL url = new URL(urlString);
try {
URLConnection urlConnection = url.openConnection();
HttpURLConnection httpConnection = (HttpURLConnection)urlConnection;
int responseCode = httpConnection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
InputStream inputStream = httpConnection.getInputStream();
// Parsing XML Document
createDomParser(inputStream);
String[] xmlData = getByTagName(XML_NODE);
for (int i = 0; i < xmlData.length; i++) {
System.out.println(xmlData[i]);
}
inputStream.close();
} else {
System.out.println("HTTP Response is not \"HTTP Status-Code 200: OK.\"");
}
} catch (IOException e) {
e.printStackTrace();
}
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
private static void createDomParser(InputStream inputStream) {
// Use factory to create a DOM document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setIgnoringElementContentWhitespace(true);
DocumentBuilder builder = null;
try { // Get a DOM parser from the Factory
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
return;
}
try { // Request the DOM parser to parse the file
xmlDoc = builder.parse(inputStream);
} catch (SAXException e) {
e.printStackTrace();
return;
} catch (IOException e) {
e.printStackTrace();
return;
}
}
private static String[] getByTagName(String tagName) {
if (!(xmlDoc == null)) {
NodeList nodes = xmlDoc.getElementsByTagName(tagName);
NamedNodeMap nodeMap = nodes.item(0).getAttributes();
String[] values = new String[4];
values[0] = nodeMap.getNamedItem(XML_CITY).getNodeValue();
values[1] = nodeMap.getNamedItem(XML_TIME).getNodeValue();
values[2] = nodeMap.getNamedItem(XML_SKIES).getNodeValue();
values[3] = nodeMap.getNamedItem(XML_TEMP).getNodeValue();
return values;
}
return null;
}
}
XML Parser 함수들
|
함수 |
리턴 값 |
설명 |
|
xml_error_string(code) |
string |
제공된 오류 code와 결홥된 오류 메시지를 리턴한다. |
|
xml_get_current_byte_index(parser) |
integer |
XML 파서를 위해 현제 바이트 인덱스를 리턴한다. |
|
xml_get_current_column_number(parser) |
integer |
지정된 parser를 위해 현재 행 번호를 리턴한다. |
|
xml_get_current_line_number(parser) |
integer |
지정된 parser를 위해 현재 줄 번호를 리턴한다. |
|
xml_get_error_code(parser) |
integer |
마지막으로 발생한 xml,파서의 올에대한 오류 코드를 리턴한다. |
|
xml_parse(parser, data, [is_final]) |
integer |
지정된 data를 분석한다. |
|
xml_parser_create([encoding_parameter]) |
integer |
xml 파서를 작성한다. |
|
xml_parser_free(parser) |
Boolean |
지정된 xml parser를 해제한다. |
|
xml_parser_get_option(parser, option) |
Mixed |
지정된 parser에 대한 지정된 option의 값을 리턴한다. |
|
xml_parser_set_option(parser, option, value) |
integer |
지정된 parser를 위해 option을 지정된 value로 설정한다. |
|
xml_set_character_data_handler(parser, handler) |
integer |
문자 데이터 핸들러를 등록한다. |
|
xml_set_default_handler(parser, handler) |
integer |
기본 핸들러를 등록한다. |
|
xml_set_element_handler(parser, handler) |
integer |
시작과 끝 구성 요소 핸들러를 등록한다. |
|
xml_set_external_entity_ref_handler(parser, handler) |
integer |
외부 엔티티 참조 핸들러를 등록한다. |
|
xml_set_notation_decl_handler(parser, handler) |
integer |
표기법 선언 핸들러를 등록한다. |
|
xml_set_processing_instruction_handler(parser, handler) |
integer |
처리 지시어 핸들러를 등록한다. |
|
xml_set_unparsed_entity_decl_handler(parser, handler) |
integer |
분석되지 않은 엔티티 선어 핸들러를 등록한다. |
[ xml_parser_create() ]
XML 파서 컨텍스트를 만든다.
int xml_parser_create(string [encoding_parameter]);
encoding_parameter : 파서가 사용할 문자 소스 암호화. 일단 설정된 소스 암호화는 나중에 변경할 수 없다. 가능한 값으로는 ISO-8859-1(default) , US-ASCII, UTF-8
[ xml_set_element_handler()]
"start()"와 “end()"ㅅ구성 요소 핸들러 함수들을 XML 파서에 등록한다.
int xml_set_element_handler( int parser, string startElementHandler , string endElementHandler);
parser : XML 파서의 핸들러. 시작과 끝 구성 요소 핸들러들이 등록되어있다.
startElementHandler : 시작 구성 요소 핸들러 함수의 이름. 만약 null이 지정되면 시작 구성 요소 핸들러가 등록되지 않은 것이다.
endElementHandler : 끝 구성 요소 핸들러 함수의 이름. 만약 null이 지정되면 끝 구성 요소 핸들러가 등록되지 않는다.
< satartElementHandler(int parser, string name, string attribs[]); >
parser : 이함수를 호출하고 있는 XML 파서에 대한 참조
name : 구성 요소의 이름
attribs() : 구성 요소의 속성들을 포함하고 있는 조합배열
< endElementHandler(int parser, string name); >
parser : 이 함수를 호출하고 있는 XML 파서로의 참조
name 구성요소 이름
[ xml_set_character_data_handler() ]
XML 파서에 문자 데이터 핸들러를 등록한다.
int xml_set_character_data_handler( int parser, string characterDataHandler);
parser : 문자 데이터 핸들러가 등록된 XML 파서를 위한 핸들
characterDataHandler : 문자 데이터 핸들러 함수의 이름. 만약 null이 지정되면 문자 데이터 핸들러가 등록되지 않는다.
< characterDataHandler( int parser, string data); >
parser : 이 함수를 호출 중인 XML 파서로의 참조
data : XML 문서에 제공되는 문자 데이터. 파서는 문자 데이터를 이TSms 그대로 리턴하며, 어떠한 공백 문자도 제거하지 않는다.
[ xml_parse() ]
XML 문서의 컨텐츠를 파서로 전달한다. 이 함수는 문서의 실제 분석을 수행한다(XML 문서에서 노드들을 만나면 등록된 적당한 핸들러들을 호출한다.).
이 함수는 XML 문서에 있는 다양한 노드 타입들에 대한 핸들러 함수들이 모두 파서에 등록된 후에 호출된다.
int xml_parse( int parser, string data, int [isFinal]);
parser : 제공된 데이터를 분석할 XML 파서의 핸들
data : XML 문서의 컨텐츠. XML 파일의 전체 컨텐츠는 한 번의 호출로 전달될 필요는 없다.
isFinal : 입력 데이터의 끝을 지정한다.
전달된 데이터의 분석이 가능하면 true를 리턴하고, 그렇지 않으면 false를 리턴한다. 실패이 경우 , 오류정보는 xml_get_error_code()와 xml_get_error_string()함수를 이용하여 발견 할 수 있다.
[ xml_get_error_code ]
XML 파서로부터 오류 코드를 리턴한다.
int xml_get_error_code( int parser);
parser : XML 파서으 핸들
분석에 실패하거나 유호한 XML파서가 아닐 경우 flase를 리턴한다.
[ xml_error_string ]
오류 코드에 따라 오류 메시지를 리턴한다.
string xml_get_error_code( int errorCode);
ErrorCode : xml_get_error_code() 함수가 리턴한 오류 코드
[ 예제 ]
<?
class RSSParser {
var $feed_info = array();
var $feed_articles = array();
var $inchannel = FALSE;
var $initem = FALSE;
var $inimage = FALSE;
var $current_item = array();
var $current_el = FALSE;
// 여는 태그 처리
function startElement($parser, $name, $attrs)
{
$el = strtoupper($name);
if ($el == 'RSS') {
return;
} else if ($el == 'CHANNEL') {
$this->inchannel = TRUE;
} else if ($el == 'ITEM') {
$this->initem = TRUE;
} else if ($el == 'IMAGE') {
$this->inimage = TRUE;
} else {
$this->current_el = $el;
}
}
// 닫는 태그 처리
function endElement($parser, $name)
{
$el = strtoupper($name);
if ($el == 'RSS') {
return;
} else if ($el == 'CHANNEL') {
$this->inchannel = FALSE;
} else if ($el == 'ITEM') {
$this->feed_articles[] = $this->current_item;
$this->current_item = array();
$this->initem = FALSE;
} else if ($el == 'IMAGE') {
$this->inimage = FALSE;
} else {
$this->current_el = FALSE;
}
}
// 태그 사이의 데이터 처리
function characterData($parser, $data)
{
if ($this->initem) {
if ($this->current_el) {
$this->current_item[$this->current_el] .= $data;
}
} else if ($this->inimage) {
} else if ($this->inchannel) {
if ($this->current_el) {
$this->feed_info[$this->current_el] .= $data;
}
}
}
}
function parse_save_rss($document)
{
// RSS 피드의 인코딩을 UTF-8에 맞춤
if (preg_match('/<?xml.*encoding=[\'"](.*?)[\'"].*?>/m', $document, $m)) {
$in_enc = strtoupper($m[1]);
if ($in_enc != 'UTF-8') {
$document = preg_replace('/(<?xml.*encoding=[\'"])(.*?)([\'"].*?>)/m', '$1UTF-8$3', $document);
$document = iconv($in_enc, 'UTF-8', $document);
}
}
// XML 및 RSS 분석기 생성
$xml_parser = xml_parser_create('UTF-8');
$rss_parser = new RSSParser();
xml_set_object($xml_parser, $rss_parser);
xml_set_element_handler($xml_parser, "startElement", "endElement");
xml_set_character_data_handler($xml_parser, "characterData");
if (!xml_parse($xml_parser, $document, true)) {
printf("XML error: %s at line %d\n",
xml_error_string(xml_get_error_code($xml_parser)),
xml_get_current_line_number($xml_parser));
} else {
// 분석결과를 DB에 저장
$link = mysql_connect('mysql_host', 'mysql_user', 'mysql_password') or die('Could not connect: '.mysql_error());
mysql_select_db('my_database') or die('Could not select database');
foreach ($rss_parser->feed_articles as $article) {
$published = date('Y-m-d H:i:s', strtotime($article['PUBDATE']));
$query = sprintf("INSERT INTO feed_articles (source, title, link, description, published) VALUES ('%s', '%s', '%s', '%s', '%s')",
mysql_real_escape_string($rss_parser->feed_info['TITLE']),
mysql_real_escape_string($article['TITLE']),
mysql_real_escape_string($article['LINK']),
mysql_real_escape_string($article['DESCRIPTION']),
$published);
if (mysql_query($query, $link)) echo $query."\n";
}
}
xml_parser_free($xml_parser);
}
// 읽어올 피드 목록
$feed_urls = array(
'http://blog.rss.naver.com/kickthebaby.xml',
'http://srlog.egloos.com/index.xml',
'http://feeds.feedburner.com/tapestrydilbert'
);
foreach ($feed_urls as $url) {
$handle = fopen($url, 'r');
if ($handle) {
$document = '';
while (!feof($handle)) {
$document .= fgets($handle, 4096);
}
echo $url."\n";
// 읽어온 피드를 분석하여 DB에 저장
parse_save_rss($document);
fclose($handle);
}
}
?>
[출처] XML Parser 함수 표|작성자 아슈크림
Parser 와 DOM 기초
- Parser
- XML 문서를 읽고 해석 : well-formed, valid 검사
- 응용 개발시 파서 사용 이유 : 세부적인 XML 문법으로부터 프로그램 격리
XML 문서 --> [파서] -->인터페이스--> [응용 프로그램]- 파서가 메모리에 DOM 트리를 생성 : XML 문서트리와 일치
- 파서가 메모리에 DOM 트리를 생성 : XML 문서트리와 일치
- 표준 API
- DOM : 객체 기반 (Object-based) Interface
- 메모리 상주 트리 이용, 응용에서 간단히 사용, p.208 - SAX : 이벤트 기반 (Event-driven) Interface
- 파서가 간단, 응용프로그램은 복잡
- DOM : 객체 기반 (Object-based) Interface
- DOM 개요
- 문서내 객체(element)를 조작하기 위한 인터페이스(API)
- DOM level 1 : ’98.10 W3C Recommendation
- DOM level 2 : 2000.11 W3C Recommendation
- DOM level 3 : 2001.8 W3C Working Draft- 문서 전체가 아닌 문서 일부분에 대한 접근 가능
- 대상 문서 : XML1.0 또는 HTML4.0
- DOM의 역할
- 구조의 탐색 : 각 요소와 속성에 대한 탐색/질의가 가능
- 문서 구조의 조작 : 문서 구조에서 요소, 속성의 추가/수정/삭제가 가능
- 컨텐츠의 조작 : 문서 요소에서 text 등 컨텐츠의 탐색/추가/수정/삭제가 가능
- 문서내 객체(element)를 조작하기 위한 인터페이스(API)
Document 객체
- DOMDocument 객체 생성 및 읽기
- Msxml2.DOMDocument 객체
- async 속성, load 메쏘드, xml 속성
MSXML 파서 설치할 경우 MSXML 파서 설치안한 경우 <HTML>
<HEAD>
<Script language="Javascript">
function xload0()
{
var xmldoc = new
ActiveXObject("Msxml2.DOMDocument");
xmldoc.async = false; xmldoc.load("ex07a.xml");
alert(xmldoc.xml);
}
</script>
</HEAD>
<BODY>
<input type="button" value="XML 로드0"
onClick="xload0()">
</BODY>
</HTML>
111<HTML>
<HEAD>
<Script language="Javascript">
function xload1()
{
xmldoc.async = false;
xmldoc.load("ex07a.xml");
alert(xmldoc.xml);
}
</script>
</HEAD>
<BODY>
<input type="button" value="XML 로드1"
onClick="xload1()">
<xml id="xmldoc"></xml>
</BODY>
</HTML>
VBScript 의 경우 <Script language="VbScript">
Dim xmldoc
Set xmldoc = CreateObject("Msxml2.DOMDocument")
xmldoc.async = False;
xmldoc.load("ex07a.xml");
MsgBox xmldoc.xml
</Script>
- 신규 문서 작성 : loadXML 메쏘드
xmldoc.async = false;
xmldoc.loadXML( "<book><title>XML 입문</title><author>일지매</author></book>");
alert(xmldoc.xml);
xmldoc.async = false;
xmldoc.loadXML( "<book> <title> XML 입문 </title> <author> 일지매 </author> </book>");
alert(xmldoc.xml);
- 공백의 처리 : preserveWhiteSpace 속성
xmldoc.async = false;
xmldoc.preserveWhiteSpace = true;
xmldoc.loadXML( "<book> <title> XML 입문 </title> <author> 일지매 </author> </book>");
alert(xmldoc.xml);
xmldoc.async = false;
xmldoc.preserveWhiteSpace = true;
xmldoc.load("ex07a.xml");
alert(xmldoc.xml);
- XML 문서의 저장 : save 메쏘드
- 에러 처리 : parseError, parseError.line, parseError.linepos, parseError.reason
xmldoc.async = false;
xmldoc.loadXML( "<book> <title> XML 입문 </title> <author> 일지매 </authors> </book>");
alert(xmldoc.xml);
xmldoc.async = false;
xmldoc.loadXML( "<book> <title> XML 입문 </title> <author> 일지매 </authors> </book>");
if (xmldoc.parseError)
alert("에러 위치 : " + xmldoc.parseError.line + "번째 라인 " + xmldoc.parseError.linepos
+ "번째 문자\n\n에러 이유 : " + xmldoc.parseError.reason);
else alert(xmldoc.xml);
- 루트 노드 찾기 : documentElement 속성
xmldoc.async = false;
xmldoc.load("ex07a.xml");
var xmlroot = xmldoc.documentElement;
alert(xmlroot.nodeName);
xmldoc.async = false;
xmldoc.loadXML( "<book> <title> XML 입문 </title> <author> 일지매 </author> </book>");
var xmlroot = xmldoc.documentElement;
alert(xmlroot.nodeName);
- 임의의 노드 찾기 : getElementsByTagName("tagName")
- 노드의 추가 메쏘드 : 뒤에 설명
- createElement(name), createTextNode(data), createAttribute(name), createComment(data), createProcessingInstruction(target,data), createCDATASection(data), createEntityReference(name)
Node 객체
- nodeName, nodeType, nodeValue, attributes, text 속성
- nodeType = 1(element), 2(attribute), 3(text) , 4(CDATA), ... : 표7.1 [p.215]
xmldoc.load("ex07a.xml");
var xmlroot = xmldoc.documentElement;
alert('nodeName: '+xmlroot.nodeName+'\nnodeType: '+xmlroot.nodeType+
'\nnodeValue: '+xmlroot.nodeValue+'\nattributes: '+xmlroot.attributes.length);
alert(xmlroot.text);
- Node의 운행(Traversal) 관련 속성
- 관련속성
-- previousSibling
... parentNode -- **현재노드** -- childNodes [ firstChild, … , lastChild ]
-- nextSibling - hasChildNodes() 메쏘드
- 관련속성
- NodeList 객체
- length 속성, item(번호) 메쏘드
| xmldoc.load("ex07a.xml"); var xmlroot = xmldoc.documentElement; if (xmlroot.hasChildNodes) { alert(xmlroot.childNodes.length); var curr = xmlroot.firstChild; alert(curr.xml); alert(curr.nodeName + curr.nodeType +curr.nodeValue+curr.attributes.length); } else alert('No Child'); |
xmldoc.load("ex07a.xml"); var xmlroot = xmldoc.documentElement; var curr = xmlroot.firstChild.nextSibling; alert(curr.xml); curr = curr.childNodes.item(2); alert(curr.xml); curr = curr.previousSibling; alert(curr.text); alert(curr.nodeName + curr.nodeType +curr.nodeValue+curr.attributes.length); |
- NamedNodeMap 객체
- getNamedItem("속성명"), setNamedItem(), removeNamedItem() 메쏘드
- Attribute 객체
- name, value, specified 속성
xmldoc.load("ex07a.xml");
var attrs = xmlroot.firstChild.attributes;
var attr0 = attrs.getNamedItem("InStock");
alert(attr0.name + attr0.value + attr0.specified);
- 노드의 추가/삭제/수정 메쏘드 : 뒤에 설명
- appendChild(child), insertBefore(child,before), removeChild(child),
replaceChild(child,toReplace), cloneNode(deep)
- appendChild(child), insertBefore(child,before), removeChild(child),
임의 노드의 검색
- 태그 이름으로 검색
- 노드리스트 = 문서.getElementsByTagName("tagName");
| xmldoc.load("ex07a.xml"); var nlist = xmldoc.getElementsByTagName("book"); for (i=0; i<nlist.length; i++) alert(nlist.item(i).xml); |
xmldoc.load("ex07a.xml"); var nlist = xmldoc.getElementsByTagName("title"); for (i=0; i<nlist.length; i++) alert(nlist.item(i).xml); |
- 패턴으로 검색
- 노드리스트 = 노드.selectNode("query");
- 노드 = 노드.selectSingleNode("query");
| xmldoc.load("ex07a.xml"); var xroot = xmldoc.documentElement; var node1 = xroot.selectSingleNode("title"); alert(node1.text); var tlist = xroot.selectNodes('//title'); var alist = xroot.selectNodes('//author'); for (i=0; i<alist.length; i++) alert('['+i+'] '+alist.item(i).text+', ' +tlist.item(i).text); |
xmldoc.load("ex07a.xml"); var xroot = xmldoc.documentElement; var node1 = xroot. selectSingleNode('//book[@InStock=0]'); alert(node1.xml+'\n=> 재고가 없습니다.'); var tlist = xroot. selectNodes('//book[@InStock!=0]/title'); for (i=0; i<tlist.length; i++) alert(tlist.item(i).text+'\n=>재고 있음.'); |
펌 - http://mm.sookmyung.ac.kr/~sblim/lec/xml-int02/
MSDN - http://msdn.microsoft.com/library/default.asp?url=/library/en-us/xmlsdk/html/dom_reference.asp
Xerces-J contains many useful samples to help you get up-and-running with writing XML applications. Many of the sample programs are even useful as standalone programs to help in testing the validity of XML documents and/or debugging applications.
The samples are organized either by API or by programming area in the following categories:
Apache parser
The Apache parser version 1.2.3 (commonly known as Xerces) is an open-source effort based on IBM's XML4J parser. Xerces has full support for the W3C Document Object Model (DOM) Level 1 and the Simple API for XML (SAX) 1.0 and 2.0; however it currently has only limited support for XML Schemas, DOM Level 2 (version 1). Add the xerces.jar file to your CLASSPATH to use the parser. You can use Xalan, also available from Apache's Web site, for XSLT processing. You can configure both the DOM and SAX parsers. Xerces uses the SAX2 method getFeature() and setFeature() to query and set various parser features. For example, to create a validating DOM parser instance, you would write:
DOMParser domp = new DOMParser();
try {
domp.setFeature ("http://xml.org/dom/features/validation", true);
} catch (SAXExcepton ex) {
System.out.println(ex);
}
The following example shows a minimal program that counts the number of <servlet> tags in an XML file using the DOM. The second import line specifically refers to the Xerces parser. The main method creates a new DOMParser instance and then invokes its parse() method. If the parse operation succeeds, you can retrieve a Document object through which you can access and manipulate the DOM tree using standard DOM API calls. This simple example retrieves the "servlet" nodes and prints out the number of nodes retrieved.
import org.w3c.dom.*;
import org.apache.xerces.parsers.DOMParser;
public class DOM
{
public static void main(String[] args)
{
try {
DOMParser parser = new DOMParser();
parser.parse(args[0]);
Document doc = parser.getDocument();
NodeList nodes = doc.getElementsByTagName("servlet");
System.out.println("There are " + nodes.getLength() +
" elements.");
} catch (Exception ex) {
System.out.println(ex);
}
}
} You can use SAX to accomplish the same task. SAX is event-oriented. In the following example, inherits from DefaultHandler, which has default implementations for all the SAX event handlers, and overrides two methods: startElement() and endDocument(). The parser calls the startElement() method each time it encounters a new element in the XML file. In the overridden startElement method, the code checks for the "servlet" tag, and increments the tagCounter counter variable.. When the parser reaches the end of the XML file, it calls the endDocument() method. The code prints out the counter variable at that point. Set the ContentHandler and the ErrorHandler properties of the the SAXParser() instance in the main() method , and then use the parse() method to start the actual parsing.
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import org.apache.xerces.parsers.SAXParser;public class SAX extends DefaultHandler
{
int tagCount = 0;
public void startElement(String uri, String localName,
String rawName, Attributes attributes)
{
if (rawName.equals("servlet")) {
tagCount++;
}
}
public void endDocument()
{
System.out.println("There are " + tagCount +
" <servlet> elements.");
}
public static void main(String[] args)
{
try {
SAX SAXHandler = new SAX();
SAXParser parser = new SAXParser();
parser.setContentHandler(SAXHandler);
parser.setErrorHandler(SAXHandler);
parser.parse(args[0]);
}
catch (Exception ex) {
System.out.println(ex);
}
}
}
With Xerces installed and your CLASSPATH set, you can compile and run the above programs as follows:
javac DOM.java
javac SAX.java
C:\xml\code>java DOM web.xml
There are 6 <servlet> elements.C:\xml\code>java SAX web.xml
There are 6 <servlet> elements.<%@ page contentType="text/html;charset=EUC-KR" %>
<% request.setCharacterEncoding("euc-kr"); %>
<%@ page import="java.util.*" %>
<%@ page import="java.net.*" %>
<%@ page import="javax.xml.parsers.*" %>
<%@ page import="org.w3c.dom.*" %>
<%!
final String G_ROOT_URL="http://locahost:6973/test.cgi?";
final String strVal(String str){
if(str == null) str = "";
return str.trim();
}
class T_DOC{
String id;
String sim;
HashMap<String,String> hm_item=new HashMap<String,String>();
}
class SrchInfo{
StringBuffer m_URL=new StringBuffer();
SrchInfo(){
m_URL.append(G_ROOT_URL);
}
public void SetQRY(String p_name,String p_value){
m_URL.append(p_name + "=" + p_value + "&");
}
// 헤더 정보 변수
String m_section_name;
String m_usrspec;
String m_idxname;
String m_qryflag;
String m_srtflag;
String m_totcnt;
String m_maxcnt;
String m_outcnt;
String m_pagenum;
// 결과 정보
ArrayList<T_DOC> m_DOCS=new ArrayList<T_DOC>();
private DocumentBuilderFactory docBuilderFactory;
private DocumentBuilder docBuilder;
private Document doc;
private NodeList nodeDOC;
public void GetData(){
try{
// DocumentBuilderFactory 의 객체 생성
DocumentBuilderFactory docBuilderFactory=DocumentBuilderFactory.newInstance();
// factory로부터 DocumentBuilder 를 얻어온다.
DocumentBuilder docBuilder=docBuilderFactory.newDocumentBuilder();
// XML 문서로부터 DOM 객체를 만들어서 문서(Document) 로 반환 받는다.
//System.out.println(p_xmlfile);
Document doc=docBuilder.parse(m_URL.toString());
//메타 정보 추출
nodeDOC=doc.getElementsByTagName("section");
m_section_name=nodeDOC.item(0).getAttributes().getNamedItem("name").getNodeValue();
m_usrspec=nodeDOC.item(0).getChildNodes().item(1).getFirstChild().getNodeValue();
m_idxname=nodeDOC.item(0).getChildNodes().item(3).getFirstChild().getNodeValue();
m_qryflag=nodeDOC.item(0).getChildNodes().item(5).getFirstChild().getNodeValue();
m_srtflag=nodeDOC.item(0).getChildNodes().item(7).getFirstChild().getNodeValue();
m_totcnt=nodeDOC.item(0).getChildNodes().item(9).getFirstChild().getNodeValue();
m_maxcnt=nodeDOC.item(0).getChildNodes().item(11).getFirstChild().getNodeValue();
m_outcnt=nodeDOC.item(0).getChildNodes().item(13).getFirstChild().getNodeValue();
m_pagenum=nodeDOC.item(0).getChildNodes().item(15).getFirstChild().getNodeValue();
int count=Integer.parseInt(m_outcnt);
for ( int i=0 , idx=19; i < count ; i++ , idx+=2 ){
T_DOC tmp_doc=new T_DOC();
tmp_doc.id=nodeDOC.item(0).getChildNodes().item(idx).getAttributes().getNamedItem("id").getNodeValue();
tmp_doc.sim=nodeDOC.item(0).getChildNodes().item(idx).getAttributes().getNamedItem("sim").getNodeValue();
int child_cnt=nodeDOC.item(0).getChildNodes().item(idx).getChildNodes().getLength();
for ( int j = 1 ; j < child_cnt ; j+=2 ) {
String tag=nodeDOC.item(0).getChildNodes().item(idx).getChildNodes().item(j).getAttributes().getNamedItem("name").getNodeValue();
String value=nodeDOC.item(0).getChildNodes().item(idx).getChildNodes().item(j).getFirstChild().getNodeValue();
tmp_doc.hm_item.put(tag,value);
}
m_DOCS.add(tmp_doc);
}
}catch(java.lang.Exception e) {
System.err.println("==GetData()]"+ e.toString());
e.printStackTrace(System.out);
// System.exit(-1);
}
}// end of GetHeader
public void GetResults(){
}
}//end of class
%>
==================== index.jsp ===========================================
실제 사용 샘플 페이지
<%-- xml parse fs 2008 07 --%>
<%@ page contentType="text/html;charset=EUC-KR" %>
<% request.setCharacterEncoding("euc-kr"); %>
<%@ include file="common.jsp" %>
<%
SrchInfo OB_SrchInfo=new SrchInfo();
OB_SrchInfo.SetQRY("w","test");
String qry=strVal(request.getParameter("qry"));
if( qry.length() == 0 ) qry="*";
OB_SrchInfo.SetQRY("q",URLEncoder.encode(qry));
// xml 파서 시작
OB_SrchInfo.GetData();
out.println("<xmp> " + OB_SrchInfo.m_URL + "</xmp>" );
%>
<HEAD>
<TITLE>XML JAVA 파서 샘플 페이지</TITLE>
</HEAD>
<BODY>
<P>
<table>
<form name=form action=index.jsp method=get>
검색어:<input type=text name=qry value=<%= qry %>>
<input type=submit value="검색">
</form>
</table>
<검색 결과 헤더 정보> : <br>
- 전체건수: <%= OB_SrchInfo.m_totcnt %> <br>
- 요청건수(outmax값): <%= OB_SrchInfo.m_maxcnt %> <br>
- 출력건수: <%= OB_SrchInfo.m_outcnt %> <br>
- 출력페이지번호: <%= OB_SrchInfo.m_pagenum %> <br>
<p>
<검색 결과 데이터> :
<p>
<%
for(int i=0; i < OB_SrchInfo.m_DOCS.size() ; i++){
T_DOC RESULT=OB_SrchInfo.m_DOCS.get(i);
out.println( "DOC ID : " + RESULT.id + "<br>");
out.println( "DOC SIM : " + RESULT.sim + "<br>");
out.println( "제목 : " + RESULT.hm_item.get("TITLE=") + "<br>");
out.println( "내용 : " + RESULT.hm_item.get("ARTICLE=") + "<p>");
}
%>
실제 활용예 소스는 아니지만 좀 아는 사람이라면
실무에 패키지해서 유용하게 사용할수도 있을것이다~~
2008 07 fs
<html>
<head>
<script type="text/javascript">
function parseXML()
{
text="<note>";
text=text+"<to>Tove</to>";
text=text+"<from>Jani</from>";
text=text+"<heading>Reminder</heading>";
text=text+"<body>Don't forget me this weekend!</body>";
text=text+"</note>";
try //Internet Explorer
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.loadXML(text);
}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
parser=new DOMParser();
xmlDoc=parser.parseFromString(text,"text/xml");
}
catch(e)
{
alert(e.message);
return;
}
}
document.getElementById("to").innerHTML=xmlDoc.getElementsByTagName("to")[0].childNodes[0].nodeValue;
document.getElementById("from").innerHTML=xmlDoc.getElementsByTagName("from")[0].childNodes[0].nodeValue;
document.getElementById("message").innerHTML=xmlDoc.getElementsByTagName("body")[0].childNodes[0].nodeValue;
}
</script>
</head>
<body onload="parseXML()">
<h1>W3Schools Internal Note</h1>
<p><b>To:</b> <span id="to"></span><br />
<b>From:</b> <span id="from"></span><br />
<b>Message:</b> <span id="message"></span>
</p>
</body>
</html>
