| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 download.asp?FileID=19154050download.asp?FileID=19154049download.asp?FileID=19154048download.asp?FileID=19154047download.asp?FileID=19154046download.asp?FileID=19154045download.asp?FileID=19154044download.asp?FileID=19154043download.asp?FileID=19154042
download.asp?FileID=19154050download.asp?FileID=19154049download.asp?FileID=19154048download.asp?FileID=19154047download.asp?FileID=19154046download.asp?FileID=19154045download.asp?FileID=19154044download.asp?FileID=19154043download.asp?FileID=19154042|
6. file - new - class해서 새로운 클래스파일을 만든다. 원하는 클래스명을 적고 browse를 누른다.
7. choose a type에 'jlet'을 검색하여 선택한다. finish버튼을 누른다.
8. 위피에 맞게 기본 자바파일이 만들어졌다.
|
여러분은 자바 가상 머신을 메모리 용량이 적고 자원이 제한되어 있으며 네트워크로 연결된 환경에 적합하게 만들고 싶을 것이다. K 가상 머신 (KVM)의 중심에 특수한 자바 클래스가 있는데, MIDlet이 그것이다. 이 글에서 Soma Ghosh는 여러분에게 MIDlet 클래스의 장단점을 소개하고 여러분 자신의 J2ME 애플리케이션을 구축할 때 이를 활용하는 방법을 소개하겠다. 여러분은 MIDlet의 이론을 배우고 난 후 그녀가 구축하는 샘플 프로그램을 통해 그 기술이 실행되는 것을 확인하게 될 것이다.
이 주제에 대해 내가 작성한이전 글에서 나는 Java 2 Platform, Micro Edition (J2ME)의 기초 사항들에 대해 논의하였다. 그 글을 읽어보지 않은 분이라면 이 글을 읽기 전에 아마도 그것을 먼저 읽어 보아야 할 것이다. J2ME의 가장 중요한 구성 요소가 MIDlet이다. 여기서 우리는 MIDlet의 상태와 상태 애플리케이션 뿐 아니라 이벤트와 예외를 처리하기 위한 기법들을 검토하면서 MIDIet을 상세히 살펴보도록 하겠다. 또한 여기에서 설명된 개념들을 입증해 줄 간단한 애플리케이션을 구축해 봄으로써 결론을 짓도록 하겠다. 이 글을 끝낼 때쯤이면 여러분은 여러분 자신의 J2ME 애플리케이션을 작성하는 중일 것이다.
Mobile Information Device Profile (MIDP)은 이동 전화나 기본적인 수준의 팜탑 장비와 같은 모바일 정보 장비를 타겟으로 하는 자바 API 세트이다. MIDlet은 MIDP 애플리케이션을 말한다. 이 글에서는MIDlet과MID 애플리케이션라는 용어가 교대로 사용된다. MIDlet은 J2ME 실행 환경의 구성 요소가 된다.
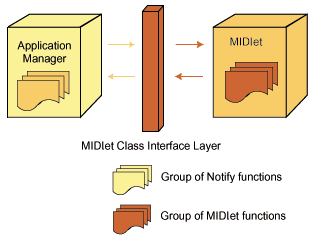
MIDlet은 모바일 장비에서 작동하도록 설계되었으며 자바 가상 머신의 핵심만 모은 버전인 K Virtual Machine (KVM)의 애플리케이션 관리자에 의해 실행되고 제어되도록 만들어졌다.javax.microedition.midlet.MIDlet클래스는 MIDlet과 애플리케이션 관리자 사이의 인터페이스로 작동한다. 이 클래스의 메소드는 애플리케이션 관리자가 MIDlet을 만들고 구동시키고 중지시키고 없애도록 해준다.
J2ME 애플리케이션은javax.microedition.midlet.MIDlet클래스를 확장해야 하는데, 이는 다음 작업들에 대한 프레임워크를 제공한다.:
그림 1은 MIDlet과 애플리케이션 관리자 간의 상호작용을 보여준다.
|
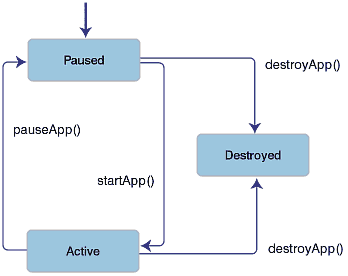
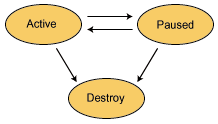
MIDlet은 그 수명 주기 동안 다양한상태로 있을 수 있다. 이 상태들은 애플리케이션 관리자가 런타임 환경 내에서 여러 MIDlet들의 행동을 관리하도록 해 준다. 애플리케이션 관리자는 MIDlet들을 개별적으로 시작시키고 중지시킴으로써 주어진 시점에 어떤 MIDlet이 작동할지 선택할 수 있다. 애플리케이션 관리자는 또한 MIDlet의 상태를 유지보수한다. MIDlet은 다음 상태들 중 하나로 있을 수 있다.:
그림 2는 MIDLet의 상태 변화를 보여주고 있다. 화살표는 허가된 상태 변화를 나타낸다. 예를 들어, 작동 상태의 MIDlet은 중지 상태나 파기 상태 중 하나로 이동할 수 있다.
|
애플리케이션 관리자는 상태를 바꾸기 위해 MIDlet에 특정 메소드를 호출한다. MIDlet은 이 메소드를 구현하여 자신의 내부 행동과 자원 활용을 애플리케이션 관리자가 지시하는대로 업데이트시킨다.:
startApp(): 이 메소드는 MIDlet에게 작동 상태로 들어간다는 신호를 보내며, MIDlet의 대화형 화면 환경을 설정하기 위한 초기화 절차들로 구성되어 있다.pauseApp(): 이 메소드는 MIDlet에게 작동을 멈추고 중지 상태로 가라고 신호한다.destroyApp(): 이 메소드는 MIDlet에게 작동을 종료하고 파기 상태로 가라고 지시한다.MIDlet은 스스로 몇 가지 상태를 개시하고, 이 메소드들 중 하나를 호출하여 애플리케이션 관리자에게 이러한 상태 변화들을 통지할 수 있다.:
notifyDestroyed(): 자신이 파기 상태로 들어갔음을 애플리케이션 관리자에게 통지하기 위해 MIDlet이 사용하는 메소드이다.notifyPaused(): 이 메소드는 MIDlet이 작동 상태로 있고 싶지 않으며 중지 상태로 가고 싶다고 애플리케이션 관리자에게 통지한다.resumeRequest(): 이 메소드는 MIDlet이 작동 상태로 가고 싶어함을 표시하는 메커니즘을 제공한다. 이 메소드에 대한 호출은 애플리케이션 관리자가 사용하는데, 어떤 애플리케이션이 작동 상태로 갈지를 결정한다. 애플리케이션 관리자가 한 MIDlet을 활성화하기로 결정하면 그 MIDlet의startApp()메소드를 호출할 것이다.MIDlet은 애플리케이션 관리자로부터 지정된 특성들을 검색하는 메커니즘을 받았다.getAppProperty()메소드가 그것이다. MIDlet 배치의 일부분으로 제공되는 이 특성들은 애플리케이션 디스크립터 파일과 manifest가 조합된 것으로부터 얻어진다.
startApp()혹은pauseApp()동안 런타임 예외가 발생하면 MIDlet은 즉시 파기될 것이다.
|
사용자가 MIDlet과 상호작용할 때,이벤트가 생성된다. MIDlet은 자신의 이벤트 처리 메커니즘의 일부분으로 특정 인터페이스들을 제공하여 애플리케이션이 이벤트를 통지받고 이에 대해 응답할 수 있도록 한다. 각 인터페이스는콜백 (callback) 이라고 알려진 메소드를 제공하는데, 이것은 이벤트에 응답하여 애플리케이션이 실행시키는 프로그래머 정의 메소드를 호출하는 것이다.
MIDlet이 실행되고 있는 동안 생성되는 이벤트들은 다음과 같다. :
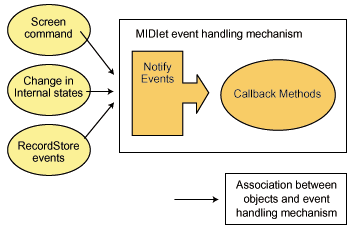
MIDlet 이벤트 처리 메커니즘은listener모델에 기반하고 있다. 각 객체는 이벤트를 통지받고 여기에 응답할 수 있도록 Listener를 구현해야 한다. 이를 위해 MIDlet은ItemStateListener,CommandListener,RecordListener라는 세 인터페이스를 제공한다. 각각을 상세하게 살펴 보자.
|
CommandListener는 화면 출력될 수 있는 아이템 (예 : 화면에 입력되는 명령어)들에서 생성되는 이벤트를 MID 애플리케이션에게 통지하는 책임을 가진다.CommandListener는 listener를 확장하는 객체가 구현해야 하는commandAction(Command c, Displayable d)메커니즘을 제공한다. 이 메소드는 명령어 이벤트가Displayable d에 발생했음을 가리킨다.
|
ItemStateListener는 화면 아이템 (예 : 화면에 있는TextField의 값)의 내부 상태 변화를 MID 애플리케이션에게 통지하며, 아이템의 내부 상태가 사용자에 의해 변경되었을 때 호출되는itemStateChanged(Item I)메소드를 제공한다. 내부 상태의 변화는 사용자에 의해 발생한다.:
ChoiceGroup에서 선택된 값들 변경하기Gauge의 값 조정하기TextField에 값을 입력하거나 수정하기DateField에 날짜나 시간 입력하기여러분은 내가 작성한이전 글에서 이들 화면 아이템에 관해 더 배울 수 있다.
아이템에 언제 새 값을 입력해야 하는지의 결정은 장비에 달려 있다. 예를 들어,TextField내에 텍스트 편집을 구현하는 것은 장비에 따라 아주 다양하다.
ItemStateListener는 애플리케이션이 대화형 아이템의 값을 변경한 경우에는 호출되지 않는다. 사용자가 변경했을 때만 호출된다.
|
RecordListener의 책임은 애플리케이션과 연관되어 있는 레코드 스토어에서 레코드 변경과 관련된 이벤트를 받는 것이다. 이것을 사용하려면 애플리케이션은RecordListener가 제공하는 다음 메소드들을 구현해야 한다. :
recordAdded(): 레코드가 레코드 스토어에 추가되었을 때 호출된다.recordDeleted(): 레코드 스토어의 레코드가 변경된 후에 호출된다.recordChanged(): 레코드 스토어에서 레코드가 삭제된 후 호출된다.
|
MIDlet이 실행될 때 객체들이 이벤트에 응답할 수 있도록 Listeners가 이들 객체들에 연결되어야 한다. MIDlet 클래스는 이벤트 listener를 객체와 연결시키기 위한 특정 메소드들을 제공한다.:
setCommandListener(): 이 메소드는 모든 명령어에 대한 listener를Displayable에 설정하며, 이전의CommandListener를 바꾼다setItemStateListener(): 이 메소드는 화면 아이템에 대한 아이템 상태 listener를 설정하며, 이전의itemStateListener를 바꾼다.addRecordStateListener(): 이 메소드는 레코드 스토어에 레코드 상태 listener를 추가한다.그림 3은 MIDlet 이벤트 처리 모델이다.
|
MIDlet은예외 처리 기능을 사용해 예외적인 상황을 처리할 수 있다.예외란 프로그램이 실행되는 동안 정상적인 명령의 흐름을 혼란시키는 이벤트를 말한다. MIDlet은 자바 예외 처리 메커니즘의 모델을 보존하고 있다. 그러한 에러가 메소드에 발생했을 때, 메소드는 예외 객체를 만들어 이를 런타임 시스템에 넘겨 준다. 예외 객체는 예외의 유형 및 예외가 발생했을 때 프로그램의 상태 등 예외에 관한 정보를 가지고 있다. 그러면 런타임 시스템은 에러를 처리하기 위해 몇 가지 코드를 발견해야 한다. 자바 전문 용어에서, 예외 객체를 만들어 이를 런타임 시스템에 넘겨 주는 것은예외를 던진다(throwing an exception)라고 불린다.
앞에서 살펴 보았듯이, MIDlet은 수명 주기 동안 다양한 상태로 있을 수 있다. MIDlet은 요청된 MIDlet 상태 변화가 실패했음을 함축적인MIDletStateChangeException을 던짐으로써 알려준다.
자바 예외 처리에 관한 상세 정보는 아래의참고 자료부분을 참조한다.
|
이번 섹션에서 우리는 다양한 단계에서의 MIDlet의 역할을 보여주는 J2ME 이미지 애플리케이션을 개발할 것이다. 이 애플리케이션은 또한 이벤트 처리 메커니즘을 통해 종료하는 기능도 가질 것이다.
PhoneImage애플리케이션은 자신의 MIDIet 메소드에 대한 호출에 대응하여 하나의 생성자를 불러온다. 이 생성자는 전화기 화면 환경, 전화기 화면 아이템, 애플리케이션을 종료시키기 위한 화면 명령어를 생성하여 초기화 절차를 수행한다.
전화기 화면 환경은Display클래스에 의해 표시된다. MIDlet당 정확히 하나의Display인스턴스가 있고,PhoneImage생성자는getDisplay()메소드를 호출함으로써 그 인스턴스에 대한 참조를 얻는다.:
|
이 애플리케이션의 UI 측면은 그래픽 이미지 데이터를 보유하기 위해 사용되는javax.microedition.lcdui.Image클래스이다.Image객체들은 화면 장치와 독립적으로 존재한다. 그들은 화면과 무관한 메모리에만 존재하며, 애플리케이션이 명시적인 명령어(Canvas의paint()메소드에서처럼)를 발행하지 않는 한 혹은Image객체가Form화면이나Alert화면 내에 위치하고 그 화면이 갱신되기 전까지는 화면에 표시되지 않을 것이다.
이미지는 그들이 만들어진 방식에 따라가변일 수도 있고불변일 수도 있다. 불변 이미지는 일반적으로 자원 번들, 파일 혹은 네트워크에서 이미지 데이터를 로딩함으로써 만들어진다. 이들은 한 번 만들어지면 수정할 수 없다. 가변 이미지는 화면과 무관한 메모리에서 만들어진다. 애플리케이션은 이를 위해Graphics객체를 명확하게 생성한 후 이들을 표시할 수 있다.Alert,Choice,Form혹은ImageItem객체에 있는 이미지는 불변이어야 한다. 런타임 환경이 애플리케이션에게 통지하지 않고 언제든지 화면을 업데이트하기 위해 이들을 사용할 수 있기 때문이다.
PhoneImage애플리케이션은javax.microedition.lcdui.Image클래스의createImage(String resourceName)메소드를 호출함으로써 불변 이미지 아이템을 생성한다. 이 메소드는 지정된 자원에서 얻어지는 해독된 이미지 데이터들로부터 불변 이미지를 생성하는데, 이 데이터들은 장비 구현에 따라 자원 번들 내에 혹은 파일 시스템상에, 혹은 네트워크상에 존재할 수 있다.resourceName은 지원되는 이미지 포맷 중 하나로 된 이미지 데이터를 포함하고 있는 자원의 이름을 표시하고 있다. 구현은 PNG (Portable Network Graphics) 포맷 v.1.0에 저장되어 있는 이미지들을 지원해야 한다.
자원 명이 null일 경우 메소드는NullPointerException을 던진다. 자원이 존재하지 않거나 데이터를 로딩할 수 없거나 이미지 데이터를 해독할 수 없는 경우에는IOException을 던진다. Listing1은 이 모든 것이 어떻게 작동하는지 보여준다.
|
PhoneImage애플리케이션은startApp()메소드를 호출함으로써 작동 상태로 들어간다.Image아이템은Form객체 (Listing 2 참조)에 내장되어 있다. 구현은 화면 배치, 순환 및 스크롤링을 처리한다.Form역시 화면 명령어와 연결되어 있다.
|
startApp()메소드는 Listing 3과 같이 각 명령어를 listener에 연결하고Form을 현재 표시 가능한 아이템으로 정의함으로써 이벤트 처리 메커니즘을 설정한다.
|
애플리케이션 관리자가pauseApp()메소드를 호출하면PhoneImage애플리케이션이 정지 상태로 들어간다. 이는 백그라운드 작업이 없거나 레코드 스토어가 종료되었을 때 사용하는 무연산 메소드이다.destroyApp()메소드는PhoneImage애플리케이션의 종료 단계를 시작시킨다. 이 메소드는 모든 자원을 해제하는 책임을 가지고 있다.
commandAction메소드 (Listing 4 참조)는PhoneImageMIDlet이 명령에 응답하도록 하며, 모든 화면 명령어 작업시 호출된다.exitCommand가 호출되었을 때 MIDlet을 종료시키는exitCommand의 핸들러가 정의된다.
|
Listing 5는PhoneImage애플리케이션의 전체 소스 코드이다. :
|
그림 4는 장치 에뮬레이터상에서 실행되는 애플리케이션이다.
|
모든 이동 전화나 호출기에서 작동하는 무선 애플리케이션의 작성이 MIDlet으로 훨씬 쉬워졌다. MIDlet의 잘 정의된 아키텍처는 광범위한 기능을 제공하지만 요약된 아키텍처를 유지하는 잘 정의된 메소드 세트를 기반으로 구축되었다. 나는 이 글이 여러분 자신의 MIDlet 구축에 착수하는데 도움이 되기를 바란다.
|
Java의 모든 원천 기술은 Sun Microsystems에서 갖고 있으며 다음과 같이 총 3가지 스펙으로 나누어 집니다.
① J2EE (Java 2 Platform, Enterprise Edition)
② J2SE (java 2 Platform, Standard Edition)
③ J2ME (Java 2 Platform, Micro Edition)
입니다.
그 중에 J2ME는 엔터프라이즈급을 위한 J2EE와, 일반 PC를 위한 J2SE에 바탕을 두고
정의되었으며, 휴대폰이나 PDA 셋톱박스처럼 휴대용의 작은 기기에 적합한, 동적인 네트웍크
기반의 어플리케이션을 개발 할 수 있도록 설계되었습니다.
그러면 이제 J2ME를 세분화 해 보도록 하겠습니다.
J2ME를 세분화 하면 다음과 같이 총 3 가지로 세분화 할 수 있습니다.
① CVM
② KVM
③ Card VM
위와 같이 3가지로 세분화 시켜놓은 것은 VM(Virtual Machine) 에 따라서 구분을 해 놓은 것입니다.
다시 위의 3가지를 자세하게 설명하면 다음과 같습니다.
▣ CVM (Classic Virtual Machine)
CVM은 디지털 셋탑박스, TV등을 위한 컨피규레이션인 CDC(Connected Device Configuration)와 Personal Profile, Foundation Profile, Personal Basis Profile 로 구성됩니다.CVM은 32비트 이상의 프로세서를 가진 디바이스에서 사용됩니다.
즉 CVM 은 밑에서 설명할 KVM을 사용하는 디바이스 보다 덜 제한적인, 즉 조금 더 큰 용량의 디바이스에서 이용될 수 있습니다.
▣ KVM (Kilobyte Virtual Machine)
소형 컴퓨팅 장비들을 위한 J2ME 의 가상 머신입니다. 이 KVM은 휴대폰 이나 PDA , 페이져 등을 위한 컨피규레이션인 CLDC(Connected, Limited Device Configuration)와 MIDP(Mobile Information Device Profile)로 이루어져 있습니다.
▣ Card VM
자바 카드를 위한 VM 입니다.
자 ~ ! 위와 같이 정리를 해 놓고 보니 이제 J2ME 라는 녀석이 한눈에 들어오는 느낌이 드실겁니다. 그러면 이제는 우리가 앞으로 집중적으로 공부를 해야할 KVM에 대해서 조금만 더 알아봅시다.
KVM은 휴대폰을 위한 스펙으로 J2ME를 대표하는 솔루션으로 세계 무선 인터넷 플랫폼 시장에서 그 위치가 확고하다고 볼 수 있습니다. 우리나라에서도 SK 텔레콤과 LG텔레콤을 통해 제공되고 있으며, 또한 우리나라에서 독자적으로 개발한 "대한민국 무선 인터넷 플렛폼 "WIPI" 와도 100 % 호환됩니다.
즉 한번 작성한 J2ME 어플리케이션은 자바를 지원하는 전 세계의 대부분의 폰에서 그대로 작동되는 이점을지니고 있다는 겁니다.
CLDC와 MIDP 에 대한 간단한 설명은 다음과 같습니다
CLDC 는 Connected Limited Device Configuration 의 약자 입니다.
여기서 맨 마지막 단어인 Configuration 은 비슷한 특성을 가지는 디바이스들이 가져야될 최소한의 요구사항에 대한 정의 라고 할 수 있습니다.
즉 J2ME자체가 모바일과 같은 제한된 환경의 디바이스들을 위한 표준 스펙이라고 한다면, 다시 그 J2ME 내부에서도 핸드폰과 같은 아주 극한된 환경을 가지고 있는 디바이스들이 가져야 될 최소한의 요구사항을 정의하는 Configuration을 CDDC 라고 하고, 핸드폰보다는 좀 더 여유로운 환경을 가지고 있는 셋톱박스와 같은 디바이스 내에서 가져야 할 최소한의 요구사항을 정의하는 Configuration을 CDC 라고 합니다.
이제 CLDC를 좀 더 살펴보도록 하겠습니다.
CLDC가 대상으로 하는 디바이스에는 핸드폰 이나 PDA, 양방향페이져 등이 있습니다.
이들은 모두 네트워크에 연결될 수 있고, 극히 제한적인 리소스를 가진 디바이스라는
공통점이 있습니다. 하지만 이러한 공통점 만으로 이들을 하나의 범주로 묶을 수는 없습니다.
예를 들면 핸드폰과 양방향 페이져 등은 디스플레이 창의 크기도 다르며, 사용자의 입력을
처리하는 방법도 천차만별입니다.
즉 공통적인 특성을 가진 디바이스라 할지라도 특정 부분에 대해서는 다른 특성을 가진다는
사실은 어쩔 수 없는 것입니다. 즉 이러한 차이점을 Profile 인 MIDP가 맡게 되는 겁니다.
다시한번 말씀드린다면 Configuration은 최소한의 정의만 하고, 실제 구현이나 확장은
Profiles 에서 담당한다고 할 수 있는 겁니다.
|
1. CLDC 소개 | |||||||||||||||||||||||
CLDC(connected limited device configuration)는 앞서 본 바대로 성능이 제한된 CPU나 메모리가 한정적인 시스템을 대상으로 하는 spec이다. CLDC 관련 library는 시스템에 독립적인 고수준의 API 그리고 네트웍관련 API로 되어 있다. 크게 두 가지로 나눌 수 있는데 J2SE에 포함되어 있는 부분과 CLDC에만 있는 부분이다.
다음은 CLDC에서 주목해야할 몇 가지 특징들이다. | |||||||||||||||||||||||
|
이러한 특징들은 프로그램밍과 시스템의 설계에 있어서 중요한 항목일 경우가 많다. 따라서 하나하나가 의미하는 바를 잘 알아두어야 한다. | |||||||||||||||||||||||
CDC, CLDC가 J2ME에서 configuration이라는 것은 이미 배웠다. 두가지 Configuration의 차이를 아래의 표에서 정리하였다.
[ 표 1 - CLDC와 CDC비교 ] | |||||||||||||||||||||||
아래의 그림은 이러한 차이를 좀더 그래픽하게 표현하였고 Profile종류도 나타나 있다. | |||||||||||||||||||||||
 | |||||||||||||||||||||||
|
[ 그림 1 - CDC와 CLDC 하드웨어 스펙 ] | |||||||||||||||||||||||
| 1) 부동소수점을 지원하지 않는다. | |
| CLDC는 부동소수점을 지원하지 않는다. 이것은 J2SE full spec과 가장 현격한 차이점이기도 하다. 이유는 CLDC 타겟 디바이스가 하드웨어적으로 부동소수점을 지원하지 않기 때문인데, 소프트웨어적으로 부동소수점을 지원하는 것은 너무 큰 부하가 있다. 그래서 언어적인 측면과 가상머신에서 부동소수점은 지원하지 않는다고 명세서에 명시되어 있다. 그러므로, float, double 형과, 부동소수점 리터럴,부동소수점 연산은 사용할 수 없다. 만일 반드시 부동소수점 연산을 해야 한다면 하드웨어 업체가 제공한 OEM spec에서 기능을 찾아보아야 한다. 만일 거기에도 없다면 소프트웨어적으로 처리해야 한다. 다행스럽게도 이러한 Package가 나와 있는데 정수형 타입으로 부동 소수점형 연산을 시뮬레이션 해주는 것이다. MathFP라고 부르는 이 Package는 다음 URL에서 구할 수 있다. SKVM에서는 이 부분을 아예 OEM Spec에 포함하여 출시하고 있다. http://home.rochester.rr.com/ohommes/MathFP | |
2) Finalization과 가비지 컬렉션 | |
| CLDC 라이브러리의 Object 클래스에는 finalize() 메소드가 없다. 그러므로, CLDC 가상머신은 클래스 인스턴스를 가비지 컬렉트할 때 finalization을 수행하지 않는다. KVM은 크기가 작고 메모리를 효율적으로 사용하는 가비지 컬렉터를 위해서, 마크-청소(mark-sweep) 알고리즘을 사용하고, 비복사(non-copying), 비압축(non-compacting) 가비지 컬렉터를 사용한다. | |
3) 에러 처리 | |
| Java에서는 Error 와 Exception 두가지의 예외상황을 처리하는데 Error는 복구할 수 없는 것이고 Exception은 복구가능한 것이다. CLDC는 예외 처리는 지원하지만 에러 처리는 제한적으로 지원한다. 아래와 같이 두가지 Error처리만을 수행하는데 이렇게 대부분의 에러처리가 빠져 버린 이유는 하나는 에러처리가 대부분 하드웨어에서 처리되기 때문이다. 에러 처리가 일관성이 없는 임베디드 환경에서 대부분의 디바이스들은 에러가 발생했을 때, 그냥 리셋을 해 버린다. 다른 하나는 복구할 수 없는 에러를 처리하기 위해서는 매우 힘이 들기 때문이다. 너무 심한 오버헤드를 초래할 가능성이 높다. | |
4) JNI(Java Native Interface) | |
| CLDC는 JNI를 지원하지 않는다. 네이티브 함수를 호출하는 방법은 CLDC의 구현에 의존적이다. 즉, CLDC를 구현하는 사람에게 달려있다는 것이다. JNI는 덩치가 크기도 하지만, CLDC의 제한적인 보안 모델로 인해, 네이티브 함수의 호출 자체가 위험할 수 있기 때문에 지원하지 않는다. | |
5) 리플렉션 | |
| 리플렉션은 런타임시에 자바 프로그램이 가상머신 내부의 클래스, 인터페이스, 객체 인스턴스들을 조사할 수 있게 하는 자바가상 머신의 특징이다. CLDC에서는 이러한 리플렉션 기능을 지원하지 않는다. 따라서 리플렉션 기능에 의존적인 여러가지 기능들을 지원할 수 없다. RMI, 객체 직렬화, 디버깅 인터페이스(JVMDI), 프로파일러 인터페이스(JVMPI) 등이 그것이다. 한가지 아쉬운 것은 RMI가 지원되지 않으므로, CLDC/MIDP 플랫폼에 지니를 올릴 수 없다는 것이다. 지니가 핸드폰에 탑재되기를 기대하시던 분들에게는 실망스러운 소식일 것이다. 무선 지니 디바이스에 관심이 있는 분이라면, RMI 프로파일이 포함된 CDC/퍼스널 프로파일 플랫폼을 탑재한 단말기를 기대하셔야 할 것 같다. | |
| 1) 보안 모델 | |||||||||||||||||||||||||||||||||||
CLDC 타겟 디바이스에는 J2SE 플랫폼의 정책기반(policy-based) 보안 모델을 적용하기 어렵다. 왜냐하면, CLDC 구현보다 보안 모듈이 훨씬 더 큰, ‘배 보다 배꼽이 더 큰’ 형국이 될 것이기 때문이다. CLDC에서 정의된 보안 관련사항은 다음과 같은 두 가지 수준의 보안에 대한 지원이다.
보안에 관한 한 CLDC는 원시적인 자바의 모습으로 퇴화했는데, CLDC 모래상자 보안 모델은 다음과 같은 요구사항을 만족해야 한다. | |||||||||||||||||||||||||||||||||||
2) 클래스 검증 과정 | |||||||||||||||||||||||||||||||||||
| J2SE의 virtual Machine과 같이, KVM에서도 class file의 수행전에 verify하는 과정을 거쳐야 할 필요가 있다. 하지만 JVM의 class file 검증은 과도한 static / dynamic foot print를 사용하기 때문에 좀 더 단순하고, 효율적인 검증과정이 필요로 하게 되었다. 그 solution으로 제시된 것이 OFF-Line 사전검증 과 ON-Line 검증으로 나누어 검증하는 것이다. J2SE의 Java Virtual Machine에서 일반적으로 검증기(verifier)는 runtime시 50KB의 binary code space와 30~100 KB의 동적 RAM을 필요로 한다. 게다가 CPU역시 실행 시 반복이 많은 data flow 알고리즘을 가지므로 많은 over head를 가지게 된다. 검증(verify)은 프로그램코드의 이동성을 보장하는 Java VM의 제어장치라고 할 수 있을 것이다. 검증기는 프로그램이 검증을 거쳐서 특정한 규칙을 따르고 있으며, 이 어플리케이션이 실행됨으로써 다른 어플리케이션 및 device의 안전을 보장하는 것이다. 반드시 필요한 반면 위에서 설명하다시피 embedded device에서는 과도한 performance를 요구하게 된다.. 그래서 나눈 것이 사전검증(pre-verify)과 실행 시 검증(verify)이다. 즉 OFF-Line 사전검증 과 ON-Line 검증인 것이다. <그림 2>를 보도록 하자. MyApp.java라는 애플리케이션을 작성한 후에 컴파일을 수행하면, MyApp.class라는 클래스 파일을 얻을 수 있다. 이 클래스 파일은 자바 가상머신 명세서에 정의된 클래스 파일 포맷을 따른다. 이 클래스 파일을 사전검증기(preverifier)를 통해 사전검증을 하게 되면, 변경된 MyApp.class 파일을 얻게 된다. 이 때, 이 클래스 파일은 CLDC 명세서에 정의된 클래스 파일 포맷을 따르게 된다. 이렇게 사전검증된 클래스 파일을 디바이스에서 다운로드하여 로딩한 후에는 온-디바이스 검증을 수행한다. | |||||||||||||||||||||||||||||||||||
 [ 그림 2 - 클래스 파일 검증 과정 ] | |||||||||||||||||||||||||||||||||||
검증 과정은 프로그램 코드의 네트웍 이동성을 보장하는 자바 가상머신의 안전장치이다. 즉, 검증 과정을 통해서 자바 가상머신은 애플리케이션이 특정한 규칙을 따르고 있음을 확인하고, 이 애플리케이션의 수행이 안전함을 보장할 수 있다. 이것은 애플리케이션이 허락되지 않은 위험한 작업을 수행하지 못하도록 함으로써, 시스템의 안정성을 확보하고, 바이러스 등의 위해한 애플리케이션의 등장을 방지할 수 있게 해 준다. 그러나, 검증 알고리즘을 구현하는 것은 약 50K 정도의 코드 공간이 필요하고, 기존의 검증 과정은 실행시 오버헤드도 크다. 그래서, 사전검증과 실행시 검증이라는 새로운 방법을 CLDC에서 도입한 것이다. 이러한 검증방법을 안전하고 유효하게 만들기 위해서는 몇가지 복잡한 고려를 해야 한다. 그 중에서도 가장 중요한 것은 클래스 파일포맷의 변화이다. 온-디바이스 검증기가 정상적으로 검증을 수행하기 위해서는 사전검증기가 이에 필요한 추가정보를 클래스 파일에 포함시켜야 하고, ‘스택 맵 애트리뷰트’라고 불리는 이러한 추가적인 애트리뷰트를 통해 온-디바이스 검증기는 효율적인 검증을 수행할 수 있다. 추가적인 애트리뷰트로 인해 클래스 파일의 크기는 약 5% 정도 늘어나게 되지만, 온-디바이스 검증기의 크기를 효과적으로 줄일 수 있고, 검증시에 재귀적인 검증을 하지 않고, 1패스 검증을 할 수 있다는 측면에서는 상당한 향상이 있었다고 평가할 수 있다. 다음은 위에서 설명한 사전검증과 실행시 검증으로 분리된 검증방법의 특징들이다.
| |||||||||||||||||||||||||||||||||||
3) 클래스의 로딩과 링킹 | |||||||||||||||||||||||||||||||||||
| CLDC 명세는 JAR(Java ARchive) 파일 포맷을 지원을 강제하고, MIDP 명세는 클래스 파일의 배포를 반드시 JAR(Java ARchive) 파일을 통해서만 이루어 지도록 하고 있다. 이것은 JAR 파일의 사용이 약 30~40% 정도의 대역폭 절감 효과가 있기 때문이다. 물론, 이 때 배포되는 JAR 파일에 포함된 클래스 파일들은 사전검증기에 의해 사전검증이 된 클래스 파일이어야 함은 당연하다. 로딩이란 애플리케이션에서 사용하고자 하는 클래스 파일들을 자바 가상머신으로 전달하는 과정을 말한다. CLDC에서는 JAR 파일의 형태로 네트웍을 통해 전송된 클래스 파일들이 시스템 클래스 로더에 의해 로딩된다. 링킹은 로딩된 클래스 파일, 즉, 바이너리 코드가 자바 가상머신에 의해서 수행될 수 있는 상태로 만드는 과정이다. 이 과정은 로딩된 클래스가 올바른 클래스 포맷을 가지고 있는 지 실행시 검증을 하는 검증(verification) 과정과, 메모리 영역의 할당 등의 예비 과정(preparation), 심볼릭 참조 주소를 직접 참조 주소로 변환하는 결정 과정(resolution) 등으로 세분화할 수 있다. 이 때, 보안상의 이유와 애플리케이션 관리 소프트웨어의 존재로 인해 클래스 파일의 룩업순서가 조금 다르며, 사용자 정의 클래스 로더를 만들 수 없다는 것도 CLDC의 특징이다. 여기서 한가지 강조하고 싶은 문제는 CLDC 디바이스는 대부분 파일시스템이 없다는 것이다. 그러므로, CLDC 명세도 파일시스템에 대한 고려를 하지 않고 있다. 즉, 플래시 메모리를 주 저장장치로 사용하는 CLDC 디바이스의 경우에, 저장공간은 ROM이 아니면 RAM이라는 것이다. 일반적으로 파일 시스템이 보조 기억장치로서 존재하는 PC 시스템의 경우, 자바 가상머신이 수행될 때, 먼저 자바 가상머신이 파일 시스템으로부터 메모리로 올려 진다. 그리고, 클래스 로더가 필요한 시스템 클래스 파일들을 파일시스템으로부터 메모리로 로딩한다. 그리고 나서, 필요한 사용자 정의 클래스 파일들을 파일시스템으로부터 메모리로 로딩한다. 그런데, CLDC 디바이스에서는 가상머신과 시스템 클래스 파일들이 이미 메모리에 존재한다. 그런데, 굳이 로딩과 링킹, 초기화라는 불필요한 절차를 거칠 필요가 있을까? 로마이징(ROMizing)은 이처럼 특정 클래스들을 사전에 미리 로딩하고 링킹해 놓음으로써 애플리케이션의 속도 향상을 가져올 수 있는 기법을 의미한다. CLDC 명세에서는 사전로딩/사전링킹을 통한 로마이징을 구현에 의존적인 기능으로 정의하고 있다. | |||||||||||||||||||||||||||||||||||
4) CLDC 라이브러리 | |||||||||||||||||||||||||||||||||||
자바와 관련한 신기술이 발표될 때 마다, 함께 쏟아져 나오는 API들은 늘 신선함과 함께 부담감으로 작용한다. 필자는 개인적으로 선이 이룩한 가장 기념비적인 업적 중의 하나가 javadoc이라는 문서화 툴의 확산이라고 생각한다. 만일, 그토록 많은 API들의 홍수 속에 살면서, javadoc에 의한 편리하고, 보편적인 문서화가 이루어지지 않았다면, 많은 사람들이 자바를 외면했을 것이라는 생각을 해 본다. 그럼에도 불구하고, 매번 새로운 API를 접하는 것은 상당히 부담스러운 일이다. 그러므로, CLDC에서도 가능하면 모든 API들이 기존의 J2SE API의 서브셋이기를 바라는 것이 자바 개발자들의 공통된 요구일 것이다. 하지만, MIDP를 통해서 더욱 확실히 느끼게 되겠지만, 기존 API와의 호환성은 잊어버리는 게 좋을 정도로 많은 API들이 재정의되었다. 재사용 가능한 API들이라고는 다음 세 가지의 패키지들 중에서도 일부일 뿐이다. 각각의 패키지에 포함된 클래스들은 [표 2]에 정리하였다.
[ 표 2 - CLDC 라이브러리 ] | |||||||||||||||||||||||||||||||||||
5) 프로퍼티 | |||||||||||||||||||||||||||||||||||
[표 2]에서 java.util.Properties를 찾아 보면 찾을 수 없을 것이다. 즉, CLDC에서는 프로퍼티 기능을 지원하지 않는다는 것이다. 다만, System.getProperty(String key) 메소드를 통해서 시스템 프로퍼티에 접근할 수는 있다. 하지만, setProperty() 메소드는 지원되지 않는다는 것을 확인하기 바란다. 그러므로, 애플리케이션 개발자는 시스템 프로퍼티를 변경하거나 새로운 프로퍼티를 생성할 수는 없다. [표 3]은 CLDC에서 정의하는 시스템 프로퍼티들이다. MIDP에서는 지역화를 고려하여 locale 프로퍼티를 추가하였다.
[ 표 3 - 시스템 프로퍼티 ] | |||||||||||||||||||||||||||||||||||
6) 국제화/지역화 | |||||||||||||||||||||||||||||||||||
| 국제화/지역화의 지원은 아직 CLDC/MIDP에서는 제대로 지원을 보장하지 못하고 있다. CLDC에서 유니코드 문자를 바이트로 변환해 주는 변환기를 제한적으로 지원할 뿐이다. 이러한 국제화 지원은 Reader와 Writer를 통해서 이루어지고, 각각에 대해서는 다음과 같은 생성자에서 두 번째 인자로 인코딩 방법을 지정함으로써 코드 변환을 할 수 있다. ISO8859_1 이외의 인코딩 방법에 대해서는 기본적으로 CLDC/MIDP 구현자에게 의존적이며, 날짜, 시간, 통화 등의 포맷에 관련한 지역화에 대해서도 MIDP 구현에 의존적이다. 국제화/지역화 문제는 <표 3>에서와 같이 시스템 프로퍼티에 한글 인코딩과 한국의 로캘을 지정하고, 코드 변환기와 포맷 변화기가 완전히 구현되어야 한다. 선 마이크로시스템즈의 CLDC 1.0 베타와 MIDP Early Access 1에서는 한글 및 지역화 지원이 완벽하지 않다고 한다. 그러나 조만간에 이 문제는 해결이 될 것이라 생각된다. | |||||||||||||||||||||||||||||||||||
7) 애플리케이션 관리 메커니즘 | |||||||||||||||||||||||||||||||||||
| 이 글의 서두에서 모바일 솔루션으로서의 자바의 특장점 중의 하나가 애플리케이션의 동적인 다운로드 기능이라고 했다. 자바 애플릿을 떠올린 분들이 많으실텐데, 이것은 커다란 오해다. CLDC/MIDP 플랫폼에서는 완전히 새로운 애플리케이션 모델을 제시하고 있다. ‘애플리케이션 관리 소프트웨어’라고 불리는 새로운 소프트웨어의 등장은 애플릿과 애플리케이션의 혼합, 혹은 자바 플러그-인의 확장이라고 할 수 있는, 새롭지만, 그리 낯설지 않은 애플리케이션의 배포와 관리 메커니즘을 제공하고 있다. CLDC는 단지 이러한 애플리케이션 관리 소프트웨어의 존재에 대해서만 가정하고 있으며, 실질적인 애플리케이션 모델에 대한 정의는 MIDP에서 이루어 지고 있으므로, 나중에 이 부분을 자세히 살펴보도록 하자. | |||||||||||||||||||||||||||||||||||
8) Generic Connection Framework | |||||||||||||||||||||||||||||||||||
| CLDC에서는 확장 패키지에 포함될 클래스를 정의하는 부분이 있다. javax.microedition.io 패키지가 그것인데, 여기에는 Generic Connection Framework(이하, 커넥션 프레임웍)이라고 이름이 붙은 네트워킹과 입출력에 대한 상위 수준의 프레임웍에 대한 인터페이스 정의가 포함되어 있다. 왜 전혀 새로운 네트워킹과 입출력 프레임웍을 정의해야만 했는가? 이에 대한 해답은 다시 메모리의 제약으로 돌아간다. 기존의 java.net 패키지와 java.io 패키지는 덩치가 너무 크다. 100개 이상의 클래스와 200K 이상의 크기를 가진 이 패키지들은 CLDC 디바이스들에는 적합하지 않다. 게다가, TCP/IP, WAP, iMode, IrDA, Bluetooth라는 새로운 통신방법에 대한 지원과, 파일 시스템이 존재하지 않는 입출력 메커니즘을 하나로 통합할 필요성이 존재했다. 그리고, 그 방법으로 새로운 프레임웍의 정의를 선택한 것이다. 다음은 커넥션 프레임웍의 설계목표이다. CLDC의 커넥션 프레임웍은 네트웍과 입출력을 포함한 모든 연결의 생성에 대해서 다음과 같은 형태의 일관성을 제공한다. Connector.open(“<protocol>:<address>”); 이 일관성의 핵심은 Connector 클래스만으로 모든 연결을 생성할 수 있으며, open() 메소드의 인자를 변경함으로써 연결의 형태를 바꿀 수 있다는 데에 있다. 연결이 성공적이었다면, open() 메소드는 커넥션 프레임웍의 인터페이스들을 구현한 클래스의 인스턴스를 리턴한다. <그림 3>은 커넥션 프레임웍의 계층도에 대해 보여주고 있다. 그리고, <표 5>는 Connector 클래스를 이용해서 여러 프로토콜의 연결을 생성하는 예를 보여주고 있다.
| |||||||||||||||||||||||||||||||||||
|
[ 표 4 - 프로토콜별 연결생성 예 ] | |||||||||||||||||||||||||||||||||||
한 가지 분명히 해 두어야 할 것은 CLDC는 Connector 클래스를 포함해서, 어떠한 실제 구현에 대한 명세도 포함하지 않는다는 점이다. 커넥션 프레임웍은 단지 프레임웍만을 제공할 뿐, 실질적으로 지원할 프로토콜에 대한 정의와 구현은 프로파일의 몫이며, MIDP에서는 HTTP 프로토콜의 지원에 대해서 정의하고 있다. MIDP의 HTTP 지원은 나중에 다시 살펴보도록 하자. | |||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||
|
IONETKOREA E&D 연구소 제공 | |||||||||||||||||||||||||||||||||||
백업의 중요성에 대해서는 앞서 한 포스팅 어느날 블로그글이 싸악 사라져버린다면? 에서 언급을 하였습니다. 하지만 이미 블로그를 시작할때부터 포스팅한 내용을 별도로 백업을 한 사람이 아니라면 블로그의 내용들을 백업한다는 것은 그리 쉬운것이 아닙니다. 하지만 백업의 중요성에 대해서 알았으니 그냥 손놓고 있을수많은 없습니다. 쉬운 백업방법에 대한 대책없이 글을 쓸리는 없겠죠?
웹집(Webzip) 으로 백업 쉽게 하기
지금 소개하려고 하는 webzip 7.1 프로그램은 웹사이트의 내용을 그대로 다운로드해주는 프로그램입니다. 이미 사용을 하고 계시는 분들도 계시겠지만 사용법 또한 매우 쉬워서 누구나 쉽게 블로그 (또는 홈페이지) 글을 본인의 PC에 저장할 수가 있습니다.
웹집 프로그램 다운로드 및 설치
먼저 웹집 7.1 트라이얼 버전을 아래 링크를 클릭하여 다운로드 하시기 바랍니다.
클릭하여 다운로드 하세요 ->
 webzip71_setup.exe webzip71_setup.exe |
다운로드 받은 파일을 실행하여 설치를 합니다. 간단히 next 만 몇번 눌러주면 설치가 되므로 설치과정은 생략하겠습니다.
블로그 백업하기
1. 설치한 웹집을 실행한 다음 "File-New Project"를 클릭합니다.
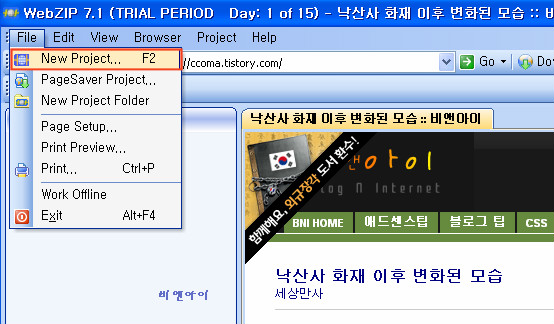
2. 프로젝트정보 입력
1) 아래와 같은 화면이 나오면 Project Name에 본인 블로그를 알아볼 수 있는 이름을 영문으로 입력합니다.
2) Start URL(s) 영역의 하얀 박스안에 백업할 블로그의 주소를 적어줍니다.
(http://ccoma.tistory.com <- 이렇게요 )
3) 제일 아래 부분의 SaveTo Folder 부분은 백업(또는 다운로드)한 파일이 저당되는 곳입니다. 저장위치를 수정해줘도 되고 수정을 하지 않을거라면 저장위치를 기억해두시기 바랍니다.
4) 이제 하단의 "Run Now " 버튼을 클릭하면 백업을 시작합니다.

- Now Downloading
왼쪽 사이트 아래에서 Now Downloading을 누르면 웹사이트로부터 다운로드 받는 상황을 보여줍니다. 그다지 큰 볼거리는 없는것 같습니다.
Local Files
Local Files를 누르면 내 PC에 저장된 블로그(또는 웹사이트의 웹페이지)의 글들의 목록과 내용까지 볼 수가 있습니다. 그림에서는 제 블로그(ccoma.tistory.com) 글을 다운로드 받고 현재까지 백업받은 내용을 보는 그림입니다.
좀더 확대를 해보겠습니다.
우측에 1.html, 2.html 등으로 표시되는 파일이 블로그에 올린 글입니다. 블로그주소 http://ccoma.tistory.com/1에 해당되는 글이 1.html에 저장이 되어 있습니다. 이렇게 해서 본인의 마지막블로그 주소까지 숫자가 나오면 모두 백업이 된것입니다. 아니 이렇게 좋을 수가! ^^
 |
정리할 파일들
웹집은 블로그에 링크로 연결된 내용들을 모두 다운로드 하여 저장을 하다 보니 글이 중복되어 저장이 됩니다. 중복된 자료의 경우 삭제를 하시면 됩니다.
 |
위와 같이 번호.html (463.html, 464.html등)을 빼고는 글자가 깨진 파일명은 지워도 됩니다.
백업된 파일 확인하기
백업된 8.html 을 더블클릭하여 확인을 해보면 실제 블로그내용과 똑 같이 다운로드 되어있는것을 볼수가 있습니다. 심지어는 블로그에 삽입한 광고마저도 그대로저장이 되어 있네요. 이부분은 조금 불필요한 부분이긴 하지만 원래 웹집이 웹에 표시되는 모든 내용을 저장하다 보니 어쩔 수가 없습니다.
백업된파일 내용 보기

웹집의 단점
티스토리의 경우 이미지나 미디어파일 저장이 되지 않는다는 점입니다. 이유는 티스토리의 경우 이미지나 동영상파일은 그 파일명을 변경하여 확장자가 없는형태로 제공을 하기 때문입니다. 즉 일반적인 이미지의 경우 확장자가 jpg나 png, gif인데 이러한 확장자가 이미지경로에 표시되지 않고 http://cfs15.tistory.com/image/30/tistory/2008/11/19/00/01/4922d8ad56ed9 와 같은 형태로 경로가 표시되어 이미지가 저장이 되지 않는것입니다. 하지만 대부분 찍은 사진은 보관을 하고 있기 때문에 큰 문제는 없을거라는 생각을 해봅니다. (방법이 있는지는 연구를 해봐야겠습니다)
또하나 웹집 트라이얼버전은 설치후 15일동안만 사용할 수 있습니다. 추후 백업시는 삭제후 다시 설치하여 백업을 해야 하는 불편함이 있습니다.
이후...
웹집을 이용하여 이렇게 백업을 해놓으면 이 다음부터는 추가되는 포스트만 별도로 백업을 받을 수가 있습니다. 방법은 바로 위의 2번단계에서 2)번 설명에서 블로그 주소적는란에 기존내용은 모두 지워버리고 포스트주소를 나열한다음 백업을 받으면 됩니다. 예를 들어 http://ccoma.tistory.com/475 와 같은 형식으로 줄을 바꿔가면서 입력해준다음 백업을 받으면 된답니다.
저는 유용하게 사용하고 있는데 여러분들에게도 도움이 되었으면 좋겠네요!
출처 : http://ccoma.tistory.com/477?_new_tistory=new_title
JAVA 환경변수 설정
시스템변수(S)에서 설정
1. 변수값 : path(맨끝에) : 수정
변수값 : ;%JAVA_HOME%\bin
2. 변수이름 : CLASSPATH : 생성
변수값 : .;%JAVA_HOME%\lib\tools.jar
※ 앞에 .; <= 주의할것 빼먹지말것
3. 변수이름 : JAVA_HOME : 생성
변수값 : C:\Program Files\Java\jdk1.5.0_16
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
TOMCAT 환경변수 설정 (tomcat은 설치하는거 없이 압축풀면 설치끝)
시스템변수(S)에서 설정
변수이름 : CATALINA_HOME - 생성
변수값 : d:\www\apache-tomcat-5.5.27
톰캣Start : apache-tomcat-5.5.27\bin\startup.bat
톰캣Shutdown : apache-tomcat-5.5.27\bin\shutdown.bat
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Servlet 설정 (web.xml 수정)
Tomcat이 설치된 폴더 => \conf\web.xml
ex> apache-tomcat-5.5.27\conf\web.xml
※ 기본적으로 보안상 Servlet은 막혀있으므로 Servlet개발을 위해서
주석을 제거하여 사용 환경을 만든다.
1. "invoker" 찾기
########################################################
# <!-- #
# <servlet> #
# <servlet-name>invoker</servlet-name> #
# <servlet-class> #
# org.apache.catalina.servlets.InvokerServlet #
# </servlet-class> #
# <init-param> #
# <param-name>debug</param-name> #
# <param-value>0</param-value> #
# </init-param> #
# <load-on-startup>2</load-on-startup> #
# </servlet> #
# --> #
########################################################
[▲ 이부분을 찾는다]
2. 주석제거 <!--, --> 이것만 삭제할것
########################################################
# <servlet> #
# <servlet-name>invoker</servlet-name> #
# <servlet-class> #
# org.apache.catalina.servlets.InvokerServlet #
# </servlet-class> #
# <init-param> #
# <param-name>debug</param-name> #
# <param-value>0</param-value> #
# </init-param> #
# <load-on-startup>2</load-on-startup> #
# </servlet> #
########################################################
[▲ 이렇게 만들면 됨]
3. Servlet Mapping의 주석도 제거("invoker" 찾기)
########################################################
# <!-- The mapping for the invoker servlet --> #
# <!-- #
# <servlet-mapping> #
# <servlet-name>invoker</servlet-name> #
# <url-pattern>/servlet/*</url-pattern> #
# </servlet-mapping> #
# --> #
########################################################
[▲ 이부분을 찾아서 주석제거, ▼ 이렇게 만든다]
########################################################
# <!-- The mapping for the invoker servlet --> #
# #
# <servlet-mapping> #
# <servlet-name>invoker</servlet-name> #
# <url-pattern>/servlet/*</url-pattern> #
# </servlet-mapping> #
# #
########################################################
4. web.xml을 저장하고 닫는다.
※ Servlet를 작성하기위해 API를 연결한다.
여기서는 Tomcat에 있는 servlet-api.jar파일을 이용한다.
EJB를 개발한다면 JavaEE를 설치하는게 좋다.
5. tomcat\common\lib\
위의 경로에서 servlet-api.jar파일을 복사하여
Program Files/Java/jdk/lib/
위의 lib폴더에 복사
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Servlet 환경변수 설정
시스템변수(S)에서 설정
1. 변수값 : CLASSPATH : 지금까지 설정되있는것
변수값 : .;%JAVA_HOME%\lib\tools.jar
2. jar파일 복사
원본파일 : 톰캣경로\common\lib\servlet-api.jar (복사)
사본파일 : C:\Program Files\Java\jdk1.5.0_16\lib\servlet-api.jar (여기에 복사할것)
3. 변수값 : CLASSPATH(맨끝에) : 수정
변수값 : .;%JAVA_HOME%\lib\tools.jar;C:\Program Files\Java\jdk1.5.0_15\lib\servlet-api.jar
위치 : 톰캣경로\common\lib\servlet-api.jar
※ 뒤에 servlet-api파일의 경로만 넣어주면된다.
;C:\Program Files\Java\jdk1.5.0_15\lib\servlet-api.jar
※ tomcat이설치된 경로\webaps\ROOT\WEB-INF\
classes란 폴더를 만든다. (WEB-INF 폴더아래에)
※ Servlet은 웹 어플리케이션 폴더 아래에
WEB-INF\classes폴더가 존재해야함
※ sevlet가 잘돌아가는지 확인하는것은
classes폴더에 servlet파일을 넣고
웹브라우저에 http://127.0.0.1/servlet/서블릿파일(확장자빼고)
실행되는지 볼것 ( servlet도 java기반이기때문에 대소문자 구분.. 조심!! )
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Eclipse 설치
PHP에 대해 알듯 모를듯하시는 분이 계시는것 같아 몇줄 적어 보았습니다.
저도 배우는 중이라 100% 맞는다고는 할 수 없지만 개념정도를 이해하시면 될 것입니다
1. 질문들이 PHP라 어렵다...뭐 그러시는 분들이 많으신것 같습니다,
그러나 질문내용을 보면 대부분이 HTML에 관한 질문들입니다...
화면을 구획으로 나누고, 테투리를 설정하고, 그림 등으로 장식하고 하는일은
전부 HTML이 하는 일이라고 보시면 됩니다.
즉 잘... 아주 잘..... 구성된 구획안에 ..... 여기까지는 HTML
어떤 값 (데이터값,그림등)을 채워 넣는 단순한 역할을 하는 것이 PHP(mySQL쿼리)리고 보시면 됩니다.
2. 정리들어갑니다..
사용자의 PC의 브라우저가 해석하는것은 HTML 입니다.
그러므로 PHP는 사용자PC(Client)에서 적용되는 것이 아니고 웹서버에서 적용되는 것이지요
정리 : 사용자 PC는 HTML을 웹서버는 PHP을 해석한다고 보면 되겠네요
3. 우리가 흔히 아는 HTML 을 아래와 적었다면
<table>
<tr>
<td>
제목 1
</td>
</tr>
</table>
화면출력은 '제목 1' 이라고 달랑 한줄 나옵니다. 動적이 아니라 靜적 이지요.....
아무 가감없이 즉 주는대로 나옵니다.
4. 여기다가 동적 값을 구현해 주는게 PHP라고 보시면 됩니다.
동적 값을 구현하려면 아래와 같이 해주어야 할 것 같군요
즉, 아래의 예문에서
'DB에서 제목줄을 읽어 그내용을 출력' 대신에
웹서버에서 수행 할 명령을 적어주면 된다는 것 입니다
<table>
<tr>
<td>
DB에서 제목줄을 읽어 그내용을 출력 ---> 대신에 명령을 적어줌으로 각기 다른값들이 출력됨
</td>
</tr>
</table>
5. 상기의 'DB에서 제목줄을 읽어 그내용을 출력' 대신에
아래와 같은것을 적어 웹서버에 명령을 내려 볼까요.
reeboard에서 번호 1번인것을 읽어서 그내용중 제목을 출력하라는 의미입니다
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){
echo $data[subject];
}
그러면 웹서버에서 상기명령을 수행한후 그 결과값을 업로드 할 것입니다.
즉 명령 내용에 따라 구획안에 들어갈 값이 변경 됩니다. 그걸 동적이라고 표현한 것입니다
6. 이해가 되셨으면 브라우저가 수행할 명령과 웹서버가 수행할 명령을 합쳐 볼까요...
합치기 전 우선 두가지의 명령의 구분을 위해서 웹서버가 실행할 명령의 앞,뒤에 <?, ?>를 붙여 봅니다
<?
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){
echo $data[subject];
}
?>
브라우저 명령(html)과 웹서버 명령(<?, ?>)을 구분하였으니 이젠 합쳐 봅니다. 아래와 같이 되겠습니다.
<table>
<tr>
<td>
<?
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){
echo $data[subject];
}
?>
</td>
</tr>
</table>
7. 이 파일을 수행하면 결과는 아래와 같이 될것 같군요..
아마 프리보드의 제일 처음 레코드의 제목 "보드생성이 완료" 정도가 출력 될 것 같군요..
어쨋든 지정된 글자(정적인 글자)가 아닌 보드의 활성데이터(동적)인 데이터를
출력하게끔 만들어 주는것이 PHP라고 보면 되겠네요.
8. 또 정리 들어갑니다... client 와 web server 간의 작업순서를 나타낸 것입니다.
가. 클라이언트(Client:사용자의 PC)
▽
▽ 클릭함으로써 보여줄 내용의 파일을 요청하게 됨
▽ 클릭한곳에 링크된 내용을 보여줄 파일을 요청(예;board.php 파일등)
▽
나. 웹서버(Web Server:apache iis등)
▽
▽ 웹서버가 보여줄 내용의 파일을 보니 내용에 PHP가 있다,그러면 PHP를 실행.
▽ PHP 실행후 실행 결과를 HTML 텍스트로 만들어 클라이언트에 업로드
▽
다. 클라이언트(Client:사용자의 PC)
▽
▽ 웹서버로 부터 전송되어온 HTML 파일을 해석하여 화면 출력(브라우저)
▽
라. 클라이언트(Client:사용자의 PC 화면 출력)
상기의 '나' 번에서 웹서버가 수행할 명령들을 내려주는것이
파일내에서 <?....?>로 감싸져 있는 PHP 내용이 되겠네요.
9 약간 무리하게 내용을 구성한다면 아래와 같이 하셔도 되긴 됩니다만...
하여간 이렇게 해도 된다는것을 보여드리기 위해..
아래와 같이 명령 전체를 웹서버에 떠넘기는 것이지요..
<?
echo "<table>
<tr>
<td>";
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){
echo $data[subject];
}
echo " </td>
</tr>
</table>";
?>
위의 예에서 스페이스는 인식하기 좋게 하기 위한 목적으로 대충 띄운 것입니다.
별 의미가 없단 얘기입니다.
가. 이렇게 하면 아무의미없이 echo 명령에 의해 <table><tr><td> 등을 쓸것이고
나. 그다음에 동적인 명령으로으로 테이블을 읽어오고 쓰고
다, 또다시 아무런 의미 없이 echo 명령에 의해 </td></tr></table> 등을 쓸것입니다
프로그램의 효율성이 문제가 되겠지만 어쨋던 결과는 똑 같아집니다..
10. 또는 아래와 같이 써도 결과는 똑 같습니다..
<table>
<tr>
<td>
<?
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){}
?>
<?= $data[subject]?>
</td>
</tr>
</table>
여기서 <?=$변수명?> 은 그변수가 가지고 있는 값을 출력하라는 명령입니다
11. 또는 아래와 같이 써도 결과는 똑 같습니다.. 가장 많이 쓰는 방식이기도 합니다
<?
while($Data = mysql_fetch_array(@mysql_query("select * from a_tn2_freeboard_list where no=1"))){}
?>
<table>
<tr>
<td>
<?= $data[subject]?>
</td>
</tr>
</table>
여기서 <?=$변수명?> 은 그변수가 가지고 있는 값을 출력하라는 명령입니다
12. 이해하셨다면.....우리가 어떤 화면을 소스보기하여 보면
소스보기의 내용에는 PHP 프로그램은 없고 HTML 내용만 있는지 아실 겁니다.
그것은 웹서버에서 수행한 결과를 브라우저가 해석해서 화면에 뿌려주기 때문에
화면상에는 결과값만 있는 것입니다...
13. 이상 간단 개념 정리입니다... 그래도 의문점이 있으시면 질문주십시요...
초보분들은 한번씩 읽으시고 간단개념 정리를 하셔요..
개념정리가 어쩌면 더 중요할지도 모르기 때문입니다..
대충 이해가 되셨으리라 생각하고 이만 줄입니다.. 도움되시기를..
[출처] 왕초보, 왕비초보를 위한 PHP 개념정리 (테크노트PHP) |작성자 테크노트
// 네임스페이스 만들기
create tablespace Oracletable
datafile 'e:\OracleDB\Oracletable.dbf' size 10m
autoextend on next 100m maxsize 1000m online;
//아이디 생성 및 네임스페이스 연결
create user oldb identified by oldb
default tablespace Oracletable;
//권한부여
grant connect, resource to oldb;
//테이블생성 및 필드값 추가
create Table Dept (Deptno Number(3) Primary Key,
Dname Varchar2(10) UNIQUE,
Loc Varchar2(10)) ;
Insert Into Dept Values(10, '총무부','서울');
Insert Into Dept Values(20, '영업부','대전');
Insert Into Dept Values(30, ‘전산부’,’부산’);
Insert Into Dept Values(40, '관리부', ‘광주’);
// 수정
alter table imsi add (tel number(5)); - > 추가
alter table samp modify (tel varchar2(10)); -> 데이타 타입 변경
alter table samp modify (tel varchar2(30)); -> 칼럼의 폭 변경
insert into samp values(‘kim’,20,’123-3456’) ; -> 데이타 추가
alter table samp modify (tel varchar2(14)); -> 칼럼의 폭 축소는 불가
alter table samp add constraint samp_name_uq unique(name); -> 유일성 부여
//삭제
DROP TABLE 테이블명
// 필드삭제....
alter table imsi drop column temp02;
// 필드값 업데이트
update imsi a set id='변경아이디' where id='아이디';
//조건 삭제
delete from imsi where no='2';
------------------------------------
/* dbf 데이터 파일 경로 및 개수 확인 */
select file_name from dba_data_files;
/* 모든 사용자 이름 조회 */
select * from all_users;
select * from tablespace;
/* 모든 테이블 스페이스 확인 */
select a.tablespace_name, a.bytes/1024/1024 || 'M' total, substr(a.file_name,1,50), b.free || 'M' from DBA_DATA_FILES a,
(select tablespace_name, sum(bytes)/1024/1024 free from DBA_FREE_SPACE group by tablespace_name) b
where a.tablespace_name = b.tablespace_name
/* 모든 테이블 스페이스 확인 */
SELECT USERNAME, DEFAULT_TABLESPACE, TEMPORARY_TABLESPACE FROM DBA_USERS;
SELECT TABLE_NAME, TABLESPACE_NAME FROM USER_TABLES;
1. Import 유틸리티 사용
Export 를 사용하여 백업을 받은 경우 처리 할 수 있는 방법
Import 방법 ( 자세한 사항은 오라클 유틸리티 매뉴얼을 참조 )
- imp 오라클사용자명/암호@TNS명 file=덤프파일명 fromuser=ExportID touser=ImportID ignore=yes
- 예) imp userid=erprail/erprail@RAIL file=C:\erprail_mon.dmp fromuser=erprail touser=erprail ignore=yes
일반적 경고
- 1) Export 사용자와 Import 사용자의 ID가 틀린 경우
- 2) Export 객체들의 테이블 스페이스와 Import 테이블 스페이스 이름이 다른 경우
- 3) Export 테이블스페이스 스토리지 옵션과 덤프할 데이터가 맞지 않은 경우 ( Initial 사이즈가 너무 크거나 작다거나 등 )
일반적 경고 해결 방법
- 2) 덤프 파일에서 테이블 생성 스크립트 추출하기 : imp 명령의 indexfile 옵션을 이용한다
: imp 사용자명/암호@TNS명 file=덤프파일이름 fromuser=Export사용자ID touser=ImportID indexfile=ScriptFile
- 3) Spool / TAB View 를 활용 하여 처리 함
: spool drop.sql ( 파일 명 임 ) select 'drop table '||table_name||';' from tabs; spool off ( 실행방법 @파일명 임 )
: 실행도중 Referencial Integrity Error 발생시 수동 Drop 을 시켜 주면서 복구
출처 : http://gtko.springnote.com/pages/723356
1. BACKUP 명령 옵션
- 물리적 블록 손상을 검사한다.
- 논리적 손상 및 물리적 손상을 스캔 한다.
- 중지 전에 허용된 손상 감지 수에 대한 임계값을 설정한다.
- 백업 작업을 수행하기 전에 대상 입력 파일을 검증한다.
- 백업 셋을 이중화한다.
- 기존 백업 셋 또는 Image Copy를 겹쳐 사용한다.
- 저장 장치와 디스크의 데이터 파일 간 데이터 전송에 대한 제어를 Media management층에 전달한다.
- 백업 파일을 암호화(encryption)한다. (10g 10.2c R2 부터 가능)
2. 아카이브된 리두 로그 백업
- 온라인 리두 로그 파일 스위치는 자동으로 발생한다.
- 아카이브된 로그 failover가 수행된다.
- 백업할 아카이브된 리두 로그의 범위를 지정할 수 있다.
- 아카이브된 리두 로그 파일의 백업 셋은 다른 유형의 파일을 포함할 수 없다.
( 데이터파일, 컨트롤파일, 아카이브 리두 로그 파일을 백업 했을때 데이터파일과 컨트롤파일은 같은 백업 셋에 들어갈 수 있지만 아카이브 리두 로그 파일은 별도의 백업 셋에 저장되어야 한다. )
예)
RMAN> BACKUP
2> FORMAT '/disk1/backup/ar_%t_%s_%p'
3> ARCHIVELOG FROM SEQUENCE=234
4> DELETE INPUT;
- 슬라이드에 표시된 예제는 Sequence Number가 234 이상인 아카이브된 리두 로그를 모두 백업 셋에 백업한다.
- 아카이브된 로그는 복사된 후 디스크에서 삭제되며 V$ARCHIVED_LOG뷰에도 삭제된 것으로 표시된다.
3. Whole 데이터베이스 백업
- 두 개 이하의 백업 복사본이 필요한 경우 불필요한 recovery 파일 나열
RMAN> REPORT OBSOLETE REDUNDANCY 2;
- 백업 셋 키가 4인 백업 셋 삭제
RMAN> DELETE BACKUPSET 4;
- recovery 파일에 백업이 두 개를 초과하므로 불필요한 것으로 간주되는 파일 삭제
RMAN> DELETE OBSOLETE REDUNDANCY 2;
7. EM을 사용하여 백업 관리
Database Home 페이지 > Maintenance > Manage Current Backups
- repository 상호 확인:
* repository에 나열된 백업이 존재하고 이 백업에 액세스할 수 있는지 확인
* 상호 확인 작업 시 백업에 액세스할 수 없으면 만료된 것으로 표시
- RMAN repository에서 만료된 백업의 레코드 삭제
- repository 및 디스크에서 불필요한 백업 삭제
8. RMAN 동작 뷰
※ 다음 뷰를 사용하여 컨트롤 파일에 저장된 RMAN 정보를 얻을 수 있다.
- V$ARCHIVED_LOG는 어떤 아카이브가 데이터베이스에서 생성되고 백업되고 지워졌는지 보여준다.
- V$BACKUP_CORRUPTION은 백업 셋을 백업하는 중에 발견한 손상 블록을 보여준다.
- V$BACKUP_DATAFILE은 각 데이터 파일의 블록 수를 확인하여 동일한 크기의 백업 셋을 생성하는 데 유용하다.
또한 데이터 파일의 손상된 블록 수도 알 수 있다.
- V$BACKUP_DEVICE는 지원되는 백업 장치에 대한 정보를 표시한다.
특수 장치 유형 DISK는 항상 사용할 수 있기 때문에 이 뷰에 의해 반환되지 않는다.
- V$BACKUP_FILES는 모든 RMAN 백업(Image Copy 및 백업 셋 모두) 및 아카이브된 로그에 대한 정보를 표시한다.
이 뷰는 LIST BACKUP 및 LIST COPY RMAN 명령을 시뮬레이트한다.
- V$BACKUP_PIECE는 백업 셋에 생성된 백업 피스를 보여준다.
- V$BACKUP_REDOLOG는 백업 셋에 저장된 아카이브된 로그를 보여준다.
- V$BACKUP_SET은 생성된 백업 셋을 보여준다.
- V$BACKUP_SPFILE은 백업 셋의 서버 파라미터 파일에 대한 정보를 표시한다.
- V$COPY_CORRUPTION은 Image Copy 중에 발견한 손상 블록을 보여준다.
9. RMAN 백업 모니터
- SET COMMAND ID 명령을 사용하여 서버 세션과 채널을 상호 연관짓는다.
- V$PROCESS 및 V$SESSION을 query하여 어떤 세션이 어떤 RMAN 채널에 대응되는지 확인한다.
- V$SESSION_LONGOPS를 query하여 백업 및 복사본의 진행 상태를 모니터한다.
- 운영 체제 유틸리티를 사용하여 프로세스 또는 스레드를 모니터한다.
Oracle Database 10g: DBA를 위한 20가지 주요 기능
원문 : http://www.oracle.com/technology/global/kr/pub/articles/10gdba/index.html
1주 — 플래시백 버전 질의
2주 — 롤백 모니터링
3주 — 테이블스페이스 관리
4주 — Oracle Data Pump
5주 — Flashback Table
6주 — Automatic Workload Repository
7주 — SQL*Plus의 향상된 기능
8주 — Automatic Storage Management
9주 — RMAN
10주 — 감사기능의 확장
11주 — Wait 인터페이스
12주 — Materialized Views
13주 — Enterprise Manager 10g
14주 — Virtual Private Database
15주 — 세그먼트의 관리
16주 — Transportable Tablespace
17주 — Automatic Shared Memory Management
18주 — ADDM과 SQL Tuning Advisor
19주 — Scheduler
20주 — 그 밖의 주요 기능
첫번째.
사진이 아닌 동영상으로: Flashback 버전 질의
전혀 아무런 설정 없이도 행의 모든 변경 내용을 즉시 식별 가능
Oracle9i Database에는 Flashback 질의 형태의 소위 “타임 머신” 기능이 이미 도입된 바 있습니다. DBA는 이 기능을 통해 실행 취소 세그먼트에 블록의 이전 이미지 복사본이 있으면 열의 값을 특정 시간으로 확인할 수 있습니다. 하지만 Flashback 질의는 두 시점 간의 변경된 데이타를 표시하는 대신 데이타의 고정된 스냅샷을 시간으로 나타내는 데 그칩니다. 외환 관리 등과 관련된 일부 애플리케이션에서는 값 데이타의 변경 내용을 두 시점에서가 아닌 일정 기간으로 확인해야 합니다. Oracle Database 10g에는 Flashback 버전 질의 기능이 있어 이러한 작업을 쉽고 편리하게 수행할 수 있습니다.
테이블 변경 내용 질의
이 예에서는 은행의 외환 관리 애플리케이션을 사용했습니다. 데이타베이스에는 특정 시간의 환율을 기록하는 RATES라는 테이블이 있습니다.
SQL> desc rates
Name Null? Type
----------------- -------- ------------
CURRENCY VARCHAR2(4)
RATE NUMBER(15,10)
이 테이블에는 CURRENCY 열에 표시된 기타 여러 통화에 대한 US 달러의 환율이 표시됩니다. 재무 서비스 업계에서는 환율을 단순히 변경될 때마다 업데이트하는 대신 지속적인 기록으로 관리합니다. 이 접근방법은 은행 거래가 “이미 지난 시간”에 이루어져 송금으로 인한 시간상의 손실을 수용할 수 있기 때문에 채택되는 것입니다. 예를 들어, 오전 10:12에 이뤄지지만 오전 9:12에 발효된 거래는 현재 시간이 아닌 오전 9:12의 환율이 적용됩니다.
지금까지는 환율 기록 테이블을 생성해 환율 변경 내용을 저장한 후 해당 테이블에 기록이 있는지 질의할 수 밖에 없었습니다. 이 밖에도 RATES 테이블 자체에 특정 환율이 적용되는 시작 시간과 종료 시간을 기록하는 방법이 있었습니다. 변경 내용이 발생하면 기존 행의 END_TIME 열이 SYSDATE로 업데이트되며 END_TIME이 NULL인 새 환율과 함께 행이 새로 삽입되는 것입니다.
하지만 Oracle Database 10g에는 Flashback 버전 질의 기능이 있어 기록 테이블을 유지하거나 시작 및 종료 시간을 저장할 필요가 없습니다. 대신 이 기능을 사용하면 추가로 설정하지 않고도 과거의 특정 시간에 해당하는 행의 값을 가져올 수 있습니다.
예를 들어, 일상 업무를 수행하는 DBA가 환율을 여러 번 업데이트하거나, 때로는 행을 삭제하고 다시 삽입하기도 한다고 가정합니다.
insert into rates values ('EURO',1.1012);
commit;
update rates set rate = 1.1014;
commit;
update rates set rate = 1.1013;
commit;
delete rates;
commit;
insert into rates values ('EURO',1.1016);
commit;
update rates set rate = 1.1011;
commit;
이러한 일련의 작업이 끝나면 DBA는 다음과 같은 RATE 열의 현재 커밋된 값을 얻게 됩니다.
SQL> select * from rates;
CURR RATE
---- ----------
EURO 1.1011
이 결과에는 행을 처음 생성했을 때부터 발생한 모든 변경 내용이 아닌 RATE의 현재 값이 표시됩니다. 따라서 Flashback 질의를 사용하면 해당 시점의 값을 검색할 수 있지만, 여기서 보다 핵심적인 의도는 단순히 특정 시점에 얻은 일련의 스냅샷이 아니라 캠코더를 통해 변경 내용을 기록하는 것 같이 변경 내용의 감사추적(Audit Trail)을 구축하려는 것입니다.
다음 질의에는 테이블의 변경 내용이 나와 있습니다.
select versions_starttime, versions_endtime, versions_xid,
versions_operation, rate
from rates versions between timestamp minvalue and maxvalue
order by VERSIONS_STARTTIME
/
VERSIONS_STARTTIME VERSIONS_ENDTIME VERSIONS_XID V RATE
---------------------- ---------------------- ---------------- - ----------
01-DEC-03 03.57.12 PM 01-DEC-03 03.57.30 PM 0002002800000C61 I 1.1012
01-DEC-03 03.57.30 PM 01-DEC-03 03.57.39 PM 000A000A00000029 U 1.1014
01-DEC-03 03.57.39 PM 01-DEC-03 03.57.55 PM 000A000B00000029 U 1.1013
01-DEC-03 03.57.55 PM 000A000C00000029 D 1.1013
01-DEC-03 03.58.07 PM 01-DEC-03 03.58.17 PM 000A000D00000029 I 1.1016
01-DEC-03 03.58.17 PM 000A000E00000029 U 1.1011
행을 삭제하고 다시 삽입했더라도 여기에 행의 모든 변경 내용이 표시됩니다. VERSION_OPERATION 열에는 행에서 수행한 작업(삽입/업데이트/삭제)이 나타나며, 이를 위한 모든 과정이 기록 테이블이나 추가 열 없이 이뤄집니다.
위의 질의에서 versions_starttime, versions_endtime, versions_xid, versions_operation 열은 ROWNUM, LEVEL 같이 친숙한 열과 유사한 의사(Pseduo) 열입니다. VERSIONS_STARTSCN 및 VERSIONS_ENDSCN 같은 다른 의사 열에는 해당 시간의 시스템 변경 번호(SCN)가 표시됩니다. 또한 versions_xid 열에는 행을 변경한 트랜잭션 식별자가 표시됩니다. 트랜잭션의 상세 내역은 FLASHBACK_TRANSACTION_QUERY 뷰에 나와 있으며, 여기서 XID 열에는 트랜잭션 ID가 표시됩니다. 예를 들어, 위에서 VERSIONS_XID 값인 000A000D00000029를 사용하면 UNDO_SQL 값에 실제 문이 표시됩니다.
SELECT UNDO_SQL
FROM FLASHBACK_TRANSACTION_QUERY
WHERE XID = '000A000D00000029';
UNDO_SQL
----------------------------------------------------------------------------
insert into "ANANDA"."RATES"("CURRENCY","RATE") values ('EURO','1.1013');
이 뷰에는 실제 문 외에도 커밋의 타임 스탬프와 SCN을 비롯해 질의 시작 시의 SCN과 타임 스탬프가 표시됩니다.
기간 내 변경 내용 확인
이제 이러한 정보를 효과적으로 사용하는 방법에 대해 알아보도록 하겠습니다. 오후 3:57:54의 RATE 열 값을 확인해야 한다고 가정하면 다음과 같이 실행할 수 있습니다.
select rate, versions_starttime, versions_endtime
from rates versions
between timestamp
to_date('12/1/2003 15:57:54','mm/dd/yyyy hh24:mi:ss')
and to_date('12/1/2003 16:57:55','mm/dd/yyyy hh24:mi:ss')
/
RATE VERSIONS_STARTTIME VERSIONS_ENDTIME
---------- ---------------------- ----------------------
1.1011
이 질의는 Flashback 질의와 유사합니다. 위의 예에서 시작 및 종료 시간은 NULL로 해당 시간 간격 동안 환율이 변하지 않았으며 시간 간격을 포함하고 있음을 나타냅니다. 또한 SCN을 사용하면 이전 버전 값을 확인할 수 있으며, SCN 번호는 의사 열인 VERSIONS_STARTSCN 및 VERSIONS_ENDSCN에서 가져옵니다. 다음은 이에 대한 예입니다.
select rate, versions_starttime, versions_endtime
from rates versions
between scn 1000 and 1001
/
키워드 MINVALUE 및 MAXVALUE를 사용하면 실행 취소 세그먼트의 모든 변경 내용이 표시됩니다. 특정 날짜 또는 SCN 값을 범위의 끝점 중 하나로 지정하고 다른 끝점을 리터럴 MAXVALUE 또는 MINVALUE로 지정할 수도 있습니다. 예를 들어, 다음은 전체 범위가 아닌 오후 3:57:52부터의 변경 내용을 알려주는 질의입니다.
select versions_starttime, versions_endtime, versions_xid,
versions_operation, rate
from rates versions between timestamp
to_date('12/11/2003 15:57:52', 'mm/dd/yyyy hh24:mi:ss')
and maxvalue
order by VERSIONS_STARTTIME
/
VERSIONS_STARTTIME VERSIONS_ENDTIME VERSIONS_XID V RATE
---------------------- ---------------------- ---------------- - ----------
01-DEC-03 03.57.55 PM 000A000C00000029 D 1.1013
01-DEC-03 03.58.07 PM 01-DEC-03 03.58.17 PM 000A000D00000029 I 1.1016
01-DEC-03 03.58.17 PM 000A000E00000029 U 1.1011
최종 분석
Flashback 버전 질의는 틀을 벗어나 테이블 변경 내용의 짧은 휘발성 값(value) 감사(Audit)를 복제합니다. 이러한 이점을 통해 DBA는 과거의 특정 값이 아니라 일정 기간의 모든 변경 내용을 가져오므로 실행 취소 세그먼트(Undo Segment)의 데이타를 최대한 활용할 수 있습니다. 따라서 최대한으로 사용할 수 있는 버전은 UNDO_RETENTION 매개변수에 달려있다고 하겠습니다.
Flashback 버전 질의에 대한 자세한 내용은 Oracle Database Concepts 10g Release 1 (10.1) 설명서의 관련 섹션을 참조하십시오.
두번째.
얼마나 더 걸리나요?: 롤백 모니터링
롤백 작업 시간의 정확한 예측
아직 멀었나요? 얼마나 더 걸리죠?
귀에 익은 말들입니까? 이런 질문은 아이들이 좋아하는 테마 공원에 가는 도중 갈수록 횟수를 더하며 끊임없이 뒷좌석에서 들려올 수 있습니다. 이럴 때, 앞으로 정확히 얼마나 더 걸릴지 말해주거나 적어도 그 답을 혼자만이라도 알고 있다면 낫지 않겠습니까?
긴 실행 트랜잭션을 롤백했을 때도 이와 마찬가지로 여러 사용자들이 바짝 따라다니며 같은 질문을 하는 경우가 많습니다. 롤백이 진행되면서 트랜잭션에 잠금이 발생하고 일반적인 처리 성능이 저하되므로 이러한 질문을 하는 것은 당연합니다. Oracle 9i Database 이전 버전에서는 다음 질의를 실행하면,
SELECT USED_UREC
FROM V$TRANSACTION;
현재 트랜잭션에서 사용하는 실행 취소 레코드 수를 반환하며, 반복해서 실행하면 롤백 프로세스가 진행되면서 실행 취소 레코드가 해제되므로 계속해서 줄어든 값이 표시됩니다. 그런 다음 일정 간격의 스냅샷을 얻어 비율을 계산한 후 결과를 추정하여 종료 시간을 예측할 수 있습니다.
V$TRANSACTION 뷰에 START_TIME이라는 열이 있지만, 이 열에는 전체 트랜잭션의 시작 시간만 표시됩니다(즉, 롤백 실행 전). 따라서 실제로 롤백을 실행한 시간을 알 수 있는 방법은 추정뿐입니다.
트랜잭션 롤백을 위한 통계 확장
Oracle Database 10g에서는 이 과제를 간단히 수행할 수 있습니다. 트랜잭션을 롤백하면 이벤트가 V$SESSION_LONGOPS 뷰에 기록되어 긴 실행 트랜잭션을 표시합니다. 롤백을 위한 프로세스가 6초 이상 걸리는 경우 레코드가 뷰에 나타납니다. 롤백의 실행이 끝나면 모니터 스크린을 가리고도 다음 질의를 실행할 수 있을 것입니다.
select time_remaining
from v$session_longops
where sid = <sid of the session doing the rollback>;
이제 이 V$SESSION_LONGOPS 뷰가 얼마나 중요한지 알았으니 이 뷰의 다른 기능들에 대해 살펴보도록 하겠습니다. Oracle Database 10g 이전 버전에도 이 뷰가 있지만 롤백 트랜잭션 정보는 캡처되지 않았습니다. 모든 열을 읽기 쉬운 방식으로 표시하기 위해 Tom Kyte가 AskTom.com에 설명한 PRINT_TABLE 함수를 사용하겠습니다. 이 프로시저는 열을 일반적인 행이 아닌 테이블로만 표시합니다.
SQL> set serveroutput on size 999999
SQL> exec print_table('select * from v$session_longops where sid = 9')
SID : 9
SERIAL# : 68
OPNAME : Transaction Rollback
TARGET :
TARGET_DESC : xid:0x000e.01c.00000067
SOFAR : 10234
TOTALWORK : 20554
UNITS : Blocks
START_TIME : 07-dec-2003 21:20:07
LAST_UPDATE_TIME : 07-dec-2003 21:21:24
TIME_REMAINING : 77
ELAPSED_SECONDS : 77
CONTEXT : 0
MESSAGE : Transaction Rollback: xid:0x000e.01c.00000067 :
10234 out of 20554 Blocks done
USERNAME : SYS
SQL_ADDRESS : 00000003B719ED08
SQL_HASH_VALUE : 1430203031
SQL_ID : 306w9c5amyanr
QCSID : 0
이제 이 열들을 하나하나 자세히 살펴보도록 하겠습니다. 뷰에는 이전 세션의 모든 긴 실행 작업 기록이 포함되어 있으므로 세션에는 긴 실행 작업이 하나 이상일 수 있습니다. OPNAME 열에는 이 레코드가 “트랜잭션 롤백”용이라고 명시되어 있어 올바른 작업 방향으로 이끌어줍니다. TIME_REMAINING 열은 이전에 기술한 예측 잔여 시간을 초 단위로 표시하며, ELAPSED_SECONDS 열에는 현재까지 사용된 시간이 표시됩니다.
그렇다면 이 테이블에 어떻게 예측 잔여 시간을 나타낼까요? 단서는 총 수행 작업량을 나타내는 TOTALWORK 열과 현재까지 수행한 작업량을 나타내는 SOFAR 열에 있습니다. 작업 단위는 UNITS 열에 나와 있습니다. 여기서는 블록에 들어 있으므로 현재까지 20,554개의 블록 중 총 10,234개를 롤백한 것입니다. 또한 현재까지의 작업 소요 시간은 77초이므로 잔여 블록의 롤백 시간은 다음과 같이 구합니다.
77 * ( 10234 / (20554-10234) ) ≈ 77 seconds
반드시 이러한 경로를 통해서만 수치를 얻어야 하는 것은 아니지만 가장 명확한 방법입니다. 마지막으로 LAST_UPDATE_TIME 열에는 뷰 내용이 통용되는 시간이 표시되어 결과를 보다 쉽게 해석할 수 있도록 해줍니다.
SQL 문
또 하나의 중요하면서도 새로운 정보는 롤백 중인 SQL 문의 식별자입니다. 이전에는 롤백 중인 SQL 문을 가져오기 위해 SQL_ADDRESS 및 SQL_HASH_VALUE를 사용했습니다. 새로운 열인 SQL_ID는 아래에서처럼 V$SQL 뷰의 SQL_ID에 해당됩니다.
SELECT SQL_TEXT
FROM V$SQL
WHERE SQL_ID = <value of SQL_ID from V$SESSION_LONGOPS>;
이 질의를 실행하면 롤백된 문을 반환하므로 SQL 문의 주소 및 해시 값과 함께 추가 검사를 제공합니다.
병렬 인스턴스 복구
DML 작업이 병렬이었으면 QCSID 열에 병렬 질의 서버 세션의 SID가 표시됩니다. 인스턴스 복구 및 실패한 트랜잭션의 후속 복구 과정 같은 병렬 롤백을 실행하는 경우 대개 이 정보를 유용하게 사용할 수 있습니다.
예를 들어, 대규모 업데이트를 수행하는 도중 인스턴스가 비정상적으로 종료되었다고 가정합시다. 인스턴스가 나타나면 실패한 트랜잭션이 롤백됩니다. 병렬 복구를 위한 초기화 매개변수 값을 사용할 수 있는 경우 롤백이 정규 트랜잭션 롤백에서 발생하므로 직렬이 아닌 병렬로 이뤄집니다. 그런 다음 롤백 프로세스의 완료 시간을 예측합니다.
V$FAST_START_TRANSACTIONS 뷰에는 실패한 트랜잭션을 롤백하기 위해 발생한 트랜잭션이 표시됩니다. 이와 유사한 뷰인 V$FAST_START_SERVERS에는 롤백에 실행되는 병렬 질의 서버의 수가 나와 있습니다. 이전 버전에서는 이러한 두 개의 뷰가 있지만, 트랜잭션 식별자를 나타내는 새로운 XID 열이 추가되어 조인이 더 수월해졌습니다. Oracle9i Database 이전에서는 세 개 열(USN – 실행 취소 번호, SLT – 실행 취소 세그먼트 내의 슬롯 번호 및 SEQ – 시퀀스 번호)의 뷰에 조인해야 했습니다. 또한 상위 집합은 PARENTUSN, PARENTSLT 및 PARENTSEQ에 표시되었습니다. 하지만 Oracle Database 10g에서는 XID 열의 뷰에만 조인하면 되고 상위 XID는 알기 쉽게 PXID로 표시됩니다.
가장 유용한 정보는 V$FAST_START_TRANSACTIONS 뷰의 RCVSERVERS 열에 나와 있습니다. 병렬 롤백을 진행하면 이 열에 병렬 질의 서버의 수가 나타나며, 이를 통해 다음과 같이 시작된 병렬 질의 프로세스의 수를 확인할 수 있습니다.
select rcvservers from v$fast_start_transactions;
출력에 1로만 나타나면 트랜잭션이 가장 비효율적인 방식인 SMON 프로세스를 통해 직렬로 롤백되고 있는 것입니다. 이 경우 초기화 매개변수 RECOVERY_PARALLELISM을 0과 1을 제외한 값으로 수정한 다음 병렬 롤백 인스턴스를 다시 시작할 수 있습니다. 그런 다음, ALTER SYSTEM SET FAST_START_PARALLEL_ROLLBACK = HIGH를 실행하면 CPU 수의 네 배나 되는 병렬 서버를 생성할 수 있습니다.
위의 질의 출력이 1을 제외한 임의의 값이 표시되면 병렬 롤백이 이뤄지는 것입니다. 이 경우 동일한 뷰(V$FAST_START_TRANSACTIONS)를 질의하여 상위 및 하위 트랜잭션(상위 트랜잭션 ID – PXID 및 하위 트랜잭션 ID – XID)을 가져올 수 있습니다. 또한 XID는 이 뷰와 V$FAST_START_SERVERS를 조인하는 데 사용하여 상세 내역을 추가로 가져올 수 있습니다.
결론
요컨대 Oracle Database 10g에서 긴 실행 트랜잭션을 롤백할 때는 병렬 인스턴스 복구 세션이나 사용자 실행 롤백 문으로 표시한 다음, V$SESSION_LONGOPS 뷰를 살펴보고 향후 소요 시간의 결과를 예측하기만 하면 됩니다. 이제 테마 공원에 도착하는 시간만 예측할 수 있으면 되겠군요!
세번째.
손쉬운 이름 변경: 향상된 테이블스페이스 관리
Sparser인 SYSTEM, 사용자 기본 테이블스페이스 정의 지원, 새로운 SYSAUX 및 이름 바꾸기 등으로 수월해진 테이블스페이스 관리
누구나 SYSTEM 테이블스페이스에 SYS 및 SYSTEM을 제외한 세그먼트를 생성하면서 좌절감에 머리를 쥐어 뜯으며 고민한 경험이 있을 것입니다.
Oracle9i Database 이전 버전에서는 사용자를 생성할 때 DEFAULT TABLESPACE를 명시하지 않으면 기본값이 SYSTEM 테이블스페이스로 설정되었습니다. 사용자가 세그먼트를 생성하는 동안 테이블스페이스를 명시적으로 지정하지 않는 경우, 명시적으로 부여 받은 것이든 시스템 권한 UNLIMITED TABLESPACE를 통한 것이든 사용자가 테이블스페이스 할당량을 갖고 있으면 SYSTEM에 생성되었습니다. Oracle9i에서는 DBA가 명시적인 임시 테이블스페이스 절 없이 생성된 모든 사용자에 대해 기본 임시 테이블스페이스를 지정하도록 하여 이 문제를 어느 정도 해결했습니다.
Oracle Database 10g에서도 이와 유사하게 사용자에게 기본 테이블스페이스를 지정할 수 있습니다. 우선, 데이타베이스를 생성하는 과정에 CREATE DATABASE 명령은 DEFAULT TABLESPACE 절을 포함할 수 있습니다. 데이타베이스의 생성이 끝나면 다음을 실행하여 기본 테이블스페이스를 만들 수 있습니다.
ALTER DATABASE DEFAULT TABLESPACE <tsname>;
DEFAULT TABLESPACE 절 없이 생성된 모든 사용자는 기본값으로 <tsname>을 갖게 됩니다. 기본 테이블스페이스는 이 ALTER 명령을 사용해 언제든 변경하여 다른 위치의 기본값으로 다른 테이블스페이스를 지정할 수 있습니다.
여기서 중요한 점은 일부 사용자에 대해 다른 어떤 항목이 명시적으로 지정되어 있어도 이전 테이블스페이스와 함께 모든 사용자의 기본 테이블스페이스가 <tsname>으로 변경된다는 것입니다. 예를 들어, 사용자 생성 도중 사용자 USER1 및 USER2의 기본 테이블스페이스를 각각 TS1 및 TS2로 명시적으로 지정했다고 가정합니다. 데이타베이스의 현재 기본 테이블스페이스는 TS2지만, 나중에는 데이타베이스의 기본 테이블스페이스가 TS1으로 변경됩니다. USER2의 기본 테이블스페이스를 TS2로 명시적으로 지정했다 하더라도 TS1으로 바뀌게 되므로 이러한 부작용을 염두에 둬야 합니다!
데이타베이스 생성 과정에 기본 테이블스페이스를 지정하지 않으면 기본값이 SYSTEM으로 설정됩니다. 하지만 기존 데이타베이스의 기본 테이블스페이스는 어떻게 알 수 있을까요? 우선, 다음 질의를 실행합니다.
SELECT PROPERTY_VALUE
FROM DATABASE_PROPERTIES
WHERE PROPERTY_NAME = 'DEFAULT_PERMANENT_TABLESPACE';
DATABASE_PROPERTIES 뷰에는 기본 테이블스페이스 외에도 기본 임시 테이블스페이스, 전역 데이타베이스 이름, 시간대 등과 같은 몇 가지 매우 중요한 정보가 표시됩니다.
중요하지 않은 스키마의 기본 테이블스페이스
인텔리전트 에이전트 사용자 DBSNMP 및 데이타 마이닝 사용자 ODM 같은 여러 스키마는 사용자 작업과 직접적인 관련이 없지만 데이타베이스 무결성을 위해 나름대로 중요한 역할을 합니다. 이러한 스키마의 일부는 기본 테이블스페이스가 SYSTEM인데, 이는 해당 특수 테이블스페이스 내에서 객체가 확산되는 또 다른 이유이기도 합니다.
Oracle Database 10g에는 이러한 스키마의 객체를 보유하는 SYSAUX라는 새로운 테이블스페이스가 도입되었습니다. 이 테이블스페이스는 데이타베이스 생성 도중 자동으로 생성되며 지역적으로 관리됩니다. 또한 데이타 파일 이름만 유일하게 변경할 수 있습니다.
이 접근방법은 SYSTEM이 손상되어 전체 데이타베이스를 복구해야 할 때 복구를 지원합니다. 데이타베이스는 계속 실행하면서 SYSAUX의 객체를 일반 사용자 객체로 복구할 수 있습니다.
하지만 SYSAUX에 있는 이들 스키마의 일부를 다른 테이블스페이스로 옮겨야 한다면 어떻게 할까요? 크기가 늘어나 결국에는 테이블스페이스를 꽉 채우는 일이 빈번한 LogMiner에 사용되는 객체를 예로 들어봅시다. 관리 효율을 높이기 위해 이를 저마다의 테이블스페이스로 옮기는 방법을 고려할 수도 있을 것입니다. 하지만 이것이 최선의 방법일까요?
DBA라면 이러한 특수 객체를 옮기기 위한 올바른 프로시저를 알고 있어야 합니다. 다행히도 Oracle Database 10g에는 이러한 추측 작업을 수행하는 새로운 뷰가 있습니다. 이 V$SYSAUX_OCCUPANTS 뷰에는 SYSAUX 테이블스페이스에 있는 스키마의 이름, 설명, 현재 사용 공간 그리고 이동 방법이 나와 있습니다 (See 표 1 참조).
여기서 LogMiner가 어떻게 분명히 7,488KB를 차지하고 있는 것으로 표시되는지에 주목합니다. LogMiner는 SYSTEM 스키마에 속해 있으며 객체를 이동하려면 패키지 프로시저 SYS.DBMS_LOGMNR_D.SET_TABLESPACE를 실행합니다. 하지만 STATSPACK 객체의 경우 뷰에 엑스포트/임포트 접근방법을 사용하는 것이 좋으며 Streams에는 이동 프로시저가 없으므로 SYSAUX 테이블스페이스에서 이를 쉽게 옮길 수 없습니다. MOVE_PROCEDURE 열에는 SYSAUX에 기본적으로 상주하는 거의 모든 툴에 대한 올바른 이동 프로시저가 표시됩니다. 이동 프로시저는 역방향으로도 사용하여 객체를 다시 SYSAUX 테이블스페이스로 가져올 수 있습니다.
테이블스페이스 이름 바꾸기
데이타 웨어하우스 환경에서는 일반적으로 데이타 마트 아키텍처가 데이타베이스 사이에서 테이블스페이스를 이동합니다. 하지만 원본 및 대상 데이타베이스는 테이블스페이스 이름이 서로 달라야 합니다. 이름이 같은 테이블스페이스가 두 개이면 대상 테이블스페이스의 세그먼트를 다른 테이블스페이스로 옮기고 테이블스페이스를 다시 생성해야 하는데 말처럼 쉽지가 않습니다.
Oracle Database 10g에는 편리한 솔루션이 있어 영구 또는 임시 여부에 관계 없이 기존 테이블스페이스(SYSTEM 및 SYSAUX 제외)의 이름을 다음 명령을 사용해 간단히 변경할 수 있습니다.
ALTER TABLESPACE <oldname> RENAME TO <newname>;
이 기능은 아카이브 프로세스에도 유용하게 사용할 수 있습니다. 매출 기록을 관리하기 위해 범위로 분할된 테이블이 있으며, 매월의 파티션은 해당 월의 이름을 따 명명된 테이블스페이스에 있습니다. 예를 들어, 1월의 파티션에는 JAN이라는 이름이 지정되며 JAN으로 명명된 테이블스페이스에 상주합니다. 보존 정책 기간은 12개월입니다. 따라서 2004년 1월에 2003년 1월의 데이타를 아카이브할 수 있게 되는 것입니다. 대략적인 작업 과정은 다음과 유사한 형태가 됩니다.
ALTER TABLE EXCHANGE PARTITION을 사용해 파티션 JAN에서 독립형 테이블 JAN03을 생성합니다.
테이블스페이스 이름을 JAN03으로 변경합니다.
테이블스페이스 JAN03에 설정된 이동 가능한 테이블스페이스를 생성합니다.
테이블스페이스 JAN03의 이름을 다시 JAN으로 변경합니다.
비어 있는 파티션을 다시 테이블로 교환합니다.
1, 2, 4 및 5단계는 순조롭게 진행되며 리두 및 실행 취소 공간 같은 리소스를 과도하게 소모하지 않습니다. 3단계는 단순히 파일을 복사하고 JAN03의 데이타 딕셔너리만 엑스포트하면 되므로 마찬가지로 매우 간단한 프로세스입니다. 이전에 아카이브한 파티션을 다시 유효화해야 하는 경우, 프로시저는 동일한 프로세스를 반대로 수행하는 것만큼 간단합니다.
Oracle Database 10g는 이러한 이름 바꾸기를 처리하는 방식에 있어 상당히 지능적입니다. UNDO로 사용되는 테이블스페이스 또는 기본 임시 테이블스페이스의 이름을 변경하는 경우 혼동이 발생할 수 있습니다. 하지만 데이타베이스가 필요한 레코드를 자동으로 조정하여 변경 내용을 반영합니다. 예를 들어, 기본 테이블스페이스 이름을 USERS에서 USER_DATA로 변경하면 DATABASE_PROPERTIES가 자동으로 변경됩니다. 변경에 앞서 다음 질의가
select property_value from database_properties
where property_name = 'DEFAULT_PERMANENT_TABLESPACE';
USERS를 반환합니다. 다음 문을 실행하고 나면
alter tablespace users rename to user_data;
USER_DATA에 대한 모든 참조가 USER_DATA로 변경되었므로 위의 질의가 USER_DATA를 반환합니다.
기본 임시 테이블스페이스를 변경하는 방법도 이와 동일합니다. UNDO 테이블스페이스 이름을 변경하더라도 다음과 같이 SPFILE에 변경을 트리거합니다.
SQL> select value from v$spparameter where name = 'undo_tablespace';
VALUE
--------
UNDOTBS1
SQL> alter tablespace undotbs1 rename to undotbs;
Tablespace altered.
SQL> select value from v$spparameter where name = 'undo_tablespace';
VALUE
--------
UNDOTBS
결론
객체 처리 기능은 최근의 여러 Oracle 버전을 거치면서 꾸준히 향상되었습니다. Oracle8i에는 한 테이블스페이스에서 다른 테이블스페이스로의 테이블 이동이 도입되었으며, Oracle 9i Database R2는 열 이름 변경 기능을 갖추게 되었습니다. 그리고 지금은 테이블스페이스 자체의 이름을 변경할 수 있는 수준에 이르고 있습니다. 또한 이처럼 기능이 향상되면서 데이타 웨어하우스 또는 마트 환경 등에서 DBA의 작업 부담을 크게 덜어주고 있습니다.
네번째.
한층 강화된 엑스포트/임포트: Oracle Data Pump
Oracle Database 10g 유틸리티로 크게 향상된 데이타 이동 기능
지금까지 엑스포트/임포트 툴세트는 열악한 속도에 대한 불만에도 불구하고 최소한의 노력으로 여러 플랫폼에 데이타를 전송하기 위해 사용해 온 유틸리티였습니다. 임포트는 단순히 엑스포트 덤프 파일에서 각 레코드를 읽고 이를 일반적인 INSERT INTO 명령을 사용해 대상 테이블에 삽입하기만 하므로 임포트 프로세스가 느린 것은 그리 놀랄만한 일이 아닙니다.
이제 프로세스 속도가 월등히 향상된 Oracle Database 10g의 보다 새롭고 빠른 엑스포트/임포트 툴킷인 Oracle Data Pump, the newer and faster sibling of the export/import toolkit in Oracle Database 10g를 사용해 보십시오.
Data Pump는 엑스포트/임포트 프로세스의 전체 구성을 나타냅니다. 일반적인 SQL 문을 사용하는 대신 독점 API로 데이타를 현저하게 빠른 속도로 로드 및 언로드합니다. 제가 테스트해본 결과, 직접 모드의 엑스포트보다 성능이 10-15배 향상되었으며, 임포트 프로세스 성능도 5배 이상 증가했습니다. 또한 엑스포트 유틸리티와 달리 프로시저 같은 특정 유형의 객체만 추출할 수 있습니다.
Data Pump Export
이 새로운 유틸리티는 원래의 엑스포트인 exp와 구분하기 위해 expdp라고 합니다. 이 예에서는 Data Pump를 사용해 약 3GB 크기의 대형 테이블인 CASES를 엑스포트합니다. Data Pump는 서버 측에서 파일 조작을 사용하여 파일을 생성하고 읽으므로 디렉토리를 위치로 사용합니다. 여기서는 filesystem /u02/dpdata1을 사용해 덤프 파일을 유지할 예정입니다.
create directory dpdata1 as '/u02/dpdata1';
grant read, write on directory dpdata1 to ananda;
그리고 다음과 같이 데이타를 엑스포트합니다.
expdp ananda/abc123 tables=CASES directory=DPDATA1
dumpfile=expCASES.dmp job_name=CASES_EXPORT
이제 이 명령의 각 부분을 분석해 보겠습니다. 사용자 ID/암호 조합, 테이블 및 덤프 파일 매개변수는 말 그대로이므로 설명이 필요 없습니다. 원래의 엑스포트와 달리 파일이 클라이언트가 아닌 서버에 생성됩니다. 위치는 디렉토리 매개변수 값 DPDATA1로 지정되며, 이는 이전에 생성된 /u02/dpdata1을 가리킵니다. 또한 프로세스를 실행하면 서버의 디렉토리 매개변수로 지정된 위치에 로그 파일이 생성됩니다. 이 프로세스에는 기본적으로 DPUMP_DIR로 명명된 디렉토리가 사용되므로 DPDATA1 대신 생성할 수 있습니다.
위의 job_name 매개변수를 보면 원래의 엑스포트에 없는 특별한 항목이 하나 있습니다. 모든 Data Pump 작업은 작업(job)을 통해 이뤄집니다. Data Pump 작업은 DBMS 작업과 달리 주 프로세스를 대신해 데이타를 처리하는 단순한 서버 프로세스입니다. 마스터 제어 프로세스라고 하는 이 주 프로세스는 Advanced Queuing을 통해 이러한 작업 노력을 조정하는데, 이는 마스터 테이블이라고 하는 런타임 시 생성된 특수 테이블을 통해 이뤄집니다. 제시한 예에서 expdp를 실행하면서 사용자 ANANDA의 스키마를 검사하면 job_name 매개변수에 해당되는 CASES_EXPORT 테이블이 있음을 알 수 있습니다. expdp가 종료되면 이 테이블은 삭제됩니다.
엑스포트 모니터링
DPE(Data Pump Export)를 실행하면서 Control-C를 누르면 화면상에 메시지 표시를 중지하지만 프로세스 자체를 엑스포트하지는 않습니다. 대신 다음과 같이 DPE 프롬프트를 표시합니다. 이제 프로세스는 소위 “대화식” 모드에 들어갑니다.
Export>
이 접근방법에서는 DPE 작업에 여러 명령을 입력할 수 있습니다. 요약을 확인하려면 다음과 같이 프롬프트에 STATUS 명령을 사용합니다.
Export> status
Job: CASES_EXPORT
Operation: EXPORT
Mode: TABLE
State: EXECUTING
Degree: 1
Job Error Count: 0
Dump file: /u02/dpdata1/expCASES.dmp
bytes written = 2048
Worker 1 Status:
State: EXECUTING
Object Schema: DWOWNER
Object Name: CASES
Object Type: TABLE_EXPORT/TBL_TABLE_DATA/TABLE/TABLE_DATA
Completed Objects: 1
Total Objects: 1
Completed Rows: 4687818
하지만 이것은 상태 표시일 뿐이며 엑스포트는 백그라운드에서 실행되고 있습니다. 화면의 메시지를 계속 확인하려면 Export> 프롬프트에서 CONTINUE_CLIENT 명령을 사용합니다.
병렬 작업
PARALLEL 매개변수를 통해 엑스포트시 하나 이상의 스레드를 사용하면 작업 속도를 크게 개선할 수 있습니다. 스레드마다 개별 덤프 파일을 생성하므로 매개변수 dumpfile은 병렬화 만큼 많은 여러 항목을 갖게 됩니다. 또한 하나씩 명시적으로 입력하는 대신 다음과 같이 대체 문자를 파일 이름으로 지정할 수 있습니다.
expdp ananda/abc123 tables=CASES directory=DPDATA1
dumpfile=expCASES_%U.dmp parallel=4 job_name=Cases_Export
여기서 dumpfile 매개변수에 어떻게 대체 문자 %U가 생기는지 주목합니다. 이 대체 문자는 파일이 필요에 따라 생성되고 형식은 expCASES_nn.dmp이 됨을 나타내는데, 여기서 nn은 01에서 시작하며 필요에 따라 증가하게 됩니다.
병렬 모드에서는 상태 화면에 네 개의 작업자 프로세스가 표시됩니다. (기본 모드에서는 프로세스가 한 개만 표시됩니다.) 모든 작업자 프로세스가 데이타를 동시에 추출하며 진행률을 상태 화면에 표시합니다.
데이타베이스 파일 및 덤프 파일 디렉토리 파일 시스템에 액세스하려면 I/O 채널을 반드시 구분해야 합니다. 그렇지 않으면 Data Pump 작업의 유지와 관련된 오버헤드가 병렬 스레드의 이점을 뛰어넘어 성능을 저하시킬 수 있습니다. 병렬화는 테이블 수가 병렬 값보다 크고 테이블이 대규모인 경우에만 적용됩니다.
데이타베이스 모니터링
데이타베이스 뷰에서 실행되는 Data Pump 작업에 관해서도 자세한 정보를 확인할 수 있습니다. 작업을 모니터링하는 기본 뷰는 DBA_DATAPUMP_JOBS로 작업에서 실행되는 작업자 프로세스(DEGREE 열)의 수를 알려줍니다. 그 밖의 중요한 뷰에는 DBA_DATAPUMP_SESSIONS가 있는데, 이전 뷰 및 V$SESSION과 조인하면 주 포그라운드(Foreground) 프로세스 세션의 SID를 확인할 수 있습니다.
select sid, serial#
from v$session s, dba_datapump_sessions d
where s.saddr = d.saddr;
이 명령에는 포그라운드 프로세스의 세션이 표시됩니다. 경고 로그에서는 보다 유용한 정보를 얻을 수 있습니다. 프로세스가 시작되면 MCP 및 작업자 프로세스가 다음과 같이 경고 로그에 나타납니다.
kupprdp: master process DM00 started with pid=23, OS id=20530 to execute -
SYS.KUPM$MCP.MAIN('CASES_EXPORT', 'ANANDA');
kupprdp: worker process DW01 started with worker id=1, pid=24, OS id=20532 to execute -
SYS.KUPW$WORKER.MAIN('CASES_EXPORT', 'ANANDA');
kupprdp: worker process DW03 started with worker id=2, pid=25, OS id=20534 to execute -
SYS.KUPW$WORKER.MAIN('CASES_EXPORT', 'ANANDA');
경고 로그에는 Data Pump 작업을 위해 시작된 세션의 PID가 표시됩니다. 실제 SID는 이 질의를 사용해 확인합니다.
select sid, program from v$session where paddr in
(select addr from v$process where pid in (23,24,25));
PROGRAM 열에는 경고 로그 파일의 이름에 해당되는 프로세스 DM(마스터 프로세스) 또는 DW(작업자 프로세스)가 표시됩니다. SID 23 같은 작업자 프로세스에서 병렬 질의를 사용하는 경우, V$PX_SESSION 뷰에서 확인할 수 있습니다. 이 뷰에는 SID 23으로 표시된 작업자 프로세스에서 실행되는 모든 병렬 질의 세션이 나타납니다.
select sid from v$px_session where qcsid = 23;
V$SESSION_LONGOPS 뷰에서는 작업 완료에 걸리는 시간을 예측하는 또 다른 유용한 정보를 얻을 수 있습니다.
select sid, serial#, sofar, totalwork
from v$session_longops
where opname = 'CASES_EXPORT'
and sofar != totalwork;
totalwork 열에는 총 작업량이 표시되는데, 이 중 현재까지 sofar 작업량을 완료했으므로 이를 통해 얼마나 더 시간이 걸릴지 예측할 수 있습니다.
Data Pump Import
하지만 Data Pump에서 가장 눈에 잘 띄는 부분은 데이타 임포트 성능입니다. 이전에 엑스포트된 데이타를 임포트하려면 다음을 사용합니다.
impdp ananda/abc123 directory=dpdata1 dumpfile=expCASES.dmp job_name=cases_import
임포트 프로세스의 기본 작업 방식은 테이블 및 연관된 모든 객체를 생성하고 테이블이 있는 상태에서 오류를 만들어 내는 것입니다. 기존 테이블에 데이타를 추가해야 하는 경우 위의 명령행에 TABLE_EXISTS_ACTION=APPEND를 사용할 수 있습니다.
DPE와 마찬가지로 프로세스 도중 Control-C를 누르면 DPI(Date Pump Import)의 대화식 모드를 표시하며 Import>가 프롬프트됩니다.
특정 객체 작업
한 사용자에서 특정 프로시저만 엑스포트하여 다른 데이타베이스나 사용자에 다시 생성해야 했던 경험이 있습니까? 기존의 엑스포트 유틸리티와 달리 Data Pump는 특정 유형의 객체만 엑스포트할 수 있습니다. 예를 들어, 다음 명령을 실행하면 테이블, 뷰 또는 함수 등은 제외하고 오로지 프로시저만 엑스포트할 수 있습니다.
expdp ananda/iclaim directory=DPDATA1 dumpfile=expprocs.dmp include=PROCEDURE
To export only a few specific objects--say, function FUNC1 and procedure PROC1--you could use
expdp ananda/iclaim directory=DPDATA1 dumpfile=expprocs.dmp
include=PROCEDURE:"='PROC1'",FUNCTION:"='FUNC1'"
이 덤프 파일은 소스의 백업으로 사용됩니다. 때로는 이를 사용해 DDL 스크립트를 생성하여 나중에 사용할 수도 있습니다. DDL 스크립트 파일을 생성하려면 SQLFILE이라고 하는 특수 매개변수를 사용합니다.
impdp ananda/iclaim directory=DPDATA1 dumpfile=expprocs.dmp sqlfile=procs.sql
이 명령은 DPDATA1로 지정된 디렉토리에 procs.sql로 명명된 파일을 생성하며 엑스포트 덤프 파일 내의 객체 스크립트가 들어 있습니다. 이 접근방법을 사용하면 다른 스키마에 원본을 보다 신속하게 생성할 수 있습니다.
INCLUDE 매개변수를 사용하면 객체가 덤프 파일에서 포함 또는 제외되도록 정의할 수 있습니다. 예를 들어, INCLUDE=TABLE:"LIKE 'TAB%'" 절을 사용하면 이름이 TAB로 시작하는 테이블만 엑스포트할 수 있습니다. 마찬가지로 INCLUDE=TABLE:"NOT LIKE 'TAB%'" 구문을 사용하면 TAB으로 시작하는 모든 테이블을 제외시킬 수 있습니다. 아니면 EXCLUDE 매개변수를 사용해 특정 객체를 제외시킬 수 있습니다.
Data Pump를 사용하면 외부 테이블로 테이블스페이스를 이동할 수도 있는데, 이렇게 하면 진행 중인 병렬화를 다시 정의하고 기존 프로세스에 테이블을 추가하는 등의 작업에 매우 효과적입니다(이는 본 문서의 범위를 벗어난 내용이므로 자세한 내용은 Oracle Database Utilities 10g Release 1 10.1을 참조하십시오). 다음 명령을 실행하면 Data Pump 엑스포트 유틸리티에서 사용 가능한 매개변수 목록이 생성됩니다.
expdp help=y
마찬가지로 impdp help=y 명령을 실행하면 DPI의 모든 매개변수가 표시됩니다.
Data Pump 작업을 실행하는 동안 DPE 또는 DPI 프롬프트에 STOP_JOB을 실행하여 작업을 일시 중지한 다음 START_JOB으로 다시 시작할 수 있습니다. 이 기능은 공간이 부족하여 계속하기 전에 정정해야 하는 경우 유용하게 사용할 수 있습니다.
자세한 내용은 Oracle Database Utilities 10g Release 1 10.1 설명서 1부를 참조하십시오.
다섯번째.
Flashback 테이블
실수로 삭제한 테이블을 손쉽게 다시 유효화할 수 있는 Oracle Database 10g의 Flashback 테이블 기능
매우 중요한 테이블을 실수로 삭제하여 즉시 복구해야 하는 상황은 생각보다 자주 일어나는 시나리오입니다. (때로는 이처럼 불운한 사용자가 DBA일 수도 있습니다!)
Oracle9i Database에는 Flashback 질의 옵션 개념이 도입되어 데이타를 과거의 시점에서부터 검색하지만, 테이블 삭제 같은 DDL 작업을 순간적으로 되돌릴 수는 없습니다. 이 경우 유일한 수단은 다른 데이타베이스에서 테이블스페이스 적시 복구를 사용한 다음, 엑스포트/임포트 또는 기타 메서드를 사용해 현재 데이타베이스에 테이블을 다시 생성하는 것입니다. 이 프로시저를 수행하려면 복제를 위해 다른 데이타베이스를 사용하는 것은 물론, DBA의 많은 노력과 귀중한 시간이 요구됩니다.
하지만 Oracle Database 10g의 Flashback 테이블 기능으로 들어가면 몇 개의 문만 실행하여 삭제된 테이블을 간단히 검색할 수 있습니다. 그럼, 지금부터 이 기능의 작동 원리에 대해 알아보도록 하겠습니다.
자유로운 테이블 삭제
먼저, 현재 스키마의 테이블을 확인해 봅시다.
SQL> select * from tab;
TNAME TABTYPE CLUSTERID
------------------------ ------- ----------
RECYCLETEST TABLE
그런 다음, 아래와 같이 고의로 테이블을 삭제합니다.
SQL> drop table recycletest;
Table dropped.
이제 테이블의 상태를 확인합니다.
SQL> select * from tab;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
BIN$04LhcpndanfgMAAAAAANPw==$0 TABLE
RECYCLETEST 테이블이 사라졌지만 새 테이블인 BIN$04LhcpndanfgMAAAAAANPw==$0이 있다는 점에 주목합니다. 좀 더 자세히 설명하면 삭제된 테이블 RECYCLETEST가 완전히 사라지는 대신 시스템 정의 이름으로 이름이 변경된 것입니다. 이 테이블은 여전히 동일한 테이블스페이스에 있으며 원래 테이블과 구조도 동일합니다. 테이블에 인덱스 또는 트리거가 정의되어 있는 경우, 마찬가지로 테이블과 동일한 명명 규칙을 사용하여 이름이 변경됩니다. 프로시저 같은 종속적인 소스는 무효화되지만, 대신 원래 테이블의 트리거 및 인덱스가 이름이 변경된 테이블인 BIN$04LhcpndanfgMAAAAAANPw==$0에 들어가 삭제된 테이블의 완전한 객체 구조를 보존합니다.
테이블 및 연관된 객체는 PC에 있는 것과 유사한 “휴지통(RecycleBin)”이라고 하는 논리적 컨테이너에 들어갑니다. 하지만 이들 객체가 이전에 있던 테이블스페이스에서 옮겨지는 것은 아니며 계속 해당 테이블스페이스에서 공간을 차지하고 있습니다. 휴지통은 단순히 삭제된 객체의 목록을 만드는 논리적 구조입니다. 휴지통의 컨텐트를 확인하려면 SQL*Plus 프롬프트에서 다음 명령을 사용합니다(SQL*Plus 10.1이 있어야 함).
SQL> show recyclebin
ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME
---------------- ------------------------------ ------------ ------------------
RECYCLETEST BIN$04LhcpndanfgMAAAAAANPw==$0 TABLE 2004-02-16:21:13:31
이렇게 하면 테이블의 원래 이름인 RECYCLETEST는 물론, 삭제된 후 생성된 새 테이블 이름과 동일한 휴지통에서의 새 이름이 표시됩니다. (참고: 정확한 이름은 플랫폼별로 다를 수 있습니다.) 테이블을 다시 유효화하기 위해서는 FLASHBACK TABLE 명령만 사용하면 됩니다.
SQL> FLASHBACK TABLE RECYCLETEST TO BEFORE DROP;
FLASHBACK COMPLETE.
SQL> SELECT * FROM TAB;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
RECYCLETEST TABLE
자, 테이블이 정말 간단히 유효화되지 않습니까? 지금 휴지통을 확인하면 비어 있습니다.
여기서 유의할 점은 테이블을 휴지통에 넣는다고 해도 원래 테이블스페이스의 공간이 제거되는 것은 아니라는 것입니다. 공간을 제거하려면 다음을 사용해 휴지통을 지워야 합니다.
PURGE RECYCLEBIN;
하지만 Flashback 기능을 사용하지 않고 테이블을 완전히 삭제하려면 어떻게 해야 할까요? 이 경우 다음을 사용하면 테이블을 영구적으로 삭제할 수 있습니다.
DROP TABLE RECYCLETEST PURGE;
이 명령을 실행하면 테이블 이름이 휴지통 이름으로 변경되는 것이 아니라, 10g 이전 버전에서처럼 영구적으로 삭제됩니다.
휴지통 관리
이 프로세스에서 테이블을 완전히 삭제하지 않아 테이블스페이스를 해제하지 않은 상태에서 삭제된 객체가 테이블스페이스의 모든 공간을 차지하면 어떤 일이 발생할까요?
답은 간단합니다. 그 같은 상황은 결코 발생하지 않습니다. 데이타 파일에 데이타를 추가할 공간을 확보해야 할 정도로 휴지통 데이타가 테이블스페이스로 꽉 차는 상황이 발생하면 테이블스페이스는 이른바 “공간 압축” 상태에 들어갑니다. 위의 시나리오에서 객체는 선입선출 방식으로 휴지통에서 자동으로 지워지며, 종속된 객체(예: 인덱스)는 테이블보다 먼저 제거됩니다.
마찬가지로 특정 테이블스페이스에 정의된 사용자 할당량에도 공간 압축이 발생할 수 있습니다. 테이블에는 사용 가능한 공간이 충분하지만 사용자는 할당된 공간이 부족할 수 있습니다. 이러한 상황에서 Oracle은 해당 테이블스페이스의 사용자에 속한 객체를 자동으로 지웁니다.
이 외에도 여러 가지 방법으로 휴지통을 수동으로 제어할 수 있습니다. 삭제한 후 휴지통에서 TEST라고 명명된 특정 테이블을 삭제하려면 다음을 실행하거나,
PURGE TABLE TEST;
아래와 같이 해당 휴지통 이름을 사용합니다.
PURGE TABLE "BIN$04LhcpndanfgMAAAAAANPw==$0";
이 명령을 실행하면 휴지통에서 TEST 테이블과 인덱스, 제약 조건 등과 같은 모든 종속 객체가 삭제되어 일정 공간을 확보하게 됩니다. 하지만 휴지통에서 인덱스를 영구적으로 삭제하려면 다음을 사용합니다.
purge index in_test1_01;
이렇게 하면 인덱스만 제거되며 테이블의 복사본은 휴지통에 남아 있습니다.
때로는 상위 레벨에서 지우는 것이 유용할 수도 있습니다. 예를 들어, 테이블스페이스 USERS의 휴지통에 있는 모든 객체를 지워야 한다면 다음을 실행합니다.
PURGE TABLESPACE USERS;
휴지통에서 해당 테이블스페이스의 특정 사용자만 지워야 하는 경우도 있습니다. 이 접근방법은 사용자가 많은 수의 과도 상태 테이블을 생성 및 삭제하는 데이타 웨어하우스 유형의 환경에 유용합니다. 다음과 같이 위의 명령을 수정해 지우기 작업을 특정 사용자만으로 제한할 수 있습니다.
PURGE TABLESPACE USERS USER SCOTT;
사용자 SCOTT는 다음 명령으로 휴지통을 지웁니다.
PURGE RECYCLEBIN;
DBA는 다음을 사용해 테이블스페이스의 모든 객체를 지울 수 있습니다.
PURGE DBA_RECYCLEBIN;
위에서 살펴본 것처럼 휴지통은 사용자의 특정한 요구에 맞는 다양한 방식으로 관리할 수 있습니다.
테이블 버전 및 Flashback
다음과 같이 동일한 테이블을 여러 번 생성 및 삭제해야 하는 경우도 흔히 발생합니다.
CREATE TABLE TEST (COL1 NUMBER);
INSERT INTO TEST VALUES (1);
COMMIT;
DROP TABLE TEST;
CREATE TABLE TEST (COL1 NUMBER);
INSERT INTO TEST VALUES (2);
COMMIT;
DROP TABLE TEST;
CREATE TABLE TEST (COL1 NUMBER);
INSERT INTO TEST VALUES (3);
COMMIT;
DROP TABLE TEST;
여기서 TEST 테이블을 순간적으로 되돌린다면 COL1 열의 값은 어떻게 될까요? 기존의 개념에서 보면 휴지통에서 테이블의 첫 번째 버전이 검색되고 COL1 열의 값은 1이 될 것입니다. 하지만 실제로는 첫 번째가 아닌 테이블의 세 번째 버전이 검색되므로 COL1 열의 값은 1이 아닌 3이 됩니다.
이 때 삭제된 테이블의 다른 버전을 검색할 수도 있습니다. 하지만 TEST 테이블이 존재하는 이러한 작업이 불가능한데, 이 경우 다음 두 가지를 선택할 수 있습니다.
다음과 같이 이름 바꾸기 옵션을 사용합니다.
FLASHBACK TABLE TEST TO BEFORE DROP RENAME TO TEST2;
FLASHBACK TABLE TEST TO BEFORE DROP RENAME TO TEST1;
이렇게 하면 테이블의 첫 번째 버전은 TEST1으로, 두 번째 버전은 TEST2로 다시 유효화됩니다. 또한 TEST1 및 TEST2에서 COL1의 값은 각각 1과 2가 됩니다. 또는
복원할 테이블의 특정 휴지통 이름을 사용합니다. 이를 위해 먼저 테이블의 휴지통 이름을 식별한 후 다음을 실행합니다.
FLASHBACK TABLE "BIN$04LhcpnoanfgMAAAAAANPw==$0" TO BEFORE DROP RENAME TO TEST2;
FLASHBACK TABLE "BIN$04LhcpnqanfgMAAAAAANPw==$0" TO BEFORE DROP RENAME TO TEST1;
이렇게 하면 삭제된 테이블의 두 가지 버전이 복원됩니다.
주의 사항
삭제 취소 기능을 사용하면 테이블의 이름이 원래대로 돌아가지만 인덱스 및 트리거 같은 연관된 객체는 그렇지 않으며 계속 휴지통 이름으로 남아 있습니다. 또한 뷰 및 프로시저 같이 테이블에 정의된 소스는 재컴파일되지 않으며 무효화된 상태로 남게 됩니다. 이러한 이전 이름들은 수동으로 검색한 다음 순간적으로 되돌린 테이블에 적용해야 합니다.
이 정보는 USER_RECYCLEBIN으로 명명된 뷰에서 관리됩니다. 테이블을 순간적으로 되돌리기 전에 다음 질의를 사용해 이전 이름을 검색합니다.
SELECT OBJECT_NAME, ORIGINAL_NAME, TYPE
FROM USER_RECYCLEBIN
WHERE BASE_OBJECT = (SELECT BASE_OBJECT FROM USER_RECYCLEBIN
WHERE ORIGINAL_NAME = 'RECYCLETEST')
AND ORIGINAL_NAME != 'RECYCLETEST';
OBJECT_NAME ORIGINAL_N TYPE
------------------------------ ---------- --------
BIN$04LhcpnianfgMAAAAAANPw==$0 IN_RT_01 INDEX
BIN$04LhcpnganfgMAAAAAANPw==$0 TR_RT TRIGGER
테이블을 순간적으로 되돌리면 RECYCLETEST 테이블의 인덱스 및 트리거에는 OBJECT_NAME 열에 나타난 이름이 지정됩니다. 위의 질의에서는 원래 이름을 사용해 객체의 이름을 다음과 같이 변경할 수 있습니다.
ALTER INDEX "BIN$04LhcpnianfgMAAAAAANPw==$0" RENAME TO IN_RT_01;
ALTER TRIGGER "BIN$04LhcpnganfgMAAAAAANPw==$0" RENAME TO TR_RT;
한가지 유의해야 할 예외는 비트맵 인덱스입니다. 비트맵 인덱스를 삭제하면 휴지통에 들어가지 않으므로 검색할 수 없습니다. 또한 뷰에서 제약 조건 이름을 검색할 수 없습니다. 따라서 이 인덱스의 이름은 다른 소스에서 변경해야 합니다.
Flashback 테이블의 다른 용도
Flashback Drop Table에는 테이블 삭제 작업을 되돌리는 것 외에도 다른 기능이 있습니다. Flashback 질의와 마찬가지로 이를 사용해 테이블을 다른 시점으로 다시 유효화하여 전체 테이블을 “이전” 버전으로 바꿀 수 있습니다. 예를 들어, 다음 문을 사용하면 테이블을 시스템 변경 번호(SCN) 2202666520으로 다시 유효화합니다.
FLASHBACK TABLE RECYCLETEST TO SCN 2202666520;
이 기능은 Oracle Data Pump 기술로 다른 테이블을 생성하고 Flashback으로 테이블을 해당 SCN의 데이타 버전으로 채운 다음, 원래의 테이블을 새 테이블로 바꿉니다. 테이블을 어느 정도까지 순간적으로 되돌릴 수 있는지 확인하려면 Oracle Database 10g의 버전 관리 기능을 사용합니다. (자세한 내용은 이 시리즈의 1주 부분을 참조하십시오.) 또한 Flashback 절에 SCN 대신 타임 스탬프를 지정할 수도 있습니다.
Flashback 테이블 가능에 대한 자세한 내용은 Oracle Database Administrator's Guide 10g Release 1 (10.1)을 참조하십시오.
제 6 주
Automatic Workload Repository
AWR을 이용하여 분석과 튜닝을 위한 데이타베이스 성능 통계정보와 메트릭을 수집하고, 데이타베이스에서 사용한 정확한 시간을 확인하거나 세션 정보를 저장할 수 있습니다.
데이타베이스에 성능에 관련한 문제가 생겼을 때, 귀하가 DBA로서 가장 먼저 취하는 조치는 무엇입니까? 아마도 문제에 일정한 패턴이 존재하는지 확인하는 것이 가장 일반적인 접근방법의 하나일 것입니다. “동일한 문제가 반복되는가?”, “특정한 시간대에만 발생하는가?”, 또는 “두 가지 문제에 연관성이 있는가?” 등의 질문을 먼저 제기해 봄으로써 보다 정확한 진단을 수행할 수 있습니다.
Oracle DBA들은 데이타베이스 운영에 관련한 통계정보를 수집하거나 성능 메트릭(metric)을 추출하기 위해 써드 파티 툴, 또는 직접 개발한 툴을 사용하고 있습니다. 이렇게 수집된 정보는, 문제 발생 이전과 이후의 상태를 비교하는 데 이용됩니다. 과거에 발생했던 이벤트들을 재현해 봄으로써 현재 문제를 다양한 관점에서 분석할 수 있습니다. 이처럼 관련 통계정보들을 지속적으로 수집하는 것은 성능 분석에서 매우 중요한 작업 중의 하나입니다.
오라클은 한동안 이를 위해 Statspack이라는 이름의 빌트-인 툴을 제공하기도 했습니다. Statspack은 상황에 따라 매우 유용하긴 했지만, 성능 관련 트러블슈팅 과정에서 요구되는 안정성이 결여되었다는 문제가 있었습니다. Oracle Database 10g는 성능 통계정보의 수집과 관련하여 그 기능이 비약적으로 향상된 Automatic Workload Repository(AWR)을 제공합니다. AWR은 데이타베이스와 함께 설치되며, 기본적인 통계정보뿐 아니라 통계정보로부터 유추된 메트릭(derived metric)도 함께 수집합니다.
간단하게 테스트해 보기
AWR을 이용한 새로운 기능들은 $ORACLE_HOME/rdbms/admin 디렉토리의 awrrpt.sql 스크립트를 실행하고, 수집된 통계정보와 메트릭 정보를 바탕으로 생성된 리포트를 확인함으로써 가장 쉽게 이해할 수 있습니다. awrrpt.sql 스크립트는 Statspack과 유사한 구조로 되어있습니다. 먼저 현재 저장된 AWR 스냅샷을 모두 표시한 후, 시간 간격 설정을 위한 입력값을 요구합니다. 출력은 두 가지 형태로 제공됩니다. 텍스트 포맷 출력은 Statspack 리포트와 유사하지만, AWR 리포지토리를 기반으로 하며 (디폴트로 제공되는) HTML 포맷을 통해 section/subsection으로 구분된 하이퍼링크를 제공하는 등 사용자 편의성을 강화하였다는 점에서 차이를 갖습니다. 먼저 awrrpt.sql 스크립트를 실행하여 리포트를 확인해 보시고, AWR의 기능에 대한.특성을 이해하시기 바랍니다.
구현 원리
이제 AWR의 설계방식과 구조에 대해 알아보기로 합시다. AWR은 수집된 성능관련 통계정보가 저장되며 이를 바탕으로 성능 메트릭을 제공함으로서 잠재적인 문제의 원인 추적을 가능하게 해주는 근간을 제공해 줍니다. Statspack의 경우와 달리, Oracle10g는 AWR을 활용하여 새로운 MMON 백그라운드 프로세스와, 여러 개의 슬레이브 프로세스를 통해 자동적으로 매시간별 스냅샷 정보를 수집합니다. 공간 절약을 위해, 수집된 데이타는 7일 후 자동으로 삭제됩니다. 스냅샷 빈도와 보관 주기는 사용자에 의해 설정 가능합니다. 현재 설정값을 보기 위해서는 아래와 같이 명령을 수행하면 됩니다:
select snap_interval, retention
from dba_hist_wr_control;
SNAP_INTERVAL RETENTION
------------------- -------------------
+00000 01:00:00.0 +00007 00:00:00.0
위의 실행결과는 스냅샷이 매 시간대 별로 수집되고 있으며 수집된 통계가 7일 동안 보관되고 있음을 보여주고 있습니다. 스냅샷 주기를 20분으로, 보관 주기를 2일로 변경하기 위해서는 아래와 같이 수행하면 됩니다. (매개변수는 분 단위로 표시됩니다.)
begin
dbms_workload_repository.modify_snapshot_settings (
interval => 20,
retention => 2*24*60
);
end;
AWR은 수집된 통계를 저장하기 위해 여러 개의 테이블을 사용합니다. 이 테이블들은 모두 SYS 스키마의 SYSAUX 테이블스페이스 내에 저장되어 있으며, WRM$_* 또는 WRH$_*의 네임 포맷을 갖습니다. WRM$_* 테이블은 수집 대상 데이타베이스 및 스냅샷에 관련한 메타데이타 정보를, WRH$_* 테이블은 실제 수집된 통계 정보를 저장하는데 사용됩니다. (예측하시는 바와 같이, H는 “historical”, M은 “metadata”의 약자를 의미합니다.) 이 테이블을 기반으로 DBA_HIST_라는 prefix를 갖는 여러 가지 뷰가 제공되고 있으며, 이 뷰들을 응용하여 자신만의 성능 분석 툴을 만들 수도 있습니다. 뷰의 이름은 테이블 이름과 직접적인 연관성을 갖습니다. 예를 들어 DBA_HIST_SYSMETRIC_SUMMARY 뷰는 WRH$_SYSMETRIC_SUMMARY 테이블을 기반으로 합니다.
AWR 히스토리 테이블은 Statspack에서는 수집되지 않았던 다양한 정보(테이블스페이스 사용 통계, 파일시스템 사용 통계, 운영체제 통계 등)를 제공합니다. 테이블의 전체 리스트는 아래와 같이 데이타 딕셔너리 조회를 통해 확인할 수 있습니다:
select view_name from user_views where view_name like 'DBA_HIST_%' escape '';
DBA_HIST_METRIC_NAME 뷰는 AWR에 수집되는 주요 메트릭과 메트릭이 속한 그룹, 그리고 수집 단위(unit) 등을 정의하고 있습니다. DBA_HIST_METRIC_NAME 뷰의 레코드에 대한 조회 결과의 예가 아래와 같습니다:
DBID : 4133493568
GROUP_ID : 2
GROUP_NAME : System Metrics Long Duration
METRIC_ID : 2075
METRIC_NAME : CPU Usage Per Sec
METRIC_UNIT : CentiSeconds Per Second
위에서는 "초당 CPU 사용량(CPU Usage Per Sec)" 메트릭이 “100분의 1초(CentiSeconds Per Second)” 단위로 수집되고 있으며, 이 메트릭이 "System Metrics Long Duration” 그룹에 속함을 확인할 수 있습니다. 이 레코드를 DBA_HIST_SYSMETRIC_SUMMARY와 JOIN하여 실제 통계를 확인할 수 있습니다:
select begin_time, intsize, num_interval, minval, maxval, average, standard_deviation sd
from dba_hist_sysmetric_summary where metric_id = 2075;
BEGIN INTSIZE NUM_INTERVAL MINVAL MAXVAL AVERAGE SD
----- ---------- ------------ ------- ------- -------- ----------
11:39 179916 30 0 33 3 9.81553548
11:09 180023 30 21 35 28 5.91543912
... 후략 ...
위 조회 결과를 통해 백 분의 1초 단위로 CPU 자원이 어떻게 소비되고 있는지 확인할 수 있습니다. SD(standard deviation, 표준 편차) 값을 참조하면 계산된 평균 값이 실제 부하와 비교하여 얼마나 오차를 갖는지 분석 가능합니다. 첫 번째 레코드의 경우, 초당 백 분의 3초의 CPU 시간이 소모된 것으로 계산되었지만, 표준 편차가 9.81이나 되므로 계산된 3의 평균값이 실제 부하를 정확하게 반영하지 못하는 것으로 볼 수 있습니다. 반면 28의 평균값과 5.9의 표준 편차를 갖는 두 번째 레코드가 실제 수치에 더 가깝다고 볼 수 있습니다. 이러한 트렌드 분석을 통해 성능 메트릭과 환경 변수의 상관 관계를 보다 명확하게 이해할 수 있습니다.
통계의 활용
지금까지 AWR의 수집 대상이 어떻게 정의되는지 알아보았습니다. 이번에는 수집된 데이타를 어떻게 활용할 수 있는지 설명하기로 합니다.
성능 문제는 독립적으로 존재하는 경우가 거의 없으며, 대개 다른 근본적인 문제를 암시하는 징후로서 해석되는 것이 일반적입니다. 전형적인 튜닝 과정의 예를 짚어보기로 합시다: DBA가 시스템 성능이 저하되었음을 발견하고 wait에 대한 진단을 수행합니다. 진단 결과 “buffer busy wait”이 매우 높게 나타나고 있음을 확인합니다. 그렇다면 문제의 원인은 무엇일까요? 여러 가지 가능성이 존재합니다: 인덱스의 크기가 감당할 수 없을 만큼 커지고 있을 수도 있고, 테이블의 조밀도(density)가 너무 높아 하나의 블록을 메모리에 읽어 오는 데 요구되는 시간이 제한된 때문일 수도 있고, 그 밖의 다른 이유가 있을 수 있습니다. 원인이 무엇이든, 문제가 되는 세그먼트를 먼저 확인해 보는 것이 필요합니다. 문제가 인덱스 세그먼트에서 발생했다면, 리빌드 작업을 수행하거나 reverse key index로 변경하거나 또는 Oracle Database 10g에서 새로 제공하는 hash-partitioned index로 변경해 볼 수 있을 것입니다. 문제가 테이블에서 발생했다면, 저장 관련 매개변수를 변경해서 조밀도를 낮추거나, 자동 세그먼트 공간 관리(automatic segment space management)가 설정된 테이블스페이스로 이동할 수 있을 것입니다.
DBA가 실제로 사용하는 접근법은 일반적인 방법론, DBA의 경험 및 지식 등을 그 바탕으로 합니다. 만일 똑같은 일을 별도의 엔진이, 메트릭을 수집하고 사전 정의된 로직을 바탕으로 적용 가능한 방법을 추론하는 엔진이 대신해 준다면 어떨까요? DBA의 작업이 한층 쉬워지지 않을까요?
바로 이러한 엔진이 Oracle Database 10g에 새로 추가된 Automatic Database Diagnostic Monitor (ADDM)입니다. ADDM은 AWR이 수집한 데이타를 사용하여 결론을 추론합니다. 위의 예의 경우, ADDM은 buffer busy wait이 발생하고 있음을 감지하고, 필요한 데이타를 조회하여 wait이 실제로 발생하는 세그먼트를 확인한 후, 그 구조와 분포를 평가함으로써 최종적으로 해결책을 제시합니다. AWR의 스냅샷 수집이 완료될 때마다, ADDM이 자동으로 호출되어 메트릭을 점검하고 권고사항을 제시합니다. 결국 여러분은 데이타 분석 및 권고사항 제시를 담당하는 풀 타임 DBA 로봇을 하나 두고, 보다 전략적인 업무에 집중할 수 있게 된 셈입니다.
Enterprise Manager 10g 콘솔의 “DB Home” 페이지에서 ADDM의 권고사항과 AWR 리포지토리 데이타를 확인할 수 있습니다. AWR 리포트를 보려면, Administration->Workload Repository->Snapshot의 순서로 메뉴를 따라가야 합니다. ADDM의 자세한 기능은 향후 연재에서 소개하도록 하겠습니다.
특정 조건을 기준으로 알림 메시지를 생성하도록 설정하는 것도 가능합니다. 이 기능은 Server Generated Alert라 불리며, Advanced Queue에 푸시(push) 형태로 저장되고 리스닝 중인 모든 클라이언트에 전달되는 형태로 관리됩니다. Enterprise Manager 10g 역시 Server Generated Alert의 클라이언트의 하나로서 관리됩니다.
타임 모델 (Time Model)
성능 문제가 발생했을 때, 응답시간을 줄이기 위한 방법으로 DBA의 머릿속에 가장 먼저 떠오르는 것은 무엇일까요? 말할 필요도 없이, 문제의 근본원인을 찾아내어 제거하는 것이 최우선일 것입니다. 그렇다면 얼마나 많은 시간이 (대기가 아닌) 실제 작업에 사용되었는지 어떻게 확인할 수 있을까요? Oracle Database 10g는 여러 가지 자원에 관련한 실제 사용 시간을 확인하기 위한 타임 모델(time model)을 구현하고 있습니다. 전체 시스템 관련 소요 시간 통계는 V$SYS_TIME_MODEL 뷰에 저장됩니다. V$SYS_TIME_MODEL 뷰에 대한 쿼리 결과의 예가 아래와 같습니다.
STAT_NAME VALUE
------------------------------------- --------------
DB time 58211645
DB CPU 54500000
background cpu time 254490000
sequence load elapsed time 0
parse time elapsed 1867816
hard parse elapsed time 1758922
sql execute elapsed time 57632352
connection management call elapsed time 288819
failed parse elapsed time 50794
hard parse (sharing criteria) elapsed time 220345
hard parse (bind mismatch) elapsed time 5040
PL/SQL execution elapsed time 197792
inbound PL/SQL rpc elapsed time 0
PL/SQL compilation elapsed time 593992
Java execution elapsed time 0
bind/define call elapsed time 0
위에서 DB time이라는 통계정보는 인스턴스 시작 이후 데이타베이스가 사용한 시간의 누적치를 의미합니다. 샘플 작업을 실행한 다음 다시 뷰를 조회했을 때 표시되는 DB time의 값과 이전 값의 차이가 바로 해당 작업을 위해 데이타베이스가 사용한 시간이 됩니다. 튜닝을 거친 후 DB time 값의 차이를 다시 분석하면 튜닝을 통해 얻어진 성능 효과를 확인할 수 있습니다.
이와 별도로 V$SYS_TIME_MODEL 뷰를 통해 파싱(parsing) 작업 또는 PL/SQL 컴파일 작업에 소요된 시간 등을 확인할 수 있습니다. 이 뷰를 이용하면 시스템이 사용한 시간을 확인하는 것도 가능합니다. 시스템 / 데이타베이스 레벨이 아닌 세션 레벨의 통계를 원한다면 V$SESS_TIME_MODEL 뷰를 이용할 수 있습니다. V$SESS_TIME_MODEL 뷰는 현재 연결 중인 active/inactive 세션들의 통계를 제공합니다. 세션의 SID 값을 지정해서 개별 세션의 통계를 확인할 수 있습니다.
이전 릴리즈에서는 이러한 통계가 제공되지 않았으며, 사용자들은 여러 정보 소스를 참고해서 근사치를 추측할 수 밖에 없었습니다.
Active Session History
Oracle Database 10g의 V$SESSION에도 개선이 이루어졌습니다. 가장 중요한 변화로 wait 이벤트와 그 지속시간에 대한 통계가 뷰에 추가되어, V$SESSION_WAIT를 별도로 참조할 필요가 없게 되었다는 점을 들 수 있습니다. 하지만 이 뷰가 실시간 정보를 제공하므로, 나중에 다시 조회했을 때에는 중요한 정보가 이미 사라져 버리고 없을 수 있습니다. 예를 들어 wait 상태에 있는 세션이 있음을 확인하고 이를 조회하려 하면, 이미 wait 이벤트가 종료되어 버려 아무런 정보도 얻지 못하는 경우가 있을 수 있습니다.
또 새롭게 추가된 Active Session History(ASH)는 AWR과 마찬가지로 향후 분석 작업을 위해 세션 성능 통계를 버퍼에 저장합니다. AWR과 다른 점은, 테이블 대신 메모리가 저장 매체로 이용되며 V$ACTIVE_SESSION_HISTORY 등을 통해 조회된다는 사실입니다. 데이타는 1초 단위로 수집되며, 액티브 세션만이 수집 대상이 됩니다. 버퍼는 순환적인 형태로 관리되며, 저장 메모리 용량이 가득 차는 경우 오래된 데이타부터 순서대로 삭제됩니다. 이벤트를 위해 대기 중인 세션의 수가 얼마나 되는지 확인하려면 아래와 같이 조회하면 됩니다:
select session_id||','||session_serial# SID, n.name, wait_time, time_waited
from v$active_session_history a, v$event_name n
where n.event# = a.event#
위 쿼리는 이벤트 별로 대기하는 데 얼마나 많은 시간이 사용되었는지를 알려 줍니다. 특정 wait 이벤트에 대한 드릴다운을 수행할 때에도 ASH 뷰를 이용할 수 있습니다. 예를 들어, 세션 중 하나가 buffer busy wait 상태에 있는 경우 정확히 어떤 세그먼트에 wait 이벤트가 발생했는지 확인하는 것이 가능합니다. 이때 ASH 뷰의 CURRENT_OBJ# 컬럼과 DBA_OBJECTS 뷰를 조인하면 문제가 되는 세그먼트를 확인할 수 있습니다.
ASH 뷰는 그 밖에도 병렬 쿼리 서버 세션에 대한 기록을 저장하고 있으므로, 병렬 쿼리의 wait 이벤트를 진단하는 데 유용하게 활용됩니다. 레코드가 병렬 쿼리의 slave process로서 활용되는 경우, coordinator server session의 SID는 QC_SESSION_ID 컬럼으로 확인할 수 있습니다. SQL_ID 컬럼은 wait 이벤트를 발생시킨 SQL 구문의 ID를 의미하며, 이 컬럼과 V$SQL 뷰를 조인하여 문제를 발생시킨 SQL 구문을 찾아낼 수 있습니다. CLIENT_ID 컬럼은 웹 애플리케이션과 같은 공유 사용자 환경에서 클라이언트를 확인하는 데 유용하며, 이 값은 DBMS_SESSION.SET_IDENTFIER를 통해 설정 가능합니다.
ASH 뷰가 제공하는 정보의 유용성을 감안하면, AWR과 마찬가지로 이 정보들을 영구적인 형태의 매체에 저장할 필요가 있을 수도 있습니다. AWR 테이블을 MMON 슬레이브를 통해 디스크로 flush 할 수 있으며, 이 경우 DBA_HIST_ACTIVE_SESS_HISTORY 뷰를 통해 저장된 결과를 확인할 수 있습니다.
수작업으로 스냅샷 생성하기
스냅샷은 자동으로 수집되도록 디폴트 설정되어 있으며, 원하는 경우 온디맨드 형태의 실행이 가능합니다. 모든 AWR 기능은 DBMS_WORKLOAD_REPOSITORY 패키지에 구현되어 있습니다. 스냅샷을 실행하려면 아래와 같은 명령을 사용하면 됩니다:
execute dbms_workload_repository.create_snapshot
위 명령은 스냅샷을 즉각적으로 실행하여 그 결과를 table WRM$_SNAPSHOT 테이블에 저장합니다. 수집되는 메트릭의 수준은 TYPICAL 레벨로 설정됩니다. 더욱 자세한 통계를 원하는 경우 FLUSH_LEVEL 매개변수를 ALL로 설정하면 됩니다. 수집된 통계는 자동으로 삭제되며, 수작업으로 삭제하려는 경우 drop_snapshot_range() 프로시저를 실행하면 됩니다.
베이스라인
성능 튜닝 작업을 수행할 때에는 먼저 일련의 메트릭에 대한 베이스라인(baseline)을 수집하고 튜닝을 위한 변경 작업을 수행한 뒤, 다시 또 다른 베이스라인 셋을 수집하는 과정을 거치는 것이 일반적입니다. 이렇게 수집된 두 가지 셋을 서로 비교하여 변경 작업의 효과를 평가할 수 있습니다. AWR에서는 기존에 수집된 스냅샷을 통해 이러한 작업이 가능합니다. 예를 들어 매우 많은 자원을 사용하는 apply_interest라는 프로세스가 오후 1시부터 3시까지 실행되었고, 이 기간 동안 스냅샷 ID 56에서 59까지가 수집되었다고 합시다. 이 스냅샷들을 위해 apply_interest_1이라는 이름의 베이스라인을 아래와 같이 정의할 수 있습니다:
exec dbms_workload_repository.create_baseline (56,59,'apply_interest_1')
위 명령은 스냅샷 56에서 59까지를 ‘apply_interest_1’이라는 이름의 베이스라인으로 표시합니다. 기존에 설정된 베이스라인은 아래와 같이 확인합니다:
select * from dba_hist_baseline;
DBID BASELINE_ID BASELINE_NAME START_SNAP_ID END_SNAP_ID
---------- ----------- -------------------- ------------- -----------
4133493568 1 apply_interest_1 56 59
튜닝 과정을 거친 후, 또 다른 이름(예: apply_interest_2)의 베이스라인을 생성하여, 이 두 가지 베이스라인에 해당하는 스냅샷의 메트릭을 비교할 수 있습니다. 이처럼 비교 대상을 한정함으로써 성능 튜닝의 효과를 한층 향상시킬 수 있습니다. 분석이 끝나면 drop_baseline(); 프로시저로 베이스라인을 삭제할 수 있습니다 (이 때 스냅샷은 그대로 보존됩니다). 또 오래된 스냅샷이 삭제되는 과정에서, 베이스라인과 연결된 스냅샷은 삭제되지 않습니다.
결론
이 문서는 AWR의 매우 기초적인 기능만을 소개하고 있습니다. 더욱 자세한 내용을 확인하시려면 Oracle Database 10g 제품 문서를 확인하시기 바랍니다. 기술백서(“ The Self-Managing Database: Automatic Performance Diagnosis)에서도 AWR과 ADDM를 매우 깊이 있게 다루고 있습니다. 제 18주에는, ADDM을 이용하여 실제 문제를 해결하는 방법에 대해 자세하게 설명할 예정입니다.
제 7 주
SQL*Plus의 향상된 기능
Oracle Database 10g의 SQL*Plus 툴에는 프롬프트, 파일 조작 기능 등 몇 가지 눈에 띄는 기능 개선이 추가되었습니다.
DBA가 하루에 가장 많이 사용하는 툴은 무엇일까요? 아마 GUI 대신 오래된 작업 방식을 고수하고 있는 본인과 같은 DBA들이라면 SQL*Plus 커맨드 라인 툴을 그 첫 번째로 꼽을 것입니다.
Oracle Database 10g에서 Enterprise Manager 10g의 기능이 한층 강화되었음에도 불구하고, 초심자와 숙련된 DBA 모두에게 있어 SQL*Plus는 앞으로도 오랫동안 유용하게 활용될 것입니다.
이번 연재에서는 SQL*Plus 10.1.0.2에 추가된 유용한 기능을 살펴 보고자 합니다. 이 강좌를 따라 해 보려면 Oracle Database 10g에 포함된 sqlplus를 사용해야 함을 주의하시기 바랍니다 (Oracle9i Database의 sqlplus을 사용해서 10g 데이타베이스에 접속해서는 안됩니다).
프롬프트의 활용
지금 나는 어디에 있는가? 그리고 나는 누구인가? 지금 형이상학적인 질문을 던지려는 것이 아닙니다. SQL*Plus 환경의 관점에서 사용자의 위치를 묻는 질문입니다. SQL*Plus가 지금까지 천편일률적으로 제공했던 SQL> 프롬프트는 사용자가 누구이고 어디에 연결되었는지에 대한 아무런 정보도 제공하지 않습니다. 이전 릴리즈에서는 프롬프트를 바꾸려면 복잡한 코딩이 필요했습니다. SQL*Plus 10.1.0.2는 아래와 같은 간단한 명령만으로 프롬프트를 바꿀 수 있습니다:
set sqlprompt "_user _privilege> "
그러면 SQL*Plus 프롬프트는 아래와 같은 형식으로 표시됩니다:
SYS AS SYSDBA>
위의 경우는 SYS 사용자가 SYSDBA로서 접속한 상황임을 의미합니다. 위에서 _user와 _privilege라는 두 개의 변수가 활용되는 방법을 참고하십시오. _user는 현재 사용자를 _privilege는 로그인에 사용되는 privilege를 뜻합니다.
이번에는 다른 방법을 써 봅시다. 아래는 프롬프트에 오늘 날짜가 함께 표시되도록 하는 명령입니다:
SQL> set sqlprompt "_user _privilege 'on' _date >"
SYS AS SYSDBA on 06-JAN-04 >
여기에 database connection identifier를 추가할 수도 있습니다. 이 방법은 사용자의 “위치”를 수시로 확인해야 하는 환경에서 대단히 유용합니다.
SQL> set sqlprompt "_user 'on' _date 'at' _connect_identifier >"
ANANDA on 06-JAN-04 at SMILEY >
이번에는 오늘 날짜에 시간과 분까지 함께 표시하도록 해 보겠습니다.
ANANDA on 06-JAN-04 at SMILEY > alter session set nls_date_format = 'mm/dd/yyyy hh24:mi:ss';
Session altered.
ANANDA on 01/06/2004 13:03:51 at SMILEY >
이처럼 몇 번의 간단한 키 입력 만으로 매우 많은 정보를 포함하는 SQL 프롬프트가 만들어졌습니다. 이 설정을 glogin.sql 파일에 저장하면 앞으로도 계속 같은 프롬프트를 사용할 수 있습니다.
불필요한 인용부호의 생략
Oracle9i이 internal login을 더 이상 지원하지 않는다고 발표되었을 때, 많은 DBA들은 불만의 함성을 터뜨렸습니다. Internal login이 없다면 커맨드 라인 상에서 SYS 패스워드를 입력할 수 없고 따라서 보안 관리가 어려워진다는 이유였습니다. 오라클은 그 해결책으로 운영체제 프롬프트 상에서 인용부호를 사용하는 방법을 제시했습니다:
sqlplus "/ as sysdba"
DBA들은 이러한 변화에 만족하지 않았지만 참고 받아들일 수 밖에 없었습니다. Oracle Database 10g에서는 이러한 요구사항이 없어졌으며, 아래와 같은 방법으로 인용부호를 사용하지 않고 SYSDBA권한으로 로그인하는 것이 가능합니다.
sqlplus / as sysdba
이러한 변화는 단순히 입력할 문자의 수가 줄었다는 것만을 의미하지 않습니다. Unix와 같은 운영체제에서 escape 문자를 사용할 필요가 없어졌다는 것도 새로운 이점의 하나입니다.
파일 조작 기능의 향상
DBA가 문제 해결 과정에서 임시로 만든 SQL 구문이 있다고 가정해 봅시다. 이 DBA는 만든 구문을 나중에 다시 재사용하기 위해 저장하고 싶어할 수도 있습니다. 이럴 때 어떻게 해야 할까요? 아마도 아래와 같은 방법으로 파일에 개별 저장하는 방법을 쓰게 될 것입니다:
select something1 ....
save 1
select something else ....
save 2
select yet another thing ....
save 3
결국 위의 구문을 모두 사용하려면 그에 해당하는 세이브 파일을 모두 불러내어야 합니다. 이 얼마나 번거로운가요! SQL*Plus 10.1.0.2는 여러 구문을 파일에 append하는 형태로 저장하는 기능을 제공합니다. 위의 경우라면 아래와 같은 명령을 사용할 수 있습니다:
select something1 ....
save myscripts
select something else ....
save myscripts append
select yet another thing ....
save myscripts append
이렇게 하면 모든 구문을 myscript.sql 파일에 append 된 형태로 저장할 수 있으므로, 여러 파일에 나누어 저장한 뒤 이를 다시 하나로 연결할 필요가 없게 됩니다.
스풀링(spooling)에서도 append 형태의 저장 방식이 사용됩니다. 이전 릴리즈에서는 SPOOL RESULT.LST 명령으로 result.lst 파일을 생성할 수 있었지만, 기존에 같은 이름의 파일이 존재하는 경우 아무런 경고도 없이 덮어쓰기가 실행된다는 문제가 있었습니다. 이 때문에 실제로 작업을 수행하는 과정에서 중요한 파일이 덮어씌워져 버리는 곤란한 상황이 발생하곤 했습니다. 10g에서는 spool 명령을 수행하면서 append 방식으로 저장하도록 설정할 수 있습니다:
spool result.lst append
덮어쓰기를 원한다면 위의 append 조건 대신 REPLACE 조건을 삽입하면 됩니다. (REPLACE는 디폴트로 적용됩니다.) 아래 명령을 사용하면 세이브하기 전에 기존 파일이 존재하는지 점검합니다:
spool result.lst create
Use another name or "SPOOL filename[.ext] REPLACE"
This approach will prevent the overwriting of the file result.lst.
Login.sql 관련 문제
login.sql과 glogin.sql이라는 파일을 기억하십니까? SQL*Plus가 실행되면 현재 디렉토리에 있는 login.sql이 자동으로 실행됩니다. 하지만 심각한 기능상의 문제가 존재했습니다. Oracle9i 및 이하 버전의 login.sql 파일에 아래와 같은 내용이 포함되어 있는 경우를 생각해 봅시다:
set sqlprompt "_connect_identifier >"
데이타베이스DB1에 접속하기 위해 SQL*Plus를 실행하면 아래와 같이 프롬프트가 표시됩니다:
DB1>
이 프롬프트 상에서 데이타베이스 DB2로의 접속을 시도해 봅시다:
DB1> connect scott/tiger@db2
Connected
DB1>
DB2로 접속한 상태임에도 프롬프트가 여전히 DB1으로 표시되고 있습니다. 이유는 간단합니다. login.sql 파일은 데이타베이스 연결 시에 실행되지 않으며 SQL*Plus 시작 시에만 실행되기 때문입니다. Oracle Database 10g에서는 이러한 문제가 해결되었습니다. login.sql은 SQL*Plus가 시작되는 시점뿐 아니라 새로운 연결이 설정되는 경우에도 자동 실행됩니다. 10g 환경에서 DB1에 접속해 있다가 다른 데이타베이스로 연결을 변경하는 경우, 아래와 같이 프롬프트도 같이 변경됩니다.
In Oracle Database 10g, this limitation is removed. The file login.sql is not only executed at SQL*Plus startup time, but at connect time as well. So in 10g, if you are currently connected to database DB1 and subsequently change connection, the prompt changes.
SCOTT at DB1> connect scott/tiger@db2
SCOTT at DB2> connect john/meow@db3
JOHN at DB3>
변화를 원치 않는다면?
어떤 이유로든, SQL*Plus의 개선된 기능을 사용하고 싶지 않은 경우도 있을 수 있습니다. 그런 경우라면, 아래처럼 –C 옵션을 적용하면 됩니다:
sqlplus -c 9.2
위와 같이 입력하는 경우 9.2 버전의 SQL*Plus 환경이 실행됩니다.
Use DUAL Freely
아래와 같은 명령을 실제로 사용하는 개발자(또는 DBA)의 수가 얼마나 될 것이라 생각하십니까?
select USER into <some variable> from DUAL
아마 거의 모든 이들이 사용하고 있을 것입니다. DUAL은 호출될 때마다 새로운 논리적 I/O(Buffer I/O)를 생성합니다. 이 기능은 매우 유용하게 활용됩니다. DUAL은 <somevariable> := USER와 같은 구문만큼이나 자주 사용되고 있습니다. 하지만 오라클 코드는 DUAL을 특수한 형태의 테이블로서 취급하며, 따라서 일반적인 튜닝 방법은 적용할 수 없다는 문제가 있습니다.
Oracle Database 10g에서라면 이에 관련한 걱정은 할 필요가 없습니다. DUAL이 특수한 테이블이기 때문에, 논리적 I/O를 나타내는 consistent gets의 값도 줄어들며, event 10046 trace에서 확인할 수 있는 것처럼 optimization plan도 다른 형태로 나타납니다.
Oracle9i의 경우
Rows Execution Plan
------- ---------------------------------------------------
0 SELECT STATEMENT GOAL: CHOOSE
1 TABLE ACCESS (FULL) OF 'DUAL'
10g의 경우
Rows Execution Plan
------- ---------------------------------------------------
0 SELECT STATEMENT MODE: ALL_ROWS
0 FAST DUAL
Oracle 9i에서 사용되는 DUAL의 FULL TABLE SCAN 대신, 10g에서는 FAST DUAL optimization plan을 사용하고 있다는 점을 주목하시기 바랍니다. 이러한 기능 개선을 통해 DUAL 테이블을 자주 사용하는 애플리케이션의 연속적인 읽기 작업 성능이 대폭적으로 향상되었습니다.
참고: 엄밀하게 말하자면 DUAL 관련 기능 개선은 SQL*Plus가 아닌 SQL Optimizer의 기능이라고 보는 것이 타당할 것입니다. 여기에서는 이 기능에 접근하기 위해 주로 사용되는 툴이 SQL*Plus라는 이유로 이 기능을 소개합니다.
그 밖에 유용한 팁
그 밖에 SQL*Plus에 관련한 몇 가지 팁이 이 시리즈 전반에 걸쳐 소개되고 있습니다. 예를 들어, RECYCLEBIN 개념은 제 5주 Flashback Table 관련 연재에서 소개됩니다.
일반에 알려진 것과 달리, COPY 명령은 여전히 사용 가능합니다. 하지만 향후 릴리즈에서는 기능이 삭제될 것이라 합니다. (Oracle9i 시절부터 듣던 얘기가 아닌가요?) 이 명령이 적용된 스크립트를 사용하는 중이라면 고민할 필요가 없습니다. 사용 가능할 뿐 아니라 기술지원도 제공됩니다. 더군다나 에러 메시지 리포팅에 관련한 기능 개선도 일부 이루어졌습니다. 테이블이 LONG 칼럼을 포함하는 경우, 해당 테이블에 대한 복제본을 생성하려면 COPY 명령에 의존할 수 밖에 없습니다. CREATE TABLE AS SELECT 명령은 long 데이타 타입의 컬럼을 포함하는 테이블을 지원하지 않습니다.
제 8 주
Automatic Storage Management
마침내, DBA들은 스토리지 디스크를 추가, 이동, 삭제하는 반복적인 일상 업무로부터 해방될 수 있게 되었습니다.
오라클 데이타베이스에 사용할 새로운 서버와 스토리지 서브시스템을 지금 막 접수한 상황이라고 가정해 봅시다. 운영체제를 구성하는 문제를 제외하고, 데이타베이스를 설치하기 전에 먼저 선행되어야 할 가장 중요한 작업이 무엇일까요? 그것은 바로 스토리지 시스템 레이아웃을 생성하는 일, 좀 더 구체적으로 말해 보호 레벨(protection level)을 정의하고 적합한 RAID(Redundant Array of Inexpensive Disks) 셋을 구성하는 일일 것입니다.
데이타베이스 설치 과정에서 스토리지를 구성하는 작업은 상당히 많은 시간을 소요합니다. 적합한 디스크 구성을 선택하기 위해서는 매우 신중한 계획과 분석이 필요하며, 무엇보다도 스토리지 테크놀로지, 볼륨 관리자, 파일 시스템 등에 대한 깊은 지식을 요구합니다. 이 과정에서 수행되는 설계 작업은 대충 아래와 같은 단계로 정리할 수 있습니다. (아래는 매우 일반적인 내용만을 포함하고 있으며, 실제 작업은 구성에 따라 달라질 수 있습니다.)
스토리지가 운영체제 레벨에서 인식되는지 확인하고, 중복성(redundancy) 및 보호 레벨(protection level)을 결정합니다 (hardware RAID).
논리적 볼륨 그룹을 생성하고, 필요한 경우 스트라이핑 또는 미러링 구성을 선택합니다.
논리적 볼륨 관리자(logical volume manager)를 이용하여 논리적 볼륨 상에 파일 시스템을 생성합니다.
Oracle 프로세스가 디바이스에 대한 열기, 읽기, 쓰기를 수행할 수 있도록 접근권한 설정을 합니다.
파일시스템 상에 데이타베이스를 생성하고, 가능한 경우 리두 로그, 임시 테이블스페이스, 언두 테이블스페이스 등을 별도의 non-RAID 디스크에 배치합니다.
대부분의 환경에서는, 이러한 작업의 대부분은 스토리지 시스템에 조예가 깊은 전문가에 의해 수행됩니다. 여기서 말하는 “전문가”는 DBA와 다른 별도의 인력을 의미하는 경우가 많습니다.
하지만 스트라이핑, 미러링, 논리적 파일시스템 생성과 같은 모든 작업이 단지 Oracle Database만을 위해 수행된다는 점을 감안한다면, 오라클에서 이러한 절차를 단순화할 수 있는 테크닉을 직접 제공하는 것이 순리에 맞지 않을까요?
Oracle Database 10g가 바로 이를 위한 기능을 제공합니다. Automatic Storage Management(ASM)은 위에서 언급된 작업의 상당 부분을 DBA가 오라클 프레임워크 내에서 직접 수행할 수 있도록 하는 자동화 옵션입니다. ASM을 이용하면 별도의 비용을 지불하지 않고도 Oracle Database 10g가 기본적으로 지원하는 기능만을 활용하여 높은 확장성과 성능을 갖는 파일시스템/볼륨 관리자 환경을 구현할 수 있습니다. 또 디스크, 볼륨 관리자, 파일 시스템 관리에 대한 전문적인 지식을 가지고 있을 필요도 없습니다.
이번 연재에서는, 실제 환경에서 ASM을 활용하기 위한 기본적인 방법을 설명합니다. ASM은 제한된 지면을 통해 섭렵하기에는 너무도 방대하고 강력한 기능입니다. 더 자세한 정보를 원하신다면 결론부분에서 소개하는 자료들을 참고하시기 바랍니다.
ASM이란 무엇인가?
데이타베이스에 사용할 디스크가 10개 있다고 가정해 봅시다. ASM을 이용하는 경우, OS에서는 아무 것도 수행할 필요가 없습니다. ASM은 일련의 물리적 디스크를 “디스크그룹(diskgroup)”이라는 논리적 개체로 자동으로 그룹화합니다. ASM이 사용하는 파일시스템은 사용자 파일을 저장할 수 없으며 버퍼링 기능을 제공하지 않으므로 범용 파일시스템으로 사용될 수는 없습니다. 하지만 (버퍼링 기능이 포함되지 않았기 때문에) 직접 액세스(direct access)를 통해 로우 디바이스(raw device) 수준의 성능을 내는 동시에 파일 시스템이 제공하는 편의성과 유연성을 활용할 수 있다는 장점을 제공합니다.
논리적 볼륨 관리자는 일반적으로 블록의 논리적 주소를 물리적 주소로 변환하는 함수를 제공합니다. 이 변환 작업에는 CPU 자원이 사용됩니다. 또 (RADI-5 등의) 스트라이프 구성에 새로운 디스크가 추가되는 경우, 전체 데이타 셋에 대해 비트 단위의 이동작업이 수행되어야 합니다.
반면 ASM은 파일 익스텐트(extent)를 물리적 디스크 블록으로 변환하기 위해 별도의 오라클 인스턴스를 사용합니다. 이러한 설계 덕분에 파일 익스텐트의 위치를 확인하는 작업을 보다 신속하게 수행할 수 있을 뿐 아니라, 디스크를 추가하거나 이동하는 경우에도 파일 익스텐트의 위치를 재조정할 필요가 없다는 이점을 제공합니다. ASM 인스턴스는 ASM이 실행되기 위해서 반드시 필요하며 사용자에 의해 변경될 수 없습니다. 동일 서버 내에 위치한 여러 개의 오라클 데이타베이스 인스턴스는 하나의 ASM 인스턴스를 공유합니다.
ASM 인스턴스는 “인스턴스”이긴 하지만 데이타베이스를 포함하지 않습니다. 디스크에 관련된 모든 메타데이타는 디스크그룹 자체에 저장되며, 최대한 “self-describing”한 형태로 기술됩니다.
ASM이 제공하는 이점을 간략히 정리하면 아래와 같습니다:
디스크의 추가 — 디스크의 추가 작업이 매우 간단합니다. 다운타임이 전혀 발생하지 않으며, 파일 익스텐트는 자동으로 재분배됩니다.
I/O 분산 – I/O는 전체 디스크에 골고루 분산됩니다. 이에 관련하여 수작업이 전혀 불필요하며, 성능 병목이 발생할 가능성도 그만큼 줄어듭니다.
스트라이프 “width”의 설정 – 스트라이핑의 데이타 전송 단위는 Redo Log 파일(128K 단위 전송)처럼 작게, 또는 데이타파일(1MB 단위 전송)처럼 크게 설정할 수 있습니다.
버퍼링 – ASM 파일시스템에는 버퍼링 기능이 구현되어 있지 않으며, 따라서 direct I/O를 이용해 성능 향상이 가능합니다.
Kernerlized Async I/O – kernelized asynchronous I/O를 위해 별도의 셋업 과정을 거칠 필요가 없으며, VERITAS Quick I/O와 같은 써드 파티 파일 시스템을 이용할 필요도 없습니다.
미러링 – 하드웨어 미러링을 적용할 수 없는 경우, 소프트웨어 미러링을 쉽게 구성할 수 있습니다.
ASM을 이용한 데이타베이스 생성
ASM을 이용해 데이타베이스를 생성하는 방법을 구체적으로 설명해 보겠습니다:
1. ASM Instance의 생성
Database Creation Assistant(DBCA)에서 아래와 같이 초기화 매개변수를 설정하여 ASM 인스턴스를 생성합니다:
INSTANCE_TYPE = ASM
ASM 인스턴스는 서버 부팅 과정에서 가장 먼저 시작되고, 서버 셧다운 과정에서 가장 마지막으로 중지되어야 합니다.
이 매개변수의 디폴트 값은 RDBMS이며, 이는 일반 데이타베이스 환경을 의미합니다.
2. Diskgroup의 셋업
ASM 인스턴스를 시작한 뒤, 구성된 디스크를 이용해 디스크그룹을 생성합니다.
CREATE DISKGROUP dskgrp1
EXTERNAL REDUNDANCY
DISK
'/dev/d1',
'/dev/d2',
'/dev/d3',
'/dev/d4',
... and so on for all the specific disks ...
;
위의 예에서는 dksgrp1이라는 이름의 디스크그룹을 생성하면서 /dev/d1, /dev/d2 등의 물리적 디스크를 개별적으로 지정했습니다. 이처럼 디스크를 일일이 지정할 수도 있지만, 아래와 같이 와일드카드를 사용하는 것도 가능합니다.
DISK '/dev/d*'
위 명령에서 EXTERNAL REDUNDANCY는 디스크에 장애가 발생하는 경우 디스크그룹이 다운됨을 의미합니다. 이러한 구성은 하드웨어 미러링 등의 구성이 별도로 지원되는 경우에 사용됩니다. 하드웨어 기반의 미러링이 사용되지 않는 경우라면, ASM에서 “failgroup”으로 지정된 디스크그룹을 생성하여 이를 대신할 수 있습니다.
CREATE DISKGROUP dskgrp1
NORMAL REDUNDANCY
FAILGROUP failgrp1 DISK
'/dev/d1',
'/dev/d2',
FAILGROUP failgrp2 DISK
'/dev/d3',
'/dev/d4';
위의 명령에서 d3와 d4가 d1과 d2의 미러(mirror)로서 1:1 대응되는 것이 아님에 주의하시기 바랍니다. ASM은 모든 디스크를 한꺼번에 활용하여 중복성(redundancy)을 구현합니다. 예를 들어, 디스크그룹의 d1에 생성된 특정 파일은 d4에 복제본을 가지고 있는 반면, d3에 생성된 다른 파일은 d2에 복제본을 가지고 있을 수 있습니다. 디스크에 장애가 발생한 경우 다른 디스크에 저장된 복제본을 이용하여 운영을 재개할 수 있습니다. d1과 d2가 연결된 컨트롤러가 다운된 경우에도, ASM은 failgroup으로 지정된 디스크를 이용하여 데이타 무결성을 보장합니다.
3. Tablespace의 생성
이제 ASM이 적용된 스토리지의 데이타파일을 사용하여 메인 데이타베이스의 테이블스페이스를 생성해 봅시다.
CREATE TABLESPACE USER_DATA DATAFILE '+dskgrp1/user_data_01'
SIZE 1024M
/
이걸로 끝입니다. 이제 셋업 과정은 모두 완료되었습니다.
디스크그룹이 가상 파일시스템(virtual file system)으로서 이용되고 있음을 참고하시기 바랍니다. 이러한 구성은 데이타파일 이외의 다른 오라클 파일을 생성하는 경우에도 유용하게 활용됩니다. 예를 들어 아래와 같이 온라인 리두 로그를 생성할 수 있습니다.
LOGFILE GROUP 1 (
'+dskgrp1/redo/group_1.258.3',
'+dskgrp2/redo/group_1.258.3'
) SIZE 50M,
...
관련 자료
앞에서 언급한 것처럼, 이 문서는 지면 문제로 ASM 기능에 대한 모든 내용을 다루지 않고 있지 않습니다. 하지만 Oracle Technology Network는 ASM과 관련한 많은 정보를 제공하고 있습니다.
"Storage on Automatic," (Lannes Morris-Murphy) – ASM 소개 자료로서 매우 훌륭한 설명을 담고 있습니다.
ASMLib, , Linux 환경을 위한 ASM 관련 라이브러리로, ASM의 기능을 더욱 확장시켜 줍니다. 라이브러리 모듈에 대한 테크니컬 자료와 소스 코드의 링크를 함께 제공합니다.
Oracle Database Administrator's Guide 10g Release 1 (10.1) 제 12장은 ASM에 관련하여 매우 자세한 배경 정보를 제공하고 있습니다.
아카이브 로그 역시 디스크그룹에 저장되도록 설정할 수 있습니다. 실제로 Oracle Database에 관련된 거의 모든 것이 ASM 기반 디스크그룹에서 생성 가능합니다. 백업 또한 ASM이 활용되는 분야의 하나입니다. 저가형 디스크를 이용해 데이타베이스 복구 영역을 생성한 다음, RMAN을 통해 데이타파일과 아카이브 로그파일 백업을 생성할 수 있습니다. (RMAN에 관련한 다음 연재에서 이 기능에 대해 자세히 설명할 예정입니다.)
ASM이 Oracle Database에 의해 생성되는 파일만을 지원한다는 사실을 주의하시기 바랍니다. ASM은 일반 파일 시스템을 대체하는 수단으로 이용될 수 없으며 바이너리 또는 플랫 파일을 저장할 수 없습니다.
유지 보수
디스크그룹의 유지보수를 위해 DBA가 일반적으로 수행하는 몇 가지 작업에 대해 설명하겠습니다. 디스크그룹 diskgrp1에 디스크를 추가하여 볼륨을 확장하고자 하는 경우, 아래와 같은 명령을 사용합니다:
alter diskgroup dskgrp1 add disk '/dev/d5';
어떤 디스크가 어떤 디스크그룹에 포함되었는지를 확인하려면 아래와 같이 입력합니다:
select * from v$asm_disk;
이 명령은 ASM 인스턴스가 관리하는 모든 데이타베이스의 디스크의 목록을 표시합니다. 특정 디스크를 제거하고자 하는 경우 아래 명령을 사용합니다:
alter diskgroup dskgrp1 drop disk diskb23;
결론
ASM을 이용하면 오라클 데이타베이스의 파일 관리 작업 환경을 한층 향상시키고, 고도의 확장성과 성능을 갖춘 스토리지 환경을 구성할 수 있습니다. ASM은 디스크의 자유로운 추가, 이동, 제거가 가능한 다이내믹 데이타베이스 환경을 구현하고 DBA를 반복적인 업무로부터 해방시키는데 필요한 툴셋을 제공합니다.
제 9 주
RMAN
한층 강력해진 RMAN 유틸리티는 개선된 증분백업, 증분백업의 오프라인 복구, 복구 파일 미리보기, resetlog를 이용한 복구, 파일 압축 등에 관련한 다양한 신기능을 제공합니다.
RMAN이 오라클 데이타베이스 백업 툴의 실질적인 표준으로서 인정되고 있다는 사실은 대부분의 사람들이 동의할 것입니다. 하지만 RMAN의 이전 버전에 문제가 많았던 것도 사실입니다. 필자 역시 RMAN의 기능적인 한계에 불만을 가진 사용자 중 하나였습니다.
Oracle Database 10g는 이러한 문제의 많은 부분을 해결하고 RMAN을 한층 강력하고 유용한 툴로 변화시켰습니다. 그러면 한 번 살펴보기로 합시다.
증분 백업 (Incremental Backup) 기능의 개선
RMAN은 이전부터 증분 백업을 위한 옵션을 제공해 왔습니다. 하지만 이 기능을 실제로 사용하는 경우는 극히 드물었습니다.
증분 백업은 마지막으로 증분 백업이 수행된 이후 변경된 블록만을 백업하는 방식입니다. 예를 들어 Day 1에 전체 백업(level_0)이 수행되고 Day 2와 Day 3에 두 차례의 증분 백업(level_1)이 수행된 경우를 생각해 봅시다. 두 개의 증분 백업은 각각 Day 1과 Day 2, Day 2와 Day3 사이에 변경된 블록만을 포함하고 있습니다. 이와 같은 백업 정책을 사용함으로써 백업 사이즈와 백업에 필요한 디스크 공간을 절감하고, 백업 윈도우를 단축할 수 있을 뿐 아니라 네트워크를 통해 전송되는 데이타 양을 줄일 수 있습니다.
증분 백업은 데이타 웨어하우스 환경에서 특히 유용합니다. 데이타 웨어하우스 작업의 많은 부분은 NOLOGGING 모드로 수행되므로 변경 내역이 아카이브 로그 파일에 저장되지 않으며, 따라서 미디어 복구가 불가능합니다. 데이타 웨어하우스 환경의 데이타 규모와 이 데이타의 대부분이 거의 변경되지 않는다는 사실을 고려할 때, 전체 백업은 효과적이지 못하며 현실적으로 불가능할 수도 있습니다. 그 대신 RMAN을 사용해서 증분 백업을 수행하는 것이 좋은 대안이 될 수 있습니다..
그렇다면 DBA들이 증분 백업 방식을 이용하지 않는 이유는 무엇일까요? Oracle9i와 그 이전 버전의 경우, RMAN은 증분 백업을 수행하기 위해 전체 데이타 블록에 대한 스캔을 수행했습니다. 이러한 작업이 시스템에 너무 큰 부담을 주기 때문에 증분 백업이 효율적이지 않다는 평가를 받게 된 것입니다.
Oracle Database 10g의 RMAN 기능은 이러한 점에서 크게 개선되었습니다. Oracle Database 10g는 (파일시스템의 저널과 유사한 용도를 갖는) 별도의 파일을 통해 마지막 백업 이후 변경된 블록을 추적합니다. RMAN은 (전체 데이타 블록을 스캔하는 대신) 이 파일을 참조하여 어떤 블록을 백업해야 하는지 결정합니다.
아래 명령을 통해 추적 메커니즘(tracking mechanism)을 활성화시킬 수 있습니다:
SQL> alter database enable block change tracking using file '/rman_bkups/change.log';
위 명령은 /rman_bkups/change.log 바이너리 파일을 생성하고 이 파일에 블록 변경 내역을 저장합니다. 아래 명령을 사용하면 추적 메커니즘을 비활성화할 수 있습니다:
SQL> alter database disable block change tracking;
현재 블록 변경 내역의 추적이 수행되고 있는지 확인하려면 아래 쿼리를 사용합니다:
SQL> select filename, status from v$block_change_tracking;
Flash Recovery Area
Oracle9i에서 처음 소개된 Flashback 쿼리는 언두 테이블스페이스를 사용하여 이전 버전으로의 “회귀(flash-back)”을 수행하며, 그 원리상 아주 오래 전의 과거 시점으로는 되돌릴 수 없다는 한계를 갖습니다. 이러한 문제의 대안으로서 제공되는 Flash Recovery는 리두 로그와 유사한 형태의 flashback log을 생성함으로써, 원하는 특정 시점으로 데이타베이스의 상태를 되돌릴 수 있게 합니다. Flash Recovery를 사용하려면 먼저 데이타베이스에 flash recovery area를 생성하고, 그 크기를 정의한 뒤 아래와 같은 SQL 명령을 통해 데이타베이스를 flash recovery mode로 설정하면 됩니다:
alter system set db_recovery_file_dest = '/ora_flash_area';
alter system set db_recovery_file_dest_size = 2g;
alter system set db_flashback_retention_target = 1440;
alter database flashback on;
Flashback 기능을 사용하려면 데이타베이스가 아카이브 로그 모드로 설정되어 있어야 합니다. Flash Recovery가 활성화되면 디렉토리 /ora_flash_area에 최대 2GB 크기의 Oracle Managed File이 생성됩니다. 모든 데이타베이스 변경 사항은 이 파일에 기록되며, 이 파일을 사용하여 과거의 특정 시점으로 데이타베이스를 복구할 수 있습니다.
RMAN은 /ora_flash_area 디렉토리를 디폴트 백업 파일 저장위치로 사용하며, 따라서 백업 파일은 테이프가 아닌 디스크에 저장됩니다. 이 경우 백업 파일을 얼마나 오랫동안 보존할 것인지 설정할 수 있으며, 정의된 보존 기간이 지난 후 추가 공간이 필요해지면 파일은 자동으로 삭제됩니다.
Flash recovery area가 반드시 파일시스템 또는 디렉토리일 필요는 없으며, ASM(Automatic Storage Management) 디스크그룹으로 지정할 수도 있습니다. Flash recovery area를 ASM 디스크그룹으로 지정하려면 아래와 같은 명령을 사용합니다:
alter system set db_recovery_file_dest = '+dskgrp1';
ASM과 RMAN을 함께 사용하면, 별도의 추가비용 없이 Serial ATA 드라이브 또는 SCSI 드라이브 등의 저가형 디스크를 사용해서 뛰어난 확장성과 가용성을 갖춘 스토리지 환경을 구성할 수 있습니다. (ASM에 대한 자세한 설명은 이 시리즈의 제 8 주 연재를 참고하시기 바랍니다.) 이와 같이 구성함으로써 테이프 기반 솔루션만큼 저렴한 비용으로 디스크 백업 환경을 구축하는 동시에 백업 프로세스의 실행 속도를 향상시킬 수 있습니다.
이 접근법의 또 한 가지 장점으로 사용자 실수에 대한 보호 기능을 들 수 있습니다. ASM 파일은 일반적인 파일시스템 환경이 아니기 때문에, DBA와 시스템 관리자의 실수로 손상될 가능성이 매우 적습니다.
증분 병합 (Incremental Merge)
아래와 같은 백업 스케줄을 갖는 환경을 가정해 봅시다:
일요일 - Level 0 (전체 백업), tag level_0
월요일 - Level 1 (증분 백업), tag level_1_mon
Tuesday - Level 1 (incremental) with tag level_1_tue
... (이하 생략)
이와 같은 백업정책 하에서, 토요일에 데이타베이스 장애가 발생한 경우, 10g 이전의 환경에서는 tag level_0를 복구하고 나머지 6개의 증분 백업본을 모두 복구해야만 했습니다. 이러한 작업에는 매우 오랜 시간이 걸리며, 이는 실제로 DBA가 증분 백업을 즐겨 사용하지 않는 이유 중 하나이기도 합니다.
Oracle Database 10g RMAN은 이러한 작업환경을 극적으로 개선했습니다. Oracle Database 10g RMAN의 증분 백업 명령은 아래와 같은 형태로 수행됩니다:
RMAN> backup incremental level_1 for recover of copy with tag level_0 database;
위에서 우리는 RMAN이 incremental level_1 백업을 수행하고 그 결과를 level_0의 전체 백업본과 병합(merge)하도록 설정했습니다. 이 명령을 수행하면 그 날의 전체 백업 이미지를 갖는 level_0 백업본이 새로이 생성됩니다.
예를 들어, 화요일에 수행된 증분 백업(level_1)은 이전의 전체 백업(level_0)과 병합되어 화요일 버전의 새로운 전체 백업본이 생성됩니다. 마찬가지로 토요일에 수행된 증분백업 역시, 금요일의 전체백업본과 병합되어 새로운 전체백업으로 저장됩니다. 따라서 토요일에 데이타베이스가 장애가 발생한다면, level_0 백업본 하나와 아카이브 로그 몇 개만을 이용하여 데이타베이스를 복구할 수 있습니다. 이러한 방법으로 복구에 소요되는 시간을 극적으로 절감하고, 백업 속도를 향상시키는 한편, 전체 백업의 수행 횟수를 줄일 수 있습니다.
압축 파일(Compressed Files)
Flash recovery area에 디스크 백업을 보관하는 경우에도, 디스크 공간의 한계라는 문제는 여전히 남습니다. 특히 네트워크를 통해 백업을 수행하는 환경이라면, 백업본의 크기를 최대한 작게 유지하는 구성이 권장됩니다. 이를 위해 Oracle Database 10g RMAN은 백업 명령에 새로운 압축 옵션을 추가하였습니다:
RMAN> backup as compressed backupset incremental level 1 database;
COMPRESSED 키워드가 사용된 형태를 주의해 보시기 바랍니다. 이 키워드를 사용하는 경우 백업 데이타의 압축을 통해 백업 성능을 향상할 수 있으며, 복구 과정에서는 별도의 압축해제 작업 없이도 RMAN이 파일을 읽어 들일 수 있습니다. 압축을 설정한 경우, 백업 수행 과정에서 아래와 같은 메시지가 출력됩니다.
channel ORA_DISK_1: starting compressed incremental level 1 datafile backupset
또, RMAN list output 명령을 통해 백업 압축 설정 여부를 확인할 수도 있습니다.
RMAN> list output;
BS Key Type LV Size Device Type Elapsed Time Completion Time
------- ---- -- ---------- ----------- ------------ ---------------
3 Incr 1 2M DISK 00:00:00 26-FEB-04
BP Key: 3 Status: AVAILABLE Compressed: YES Tag: TAG20040226T100154
Piece Name: /ora_flash_area/SMILEY10/backupset/2004_02_26/o1_mf_ncsn1_TAG20040226T100154_03w2m3lr_.bkp
Controlfile Included: Ckp SCN: 318556 Ckp time: 26-FEB-04
SPFILE Included: Modification time: 26-FEB-04
모든 압축 알고리즘이 그러하듯, 이 방법을 쓰는 경우 CPU에 추가적인 부담을 주게 됩니다. 반면, 더 많은 RMAN 백업을 디스크에 보관할 수 있다는 장점이 있습니다. 또 Physical Standby Database에서 RMAN 백업을 실행하면 원본 서버에 부담을 주지 않고 백업을 수행할 수 있습니다.
Look Before You Leap: Recovery Preview
Oracle Database 10g의 RMAN은 한 걸음 더 나아가 복구 작업에 사용할 수 있는 백업본을 미리 확인하는 Recovery Preview 기능을 지원합니다.
RMAN> restore database preview;
위 작업의 실행 결과는 Listing 1에서 확인하실 수 있습니다. 테이블스페이스 별로 백업본을 개별적으로 확인하는 것도 가능합니다:
restore tablespace users preview;
Preview 기능을 활용하여 백업 인프라스트럭처가 정상적으로 운영되고 있는지 정기적으로 점검할 수 있습니다.
Resetlog와 복구 작업
커런트 온라인 리두 로그(current online redo log) 파일이 손실되어, 불완전한 데이타베이스 복구(incomplete database recovery)를 수행할 수 밖에 없는 상황을 가정해 봅시다 (이러한 경우는 흔치 않지만 실재로 존재합니다). 이 경우 가장 큰 문제는 resetlog입니다. 불완전 복구를 수행한 뒤에 resetlog 키워드를 사용하여 log thread의 시퀀스 넘버를 1로 재설정하고 데이타베이스를 오픈해야 하는데, 이렇게 하는 경우 이전에 백업된 데이타가 무용지물이 될 뿐 아니라 복구 작업 자체가 더욱 어려워지게 됩니다.
Oracle9i와 그 이전 버전에서는 데이타베이스를 resetlog 이전의 상태로 복구하려면 전혀 새로운 환경에 데이타베이스를 새로 구축할 수 밖에 없었습니다. Oracle Database 10g에서는 이러한 문제가 해결되었습니다. 컨트롤 파일에 추가된 새로운 기능 덕분에, RMAN이 resetlog 수행 이전 또는 이후의 모든 백업 이미지를 복구에 이용할 수 있게 된 것입니다. 또 백업을 수행하기 위해 데이타베이스를 셧다운할 필요도 없게 되었습니다. 이 기능을 사용하면, resetlog 작업 이후 데이타베이스를 바로 오픈하고 운영을 재개하는 것이 가능합니다.
Ready for RMAN
Oracle Database 10g RMAN은 한층 향상된 백업 관리 툴로 거듭 태어났습니다. 증분 백업에 관련한 기능 개선만으로도 RMAN은 더 이상 무시할 수 없는 툴이 되었습니다.
Oracle Database 10g RMAN에 대한 보다 자세한 정보는,“Oracle Database Backup and Recovery Basics 10g Release 1 (10.1)” 문서의 Chapter 4을 참고하시기 바랍니다.
제 10 주
감사 기능의 확장
Oracle Database 10g 의 개선된 감사(Audit Trail) 기능을 이용해 매우 상세한 수준의 사용자 접근 기록을 관리하고, 수작업에 의존한 트리거 기반의 감사 작업을 최소화할 수 있습니다.
사용자 Joe가 아래와 같이 테이블 로우에 대한 업데이트를 수행한 경우를 가정해 봅시다.
update SCOTT.EMP set salary = 12000 where empno = 123456;
이 작업이 데이타베이스에는 어떠한 형태의 기록으로 남게 될까요? Oracle9i Database와 그 이전 버전에서는 “누가” 접근했는지에 대한 기록은 남았지만, “어떤” 작업을 했는지에 대해서는 아무런 기록도 남지 않았습니다. 예를 들어, 사용자 Joe가 SCOTT가 소유한 EMP 테이블을 업데이트했다는 사실은 알 수 있지만, 그가 사번 123456을 가진 직원의 salary 컬럼을 업데이트했다는 사실은 알 수 없습니다. 또 salary 컬럼의 변경 전 값 역시 기록되지 않습니다. 이처럼 상세한 변경 내역을 추적하려면, 트리거를 적용하거나 Log Miner를 이용해 아카이브 로그를 뒤지는 수 밖에 없었습니다.
두 가지 방법 모두 변경된 컬럼과 값을 확인할 수는 있지만 이에 수반되는 비용이 만만치 않다는 문제가 따릅니다. 감사 목적으로 적용되는 트리거는 성능적으로 심각한 부담을 줍니다. 이러한 이유 때문에 사용자 정의 트리거의 적용을 아예 금지하는 경우도 많습니다. Log Miner는 성능 자체에는 아무런 영향을 주지 않으나 변경 내역을 추적하기 위해 아카이브 로그에 의존해야 한다는 문제가 있습니다.
Oracle9i에 추가된 Fine-Grained Auditing(FGA) 기능은 로우(row) 단위 변경 내역을 SCN 넘버와 함께 저장함으로써 이전의 데이타를 재구성할 수 있게 하지만, select 구문에 대해서만 적용 가능하고 update, insert, delete 등의 DML 구문에는 적용할 수 없습니다. 이러한 이유로, Oracle Database 10g 이전 버전에서 로우 단위의 데이타 변경 내역을 추적하려면 트리거를 적용하는 것 외에 다른 방법이 없었습니다.
Oracle Database 10g에서는 감사 작업과 관련하여 두 가지 중요한 기능 개선이 이루어졌습니다. 이 문서에서는 오라클이 제공하는 두 종류의 감사 관련 기능 – (모든 버전에서 제공되는) 표준 감사(standard audit) 기능과 (Oracle9i 이후 버전에서 제공되는) fine-grained audit 기능 – 의 관점에서 개선된 사항을 설명하고자 합니다.
새로운 기능들
첫 번째로, FGA는 select 이외의 다른 DML 구문을 지원합니다. 변경 내역은 이전과 마찬가지로 FGA_LOG$에 기록되며, DBA_FGA_AUDIT_TRAIL 뷰를 통해 확인할 수 있습니다. 또 특정 컬럼이 액세스되는 경우, 또는 정의된 일련의 컬럼이 액세스되는 경우에만 트리거가 동작하도록 설정하는 것이 가능합니다 (10g 환경에서의 FGA 기능에 대한 상세 정보를 확인하시려면 필자의 테크니컬 아티클을 확인하시기 바랍니다.)
“AUDIT” SQL 명령으로 구현되는 표준 감사 기능은 특정 오브젝트의 감사를 위한 환경을 쉽고 빠르게 설정하려는 경우 유용합니다. 예를 들어, Scott가 소유자인 EMP 테이블에 대한 모든 업데이트를 추적하려면 아래와 같은 명령을 사용합니다:
audit UPDATE on SCOTT.EMP by access;
위 명령은 SCOTT.EMP 테이블에 업데이트가 발생할 때마다 그 내역을 AUD$ 테이블에 기록합니다. 감사 기록은 DBA_AUDIT_TRAIL 뷰를 통해 조회할 수 있습니다.
이 기능은 10g 이전의 버전에서도 제공되어 오던 것입니다. 하지만 이전 릴리즈에서는 제한적인 정보(구문을 실행한 사용자, 시간, 터미널 ID, 등)만을 추적할 수 있었으며, 바인딩 되는 변수 값과 같은 중요한 정보의 추적이 불가능했습니다. 10g에서는 이전 버전에서 제공되던 것에 추가하여 여러 가지 중요한 정보를 수집할 수 있도록 개선되었습니다. 감사 정보를 저장하는 AUD$ 테이블에도 몇 가지 새로운 컬럼이 추가되었으며, 이전과 마찬가지로 DBA_AUDIT_TRAIL을 통해 확인할 수 있습니다. AUD$ 테이블에 추가된 컬럼에 대해 좀 더 자세히 살펴보기로 합시다.
EXTENDED_TIMESTAMP. 이 컬럼은 감사 기록의 타임스탬프 값을 TIMESTAMP(6) 포맷으로 저장합니다 (TIMESTAMP(6) 포맷은 Time Zone 정보와 함께 그리니치 평균 시간(Universal Coordinated Time으로 불리기도 합니다)을 소수점 이하 9자리 초 단위로 표현합니다). 이 포맷으로 저장된 시간 정보의 예가 아래와 같습니다:
2004-3-13 18.10.13.123456000 -5:0
위 데이타는 미국 동부 표준 시간을 기준으로 한 2004년 3월 13일 시간 정보를 표시하고 있습니다 (-5.0”은 UTC 보다 5시간 이전을 기준으로 함을 의미합니다).
이와 같은 확장형 포맷을 사용함으로써 매우 세밀한 시간 간격으로 감사 기록을 관리할 수 있고, 여러 시간대에 걸쳐 사용되는 데이타베이스 환경에서 한층 유용한 정보를 얻을 수 있습니다.
GLOBAL_UID and PROXY_SESSIONID. 사용자 인증을 위해 Oracle Internet Directory와 같은 아이덴티티 관리 솔루션을 사용하는 경우, 데이타베이스가 사용자를 표시하는 방법도 조금 달라지게 됩니다. 예를 들어, 인증된 사용자가 (데이타베이스 사용자가 아닌) 엔터프라이즈 사용자인 경우를 생각해 봅시다. 이 경우 DBA_AUDIT_TRAIL 뷰의 USERNAME 컬럼에 enterprise userid가 표시되며, 따라서 해당 컬럼의 정보에 일관성이 없게 됩니다. Oracle Database 10g에서는 enterprise userid를 위한 GLOBAL_UID 컬럼을 별도로 제공하며, 이 컬럼을 이용하여 디렉토리 서버에 엔터프라이즈 사용자에 대한 정보를 질의할 수 있습니다.
멀티-티어 애플리케이션 환경에서 엔터프라이즈 사용자가 proxy user를 통해 데이타베이스에 접속하는 경우도 있습니다. 사용자에게 프록시 인증을 제공하는 명령이 아래와 같습니다:
alter user scott grant connect to appuser;
위 명령은 사용자 SCOTT가 APPUSER라는 proxy user를 통해 데이타베이스에 접속할 수 있게 합니다. 이 경우, Oracle 9i는 COMMENT_TEXT에 “PROXY”라는 값을 저장하지만 proxy user의 session id는 저장하지 않습니다. 10g에서는 PROXY_SESSIONID에 proxy session id를 저장합니다.
INSTANCE_NUMBER. Oracle Real Application Clusters (RAC) 환경에서 사용자가 실제로 어느 인스턴스에 연결되어 있는지 확인할 수 있다면 여러모로 도움이 될 것입니다. 10g에서는 INSTANCE_NUMBER 컬럼에 초기화 매개변수 파일에 지정된 해당 인스턴스의 인스턴스 번호를 저장합니다.
OS_PROCESS. Oracle9i와 그 이전 버전에서는 SID 값만을 저장하고 운영체제의 process id는 저장하지 않았습니다. 하지만 서버 프로세스의 OS process id가 Trace파일과 상호참조를 위해 필요한 경우가 있을 수 있습니다. 10g는 이를 위해 OS_PROCESS 컬럼을 제공합니다.
TRANSACTIONID. 이번에는 정말 중요한 정보를 소개할 차례입니다. 사용자가 아래와 같은 쿼리를 실행하는 경우를 가정해 봅시다:
update CLASS set size = 10 where class_id = 123;
commit;
위 명령은 트랜잭션으로서의 조건을 만족하며, 따라서 명령에 대한 감사 기록이 생성됩니다. 그렇다면, 실제로 생성된 감사 기록을 어떻게 확인할 수 있을까요? TRANSACTIONID 컬럼에 저장된 transaction id와 FLASHBACK_TRANSACTION_QUERY 뷰를 조인하면 됩니다. FLASHBACK_TRANSACTION_QUERY 뷰를 조회하는 간단한 예가 다음과 같습니다:
select start_scn, start_timestamp,
commit_scn, commit_timestamp, undo_change#, row_id, undo_sql
from flashback_transaction_query
where xid = '<the transaction id>';
10g에서는 트랜잭션에 관련한 일반적인 정보 이외에도 undo change#와 rowid 등을 추가로 저장합니다. 트랜잭션 변경의 undo를 위한 SQL 쿼리는 UNDO_SQL 컬럼에, 변경된 로우의 rowid 값은 ROW_ID 컬럼에 저장됩니다.
System Change Number. 변경 전의 값을 저장하기 위해서 어떤 방법을 사용하고 계십니까? Oracle9i의 FGA를 이용하는 경우, flashback 쿼리를 통해 변경 전의 값을 알 수 있습니다. 이 작업을 위해서는 변경 작업에 사용된 SCN을 알고 있어야 하며, 이 정보는 감사 기록의 System Change Number 컬럼에 저장됩니다. 아래와 같은 쿼리를 사용하면 변경 전의 값을 확인할 수 있습니다.
select size from class as of SCN 123456
where where class_id = 123;
This will show what the user saw or what the value was prior to the change.
DB 감사 기능의 확장
처음에 우리가 제기했던 문제가 무엇인지 다시 상기해 보겠습니다. 표준 감사(standard auditing)을 통해 캡처되지 않던 정보들인 사용자가 실행한 SQL 구문과 바인드 변수들이 문제였습니다. Oracle Database 10g에서는 초기화 매개변수의 간단한 변경 작업만으로 이러한 목적을 달성할 수 있습니다. 매개변수 파일에 아래 항목을 삽입하면 됩니다.
audit_trail = db_extended
이 매개변수는 SQL텍스트와 컬럼에 사용된 변수 값의 기록을 활성화합니다. 이 기능은 10g 이전 버전에서는 지원되지 않았습니다.
트리거가 필요한 경우
롤백된 결과의 취소. 감사 기록은 원본 트랜잭션으로부터 파생된 autonomous transaction을 통해 생성됩니다. 그렇기 때문에 원본 트랜잭션이 롤백 되는 경우에도 감사 기록은 커밋됩니다.
간단한 예를 들어 설명해 보겠습니다. CLASS 테이블의 UPDATE 작업에 대한 감사를 수행하는 경우를 가정해 봅시다. 사용자가 SIZE 컬럼의 값을 20을 10으로 변경하는 구문을 실행한 뒤 아래와 같이 롤백했습니다:
update class set size = 10 where class_id = 123;
rollback
결국 SIZE 컬럼은 (10이 아닌) 20의 값을 갖게 됩니다. 하지만 감사 기록에는 (롤백이 수행되었음에도) 변경 작업이 수행된 것처럼 기록이 됩니다. 사용자가 롤백을 수행하는 빈도가 높은 경우, 이러한 현상으로 인해 곤란한 문제가 생길 수 있습니다. 이러한 경우라면 커밋된 변경내역만을 캡처하기 위해 트리거를 사용할 수 밖에 없습니다. 즉 사용자 정의된 audit trail에 기록하도록 CLASS테이블에 대한 트리거가 있다면, CLASS 테이블에 대한 변경 작업이 롤백 되는 경우, 설정된 트리거 역시 롤백 됩니다.
변경 전 값의 캡처. 오라클이 제공하는 감사 기록은 변경 이전/이후의 값을 제공하지 않습니다. 예를 들어, 위에서 예로 든 변경 작업에 대한 감사기록은 실행된 구문과 SCN 넘버를 저장하고 있지만 변경 전 값(20)은 저장하지 않습니다. SCN 넘버를 이용한 flashback 쿼리를 통해 이전 값을 확인할 수 있지만, 이것도 해당 정보가 undo 세그먼트에 저장되어 있는 경우에만 가능합니다. 해당 정보가 undo_retention period 설정된 보관 기간을 초과한 경우, 이전 값을 조회할 수 있는 방법은 없습니다. 트리거를 이용하면 undo_retention period의 설정값에 관계없이 변경전 값을 영구적으로 저장할 수 있습니다.
통합 감사 기록
FGA와 표준 감사(standard auditing) 기능은 서로 유사한 형태의 정보를 제공하므로, 이 두 가지를 함께 사용함으로써 매우 다양한 정보를 얻을 수 있습니다. Oracle Database 10g는 두 종류의 정보를 통합한 DBA_COMMON_AUDIT_TRAIL 뷰를 제공합니다. 이 뷰는 DBA_AUDIT_TRAIL 뷰와 DBA_FGA_AUDIT_TRAIL 뷰의 UNION ALL로 구성됩니다. (하지만 두 감사 작업이 제공하는 정보의 성격에 분명한 차이가 있는 것도 사실입니다.)
결론
10g로 오면서, 감사 기능은 단순한 “액션 레코더(action recorder)” 또는 “패스트 리코딩 메커니즘(fast-recording mechanism)”에서 매우 상세한 수준의 사용자 액티비티를 저장하는 수단으로 변화되었으며, 이 기능을 활용하여 수작업으로 수행되던 트리거 기반 감사 작업을 최소화할 수 있습니다. 또 표준 감사(standard auditing)과 FGA의 감사 결과를 통합함으로써, 데이타베이스 액세스에 대한 추적이 한층 용이해졌습니다.
더욱 자세한 정보는, Oracle Database Security Guide 10g Release 1 (10.1) 문서의 제 11 장을 참고하시기 바랍니다.
제 11 주
Wait 인터페이스
10g의 wait 인터페이스는 ADDM에 의해 아직 캡처 되지 않은 현 시점의 성능 문제를 진단하고 해결하기 위한 유용한 정보를 제공합니다.
"데이타베이스가 너무 느리네요!"
성능에 불만을 가진 사용자들은 이렇게 말하곤 합니다. 여러분들도 필자와 같다면, DBA로 근무하면서 이런 이야기를 수없이 들어왔을 것입니다.
그렇다면 성능 문제를 해결하기 위해 어떻게 대처하십니까? 사용자의 불만을 무시하는 방법도 있겠지만(대부분의 DBA에게 이런 사치는 허용되지 않으므로), 데이타베이스 내부 또는 외부에 세션 wait 이벤트가 발생했는지 확인하는 것이 첫 번째로 하는 일이 될 것입니다.
오라클은 이를 위해 단순하면서도 강력한 메커니즘을 제공합니다. V$SESSION_WAIT 뷰가 바로 그것입니다. V$SESSION_WAIT 뷰를 통해 세션이 대기 중인 이벤트가 무엇이고 얼마나 자주, 얼마나 오랫동안 대기했는지 등의 정보를 확인할 수 있습니다. 예를 들어 특정 세션이 “db file sequential read” 이벤트를 대기하고 있는 경우, 컬럼 P1과 P2는 세션이 대기 중인 블록의 file_id와 block_id를 각각 표시하게 됩니다. 대부분의 경우, V$SESSION_WAIT 뷰만으로 wait 이벤트에 관련한 충분한 정보를 확인할 수 있습니다. 하지만 다음과 같은 두 가지 약점이 있습니다:
For most wait events this view is sufficient, but it is hardly a robust tuning tool for at least two important reasons:
V$SESSION_WAIT 뷰는 현 시점의 상태만을 표시합니다. wait 이벤트가 종료되면, 그 히스토리 정보 역시 소실되어 버립니다. 또 V$SESSION_EVENT 뷰는 세션이 시작된 이후의 누적된 정보를 제공하지만 그 정보가 상세하지 않습니다.
V$SESSION_WAIT 뷰는 wait 이벤트에 대한 정보만을 포함하고 있습니다. 그 밖의 다른 정보(userid, terminal 등)를 확인하려면 V$SESSION 뷰와 조인해야 합니다.
Oracle Database 10g는 최소한의 작업으로 보다 많은 정보를 얻을 수 있도록 wait 인터페이스를 혁신적으로 개선하였습니다. 이번 연재에서는, wait 인터페이스와 관련하여 Oracle Database 10g가 제공하는 새로운 기능을 소개하고 성능 문제 해결을 위한 활용 방안을 설명합니다. 대부분의 경우 ADDM(Automatic Database Diagnostic Manager)이 성능 분석 툴로 활용되겠지만, ADDM에 의해 아직 수집되지 않은 현 시점의 성능 문제를 분석하는 데에는 wait 인터페이스가 유용합니다.
Session Wait 뷰의 기능 향상
먼저 V$SESSION_WAIT의 개선된 기능에 대해 예를 통해 설명하도록 하겠습니다.
사용자의 세션이 갑자기 느려졌다는 불만이 제기된 경우를 가정해 봅시다. 먼저 사용자 세션의 SID를 확인하고, 해당 SID에 대해 V$SESSION_WAIT 뷰를 조회합니다. 그 결과가 아래와 같습니다:
SID : 269
SEQ# : 56
EVENT : enq: TX - row lock contention
P1TEXT : name|mode
P1 : 1415053318
P1RAW : 54580006
P2TEXT : usn<<16 | slot
P2 : 327681
P2RAW : 00050001
P3TEXT : sequence
P3 : 43
P3RAW : 0000002B
WAIT_CLASS_ID : 4217450380
WAIT_CLASS# : 1
WAIT_CLASS : Application
WAIT_TIME : -2
SECONDS_IN_WAIT : 0
STATE : WAITED UNKNOWN TIME
굵은 글씨체로 표시된 컬럼을 주목하시기 바랍니다. WAIT_CLASS_ID, WAIT_CLASS#, WAIT_CLASS 등은 모두 10g에서 새로 추가된 컬럼들입니다. WAIT_CLASS는 wait의 유형을 구분해 주는 컬럼으로, idle한 wait이므로 무시해도 되는지 또는 유효한 wait인지를 판단하는 중요한 기준으로 활용됩니다. 위의 예에서는 wait class가 “Application”으로 표시되고 있으며, 따라서 주목할 만한 이유가 충분한 것으로 판단할 수 있습니다.
이러한 컬럼들은 튜닝 과정에서 매우 요긴하게 활용됩니다. 예를 들어 다음과 같은 쿼리를 작성하여 세션 wait에 관련한 정보를 얻을 수 있습니다.
select wait_class, event, sid, state, wait_time, seconds_in_wait
from v$session_wait
order by wait_class, event, sid
/
쿼리 실행 결과의 예가 다음과 같습니다:
WAIT_CLASS EVENT SID STATE WAIT_TIME SECONDS_IN_WAIT
---------- -------------------- ---------- ------------------- ---------- ---------------
Application enq: TX - 269 WAITING 0 73
row lock contention
Idle Queue Monitor Wait 270 WAITING 0 40
Idle SQL*Net message from client 265 WAITING 0 73
Idle jobq slave wait 259 WAITING 0 8485
Idle pmon timer 280 WAITING 0 73
Idle rdbms ipc message 267 WAITING 0 184770
Idle wakeup time manager 268 WAITING 0 40
Network SQL*Net message to client 272 WAITED SHORT TIME -1 0
여기 몇 가지 이벤트(Queue Monitor Wait, JobQueue Slave등)가 “Idle” 이벤트로 표시되고 있음을 확인할 수 있습니다. 이러한 항목들은 nonblocking wait로 간주하고 고려 대상에서 제외할 수도 있습니다. 하지만 “idle” 이벤트가 다른 문제를 암시하는 경우도 있습니다. 예를 들어, “idle”로 표시되는 SQL*Net 관련 이벤트는 네트워크 지연율이 높음을 나타낼 수도 있습니다.
WAIT_TIME이 -2의 값을 갖는 경우도 참고할 필요가 있습니다. Windows와 같은 일부 플랫폼은 fast timing mechanism을 지원하지 않습니다. 해당 플랫폼에 초기화 매개변수 TIMED_STATISTICS 가 설정되어 있지 않은 경우, 정확한 시간 통계를 얻을 수 없습니다. 이 경우 Oracle9i에서는 관련된 컬럼에 비정상적으로 높은 숫자가 표시되며, 이로 인해 성능 문제의 진단이 더욱 어려워질 수 있습니다. 10g에서는 이러한 경우 일률적으로 -2의 값을 표시합니다. 즉, -2는 플랫폼이 fast timing mechanism을 지원하지 않으며 TIMED_STATISTICS 매개변수가 설정되어 있지 않음을 의미합니다. (이 문서의 뒷부분에서는 fast timing mechanism이 사용 가능한 것으로 가정하고 설명을 진행합니다.)
Session 뷰와 Session Wait 뷰의 통합
세션에 대한 자세한 정보를 얻기 위해서 V$SESSION_WAIT를 V$SESSION과 조인해야만 했던 사실을 기억하고 계실 겁니다. 10g에서는 V$SESSION 뷰 안에 V$SESSION_WAIT의 정보가 기본적으로 포함됩니다. V$SESSION이 wait 이벤트에 관련하여 추가로 제공하는 컬럼이 아래와 같습니다:
EVENT# NUMBER
EVENT VARCHAR2(64)
P1TEXT VARCHAR2(64)
P1 NUMBER
P1RAW RAW(4)
P2TEXT VARCHAR2(64)
P2 NUMBER
P2RAW RAW(4)
P3TEXT VARCHAR2(64)
P3 NUMBER
P3RAW RAW(4)
WAIT_CLASS_ID NUMBER
WAIT_CLASS# NUMBER
WAIT_CLASS VARCHAR2(64)
WAIT_TIME NUMBER
SECONDS_IN_WAIT NUMBER
STATE VARCHAR2(19)
이 컬럼들은 V$SESSION_WAIT에서 제공되는 것들과 동일한 이름을 가지며 동일한 정보를 제공합니다. 결국 이벤트에 대한 세션 wait 정보를 확인하기 위해 V$SESSION_WAIT를 따로 조회할 필요가 없게 된 것입니다.
그럼 다시 처음에 설명한 예로 돌아가 봅시다. SID 269의 세션이 “enq: TX - row lock contention”이벤트를 대기 중이며, 이는 이 세션이 다른 세션이 점유하고 있는 락(lock)을 대기 중임을 의미합니다. 문제를 진단하기 위해서는 “다른” 세션이 무엇인지 확인해야 합니다. 그렇다면 어떤 방법을 써야 할까요?
Oracle9i와 이전 버전에서는 매우 복잡한 쿼리를 실행해야만 락을 소유한 세션의 SID를 알아낼 수 있었습니다. 10g에서는 다음과 같은 간단한 쿼리로 해결 가능합니다:
select BLOCKING_SESSION_STATUS, BLOCKING_SESSION
from v$session
where sid = 269
BLOCKING_SE BLOCKING_SESSION
----------- ----------------
VALID 265
이렇게 간단한 작업만으로 SID 265 세션이 세션 269를 블로킹하고 있음이 확인되었습니다.
얼마나 많은 Wait가 발생했는가?
아직도 사용자를 만족시키기에는 이릅니다. 사용자의 세션이 느려진 이유는 도대체 무엇일까요? 다음과 같은 쿼리를 먼저 실행해 봅시다:
select * from v$session_wait_class where sid = 269;
결과는 다음과 같이 표시됩니다:
SID SERIAL# WAIT_CLASS_ID WAIT_CLASS# WAIT_CLASS TOTAL_WAITS TIME_WAITED
---- ------- ------------- ----------- ------------- ----------- -----------
269 1106 4217450380 1 Application 873 261537
269 1106 3290255840 2 Configuration 4 4
269 1106 3386400367 5 Commit 1 0
269 1106 2723168908 6 Idle 15 148408
269 1106 2000153315 7 Network 15 0
269 1106 1740759767 8 User I/O 26 1
위 결과는 세션 wait에 대한 매우 상세한 정보를 제공하고 있습니다. 위 결과를 통해 애플리케이션에 관련한 세션 wait 이벤트가 873회, 총 261,537 centi-second에 걸쳐 발생되었으며, 네트워크 관련한 wait 이벤트가 15회 발생되었음을 확인할 수 있습니다.
이 방법을 응용하여, wait class에 관련한 시스템의 전반적인 통계를 확인할 수도 있습니다. (여기에서도 시간은 centi-second 단위로 표시됩니다.)
select * from v$system_wait_class;
WAIT_CLASS_ID WAIT_CLASS# WAIT_CLASS TOTAL_WAITS TIME_WAITED
------------- ----------- ------------- ----------- -----------
1893977003 0 Other 2483 18108
4217450380 1 Application 1352 386101
3290255840 2 Configuration 82 230
3875070507 4 Concurrency 80 395
3386400367 5 Commit 2625 1925
2723168908 6 Idle 645527 219397953
2000153315 7 Network 2125 2
1740759767 8 User I/O 5085 3006
4108307767 9 System I/O 127979 18623
대부분의 성능 문제는 독립적으로 존재하지 않으며, 문제의 패턴을 암시하는 단서로서 해석되는 것이 일반적입니다. 이러한 패턴을 확인하려면 wait class의 히스토리 뷰를 조회해야 합니다:
select * from v$waitclassmetric;
V$WAITCLASSMETRIC 뷰는 지난 1분 동안의 wait class 통계를 제공합니다.
select wait_class#, wait_class_id,
average_waiter_count "awc", dbtime_in_wait,
time_waited, wait_count
from v$waitclassmetric
/
WAIT_CLASS# WAIT_CLASS_ID AWC DBTIME_IN_WAIT TIME_WAITED WAIT_COUNT
----------- ------------- ---- -------------- ----------- ----------
0 1893977003 0 0 0 1
1 4217450380 2 90 1499 5
2 3290255840 0 0 4 3
3 4166625743 0 0 0 0
4 3875070507 0 0 0 1
5 3386400367 0 0 0 0
6 2723168908 59 0 351541 264
7 2000153315 0 0 0 25
8 1740759767 0 0 0 0
9 4108307767 0 0 8 100
10 2396326234 0 0 0 0
11 3871361733 0 0 0 0
WAIT_CLASS_ID 컬럼을 주목하시기 바랍니다. 지난 1분 동안 4217450380의 WAIT_CLASS_ID 값을 갖는 wait class를 2개의 세션이 총 5회, 1,499 centi-second에 걸쳐 대기하였음을 알 수 있습니다. 그렇다면 이 wait class는 무엇일까요? V$SYSTEM_WAIT_CLASS를 조회하면 이 wait class가 바로 "Application” class임을 확인할 수 있습니다.
DBTIME_IN_WAIT 컬럼도 매우 유용하게 활용됩니다. Automatic Workload Repository(AWR)를 주제로 한 제 6 주 연재에서, 10g가 한층 세분화된 시간 통계를 제공하며, 데이타베이스 내부에서 실제로 사용된 시간을 정확하게 확인할 수 있음을 설명한 바 있습니다. DBTIME_IN_WAIT가 바로 데이타베이스 내부에서 사용된 시간을 표시하는 컬럼입니다.
단서는 항상 남는다
해당 사용자의 세션이 종료되자 DBA는 안도의 한숨을 내쉽니다. 하지만 도대체 어떤 wait 때문에 세션에 성능 문제가 발생했는지에 대한 궁금증이 가시지 않습니다. V$SESSION_WAIT를 조회하면 쉽게 해답을 얻을 수 있겠지만, 이제 wait 이벤트가 종료된 상황이므로 이 뷰에는 더 이상 기록이 남아있지 않을 것입니다. 이런 경우 어떻게 하시겠습니까?
10g는 액티브 세션의 마지막 10개 이벤트에 관련한 session wait 히스토리 정보를 자동 저장하고 관리하며, 이 결과는 V$SESSION_WAIT_HISTORY 뷰를 통해 조회할 수 있습니다:
select event, wait_time, wait_count
from v$session_wait_history
where sid = 265
/
EVENT WAIT_TIME WAIT_COUNT
------------------------------ ---------- ----------
log file switch completion 2 1
log file switch completion 1 1
log file switch completion 0 1
SQL*Net message from client 49852 1
SQL*Net message to client 0 1
enq: TX - row lock contention 28 1
SQL*Net message from client 131 1
SQL*Net message to client 0 1
log file sync 2 1
log buffer space 1 1
세션이 inactive 상태가 되거나 연결이 끊어진 경우, 관련된 기록도 뷰에서 삭제됩니다. 하지만 히스토리 정보는 AWR 테이블에 별도로 저장됩니다. AWR의 V$ACTIVE_SESSION_HISTORY 뷰는 session wait에 관련한 정보를 제공합니다. (AWR에 관련한 자세한 정보는 본 시리즈의 제 6 주 연재를 참고하시기 바랍니다.)
결론
Oracle Database 10g의 향상된 wait 모델을 사용하여 한층 쉽게 성능 분석 작업을 진행할 수 있습니다. 세션 히스토리 정보를 이용하면 문제의 징후가 사라진 이후에도 문제 원인을 진단할 수 있습니다. 또 wait를 wait class로 구분함으로써, 각 wait 유형별 영향을 이해하고 효율적으로 대처할 수 있게 됩니다.
wait 이벤트 관련 다이내믹 성능 뷰에 대한 보다 자세한 정보는 Oracle Database Performance Tuning Guide 10g Release 1 (10.1)의 제 10 장을 확인하시기 바랍니다.
제 12 주
Materialized Views
10g에서는 강제적인 query rewrite, tuning advisor 등의 새로운 기능을 통해 materialized view의 관리 기능을 향상시켰습니다.
스냅샷(snapshot)이라 불리기도 하는 Materialized view(MV)는 오라클에서 오래 전부터 구현해 온 기능의 하나입니다. MV는 쿼리 결과를 별도 세그먼트에 저장하고, 쿼리가 재실행되는 경우 사용자에게 미리 저장된 결과를 전달함으로써 쿼리를 여러 차례 재실행하는 데 따르는 성능적인 부담을 줄여줍니다. MV는 데이타 웨어하우스 환경에서 특히 유용합니다. 또 “fast refresh” 메커니즘을 이용해 MV를 전체적으로 또는 부분적으로 refresh할 수 있습니다.
다음과 같은 materialized view를 구현한 경우를 가정해 봅시다:
create materialized view mv_hotel_resv
refresh fast
enable query rewrite
as
select distinct city, resv_id, cust_name
from hotels h, reservations r
where r.hotel_id = h.hotel_id';
어떻게 하면 이 MV가 완벽하게 동작하는데 필요한 오브젝트들이 모두 생성되었는지 확인할 수 있을까요? Oracle Database 10g 이전 버전에서는, DBMS_MVIEW 패키지의 EXPLAIN_MVIEW 프로시저와 EXPLAIN_REWRITE 프로시저를 이용해 이를 확인할 수 있었습니다. 이 프로시저들은 10g에서도 여전히 사용 가능합니다. 이 프로시저들을 이용하면 특정 MV에 “fast refreshability”, “query rewritability” 등의 기능 구현 여부를 정확하게 확인할 수 있었지만, 어떻게 하면 이러한 기능을 구현할 수 있는지에 대한 조언을 구할 수는 없었습니다. 이를 위해서는, 각각의 MV 구조를 비주얼한 방법으로 확인해야만 했으며, 실질적으로 이 방법은 효용성이 없었습니다.
10g에서는 새로 추가된 DBMS_ADVISOR 패키지에 포함된 TUNE_MVIEW 프로시저를 통해 이러한 작업을 간단하게 수행할 수 있습니다. 먼저 IN 매개변수에 MV 생성 스크립트의 텍스트를 저장한 후 패키지를 호출합니다. 프로시저는 자동 생성된 이름을 가진 Advisor Task를 생성하며, OUT 매개변수를 통해 사용자에게 생성된 Advisor의 이름을 반환합니다.
예를 들어 설명해 보겠습니다. 먼저 SQL*Plus에서 OUT 매개변수에 저장할 변수를 정의해야 합니다.
SQL> -- first define a variable to hold the OUT parameter
SQL> var adv_name varchar2(20)
SQL> begin
2 dbms_advisor.tune_mview
3 (
4 :adv_name,
5 'create materialized view mv_hotel_resv refresh fast enable query rewrite as
select distinct city, resv_id, cust_name from hotels h,
reservations r where r.hotel_id = h.hotel_id');
6* end;
다음에는 adv_name 변수를 조회하여 Advisor의 이름을 확인합니다.
SQL> print adv_name
ADV_NAME
-----------------------
TASK_117
다음으로, DBA_TUNE_MVIEW 뷰를 질의하여 Advisor가 제공하는 권고내역을 확인합니다. 이 명령을 실행하기 전에 SET LONG 999999 명령을 실행하는 것을 잊지 마시기 바랍니다. (DBA_TUNE_MVIEW 뷰의 STATEMENT 컬럼은 CLOB 데이타타입을 사용하므로, 문자 출력을 80개로 제한하는 디폴트 환경을 수정해야 합니다.)
select script_type, statement
from dba_tune_mview
where task_name = 'TASK_117'
order by script_type, action_id;
실행 결과는 아래와 같습니다:
SCRIPT_TYPE STATEMENT
-------------- ------------------------------------------------------------
IMPLEMENTATION CREATE MATERIALIZED VIEW LOG ON "ARUP"."HOTELS" WITH ROWID,
SEQUENCE ("HOTEL_ID","CITY") INCLUDING NEW VALUES
IMPLEMENTATION ALTER MATERIALIZED VIEW LOG FORCE ON "ARUP"."HOTELS" ADD
ROWID, SEQUENCE ("HOTEL_ID","CITY") INCLUDING NEW VALUES
IMPLEMENTATION CREATE MATERIALIZED VIEW LOG ON "ARUP"."RESERVATIONS" WITH
ROWID, SEQUENCE ("RESV_ID","HOTEL_ID","CUST_NAME")
INCLUDING NEW VALUES
IMPLEMENTATION ALTER MATERIALIZED VIEW LOG FORCE ON "ARUP"."RESERVATIONS"
ADD ROWID, SEQUENCE ("RESV_ID","HOTEL_ID","CUST_NAME")
INCLUDING NEW VALUES
IMPLEMENTATION CREATE MATERIALIZED VIEW ARUP.MV_HOTEL_RESV REFRESH FAST
WITH ROWID ENABLE QUERY REWRITE AS SELECT
ARUP.RESERVATIONS.CUST_NAME C1, ARUP.RESERVATIONS.RESV_ID
C2, ARUP.HOTELS.CITY C3, COUNT(*) M1 FROM ARUP.RESERVATIONS,
ARUP.HOTELS WHERE ARUP.HOTELS.HOTEL_ID =
ARUP.RESERVATIONS.HOTEL_ID GROUP BY
ARUP.RESERVATIONS.CUST_NAME, ARUP.RESERVATIONS.RESV_ID,
ARUP.HOTELS.CITY
UNDO DROP MATERIALIZED VIEW ARUP.MV_HOTEL_RESV
SCRIPT_TYPE 컬럼은 제공되는 조언의 유형을 의미합니다. 대부분의 내용이 실제 구현에 관련된 권고사항으로 구성되어 있으므로 SCRIPT_TYPE으로 “IMPLEMENTATION”이 설정된 것을 확인할 수 있습니다. 사용자가 승인하는 경우, 제시된 권고사항은 ACTION_ID 컬럼에 정의된 순서대로 실행됩니다.
Advisor가 제시한 권고사항을 자세히 살펴보면, 우리가 비주얼 분석 작업을 통해 생성하는 것과 유사한 내용으로 구성되어 있다는 사실을 알 수 있을 것입니다. 위에서 제시된 권고사항은 매우 논리적입니다. Fast refresh를 구현하려면 베이스 테이블MATERIALIZED VIEW LOG가 생성되어야 하며, 이 때 “including new values”와 같은 조건을 포함하여야 합니다. STATEMENT 컬럼은 이러한 권고사항을 구현하기 위해 실행되는 SQL 구문을 담고 있습니다.
구현 작업의 마지막 단계로서, Advisor는 MV 생성 과정에서 수정이 필요한 부분을 지적해 줍니다. 위의 예에서 무엇이 달라졌는지 확인해 보시기 바랍니다. count(*)가 MV에 추가되었습니다. MV가 “fast refresh”를 지원하는 것으로 설정했기 때문에 count(*)가 반드시 포함되어야 하며, Advisor는 이 부분이 생략된 것을 발견하고 권고사항에 포함시킨 것입니다.
프로시저 TUNE_MVIEW 는 EXPLAIN_MVIEW 와 EXPLAIN_REWRITE가 제공하는 것보다 수준 높은 조언을 제공하며, MV를 생성하는 보다 쉽고 효율적인 방법도 함께 제시합니다. 때로 Advisor는 질의를 보다 효율적으로 하기 위한 방법으로 하나 이상의 MV를 제안하기도 합니다.
어떤 분은 그게 과연 얼마나 유용할까라고 의문을 던질 수도 있을 것입니다. 숙련된 DBA라면 누구나 MV 생성 스크립트에서 빠진 부분을 찾아내어 직접 수정할 수 있기 때문입니다. 사실 Advisor가 하는 역할이 바로 이것입니다. Advisor는 마치 숙련된 DBA처럼 전문적인 권고를 제시합니다. 한 가지 분명하게 다른 점은, Advisor가 돈을 안받고 일할 뿐 아니라 휴가나 월급인상을 요구하지도 않는다는 사실입니다. 이러한 기능이 있음으로 해서, 선임 DBA가 하급 DBA에게 반복적인 업무를 인계하고 보다 전략적인 목표에 집중할 수 있게 되는 것입니다.
TUNE_MVIEW 프로시저를 실행할 때 Advisor name을 미리 지정해서 매개변수를 통해 전달할 수도 있습니다. 이렇게 하는 경우 Advisor는 자동 생성된 이름 대신 사용자가 지정한 이름을 사용합니다.
쉬워진 구현 작업
이제 권고사항을 확인하고 바로 구현 작업에 들어갈 준비가 되었습니다. 위 실행결과의 STATEMENT 컬럼을 조회한 결과를 별도 스크립트 파일에 스풀링한 다음, 그 파일을 실행하는 것도 한 방법입니다. 아니면 그보다 쉬운 방법으로 별도 제공되는 프로시저를 실행할 수도 있습니다:
begin
dbms_advisor.create_file (
dbms_advisor.get_task_script ('TASK_117'),
'MVTUNE_OUTDIR',
'mvtune_script.sql'
);
end;
/
이 프로시저는 아래와 같은 방법으로 디렉토리 오브젝트가 미리 생성되어 있음을 가정합니다:
create directory mvtune_outdir as '/home/oracle/mvtune_outdir';
dbms_advisor를 호출하면 /home/oracle/mvtune_outdir 디렉토리에 mvtune_script.sql이라는 이름의 파일이 생성됩니다. 이 파일을 열어 보면 다음과 같은 내용이 포함되어 있음을 확인할 수 있을 것입니다:
Rem SQL Access Advisor: Version 10.1.0.1 - Production
Rem
Rem Username: ARUP
Rem Task: TASK_117
Rem Execution date:
Rem
set feedback 1
set linesize 80
set trimspool on
set tab off
set pagesize 60
whenever sqlerror CONTINUE
CREATE MATERIALIZED VIEW LOG ON
"ARUP"."HOTELS"
WITH ROWID, SEQUENCE("HOTEL_ID","CITY")
INCLUDING NEW VALUES;
ALTER MATERIALIZED VIEW LOG FORCE ON
"ARUP"."HOTELS"
ADD ROWID, SEQUENCE("HOTEL_ID","CITY")
INCLUDING NEW VALUES;
CREATE MATERIALIZED VIEW LOG ON
"ARUP"."RESERVATIONS"
WITH ROWID, SEQUENCE("RESV_ID","HOTEL_ID","CUST_NAME")
INCLUDING NEW VALUES;
ALTER MATERIALIZED VIEW LOG FORCE ON
"ARUP"."RESERVATIONS"
ADD ROWID, SEQUENCE("RESV_ID","HOTEL_ID","CUST_NAME")
INCLUDING NEW VALUES;
CREATE MATERIALIZED VIEW ARUP.MV_HOTEL_RESV
REFRESH FAST WITH ROWID
ENABLE QUERY REWRITE
AS SELECT ARUP.RESERVATIONS.CUST_NAME C1, ARUP.RESERVATIONS.RESV_ID C2, ARUP.HOTELS.CITY
C3, COUNT(*) M1 FROM ARUP.RESERVATIONS, ARUP.HOTELS WHERE ARUP.HOTELS.HOTEL_ID
= ARUP.RESERVATIONS.HOTEL_ID GROUP BY ARUP.RESERVATIONS.CUST_NAME, ARUP.RESERVATIONS.RESV_ID,
ARUP.HOTELS.CITY;
whenever sqlerror EXIT SQL.SQLCODE
begin
dbms_advisor.mark_recommendation('TASK_117',1,'IMPLEMENTED');
end;
/
이 파일은 권고사항을 구현하기 위해 필요한 모든 정보를 포함하고 있으며, 수작업으로 파일을 생성하는 수고를 덜어줍니다. DBA 로봇이 다시 한 번 그 위력을 발휘하는 순간입니다.
Rewrite이 불가능한 경우의 실행 차단
이제 여러분들도 Query Rewrite 기능이 얼마나 중요하고 유용한지 깨닫게 되셨으리라 믿습니다. Query Rewrite는 I/O 작업과 프로세싱 작업을 줄여주고 결과를 한층 빠르게 얻을 수 있게 합니다.
위의 예를 기준으로 계속 설명해 보겠습니다. 사용자가 다음과 같은 쿼리를 실행하는 경우를 생각해 봅시다:
Select city, sum(actual_rate)
from hotels h, reservations r, trans t
where t.resv_id = r.resv_id
and h.hotel_id = r.hotel_id
group by city;
실행 통계는 아래와 같이 확인되었습니다:
0 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
478 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
consistent gets가 6의 값을 갖는 것에 주목하시기 바랍니다. 이것은 매우 낮은 수치입니다. 이는 3 개의 테이블을 기반으로 생성된 2개의 MV를 이용하도록 쿼리가 재작성 되었기 때문에 얻어진 결과입니다. Select 작업은 테이블이 아닌 MV를 통해 수행되었으며, 그 덕분에 훨씬 적은 I/O와 CPU를 사용했습니다.
하지만 Query Rewrite가 실패하면 어떻게 될까요? 실패의 이유에는 여러 가지가 있을 수 있습니다. 초기화 매개변수 query_rewrite_integrity이 “TRUSTED”로 설정되고 MV status가 “STALE”로 설정되었다면 쿼리는 재작성 되지 않을 것입니다. 쿼리를 실행하기 전에 세션 매개변수를 설정함으로써 이 현상을 테스트해 볼 수 있습니다:
alter session set query_rewrite_enabled = false;
위 명령을 실행하고 나면, explain plan은 MV가 아닌 3개 테이블로부터 select를 수행하는 것으로 변경됩니다. 실행 통계도 아래와 같이 달라지게 됩니다:
0 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
478 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
consistent gets의 값이 6에서 16으로 크게 증가했음을 확인할 수 있습니다. 추가 자원을 활용하기 어려운 실제 환경에서는, 이러한 변화를 용납하기는 어려우며, 따라서 쿼리를 재작성 하는 방법을 선택할 수 밖에 없습니다. 이러한 경우 쿼리가 재작성 되는 경우에만 실행 가능하도록 설정해야 할 수도 있습니다.
Oracle9i Database와 그 이전 버전에서는 단 한 가지 옵션만 가능했습니다. Query Rewrite를
disable할 수는 있었지만 베이스 테이블에 대한 액세스는 막을 수 없었습니다. 반면 Oracle Database 10g는 REWRITE_OR_ERROR라는 힌트를 이용하여 베이스 테이블에 대한 접근을 차단하는 기능을 제공합니다. 위의 쿼리는 아래와 같은 형태로 재작성될 수 있습니다:
select /*+ REWRITE_OR_ERROR */ city, sum(actual_rate)
from hotels h, reservations r, trans t
where t.resv_id = r.resv_id
and h.hotel_id = r.hotel_id
group by city;
에러 메시지는 아래와 같이 표시됩니다:
from hotels h, reservations r, trans t
*
ERROR at line 2:
ORA-30393: a query block in the statement did not rewrite
ORA-30393은 구문이 MV를 사용할 수 있는 형태로 재작성될 수 없으며, 이로 인해 구문 실행에 실패하였음을 의미하는 에러입니다. 이 방법을 사용하여 시스템 리소스를 많이 잡아먹는 쿼리를 사전에 차단할 수 있습니다. 다만 한 가지 주의할 점은, MV 중 (전체가 아닌) 하나만이라도 이용이 가능한 경우 쿼리가 실행된다는 사실입니다. 예를 들어 MV_ACTUAL_SALES은 사용할 수 있지만 MV_HOTEL_RESV는 사용할 수 없는 경우라 해도, 쿼리는 재작성되고 실행되며, 에러는 발생하지 않습니다. 이 경우 execution plan은 아래와 같습니다:
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=11 Card=6 Bytes=156)
1 0 SORT (GROUP BY) (Cost=11 Card=6 Bytes=156)
2 1 HASH JOIN (Cost=10 Card=80 Bytes=2080)
3 2 MERGE JOIN (Cost=6 Card=80 Bytes=1520)
4 3 TABLE ACCESS (BY INDEX ROWID) OF 'HOTELS' (TABLE) (Cost=2 Card=8 Bytes=104)
5 4 INDEX (FULL SCAN) OF 'PK_HOTELS' (INDEX (UNIQUE)) (Cost=1 Card=8)
6 3 SORT (JOIN) (Cost=4 Card=80 Bytes=480)
7 6 TABLE ACCESS (FULL) OF 'RESERVATIONS' (TABLE) (Cost=3 Card=80 Bytes=480)
8 2 MAT_VIEW REWRITE ACCESS (FULL) OF 'MV_ACTUAL_SALES' (MAT_VIEW REWRITE) (Cost=3 Card=80 Bytes=560)
이 쿼리는 MV_ACTUAL_SALES은 사용하지만 MV_HOTEL_RESV는 사용하지 않고, 대신 HOTELS 테이블과 RESERVATIONS 테이블에 직접 액세스합니다. 만일 HOTELS 또는 RESERVATIONS 테이블에 풀 테이블 스캔이 발생한다면, MV를 사용하는 경우보다 훨씬 많은 리소스를 사용하게 될 것입니다. 쿼리와 MV를 설계하는 과정에서 반드시 참고해야 할 부분입니다.
물론 Resource Manager를 이용하면 리소스 사용을 통제할 수도 있습니다. 하지만 REWRITE_OR_ERROR 힌트를 이용하면 Resource Manager가 호출되기도 전에 쿼리의 실행을 사전 차단하는 것이 가능합니다. Resource Manager는 옵티마이저 통계에 근거하여 필요한 리소스를 예측하며, 통계가 존재하지 않거나 그 정확도가 떨어지는 경우 잘못된 예측을 할 수도 있습니다. 반면 REWRITE_OR_ERROR 힌트를 이용하면 통계와 무관하게 테이블 액세스를 차단할 수 있다는 장점이 있습니다.
Explain Plan의 개선 기능
앞의 explain plan 조회결과 예에서 아래 행을 참고하시기 바랍니다:
MAT_VIEW REWRITE ACCESS (FULL) OF 'MV_ACTUAL_SALES' (MAT_VIEW REWRITE)
MAT_VIEW REWRITE 액세스 방식은 10g에서 처음 소개되는 것입니다. 이것은 테이블 또는 세그먼트가 아닌 MV가 액세스되고 있음을 의미합니다. 이 프로시저를 사용하면 테이블과 MV 중 어느 쪽이 사용되고 있는지를 바로 확인할 수 있습니다.
결론
10g에 새로 추가된tuning advisor의 강력한 권고 기능을 이용하여 MV를 더 쉽게 관리할 수 있습니다. 필자는 개인적으로, 튜닝 권고내역이 바로 실행 가능한 형태의 완성된 스크립트로 제공된다는 점이 마음에 듭니다. 리소스를 최대한 아껴야 하는 의사결정 시스템에서는, REWRITE_OR_ERROR 힌트를 사용하여 쿼리 재작성이 불가능한 경우 실행 자체를 차단하는 방법이 매우 유용하게 사용될 수 있습니다.
10g에서 MV를 관리하는 방법에 대한 보다 자세한 정보는 Oracle Database Data Warehousing Guide 10g Release 1 (10.1)의 제 8 장을 참고하시기 바랍니다.
제 13 주
Enterprise Manager 10g
마침내, 초심자와 전문가 모두를 위해 Oracle 관리와 운영에 관한 문제를 한꺼번에 해결해 줄 수 있는 툴이 완성되었습니다.
여러분이 일상적인 DBA 업무를 위해 주로 사용하는 툴은 무엇입니까? 사용자 그룹 모임에서 똑같은 질문을 던진 적이 있었습니다.
답변은 DBA의 경력에 따라 달랐습니다. 오랜 경력의 관리자일 수록 SQL*Plus 커맨드 라인 툴을 가장 선호하였고 (필자 역시 그러합니다), 다른 이들의 경우 몇 가지 써드 파티 제품을 중심으로 의견이 갈라졌습니다. 하지만 초심자 수준의 DBA의 경우에는 Enterprise Manager(EM)을 단연 선호하는 툴로 꼽았습니다.
이러한 결과는 충분히 예상할 수 있는 것입니다. Oracle Enterprise Manager는 지난 수 년 동안 꾸준히 발전되어 왔습니다. 처음에 캐릭터 모드 디스플레이의 SQL*DBA로 시작된 EM은 클라이언트 운영체제 기반의 툴로, 그리고 최종적으로는 자바 기반 환경으로 진화되었습니다. EM은 대부분의 DBA 작업을 수행하기에 충분한 수준의 정보를 제공하며, 새로운 문법을 배우기 귀찮아하는 사용자, 또는 GUI 툴을 사용하여 사용자 추가, 데이타파일 수정, 롤백 세그먼트 점검 등의 일상적인 작업을 수행하고자 하는 관리자들을 위한 솔루션으로 자리잡았습니다.
하지만 EM이 기대만큼 빠르게 확산되지 않은 이유 중 하나는, EM이 데이타베이스 서버의 발전속도를 따라잡지 못했다는 사실에 있습니다. 예를 들어 Oracle9i Database의 EM은 (이미 Oracle8i부터 지원되던 기능인) subpartitioning을 지원하지 않았습니다..
Oracle Database 10g에 포함된 EM의 새로운 버전은 과거의 문제로부터의 결별을 선언합니다. 새로운 아키텍처와 새로운 인터페이스가 적용되었으며, 초심자와 숙련된 사용자를 모두 만족할 수 있는 강력하고도 포괄적인 DBA 툴박스를 제공합니다. 더 중요한 사실은, 추가적인 비용 없이 데이타베이스와 함께 기본으로 제공된다는 것입니다. 만일 지금 써드 파티 툴을 검토하고 있는 중이라면, 그 경쟁 제품으로서 EM을 심각하게 고려해 볼 필요가 있습니다. 여러분이 (필자처럼) 커맨드 라인 툴의 맹신자라 하더라도, EM이 여러 상황에서 매우 유용하게 사용될 수 있음을 깨닫게 될 것입니다.
이번 연재에서는 EM의 새로운 기능을 소개합니다. Enterprise Manager가 제공하는 기능의 영역이 워낙 광범위하기 때문에 전체 기능을 종합적으로 다루기는 불가능합니다. 대신, 몇 가지 기본적인 내용을 설명하고 관련 자료를 소개하는 한편, (이 시리즈의 기본 취지에 맞추어) 현실적인 문제를 해결하기 위해 툴을 활용하는 사례들을 제공하고자 합니다.
아키텍처
EM 10g는 Database 10g 소프트웨어와 함께 디폴트로 설치됩니다. 클라이언트 운영체제를 기반으로 하던 이전 버전과 달리, 새로운 버전은 (DB Console이라 불리는) HTTP 서버의 형태로 데이타베이스 서버 상에 설치됩니다 (그림 1 참고). EM 인터페이스는 모든 종류의 웹 브라우저를 지원합니다.
그림 1: EM 아키텍처
DB Console의 포트 번호는 $ORACLE_HOME/install/portlist.ini 파일에 정의되어 있습니다. 이 파일의 예가 아래와 같습니다 (포트 번호는 설치 예에 따라 달라질 수 있습니다).
Ultra Search HTTP port number = 5620
iSQL*Plus HTTP port number = 5560
Enterprise Manager Agent Port =
Enterprise Manager Console HTTP Port (starz10) = 5500
Enterprise Manager Agent Port (starz10) = 1830
위 파일에서 데이타베이스 starz10의 Agent가 포트 1830에서, EM 콘솔이 포트 5500에서 리스닝 하고 있음을 확인할 수 있습니다. 아래 URL을 입력하면 EM 로그온 스크린을 호출할 수 있습니다:
http://starz/em/console/logon/logon
로그온 스크린에서는 DBA 사용자로서 로그인이 가능합니다. 이번 예에서는 SYS 사용자로 로그인해 보겠습니다.
메인 데이타베이스 홈 페이지
로그인 후, 메인 데이타베이스의 홈 페이지가 표시됩니다. 홈 페이지의 상단 부분은 데이타베이스의 중요 정보를 요약 형식으로 제공하고 있습니다 (그림 2 참고).
그림 2: 메인 데이타베이스 홈 페이지 (상단)
위 그림에서 참고할 부분에 동그라미 표시를 하고 번호를 매겼습니다. 제일 먼저 “General” (1)이라 표시된 영역을 참고하시기 바랍니다. 이 영역은 데이타베이스에 관련한 가장 기초적인 정보(인스턴스 네임, 데이타베이스 시작 시간 등)를 제공합니다. Oracle Home 항목의 하이퍼링크를 클릭하면 같은 홈을 공유하는 모든 제품과 오라클 데이타베이스가 표시됩니다. Listeners 항목의 하이퍼링크는 하이퍼링크 상에 표시된 리스너를 통해 등록된 모든 데이타베이스와 인스턴스의 정보로 연결됩니다. 그리고 마지막으로 호스트 명(starz)이 표시됩니다.
"Host CPU" (2) 항목에서는 CPU 관련 정보가 간략하게 제공됩니다. "Active Sessions" (3) 항목은 액티브 세션 통계와 세션의 현재 실행 상태에 대한 정보 (4)를 제공합니다. 위 그림에서는 세션이 사용한 시간 중 99%가 wait에 사용되었음을 확인할 수 있습니다 (그 원인은 뒤에서 확인하기로 합니다). "High Availability" (5) 항목은 가용성에 관련한 정보를 제공합니다. 예를 들어 “Instant Recovery Time”은 인스턴스의 MTTR 목표, 다시 말해 인스턴스 장애 발생 시 복구(instance crash recovery)에 얼마나 많은 시간이 사용될 것인지를 의미합니다.
"Space Usage" (6) 항목을 주목하시기 바랍니다. 이 항목은 23 개의 세그먼트에 대한 경고 메시지가 존재함을 알려주고 있습니다 (경고 메시지의 내용에 대해서는 뒷부분에서 확인하기로 합니다). "Diagnostic Summary" (7)는 데이타베이스의 진단 결과를 요약하고 있습니다. “Performance Finding”의 숫자는, 10g에 새로 추가된 성능 진단 엔진인 ADDM(Automatic Database Diagnostic Monitor)이 발견한 성능 이슈의 수를 의미합니다. 또, EM은 환경을 자동으로 분석하여 베스트 프랙티스를 위반한 사례가 있는지 점검하는 기능을 제공합니다. 분석 작업의 결과는 “Policy Violation”에 표시됩니다. 마지막으로 “Alert Log”는 최근 발생한 ORA error에 대한 정보를 제공합니다. 이 정보는 매우 중요한 가치를 갖습니다. Alert log에 대한 자동 검색을 통해 Oracle 에러를 확인해 줌으로써, 수작업으로 에러 메시지를 찾는 시간을 상당 수준 절감할 수 있습니다.
그림 3은 데이타베이스 홈 페이지의 하단 영역을 보여주고 있습니다. 여기에서는 메시지의 상세한 내용을 확인할 수 있습니다. "Alerts" (1) 항목은 주목할 필요가 있는 알림(alert) 메시지들의 목록을 표시합니다. 제일 첫 번째 메시지(2)는 Archiver 프로세스에 hang이 발생했음을 알려 주고 있습니다. 그 이유를 확인하기 위해 메시지에 연결된 링크를 클릭하면 에러 정보를 담은 alert.log 파일의 상세한 내용이 표시됩니다. 이 경우, flashback recovery area의 공간이 부족한 것이 원인임을 확인되었고, 공간 확보 작업을 거침으로써 Archiver가 다시 정상적으로 동작하게 될 것입니다.
그림 3: 메인 데이타베이스 홈 페이지 (하단)
또 다른 알림 메시지(3)은 wait에 관한 정보를 표시하고 있습니다. 데이타베이스가 69%의 시간을 “Application” wait class에 관련된 wait에 사용하고 있습니다. 홈 페이지의 상단에 있던 wait에 관련한 세션 정보를 기억하십니까? 이 메시지를 통해 그 원인이 확인된 셈입니다. 하이퍼링크를 클릭하면 실제 발생 중인 wait에 대한 상세 정보가 표시됩니다.
다음의 알림 메시지(4)는 감사에 관련된 내용입니다. 사용자 SYS가 특정 클라이언트 머신으로부터 데이타베이스에 접속했습니다. 하이퍼링크를 클릭하면 연결에 관련한 상세 정보를 얻을 수 있습니다. 마지막 메시지(5)는 몇 가지 invalid 오브젝트에 대해 알려주고 있습니다. 하이퍼링크를 클릭하면 invalid 오브젝트에 대한 상세 정보 화면이 표시됩니다.
지금까지 확인한 것처럼, 데이타베이스 홈 페이지는 주목할 필요가 있는 모든 정보를 표시하는 대시보드의 역할을 담당합니다. 세부적인 정보로 화면을 가득 채우는 대신, 인터페이스를 매우 간결한 형태로 정리하고 한 번의 마우스 클릭만으로 상세한 정보를 확인할 수 있도록 배려하였습니다. 이 모든 정보를 직접 수집할 수도 있겠지만 그렇게 하려면 많은 시간과 노력이 필요할 것입니다. EM 10g는 설치 후 별도의 구성 과정을 거치지 않고도 필요한 모든 정보를 제공합니다.
일반적 용례
이번에는 새로운 EM을 활용하여 보다 일상적인 업무를 해결하는 사례에 대해 알아보기로 합시다.
DBA가 수행하는 일상 업무의 하나로 테이블 및 인덱스의 변경을 들 수 있습니다. 데이타베이스 홈 페이지에서 “Administration” 탭을 선택하여 (그림 3의 6번) 클릭합니다. 이 페이지를 통해서 undo segment의 설정, 테이블스페이스 및 스키마 오브젝트의 생성, Resource manager설정, Scheduler의 설정 등의 데이타베이스 관리 작업을 수행할 수 있습니다. “Tables” 탭을 클릭하면 그림 4와 같은 화면이 표시됩니다.
그림 4: 테이블 관리
붉은 원 안에 표시된 플래시 심볼을 주목하시기 바랍니다. 이 심볼은 값의 목록을 불러오기 위해 사용하는 버튼입니다. 화면에서 LOV 심볼을 클릭하면 데이타베이스에 존재하는 사용자의 목록이 표시되어 그 중 하나를 선택할 수 있게 합니다. “Go” 버튼을 클릭하면 해당 사용자를 위한 테이블의 목록이 표시됩니다. 이 과정에서 와일드카드 문자(%)를 사용하는 것도 가능합니다. 예를 들어 “%TRANS%”는 테이블명에 TRANS라는 문자열을 포함하는 모든 테이블을 표시하는 조건으로 사용됩니다.
예를 들어 설명해 보겠습니다. 컬럼의 변경을 위해 TRANS 테이블을 선택합니다 하이퍼링크를 클릭하면 “Edit Table” 스크린이 표시됩니다 (그림 5 참고).
그림 5: 테이블 관리
ACTUAL_RATE 컬럼의 데이타 타입을 NUMBER(10)에서 NUMBER(11)으로 변경하고자 하는 경우, 숫자(그림 5의1번 참고)를 변경한 후 “Apply”를 클릭합니다. 이 작업에 사용되는 SQL 구문을 확인하려면 “Show SQL” 버튼을 클릭합니다.
같은 화면에서 용량의 증가 현황에 관련한 정보를 확인할 수도 있습니다. 나중에 세그먼트 관리에 관한 연재에서 자세히 설명하겠지만, 일정 기간 동안 오브젝트 크기가 증가한 추이를 관찰하는 것이 가능합니다. EM은 같은 정보를 그래픽 형태로 표시합니다. 이 정보를 얻으려면 “Segment” 탭(그림5의 2번 참고))을 클릭합니다. 그러면 그림 6에서 보여지는 것과 같은 Segment 스크린이 표시됩니다.
그림 6: Segment 스크린
붉은 색 원 안에 표시된 항목들을 주목하십시오: 이 화면은 얼마나 많은 공간이 세그먼트에 할당되었고(2), 얼마나 많은 공간이 실제로 사용되고 있으며(1), 얼마나 많은 공간이 낭비되고 있는지(3)를 알려줍니다. 스크린의 하단(4)에는 오브젝트에 할당된 공간과 사용된 공간을 그래픽을 통해 표시하고 있습니다. 이 경우, 테이블의 용량은 일정하게 유지되고 있음을 알 수 있습니다.
그 밖에도 다양한 테이블 관련 작업을 수행할 수 있습니다. 예를 들어 “Constraints” 탭은 제약조건 관리에 활용됩니다.
EM을 이용한 성능 튜닝
지금까지 확인한 것처럼, EM은 룩앤필 면에서 많은 변화를 겪었지만 과거 Java 버전에서 제공되던 기능을 모두 그대로 포함하고 있습니다. 하지만 이전 버전과 분명하게 구분되는 점은, EM이 Oracle Database의 새로운 기능을 모두 지원한다는 사실입니다. (예를 들어 EM을 이용하여 subpartition 기능을 구현할 수 있게 되었습니다.)
하지만 숙련된 DBA라면 툴이 더 많은 기능을 제공할 수 있기를 원할 것입니다. 성능 문제에 관련한 트러블슈팅 및 사전 예방적인 성능튜닝과 같은 경우입니다. 한 가지 예를 들어보겠습니다. 앞부분의 예에서 데이타베이스가 “Application” wait class에 대한 대기에 많은 시간을 소모하고 있음을 확인한 바 있으며 그 원인을 진단하길 원하고 있습니다(그림 3의 3)). 어떠한 튜닝 작업이든 CPU, 디스크, 호스트 서브시스템의 상호 관계를 확인하는 것이 중요하며, 따라서 이러한 모든 변수들을 하나의 맥락으로 파악할 수 있다면 도움이 될 것입니다. 이를 위해 데이타베이스 홈 페이지에서 “Performance” 탭을 클릭합니다. 그림 7에서 보여지는 것과 같은 화면이 뜰 것입니다.
그림 7: Performance 탭
같은 시간대를 기준으로 다양한 성능 지표가 표시되고 있으며, 따라서 다양한 성능 변수의 상호관계를 쉽게 파악할 수 있습니다. 그림 7 (3)번의 급격한 부하 증가 현상은 Scheduler 태스크의 실행 주기와 일치합니다. 또 같은 기간 동안 7개의 세션이 Scheduler 관련 wait를 위해 대기하였음을 알 수 있습니다. 그렇다면 어떤 영향이 있었을까요? 같은 시기의 CPU 성능지표를 확인하시기 바랍니다 (초록색 영역). (4)번의 기준선으로 미루어 CPU의 사용률이 가장 높게 올라간 것을 확인할 수 있습니다. 그 이전과 이후에는 CPU 사용량이 급격하게 증가한 경우가 한 차례도 없었습니다. (1) 번의 Run Queue Length가 증가한 것은 Scheduler가 실행되면서 과도한 메모리를 요구했기 때문으로 보이며, 이로 인해 페이징 작업(2)이 늘어난 것을 알 수 있습니다. 이처럼 모든 현상을 하나의 맥락으로 이해함으로써 데이타베이스 성능 문제를 보다 정확하게 진단할 수 있습니다.
뒷부분의 Run Queue Length(5)와 Paging Rate(6) 곡선은 Physical Reads(7)의 곡선과 일치합니다. 그 원인은 무엇일까요?
위의 결과를 “Sessions: Waiting and Working” 그래프와 비교해 보면, 대부분의 세션이 “Application” wait class를 대기하고 있었음을 알 수 있습니다. 하지만 해당 시간대에 대기 중이었던 이벤트가 무엇이었는지 분명하게 파악할 필요가 있습니다. 해당 시간대의 영역을 클릭하면 그림 8에서 보여지는 것과 같은 Active Sessions 스크린이 표시됩니다.
그림 8: Active Sessions Waits
위 화면을 통해 세션이 enq: TX - row lock contention 이벤트를 대기 중이었음을 알 수 있습니다. 그렇다면 그 원인이 된 SQL 구문은 무엇일까요? 이미 화면에 문제의 SQL 구문에 대한 SQL ID(8rkquk6u9fmd0)가 표시되고 있습니다 (붉은색 원 참고). 해당 SQL ID를 클릭하면 그림 9와 같은 SQL Details 스크린이 표시됩니다.
그림 9: SQL Details 스크린
위 스크린을 통해 SQL 구문과 execution plan을 포함하는 상세 정보를 확인할 수 있습니다. 이 경우 SQL이 row lock contention을 발생시킨 것을 알 수 있으며, 따라서 애플리케이션 설계가 성능 문제의 원인이 된 것으로 결론을 내릴 수 있습니다.
Latch Contention
"Performance" 탭을 클릭한 결과가 아래 그림과 같은 경우를 가정해 봅시다.
그림 10: Performance 탭 (두 번째 예)
그림에서 붉은색 사각형으로 표시된 영역의 성능 지표를 주목하시기 바랍니다. 오전 12시 20분을 전후하여 CPU에 관련한 wait가 많이 발생했고, 이로 인해 CPU의 run queue 사이즈가 증가했음을 알 수 있습니다. 이제 wait 현상의 원인을 분석할 차례입니다.
먼저 그래프의 CPU 경합에 관련된 정보 영역을 클릭하여 (“Click Here”표 표시된 부분 참고) wait에 관련한 상세한 정보를 확인합니다.
그림 11: Active Session Waits
"Active Sessions Working: CPU Used" 그래프의 회색으로 표시된 영역(1)을 참고하시기 바랍니다. 마우스를 드래그하여 해당 영역의 위치를 바꿀 수도 있으며, 이 경우, 아래의 파이 차트(2와 3)는 선택된 시간대를 기준으로 다시 계산됩니다. 위 그림에서 ID 8ggw94h7mvxd7를 갖는 SQL 구문에 많은 부하가 걸리고 있음을 알 수 있습니다(2). 또 사용자 ARUP의 SID 265 세션이 가장 많은 자원을 사용하고 있다는 사실도 확인할 수 있습니다(3). 해당 세션을 클릭하면 “Session Details” 스크린이 표시됩니다. “Wait Events” 탭을 클릭하여 세션에 관련된 wait 이벤트의 상세한 정보를 확인할 수 있습니다 (그림 12 참고).
그림 12: Wait Event 상세 정보
위 그림에서, library cache에 대한 wait가 118 centisecond로 가장 오랜 시간이 걸리고 있음을 확인합니다. “Latch: Library Cache”의 하이퍼링크를 클릭하면 그림 13과 같은 화면이 나타납니다.
그림 13: Wait Histogram
위 화면은 10g 이전 버전에서는 제공되지 않던 정보를 표시하고 있습니다. Latch 경합에 관련된 문제를 진단하면서, 118 centisecond의 대기시간이 여러 세션들의 짧은 wait들이 합산된 결과인지, 아니면 하나의 세션이 오랜 시간을 대기한 결과인지 어떻게 알 수 있을까요?
위의 히스토그램이 그 정보를 제공합니다. 약 250여 개의 세션이 wait에 1 millisecond (첫 번째 붉은색 원 참고)를 사용했으며, 180여 개의 세션이 4~8 millisecond(두 번째 붉은색 원 참고)를 사용했음을 알 수 있습니다. 따라서 매우 짧은 시간의 wait가 원인이 되고 있으며, 따라서 latch 경합이 심각한 수준이 아니라는 결론을 내릴 수 있습니다.
데이타베이스 홈 페이지에서 “Advisor Central” 탭을 클릭하면, ADDM, SQL Access Advisor를 비롯한 각종 Advisor 툴에 접근할 수 있습니다. ADDM은 자동으로 성능지표를 수집하여 Advisor Central 페이지에 그 결과를 표시하며, 각각의 결과를 클릭하면 ADDM이 제시하는 권고안을 확인할 수 있습니다. SQL Tuning Advisor가 제시하는 권고안도 이 페이지에서 확인할 수 있습니다. (ADDM과 SQL Tuning Advisor에 대한 자세한 내용은 향후 연재에서 설명합니다.)
더욱 쉬워진 유지보수 작업
데이타베이스 홈 페이지의 “Maintenance” 탭은 백업 및 복구, 데이타 익스포트/임포트 (Data Pump), 데이타베이스 클로닝 등의 유지보수 작업에 관련한 툴의 정보를 제공합니다. 이 화면에서 유지보수 정책에 위반된 내역을 확인하고 베스트 프랙티스를 구현할 수 있습니다.
결론
이 문서는 EM의 기능 중 극히 일부만을 설명하고 있습니다. 이 문서는 EM의 기능을 전반적으로 설명하기보다, 특정한 업무를 위해 EM을 사용하는 예에 초점을 맞추어 논의를 진행했습니다.
Oracle 10g EM은 초보 DBA가 Oracle Database 관리의 개념을 이해하는데 매우 유용한 툴입니다. EM의 활용에 관련한 테크닉은 "2-Day DBA" reference manual"에 잘 설명되어 있습니다. DBA 업무를 처음 시작하는 관리자라면 반드시 읽어 보실 것을 권합니다.
제 14 주
Virtual Private Database
VPD에 새롭게 추가된 4가지 policy type, 컬럼 단위 policy 적용, column masking 등의 신기능을 활용하여 한층 강력하고 유연한 보안 환경을 구현할 수 있습니다.
Fine Grained Access Control이라는 용어로 불리기도 하는 Virtual Private Database(VPD)는 로우(row) 레벨의 강력한 보안 기능을 제공합니다. VPD는 Oracle8i에서 처음 소개된 이후, 교육용 소프트웨어에서 금융 애플리케이션에 이르기까지 다양한 영역에서 활용되고 있습니다.
VPD는 접수된 데이타 쿼리를 사용자의 권한에 맞도록 테이블의 일부분만을 포함하는 부분적인 뷰에 대한 쿼리로 자동 변경합니다. VPD는 모든 쿼리에 대해 사용자에게 접근 허용된 로우(row)만을 필터링하도록 쿼리 조건을 추가합니다. 예를 들어 사용자가 SCOTT가 account manager로 할당된 account만을 보아야 하는 경우, VPD는 쿼리를 아래와 같이 재작성합니다:
select * from accounts;
to:
select * from accounts
where am_name = 'SCOTT';
DBA가 ACCOUNTS 테이블에 보안 정책을 설정하면, 설정된 정책에는 policy function이라 불리는 함수가 적용됩니다. 이 함수는 “where am_name = 'SCOTT'“와 같은 문자열을 반환하고, 생성된 문자열은 쿼리 조건에 추가되는 predicate으로 활용됩니다. VPD 기능에 대해 친숙하지 않은 경우라면, 오라클 매거진의 기사 "Keeping Information Private with VPD를 참고하실 것을 권장 드립니다."
Policy Types
이처럼 반복적인 파싱을 통해predicate을 생성하는 것은 성능적으로 부담이 될 수 있습니다. 경우에 따라서는 성능 개선을 위한 대안을 고려할 수 있습니다. 대부분의 경우 predicate은 사용자가 누구이고, 그 사용자의 권한이 어디까지이고, 사용자의 상급 관리자가 누구인지 등의 여부에 따라 다이내믹하게 결정됩니다. Policy function에 의해 생성 및 반환되는 문자열은 매우 다이내믹한 성격을 가지며, 따라서 오라클은 정확성을 보장하기 위해서 매번 policy function을 반복적으로 수행합니다. 이는 성능 및 자원사용률 면에서 낭비를 초래할 수 있습니다. 이처럼 predicate이 실행할 때마다 달라지는 경우의 policy를 “dynamic” policy라 부릅니다. Dynamic policy는 Oracle9i 데이타베이스와 그 이전 릴리즈에서 이미 지원되어 왔습니다.
이와 별도로, Oracle Database 10g는 성능 향상을 목적으로 context_sensitive, shared_context_sensitive, shared_static, static 등의 다양한 policy 유형을 추가로 제공합니다: 이제 각 policy 유형의 의미와 활용 방안을 알아 보기로 합시다.
Dynamic Policy. 하위 버전과의 호환성을 유지하기 위한 목적에서, 10g의 디폴트 policy 유형은 “dynamic”으로 설정되어 있습니다. Dynamic policy는 테이블이 액세스 될 때마다 각각의 로우(row) 및 모든 사용자에 대해서 policy function을 실행합니다. Dynamic policy가 predicate를 활용하는 방법에 대해 좀 더 자세히 알아보겠습니다:
where am_name = 'SCOTT'
where 키워드를 제외한다면, predicate은 크게 두 부분으로 나뉘어집니다. 등호 기호의 앞부분(am_name)과 뒷부분(‘SCOTT’)로 나뉘어집니다. 대부분의 경우, 뒷부분에는 사용자 데이타로부터 제공되는 변수와 같습니다. (예를 들어 사용자가 SCOTT라면 값은 ‘SCOTT’가 됩니다.) 등호 기호의 앞부분은 static한 문자열로 이루어지며, 따라서 각 로우(row) 별로 policy function을 반복적으로 수행할 필요가 없습니다. 이처럼 등호 기호의 앞부분과 뒷부분의 static / dynamic 여부를 미리 알고 있다면 부분적으로 성능을 개선하는 것이 가능해집니다. 10g에서는 이를 위해 “context_sensitive” 타입을 지원하며, dbms_rls.add_policy 호출 과정에서 이 타입을 매개변수로 사용할 수 있습니다:
policy_type => dbms_rls.context_sensitive
이번에는 여러 개의 컬럼을 갖는 ACCOUNTS 테이블에 대한 예를 설명하겠습니다. ACCOUNTS 테이블에 포함된 BALANCE 컬럼은 해당 계좌의 잔액을 표시합니다. 특정 사용자가 application context에 의해 정의된 액수 이하의 잔액을 갖는 계좌들을 조회할 수 있도록 허용되었다고 가정해 봅시다. 하드 코딩을 통해 계좌 잔액의 액수를 입력하는 대신 Policy function을 이용해 다음과 같이 application context를 활용할 수 있습니다:
create or replace vpd_pol_func
(
p_schema in varchar2,
p_table in varchar2
)
return varchar2
is
begin
return 'balance < sys_context(''vpdctx'', ''maxbal'')';
end;
Application context VPDCTX 의MAXBAL 속성을 설정해 두고 함수가 런타임에 값을 가져오도록 할 수 있습니다.
위의 코드 예제를 주의 깊게 살펴 보시기 바랍니다. Predicate은 크게 두 부분(‘<’기호 이전과 이후)으로 나뉘어집니다. 앞부분의 “balance”는 static한 문자열입니다. 뒷부분은 application context가 변경되기 전까지는 원래 값을 그대로 유지하므로 어느 정도 static하다고 볼 수 있습니다. 따라서 application context속성이 변경되지 않는 한, 전체 predicate이 static하다고 판단할 수 있으며, 따라서 함수를 재실행할 필요가 없습니다. Oracle Database 10g는 policy type이 context sensitive로 지정된 경우 이러한 최적화 알고리즘을 사용합니다. 세션에서 context 변경이 발생하지 않는 경우 함수는 재실행되지 않으며, 상당한 수준의 성능 향상 효과를 볼 수 있습니다.
Static Policy. 경우에 따라서는 보다 static한 형태의 predicate이 사용될 수도 있습니다. 위의 예제에서는 maximum balance를 변수로서 정의했습니다. 이러한 접근방식은 Oracle userid가 많은 웹 사용자에 의해 공유되고 사용자의 권한에 따라 이 변수(application context)가 변경되어야 하는 웹 애플리케이션 환경에서 유용합니다. 예를 들어 TAO와 KARTHIK이라는 두 사용자가 APPUSER라는 동일한 데이타베이스 사용자로 접근하는 경우에도, 각 세션 별로 설정된 application context에 의해 서로 다른 권한을 할당 받게 됩니다. 다시 말해 MAXBAL의 값은 Oracle userid가 아닌 TAO와 KARTHIK의 개별 세션 별로 바인드 됩니다.
Static policy의 경우 predicate은 아래와 같이 보다 예측 가능한 형태로 제시됩니다.
LORA와 MICHELLE는 각각 Acme Bearings와 Goldtone Bearings의 어카운트 관리자입니다. 두 사람은 데이타베이스에 연결할 때 개인 ID를 사용하며 각자에게 허용된 로우(row)만을 조회할 수 있습니다. Lora의 경우 predicate은 “where CUST_NAME = 'ACME'”, Michelle의 경우 predicate은 “where CUST_NAME = 'GOLDTONE'”입니다. 이 경우 predicate은 사용자ID와 연결되며, 따라서 그들에 의해 생성된 어떤 세션이든 application context가 제공하는 같은 값을 predicate으로 사용하게 됩니다.
10g는 이러한 경우 SGA 캐시에 predicate을 저장하고 해당 세션에 대해서는 policy function을 재실행하지 않고 계속적으로 재활용합니다. Policy function은 아래와 같습니다:
create or replace vpd_pol_func
(
p_schema in varchar2,
p_table in varchar2
)
return varchar2
is
begin
return 'cust_name = sys_context(''vpdctx'', ''cust_name'')';
end;
Policy는 아래와 같이 정의됩니다:
policy_type => dbms_rls.static
이와 같은 접근법을 사용하면 policy function이 단 한 차례만 수행됨을 보장할 수 있습니다. 세션에서 application context가 변경되는 경우에도 함수는 재실행되지 않으므로 성능이 대폭적으로 향상됩니다.
Static policy는 여러 구독자(subscriber)가 사용하는 애플리케이션 환경에서 유용합니다. 이 경우 여러 사용자 또는 구독자가 단일 데이타베이스의 데이타를 공유하게 됩니다. 구독자가 로그인하면, 로그인 과정에서 “after-login trigger”가 동작하여 application context를 설정하고 policy function을 실행함으로써 predicate을 얻게 됩니다.
하지만 static policy는 양날의 칼과도 같습니다. 위의 예에서는, application context의 VPDCTX.CUST_NAME속성의 값이 세션 내에서 변경되지 않는다고 가정했습니다. 만일 그 가정이 잘못되었다면 어떻게 될까요? 속성 값이 변해도 policy function이 재실행되지 않으므로 predicate에 새로운 값이 반영되지 않을 것이며, 따라서 완전히 잘못된 결과가 나올 것입니다. 그러므로 static policy를 사용할 때는 주의할 필요가 있으며, 속성 값이 변하지 않음을 분명히 확신할 수 있을 때에만 static policy를 사용해야 합니다. 이러한 가정이 불가능하다면, context sensitive policy를 사용하는 것이 무난합니다.
Shared Policy Types. 코드를 재활용하고 파싱된 코드의 활용도를 최대로 높이려면, 여러 테이블에 공통적으로 적용되는 policy function을 구현할 필요가 있습니다. 예를 들어, 위의 예에서 계좌 별로 두 개의 테이블(SAVINGS와 CHECKING)이 존재하지만 규칙은 똑같이 적용되는 경우를 가정해 봅시다. 사용자는 자신에게 허용된 것 이외의 계좌 잔액은 조회할 수 없습니다. 이 경우 CHECKING 테이블과 SAVINGS 테이블에 사용되는 policy function은 동일합니다. 생성되는 policy의 유형은 context_sensitive로 가정합니다.
다음과 같은 이벤트가 순서대로 발생한다고 가정해 봅시다:
1. 세션 연결
2. application context 설정
3. select * from savings;
4. select * from checking;
Application context가 3번, 4번 과정에서 변경되지 않았음에도 조회되는 테이블이 다르기 때문에 policy function은 재실행될 것입니다. 하지만 policy function이 같기 때문에 재실행할 필요는 없었습니다. 10g는 동일한 policy를 여러 오브젝트가 공유하는 기능을 제공합니다. 위의 예의 경우 policy type은 다음과 같이 정의됩니다:
New in 10g is the ability to share a policy across objects. In the above example, you would define the policy type of these policies as:
policy_type => dbms_rls.shared_context_sensitive
이처럼 policy를 “shared”로 지정함으로써 함수의 불필요한 실행을 방지하고 성능을 향상시킬 수 있습니다.
Selective Columns
이번에는 특정 컬럼이 select 된 경우에만 VPD policy가 적용되는 경우를 생각해 봅시다. ACCOUNTS 테이블이 아래와 같은 레코드를 갖는다고 가정합니다:
ACCTNO ACCT_NAME BALANCE
------ ------------ -------
1 BILL CAMP 1000
2 TOM CONNOPHY 2000
3 ISRAEL D 1500
Michelle은 balance가 1,600이 넘는 account를 조회할 수 없습니다. Michelle이 다음과 같은 쿼리를 실행한 경우:
select * from accounts;
아래와 같은 결과를 확인하게 될 것입니다:
ACCTNO ACCT_NAME BALANCE
------ ------------ -------
1 BILL CAMP 1000
3 ISRAEL D 1500
1,600이 넘는 balance를 갖는 acctno 2는 실행 결과에 포함되지 않았습니다. Michelle의 관점에서 볼 때 이 테이블은 3개가 아닌 2개의 로우를 갖습니다. 따라서 Michelle이 아래와 같은 쿼리를 실행하는 경우에도 그 결과는 3이 아닌 2가 반환됩니다:
select count(*) from accounts;
하지만 security policy에 예외 조건을 적용할 필요도 있습니다.
지금 Michelle은 모든 account balance를 조회하려 하는 것이 아니고 그저 데이타의 count만을 확인하려 하는 것입니다. Michelle이 조회할 수 없는 레코드의 count를 포함시키는 것을 허용하는 것을 고려할 수도 있을 것입니다. 10g는 이러한 경우를 위해 dbms_rls.add_policy 호출 과정에서 사용할 수 있는 새로운 매개변수를 추가하였습니다:
sec_relevant_cols => 'BALANCE'
이 매개변수가 사용된 경우, 사용자가 BALANCE 컬럼을 명시적으로 또는 암시적으로(예: select *) 조회하는 경우에 한해 VPD policy는 해당 로우를 조회 대상에서 제외시킵니다. 하지만 그 밖의 경우(예를 들어 사용자가 전체 로우의 count를 조회하는 경우)에는 테이블의 모든 로우에 대한 select가 허용됩니다. 이 경우 아래와 같이 쿼리를 수행하면 그 결과로 2가 아닌 3이 반환됩니다:
select count(*) from accounts;
하지만 아래의 쿼리는 두 개의 레코드만을 반환합니다.
select * from accounts;
Column Masking
이번에는 다른 조건이 붙는 경우를 생각해 봅시다. 일정한 임계값 이상의 balance를 갖는 레코드에 대한 조회를 완전히 제한하는 대신, 임계값 이상의 balance 컬럼에 대해 마스킹(masking)을 수행하는 조건으로 모든 레코드를 반환하는 방법을 선택할 수도 있습니다.
Michelle은 1,600 이상의 balance를 갖는 account를 조회할 수 없습니다. Michelle이 아래와 같은 쿼리를 실행하면:
select * from accounts;
acctno 1과 acctno3의 두 가지 레코드만을 확인하게 됩니다. 그 대신 아래와 같은 결과를 보기 원할 수 있습니다:
ACCTNO ACCT_NAME BALANCE
------ ------------ -------
1 BILL CAMP 1000
2 TOM CONNOPHY <null>
3 ISRAEL D 1500
위의 경우 모든 레코드가 표시되지만, 2000의 balance를 가진 acctno2 레코드의 BALANCE 컬럼은 null로 표시됩니다. 이러한 방법을 “column masking”이라 부르며, dbms_rls.add_policy 호출 과정에서 아래 매개변수를 사용하여 활성화할 수 있습니다:
sec_relevant_cols_opt => dbms_rls.all_rows
이 방법은 특정 컬럼에 대한 보안 유지가 필요한 경우 매우 유용하게 활용되며, 구현과정에서 별도의 코딩이 불필요합니다. 또 이 방법을 데이타 암호화의 대안으로 활용할 수도 있습니다.
결론
Oracle Database 10g의 VPD 기능은 매우 강력한 형태로 발전되었으며, policy를 기준으로 선택적인 컬럼을 마스킹하거나, 특정 컬럼이 액세스되는 경우에만 policy를 적용하는 등의 다양한 요구사항을 지원합니다. 또 애플리케이션의 성격에 따라 다른 policy를 적용함으로써 성능을 향상시킬 수도 있습니다.
VPD와 dbms_rls 패키지에 대한 자세한 설명은 PL/SQL Packages and Types Reference의 Chapter 79, 또는 Oracle Database Security Guide를 참고하시기 바랍니다. 필자가 Don Burleson과 공동집필한 Oracle Privacy Security Auditing (Rampant TechPress)도 참고가 될 것입니다.
제 15 주
세그먼트의 관리
Oracle Database 10g가 새로 제공하는 공간 재확보 기능, 온라인 테이블 재구성, 스토리지 증가량 예측 기능 등을 이용하여 세그먼트의 공간을 효율적으로 관리할 수 있습니다.
오래 전, Oracle Database의 경쟁 RDBMS 제품을 평가해 달라는 요청을 받은 일이 있습니다. 경쟁사의 프리젠테이션이 진행되는 동안, 청중들이 가장 감탄했던 기능이 바로 온라인 재구성(online reorganization) 기능이었습니다. 이 제품은 (오라클로 따지면 세그먼트에 해당하는) 영역의 데이타 블록을 온라인 상태에서 재배치하는 기능을 제공했습니다.
당시 오라클이 제공하던 Oracle9i Database는 이러한 기능을 제공하지 못했습니다. 이제 Oracle Database 10g는 온라인 상태에서 낭비되는 공간을 재확보하고 오브젝트를 보다 컴팩트(compact)한 형태로 관리할 수 있게 하는 기능을 추가적으로 제공합니다.
이 기능을 자세히 살펴 보기에 앞서, 이전에는 세그먼트 관리를 어떤 방법으로 수행했는지 설명하도록 하겠습니다.
기존의 관리 방법
그림 1과 같은 형태로 채워진 세그먼트를 가정해 봅시다. 작업이 수행되면서 그림 2와 같이 일부 로우(row)가 삭제되고 나면 낭비되는 공간이 생기게 됩니다. 낭비되는 공간은 (i) 남아있는 블록의 마지막 영역과 기존 테이블의 마지막 영역의 사이에서, 그리고 (ii) 로우가 부분적으로만 삭제된 블록 내부에서 발생합니다.
그림 1: 테이블에 할당된 블록. (로우는 회색 사각형으로 표시됨)
오라클이 이 영역에 대한 할당을 바로 해제하지 않고, 새로운 insert 작업 및 기존 로우의 확장에 대비한 예비 공간으로 활용합니다. 지금까지의 점유되었던 공간의 최고점을 High Water Mark(HWM)이라 부릅니다 (그림 2 참고).
그림 2: 일부 로우가 삭제된 후 (HWM은 변경되지 않았음)
하지만 이와 같은 접근 방식에는 두 가지 문제점이 존재합니다:
사용자의 쿼리가 풀 테이블 스캔을 발생시키는 경우, 오라클은 (설사 관련된 데이타가 전혀 존재하지 않는 경우라 하더라도) HWM 아래쪽의 모든 영역을 스캔합니다. 이로 인해 풀 테이블 스캔에 소요되는 시간이 길어질 수 있습니다.
로우가 direct path 정보와 함께 insert 되는 경우 (예를 들어 APPEND 힌트를 사용한 Insert, 또는 SQL*Loader direct path를 통해 insert 되는 경우) 새로 추가되는 데이타 블록은 HWM의 위쪽 영역에 추가됩니다. 따라서 HWM의 아래쪽 영역은 낭비된 채로 남게 됩니다.
Oracle9i와 그 이전 버전에서 공간을 재확보하려면, 테이블을 drop하고 다시 생성한 다음 데이타를 다시 로드하는 방식, 또는 ALTER TABLE MOVE 명령을 사용하여 테이블을 다른 테이블스페이스로 이동하는 방식을 사용해야 했습니다. 이 두 가지 방식은 모두 오프라인 상태에서 수행되어야 한다는 문제가 있습니다. 그 대안으로 online table reorganization 기능을 사용할 수도 있지만, 이를 위해서는 기존 테이블 크기의 두 배나 되는 공간이 필요했습니다.
10g의 경우 이러한 작업은 훨씬 간소화되었습니다. 10g의 Automatic Segment Space Management(ASSM)이 해당 테이블스페이스에 활성화되어 있는 경우, 세그먼트, 테이블, 인덱스를 shrink하고 free block을 재확보한 뒤 다른 용도로 할당하도록 데이터베이스로 반환됩니다. 그 자세한 방법을 알아보기로 합시다.
10g의 세그먼트 관리 기능
웹사이트를 통해 온라인으로 접수된 예약 정보를 보관하는 BOOKINGS라는 이름의 테이블이 존재한다고 가정해 봅시다. 확인 절차를 거친 예약은 BOOKINGS_HIST 테이블에 저장되고 해당 레코드는 BOOKINGS 테이블에서 삭제됩니다. 예약에서 확인까지 걸리는 시간은 고객에 따라 다릅니다. 이 경우 레코드 삭제로 인해 남은 공간이 충분하지 않은 경우에는 레코드가 테이블 HWM의 위쪽 영역에 insert 됩니다.
이제 낭비되는 공간을 재확보할 차례입니다. 먼저 해당 세그먼트에서 얼마나 많은 공간을 확보할 수 있는지 확인해야 합니다. 이 테이블은 ASSM이 적용된 테이블스페이스에 위치하고 있으므로, 아래와 같이 DBMS_SPACE 패키지의 SPACE_USAGE 프로시저를 사용해야 합니다:
declare
l_fs1_bytes number;
l_fs2_bytes number;
l_fs3_bytes number;
l_fs4_bytes number;
l_fs1_blocks number;
l_fs2_blocks number;
l_fs3_blocks number;
l_fs4_blocks number;
l_full_bytes number;
l_full_blocks number;
l_unformatted_bytes number;
l_unformatted_blocks number;
begin
dbms_space.space_usage(
segment_owner => user,
segment_name => 'BOOKINGS',
segment_type => 'TABLE',
fs1_bytes => l_fs1_bytes,
fs1_blocks => l_fs1_blocks,
fs2_bytes => l_fs2_bytes,
fs2_blocks => l_fs2_blocks,
fs3_bytes => l_fs3_bytes,
fs3_blocks => l_fs3_blocks,
fs4_bytes => l_fs4_bytes,
fs4_blocks => l_fs4_blocks,
full_bytes => l_full_bytes,
full_blocks => l_full_blocks,
unformatted_blocks => l_unformatted_blocks,
unformatted_bytes => l_unformatted_bytes
);
dbms_output.put_line(' FS1 Blocks = '||l_fs1_blocks||' Bytes = '||l_fs1_bytes);
dbms_output.put_line(' FS2 Blocks = '||l_fs2_blocks||' Bytes = '||l_fs2_bytes);
dbms_output.put_line(' FS3 Blocks = '||l_fs3_blocks||' Bytes = '||l_fs3_bytes);
dbms_output.put_line(' FS4 Blocks = '||l_fs4_blocks||' Bytes = '||l_fs4_bytes);
dbms_output.put_line('Full Blocks = '||l_full_blocks||' Bytes = '||l_full_bytes);
end;
/
The output is:
FS1 Blocks = 0 Bytes = 0
FS2 Blocks = 0 Bytes = 0
FS3 Blocks = 0 Bytes = 0
FS4 Blocks = 4148 Bytes = 0
Full Blocks = 2 Bytes = 16384
실행 결과를 통해 4,148개의 블록이 75-100%의 free space(FS4)를 포함하고 있으며, 이를 제외하고는 free space가 전혀 존재하지 않음을 확인할 수 있습니다. Full block은 단 2개에 불과합니다. 따라서 4,148 개의 블록에서 공간을 확보할 수 있습니다.
이제 테이블에 row-movement가 활성화되어 있는지 점검해야 합니다. row-movement를 활성화 하기 위해서는 아래와 같이 입력합니다:
alter table bookings enable row movement;
또는 Enterprise Manager 10g의 Administration 페이지에서 작업할 수도 있습니다. 또, 테이블의 모든 rowid 기반 트리거가 비활성화되어 있는지 점검해야 합니다. (로우가 이동되면서 rowid가 변경될 수 있기 때문입니다.)
마지막으로, 아래 명령을 사용하여 테이블의 기존 로우를 재구성합니다.
alter table bookings shrink space compact;
이 명령은 그림 3과 같은 형태가 되도록 블록 내부의 로우를 재배치하고, HWM 아래쪽 영역에 free block을 확보합니다. (하지만 HWM 자체는 변경되지 않습니다.)
그림 3: 재구성작업을 거친 뒤의 테이블 블록
작업이 완료된 후 공간 사용률에 변화가 있는지 확인해 봅시다. 앞에서 소개한 PL/SQL 코드를 사용하여 얼마나 많은 블록이 재구성되었는지 확인할 수 있습니다:
FS1 Blocks = 0 Bytes = 0
FS2 Blocks = 0 Bytes = 0
FS3 Blocks = 1 Bytes = 0
FS4 Blocks = 0 Bytes = 0
Full Blocks = 2 Bytes = 16384
이제 매우 중요한 변화가 있었음을 확인할 수 있습니다. FS4 블록 (75-100%의 여유 공간을 갖는 블록)의 수가 4,148에서 0으로 바뀌었습니다. 또 FS3 블록(50-75%의 여유 공간을 갖는 블록)의 수가 0에서 1로 증가했습니다. 반면 HWM은 변경되지 않았으며, 전체 공간사용률에도 아무런 변화가 없었습니다. 사용중인 전체 공간은 아래와 같이 확인할 수 있습니다:
SQL> select blocks from user_segments where segment_name = 'BOOKINGS';
BLOCKS
---------
4224
테이블이 점유중인 블록의 수(4,224)는 변경되지 않았으며, HWM도 기존 위치를 그대로 유지하고 있습니다. 다음과 같은 명령을 사용하면 HWM의 위치를 아래쪽을 이동하고 상위 영역을 재확보할 수 있습니다:
alter table bookings shrink space;
여기서 COMPACT 키워드가 사용되지 않은 점을 주목하시기 바랍니다. 위 구문을 실행하면 테이블이 사용되지 않은 블록을 반환하고 HWM을 재설정합니다. 아래와 같이 테이블에 할당된 공간을 확인하고 그 결과를 점검할 수 있습니다:
SQL> select blocks from user_segments where segment_name = 'BOOKINGS';
BLOCKS
----------
8
블록의 수가 4,224 개에서 8개로 줄었습니다. 그림 4에서 보여지는 것처럼 테이블 내에서 사용되지 않던 모든 공간이 반납되어 다른 세그먼트에서 활용할 수 있게 되었습니다.
그림 4: Shrink 작업 수행 후 free block이 데이타베이스로 반납된 결과
Shrink 작업은 온라인 상태에서 수행되며 사용자에게 아무런 영향을 미치지 않습니다.
테이블 인덱스에 대한 shrink 작업도 아래와 같이 수행할 수 있습니다:
alter table bookings shrink space cascade;
온라인 shrink 명령은 낭비되는 공간을 재확보하고 HWM을 재설정하는 매우 강력한 기능입니다. 필자는 개인적으로 HWM 재설정 기능의 유용성을 높이 평가합니다. HWM을 재설정함으로써 풀 테이블 스캔의 성능을 향상시킬 수 있기 때문입니다.
Shrinking 작업 대상 세그먼트 찾기
온라인 shrink 작업을 수행하기 전에, 압축율을 비약적으로 향상시킬 수 있는 대상 세그먼트를 찾아내는 작업을 수행해야 할 수도 있습니다. dbms_space 패키지에 내장된 verify_shrink_candidate 함수를 사용하여 이 작업을 간단하게 마무리할 수 있습니다. 아래 PL/SQL 코드는 대상 세그먼트가 1,300,000 바이트로 shrink 될 수 있는지 테스트합니다:
begin
if (dbms_space.verify_shrink_candidate
('ARUP','BOOKINGS','TABLE',1300000)
) then
:x := 'T';
else
:x := 'F';
end if;
end;
/
PL/SQL procedure successfully completed.
SQL> print x
X
--------------------------------
T
If you use a low number for the target shrinkage, say 3,000:
begin
if (dbms_space.verify_shrink_candidate
('ARUP','BOOKINGS','TABLE',30000)
) then
:x := 'T';
else
:x := 'F';
end if;
end;
이 경우 변수 x의 값은 ‘F’로 반환되었습니다. 이는 테이블이 3,000 바이트로 shrink 될 수 없음을 의미합니다.
인덱스 크기의 예측
이번에는 특정 테이블, 또는 여러 개의 테이블에 대해 인덱스를 생성해야 하는 경우를 가정해 봅시다. 컬럼, uniqueness 등의 구조에 관련한 일반적인 고려사항을 제외하고 가장 중요한 작업을 들라면, 인덱스의 크기를 예상하는 일을 꼽을 수 있을 것입니다. 테이블스페이스의 공간이 새로운 인덱스를 수용할 수 있을 만큼 충분한지 확인해야 합니다.
Oracle9i Database와 그 이전 버전의 경우, DBA들은 스프레드시트 또는 별개의 프로그램의 사용하여 인덱스의 크기를 예측하곤 했습니다. 10g에서는 새로 추가된 DBMS_SPACE 패키지를 이용해서 이 작업을 간단하게 마무리할 수 있습니다. 그렇다면 그 실제 활용 사례를 알아봅시다.
BOOKINGS 테이블의 booking_id 컬럼과 cust_name 컬럼을 대상으로 하는 새로운 인덱스를 추가해야 합니다. 새로운 인덱스가 얼마나 많은 공간을 사용하게 될까요? 아래와 같은 PL/SQL 스크립트를 실행하면 간단하게 확인할 수 있습니다:
declare
l_used_bytes number;
l_alloc_bytes number;
begin
dbms_space.create_index_cost (
ddl => 'create index in_bookings_hist_01 on bookings_hist '||
'(booking_id, cust_name) tablespace users',
used_bytes => l_used_bytes,
alloc_bytes => l_alloc_bytes
);
dbms_output.put_line ('Used Bytes = '||l_used_bytes);
dbms_output.put_line ('Allocated Bytes = '||l_alloc_bytes);
end;
/
실행 결과가 아래와 같습니다:
Used Bytes = 7501128
Allocated Bytes = 12582912
인덱스의 크기를 증가시킬 수 있는 매개변수(INITRANS 등)를 사용한 경우를 가정해 봅시다.
declare
l_used_bytes number;
l_alloc_bytes number;
begin
dbms_space.create_index_cost (
ddl => 'create index in_bookings_hist_01 on bookings_hist '||
'(booking_id, cust_name) tablespace users initrans 10',
used_bytes => l_used_bytes,
alloc_bytes => l_alloc_bytes
);
dbms_output.put_line ('Used Bytes = '||l_used_bytes);
dbms_output.put_line ('Allocated Bytes = '||l_alloc_bytes);
end;
/
실행 결과는 아래와 같습니다:
Used Bytes = 7501128
Allocated Bytes = 13631488
INITRANS 매개변수의 값을 높인 결과 Allocated Bytes가 훨씬 증가했음을 확인할 수 있습니다. 이와 같은 방법으로 인덱스가 사용하게 될 공간의 크기를 쉽게 예측할 수 있습니다.
하지만 두 가지 주의해야 할 점이 있습니다. 먼저, 이 프로세스는 “SEGMENT SPACE MANAGEMENT AUTO”가 활성화된 테이블스페이스에만 적용 가능합니다. 두 번째로, 패키지는 테이블 통계를 근거로 인덱스의 크기를 예측합니다. 따라서 테이블의 통계가 최신 상태를 유지하고 있는지 점검하는 것이 중요합니다. 가장 주의할 점은, 테이블에 통계가 존재하지 않는 경우 패키지가 에러를 발생시키는 대신 엉뚱한 계산 결과를 제시한다는 사실입니다.
테이블 크기의 예측
이번에는 BOOKING_HIST 테이블이 평균 30,000의 row length를 가진 로우로 구성되어 있고 테이블의 PCTFREE 매개변수가 20으로 설정된 경우를 가정해 보겠습니다. PCT_FREE를 30으로 올리는 경우 테이블의 크기가 얼마나 증가하게 될까요? PCT_FREE가 10% 증가한 만큼, 테이블의 크기도 10% 증가하게 될까요? DBMS_SPACE 패키지의 CREATE_TABLE_COST 프로시저를 사용하면 간단하게 확인할 수 있습니다. 테이블의 크기를 예측하기 위한 코드가 아래와 같습니다:
declare
l_used_bytes number;
l_alloc_bytes number;
begin
dbms_space.create_table_cost (
tablespace_name => 'USERS',
avg_row_size => 30,
row_count => 30000,
pct_free => 20,
used_bytes => l_used_bytes,
alloc_bytes => l_alloc_bytes
);
dbms_output.put_line('Used: '||l_used_bytes);
dbms_output.put_line('Allocated: '||l_alloc_bytes);
end;
/
실행 결과는 다음과 같습니다:
Used: 1261568
Allocated: 2097152
테이블의 PCT_FREE 매개변수를 30에서 20으로 아래와 같이 조정한 후 다시 실행합니다:
pct_free => 30
we get the output:
Used: 1441792
Allocated: 2097152
사용된 공간의 크기가 1,261,568에서 1,441,792로 증가했습니다. 이는 PCT_FREE 매개변수가 데이타 블록에 더 많은 여유 공간을 할당하기 대문입니다. 증가된 비율은 예상대로 10%가 아닌 14%로 확인되었습니다. 이처럼 DBMS_SPACE 패키지를 사용하여 PCT_FREE와 같은 매개변수를 변경하는 경우 또는 테이블을 다른 테이블스페이스로 이동하는 경우의 테이블 크기를 예측할 수 있습니다.
세그먼트의 크기 예측
Acme Hotel은 주말을 맞아 수요가 급증할 것을 예상하고 있습니다. DBA는 증가하는 수요를 감당하기에 충분한 공간이 남아 있는지 확인하려 합니다. 테이블의 크기가 얼마나 증가할지 어떻게 예측할 수 있을까요?
10g가 제공하는 예측 기능의 정확성은 우리를 놀라게 하기에 충분합니다. 결과를 얻기 위해서는 아래와 같은 쿼리를 실행하기만 하면 됩니다.
select * from
table(dbms_space.OBJECT_GROWTH_TREND
('ARUP','BOOKINGS','TABLE'));
dbms_space.object_growth_trend() 함수는 PIPELINEd 포맷으로 레코드를 반환하며, TABLE() casting을 통해 그 결과를 확인할 수 있습니다. 출력된 결과가 아래와 같습니다:
TIMEPOINT SPACE_USAGE SPACE_ALLOC QUALITY
------------------------------ ----------- ----------- ------------
05-MAR-04 08.51.24.421081 PM 8586959 39124992 INTERPOLATED
06-MAR-04 08.51.24.421081 PM 8586959 39124992 INTERPOLATED
07-MAR-04 08.51.24.421081 PM 8586959 39124992 INTERPOLATED
08-MAR-04 08.51.24.421081 PM 126190859 1033483971 INTERPOLATED
09-MAR-04 08.51.24.421081 PM 4517094 4587520 GOOD
10-MAR-04 08.51.24.421081 PM 127469413 1044292813 PROJECTED
11-MAR-04 08.51.24.421081 PM 128108689 1049697234 PROJECTED
12-MAR-04 08.51.24.421081 PM 128747966 1055101654 PROJECTED
13-MAR-04 08.51.24.421081 PM 129387243 1060506075 PROJECTED
14-MAR-04 08.51.24.421081 PM 130026520 1065910496 PROJECTED
출력된 결과는 시간(TIMEPOINT 컬럼)별로 BOOKINGS 테이블 크기의 증가 추이를 보여주고 있습니다. SPACE_ALLOC 컬럼은 테이블에 할당된 바이트 수를 의미하며 SPACE_USAGE 컬럼은 그 중 몇 바이트가 실제로 사용되고 있는지를 나타내고 있습니다. 이 정보는 Automatic Workload Repository(AWR, 본 연재 제 6 주 참고)에 의해 수집된 데이타를 기반으로 합니다. 위 데이타 중 실제로 데이타가 수집된 것은 2004년 3월 9일입니다 (QUALITY 컬럼의 값이 “GOOD”인 것으로 확인합니다). 따라서 해당 시점의 할당 공간 및 사용 공간의 수치는 정확하다고 판단할 수 있습니다. 반면, 이후 모든 데이타의 QUALITY 컬럼은 “PROJECTED”의 값을 가지며, 이는 데이타가 AWR에 의해 수집된 데이타를 근거로 추정된 것임을 의미합니다.
3월 9일 이전 데이타의 경우 QUALITY 컬럼의 값이 “INTERPOLATED”로 표시되어 있습니다. 이 데이타는 수집되거나 추정된 것이 아니며, 단순히 수집된 데이타의 패턴에 대한 interpolation을 통해 얻어진 것입니다. 이처럼 데이타가 수집되지 않은 과거 시점이 존재하는 경우, 그 값은 interpolation을 통해 계산됩니다.
결론
세그먼트 단위의 관리 기능을 이용하여 세그먼트 내부의 공간에 대한 설정을 변경하고, 테이블 내부의 여유 공간을 재확보하거나 온라인 테이블 재구성 작업을 통해 성능을 향상시킬 수 있습니다. 10g의 새로운 기능은 테이블 재구성에 관련된 반복적인 업무를 절감하는 효과를 제공합니다. 특히 온라인 세그먼트에 대한 shrink 기능은, 내부 fragmentation을 제거하고 high water mark를 조정함으로써 풀 테이블 스캔의 성능을 극적으로 향상시키는 효과가 있습니다.
Shrink 작업에 관한 자세한 정보는 Oracle Database SQL Reference의 관련 항목을 참고하시기 바랍니다. DBMS_PACKAGE는 PL/SQL Packages and Types Reference의 Chapter 88에서 설명되고 있습니다. 기술백서 The Self-Managing Database: Proactive Space & Schema Object Management는Oracle Database 10g의 공간 관리에 관련한 새로운 기능을 종합적으로 설명하고 있습니다. Oracle Database 10g의 온라인 데모 또한 OTN을 통해 제공되고 있습니다.
제 16 주
Transportable Tablespaces
10g의 transportable tablespace는 서로 다른 플랫폼 간의 데이타 이동을 지원하므로, 데이타 배포 작업을 한층 쉽고 빠르게 수행할 수 있습니다. 또, external table을 이용한 다운로드 기능을 활용하여 데이타 이동 및 변환 작업을 보다 효율적으로 완료할 수 있습니다.
데이타베이스 간의 데이타 이동 작업을 어떻게 처리하십니까? 여러 가지 방법이 있겠지만 그 중에서도 가장 돋보이는 것이 바로 transportable tablespace입니다. Transportable tablespace는 대상 테이블스페이스 집합이 자체적으로 다른 테이블스페이스에 있는 오브젝트를 참조하는 것이 없는 “self-contained”이어야 하며, 테이블스페이스를 읽기전용 상태로 설정한 뒤 메타데이타만을 먼저 익스포트(export)하고, OS 레벨의 카피 작업을 통해 데이타파일을 타겟 플랫폼으로 복사한 다음, 데이타 딕셔너리에 메타데이타를 임포트(이 프로세스를 “plugging”이라 부르기도 합니다.)하는 방식으로 데이타를 전송합니다. .
OS 파일 카피 작업은 SQL*Loader를 이용한 익스포트/임포트 작업과 같은 데이타 이동 방식에 비해 일반적으로 훨씬 빠른 처리 성능을 보입니다. 하지만 Oracle9i Database와 그 이전 버전의 경우, 소스 데이타베이스와 타겟 데이타베이스가 동일 OS플랫폼으로 구성되어야 한다는 제약사항 때문에 그 유용성에 제한을 받았습니다 (예를 들어 Solaris와 HP-UX 간의 테이블스페이스 전송은 불가능했습니다).
Oracle Database 10g에서는 이러한 기능 제약이 사라졌습니다. OS byte order가 동일하기만 하면 서로 다른 플랫폼 간이라도 테이블스페이스 전송이 가능해졌습니다. byte order에 대한 상세한 설명은 이 세션의 범위를 넘어서지만, 간략히 살펴보면 Windows를 포함하는 일부 운영체제의 경우, 멀티-바이트 바이너리 데이타를 저장할 때 least significant byte를 최하위 메모리 주소에 저장하는 방식을 사용합니다. 이러한 시스템을 “little endian”이라 부릅니다. 반면, Solaris를 비롯한 다른 운영체제는 most significant byte를 최하위 메모리 주소에 저장하며, 이러한 시스템을 “big endian”이라 부릅니다. Big-endian 시스템이 little-endian 시스템으로부터 데이타를 읽어 들이려면 변환 프로세스를 거쳐야 합니다. 그렇지 않은 경우, byte order 문제로 데이타가 올바르게 표시되지 않습니다. (Byte order에 대한 상세한 설명은 Embedded Systems Programming 2002년 1월호 기사, "Introduction to Endianness"를 참고하시기 바랍니다.) 하지만 동일한 endian을 갖는 플랫폼 간에 테이블스페이스를 전송하는 경우에는 변환 작업이 필요하지 않습니다.
그렇다면 어떤 운영체제가 어떤 byte order를 사용하는지 어떻게 알 수 있을 까요? 아래와 같은 쿼리를 사용하면 바로 확인할 수 있습니다:
SQL> select * from v$transportable_platform order by platform_id;
PLATFORM_ID PLATFORM_NAME ENDIAN_FORMAT
----------- ----------------------------------- --------------
1 Solaris[tm] OE (32-bit) Big
2 Solaris[tm] OE (64-bit) Big
3 HP-UX (64-bit) Big
4 HP-UX IA (64-bit) Big
5 HP Tru64 UNIX Little
6 AIX-Based Systems (64-bit) Big
7 Microsoft Windows IA (32-bit) Little
8 Microsoft Windows IA (64-bit) Little
9 IBM zSeries Based Linux Big
10 Linux IA (32-bit) Little
11 Linux IA (64-bit) Little
12 Microsoft Windows 64-bit for AMD Little
13 Linux 64-bit for AMD Little
15 HP Open VMS Little
16 Apple Mac OS Big
인텔 기반 Linux 운영체제를 사용하는 SRC1서버의 USERS 테이블스페이스를, Microsoft Windows 기반 TGT1 서버로 전송하는 경우를 생각해 봅시다. 이 경우 소스 플랫폼과 타겟 플랫폼 모두 little endian type 시스템입니다. USERS 테이블스페이스의 데이타파일은 users_01.dbf입니다. 전송 작업은 아래와 같은 절차를 거쳐 수행됩니다:
테이블을 READ ONLY 상태로 설정합니다:
alter tablespace users read only;
테이블을 익스포트 합니다.. 운영체제 프롬프트에서 다음과 같이 입력합니다:
exp tablespaces=users transport_tablespace=y file=exp_ts_users.dmp
exp_ts_users.dmp 파일은 메타데이타만을 포함하고 있으므로 그 크기가 매우 작습니다.
exp_ts_users.dmp 파일과 users_01.dbf 파일을 TGT1 서버로 복사합니다. FTP를 사용하는 경우에는 binary 옵션을 설정합니다.
데이타베이스에 테이블스페이스를 “플러깅(plugging)” 합니다. 운영체제 프롬프트에서 다음과 같이 입력합니다.
imp tablespaces=users transport_tablespace=y file=exp_ts_users.dmp datafiles='users_01.dbf'
4번째 단계를 마치고 나면 타겟 데이타베이스에 USERS 테이블스페이스가 생성되며, 테이블스페이스의 컨텐트도 사용 가능한 상태가 됩니다.
시스템 SRC1과 TGT1은 각각 Linux, Windows 운영체제를 사용한다는 사실을 명심하시기 바랍니다. 만일 Oracle9i 환경이었다면 TGT1의 데이타베이스가 users_01.dbf 데이타파일을 인식하지 못했을 것이고, 결국 전체 프로세스가 실패로 돌아갔을 것입니다. 이러한 경우라면 일반적인 익스포트/임포트 기능을 이용하거나, 플랫 파일을 생성한 뒤 SQL*Loader로 로드하거나, 데이타베이스 링크를 통해 direct load insert를 실행해야 할 것입니다.
10g에서는 타겟 데이타베이스가 다른 플랫폼으로부터 전송된 데이타파일을 정상적으로 인식하므로, 이러한 대안을 고려할 필요가 없습니다. 위의 예에서는 OS의 byte order 역시 동일하므로 (little endian), 변환 작업을 수행할 필요도 없습니다.
이 기능은 데이타 웨어하우스의 데이타가, 특수한 목적으로 운영되는 소규모 데이타 마트(data mart)에 정기적으로 전송되는 환경에서 특히 유용합니다. 10g 환경으로 구성된 경우, 데이타 웨어하우스는 대형 엔터프라이즈급 서버에, 데이타 마트는 Linux 기반 인텔 머신과 같은 저가형 서버에 구성하는 것이 가능해집니다. 이처럼 transportable tablespace를 사용하여 다양한 하드웨어와 운영체제를 조합한 환경을 구현할 수 있습니다.
서로 다른 endian을 갖는 시스템 간의 데이타 전송
소스 플랫폼과 타겟 플랫폼이 서로 다른 endian을 갖는 경우 어떻게 데이타 전송을 처리할 수 있을까요? 앞에서 설명한 것처럼 타겟 서버와 소스 서버의 byte order가 다르면 전송된 데이타를 올바르게 인식할 수 없으므로, 단순 카피 작업으로 데이타 파일을 이동하는 것이 불가능합니다. 하지만 방법은 있습니다. 바로 Oracle 10g RMAN 유틸리티가 데이타파일을 다른 byte order로 변환하는 기능을 지원하고 있습니다.
위의 예에서, 만일 SRC1 서버가 Linux(little endian)를 기반으로 하고, TGT1 서버가 HP-UX(big endian)을 기반으로 한다면, 3단계와 4단계의 사이에 변환을 위한 별도의 단계를 적용해야 합니다. RMAN을 사용하면 Linux 환경의 데이타파일을 HP-UX 포맷으로 변환할 수 있습니다 (단 테이블스페이스가 읽기전용 상태로 설정되어 있어야 합니다).
RMAN> convert tablespace users
2> to platform 'HP-UX (64-bit)'
3> format='/home/oracle/rman_bkups/%N_%f';
Starting backup at 14-MAR-04
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile conversion
input datafile fno=00004 name=/usr/oradata/dw/starz10/users01.dbf
converted datafile=/home/oracle/rman_bkups/USERS_4
channel ORA_DISK_1: datafile conversion complete, elapsed time: 00:00:07
Finished backup at 14-MAR-04
위 과정을 거치면 /home/oracle/rman_bkups 디렉토리에 표준 RMAN 파일 포맷의 파일이 <tablespace_name>_<absolute_datafile_no> 의 파일명으로 생성됩니다. 결국 USERS 테이블스페이스 자체는 전혀 변경되지 않았고, HP-UX 환경을 위한 새로운 파일이 생성되었습니다. 이제 이 파일을 타겟 시스템으로 복사한 뒤 위에서 설명한 것과 같은 처리 과정을 거치면 됩니다.
RMAN 변환 명령은 매우 강력합니다. 위와 같은 명령을 사용하는 경우, RMAN은 순차적으로 데이타파일을 생성합니다. 여러 개의 데이타파일을 포함하는 테이블스페이스를 처리할 때에는 여러 개의 변환 프로세스를 병렬적으로 수행하도록 명령할 수도 있습니다. 그렇게 하려면 위 명령에 아래 구문을 삽입하면 됩니다:
parallelism = 4
위와 같이 하면 네 개의 RMAN 채널이 생성되어 각각 별도의 데이타파일에 대해 변환 작업을 수행합니다. 하지만 parallelism이 정말로 효과를 발휘하는 것은, 많은 수의 테이블스페이스를 한꺼번에 변환할 때입니다. 아래는 두 개의 테이블스페이스(USERS와 MAINTS)를 HP-UX 포맷으로 변경하는 예입니다:
RMAN> convert tablespace users, maints
2> to platform 'HP-UX (64-bit)'
3> format='/home/oracle/rman_bkups/%N_%f'
4> parallelism = 5;
Starting backup at 14-MAR-04
using target database controlfile instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=244 devtype=DISK
allocated channel: ORA_DISK_2
channel ORA_DISK_2: sid=243 devtype=DISK
allocated channel: ORA_DISK_3
channel ORA_DISK_3: sid=245 devtype=DISK
allocated channel: ORA_DISK_4
channel ORA_DISK_4: sid=272 devtype=DISK
allocated channel: ORA_DISK_5
channel ORA_DISK_5: sid=253 devtype=DISK
channel ORA_DISK_1: starting datafile conversion
input datafile fno=00004 name=/usr/oradata/dw10/dw10/users01.dbf
channel ORA_DISK_2: starting datafile conversion
input datafile fno=00005 name=/usr/oradata/dw10/dw10/users02.dbf
channel ORA_DISK_3: starting datafile conversion
input datafile fno=00006 name=/usr/oradata/dw10/dw10/maints01.dbf
channel ORA_DISK_4: starting datafile conversion
input datafile fno=00007 name=/usr/oradata/dw10/dw10/maints02.dbf
converted datafile=/home/oracle/rman_bkups/USERS_4
channel ORA_DISK_1: datafile conversion complete, elapsed time: 00:00:03
converted datafile=/home/oracle/rman_bkups/USERS_5
channel ORA_DISK_2: datafile conversion complete, elapsed time: 00:00:00
converted datafile=/home/oracle/rman_bkups/MAINTS_6
channel ORA_DISK_3: datafile conversion complete, elapsed time: 00:00:01
converted datafile=/home/oracle/rman_bkups/MAINTS_7
channel ORA_DISK_4: datafile conversion complete, elapsed time: 00:00:01
Finished backup at 14-MAR-04
위의 실행결과에서, 변환된 파일이 기존 파일명과 무관하고 이해하기도 어려운 파일명을 갖게 되는 것을 볼 수 있습니다 (예를 들어, users01.dbf는 USERS_4로 변환됩니다). 원하는 경우 데이타파일의 naming format을 변경할 수 있습니다. 이 프로세스는 Data Guard에서 사용하는 데이타파일 naming 방식과 유사합니다:
RMAN> convert tablespace users
2> to platform 'HP-UX (64-bit)'
3> db_file_name_convert '/usr/oradata/dw10/dw10','/home/oracle/rman_bkups'
4> ;
Starting backup at 14-MAR-04
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile conversion
input datafile fno=00004 name=/usr/oradata/dw10/dw10/users01.dbf
converted datafile=/home/oracle/rman_bkups/users01.dbf
channel ORA_DISK_1: datafile conversion complete, elapsed time: 00:00:03
channel ORA_DISK_1: starting datafile conversion
input datafile fno=00005 name=/usr/oradata/dw10/dw10/users02.dbf
converted datafile=/home/oracle/rman_bkups/users02.dbf
channel ORA_DISK_1: datafile conversion complete, elapsed time: 00:00:01
Finished backup at 14-MAR-04
위와 같이 하면 기존의 파일명을 그대로 유지할 수 있습니다. /home/oracle/rman_bkups 디렉토리에 가 보면, users01.dbf와 users02.dbf가 생성된 것을 확인할 수 있습니다. 위 예제의 경우, 파일의 변환 작업은 소스 플랫폼에서 수행되었습니다. 필요한 경우 타겟 플랫폼에서 변환을 수행할 수도 있습니다. 예를 들어, users01.dbf를 HP-UX 기반의 TGT1 서버로 카피한 후 아래와 같이 HP-UX 포맷으로 변환할 수 있습니다:
In the above cases, we converted the files on the source platform. However, you can do that on the target platform as well. For example, you can copy file users01.dbf to host TGT1 running HP-UX and then convert the file to HP-UX format with:
RMAN> convert
2> datafile '/usr/oradata/dw10/dw10/users01.dbf'
3> format '/home/oracle/rman_bkups/%N_%f'
4> ;
이렇게 함으로써 해당 디렉토리에 지정된 포맷의 파일을 생성할 수 있습니다.
그렇다면 데이타파일을 굳이 타겟 플랫폼에서 변환하는 이유가 무엇일까요? 첫 번째로, 소스 플랫폼의 테이블스페이스를 READ ONLY 상태로 두는 기간이 짧아지므로 다운타임을 줄일 수 있다는 점을 들 수 있습니다. 데이타파일을 3중 미러 형태로 구성하고 테이블스페이스를 읽기 전용으로 설정한 다음, 3번째 미러를 분리한 후 곧바로 테이블스페이스를 읽기/쓰기 모드로 변경할 수도 있습니다. 분리된 3번째 미러는 타겟 시스템에 마운트된 후 변환됩니다. 이렇게 하면 테이블스페이스가 읽기 전용 상태에 있는 기간을 최소화할 수 있습니다.
또 다른 이유로 성능을 들 수 있습니다. 지속적으로 부하가 발생하는 OLTP 데이타베이스에서 RMAN 변환 작업을 수행함으로써 시스템에 불필요한 부담을 주게 될 수 있습니다. 그 대신, 병렬 작업에 최적화된 데이타 웨어하우스 서버에서 오프라인 형태로 변환 작업을 처리하는 것이 바람직할 수 있습니다.
External Table을 데이타 전송 매개체로 활용하기
Oracle9i Database에서 처음 소개된 external table은 일정한 형식을 갖춘 일반 텍스트 파일을 테이블처럼 보이게 하고 SQL 구문을 통해 접근할 수 있게 하는 기능입니다. OLTP 데이타베이스에서 운영 중인 TRANS 테이블의 컨텐트를, external table을 사용하여 데이타 웨어하우스 데이타베이스로 이동해야 하는 경우를 생각해 봅시다. 그 과정이 아래와 같습니다:
OLTP 데이타베이스에서, TRANS 테이블의 컨텐트를 포함하는 텍스트 파일을 생성합니다. 생성된 텍스트 파일을 /home/oracle/dump_dir 디렉토리에 trans_flat.txt라는 이름으로 저장합니다. (SQL 구문을 이용하여 텍스트 파일의 생성이 가능합니다.)
spool trans_flat.txt
select <column_1> ||','|| <column_2> ||','|| ...
from trans;
spool off
ftp, rcp 등의 전송 메커니즘을 사용하여 파일을 데이타 웨어하우스 서버에 복사합니다. (파일은 /home/oracle/dump_dir 디렉토리에 위치하고 있습니다.) 데이타 웨어하우스 데이타베이스에서 dump_dir 디렉토리를 생성합니다:
On the data warehouse database, create a directory object named dump_dir as:
create directory dump_dir as '/home/oracle/dump_dir';
external table을 생성합니다:
create table trans_ext
(
... <columns of the table> ...
)
organization external
(
type oracle_loader
default directory admin
access parameters
(
records delimited by newline
badfile 'trans_ext.bad'
discardfile 'trans_ext.dis'
logfile 'trans_ext.log'
fields terminated by "," optionally enclosed by '"'
(
... <columns> ...
)
)
location ('trans_flat.txt')
)
reject limit unlimited;
Direct load insert, merge 등의 일반적인 방법을 사용하여 external table을 일반 테이블로 로드합니다.
위에서 텍스트 파일을 생성하는 첫 번째 단계는 가장 많은 시간을 소요합니다. SQL 구문을 사용하여 텍스트를 생성하고 파일에 스풀링하는 과정은 절차 상으로는 간단하지만 실행 시간이 오래 걸립니다. SQL*Plus 대신 Pro*C 또는 OCI 프로그램을 사용하여 처리 시간을 어느 정도 단축할 수 있지만 그래도 꽤 오랜 시간이 필요합니다. 컬럼을 수작업으로 지정하는 것도 작업을 지체시키는 요인이 됩니다.
이 두 가지 문제는 10g에서 완전히 해결되었습니다. 이제 external table 생성 프로세스를 사용하여 테이블을 포터블 포맷으로 신속하게 언로드할 수 있습니다. 위 예의 첫 번째 단계는 아래와 같은 간단한 SQL 구문으로 대치됩니다:
create directory dump_dir as '/home/oracle/dump_dir';
create table trans_dump
organization external
(
type oracle_datapump
default directory dump_dir
location ('trans_dump.dmp')
)
as
select * from trans
/
위 명령은 /home/oracle/dump_dir 디렉토리에 trans_dump.dmp라는 이름의 파일을 생성합니다. 이 파일은 ASCII 텍스트 파일이 아닙니다. 메타데이타는 일반 텍스트이지만, 실제 데이타는 raw 포맷을 사용하고 있습니다. 하지만, 이 파일은 export dump 파일과 마찬가지로 모든 운영체제에서 호환 가능하며, 데이타의 다운로드가 매우 빠르게 수행된다는 점에서 export와 차별화됩니다. 이 파일을 데이타 웨어하우스 서버에 카피하고 위에서 설명한 것과 동일한 방법으로 external table을 생성할 수 있습니다.
그렇다면 지금까지 설명한 방법이 기존에 사용되어 오던 데이타 전송 메커니즘과 어떤 차이가 있는 것일까요? 첫 번째로, 복잡한SQL 구문을 작성하지 않고도 포터블 파일을 매우 빠르게 생성할 수 있습니다. 두 번째로, 이 파일을 external table의 input으로 적용해서 일반적인 테이블을 다루듯 다른 테이블로의 데이타 로드 작업을 간단하게 완료할 수 있습니다. 또 아래와 같은 구문을 사용하면 external table로의 데이타 다운로드 성능을 향상시킬 수 있습니다:
create table trans_dump
organization external
(
type oracle_datapump
default directory dump_dir
location ('trans_dump.dmp')
)
parallel 2
as
select * from trans
/
위 명령은 병렬적인 형태로 파일 생성 작업을 수행하도록 합니다. 이 방법은 멀티-CPU 환경에서 유용합니다. 이와 별도로, 동시에 여러 개의 external table을 생성하도록 할 수도 있습니다:
create table trans_dump
organization external
(
type oracle_datapump
default directory dump_dir
location ('trans_dump_1.dmp','trans_dump_2.dmp')
)
parallel 4
as
select * from trans
/
위 명령은 trans_dump_1.dmp와 trans_dump_2.dmp라는 두 개의 파일을 생성합니다. 이 방법은 파일을 여러 개의 물리적 디바이스 또는 컨트롤러로 분산하고 I/O 성능을 향상시키는데 유용합니다.
결론
10g의 transportable tablespace를 적극적으로 활용함으로써, 분석된 데이타가 더 신속하게, 그리고 더 높은 빈도로 사용자에게 제공되는 환경을 구현할 수 있습니다. 또 이 기능은 오프라인 미디어를 통해 이기종 시스템의 데이타베이스로 데이타를 배포하는 데에도 이용됩니다. External table을 이용한 다운로드 기능은 대용량 데이타 처리를 위한 ETL 툴로써 손색이 없습니다.
Furthermore, by making transportable tablespaces viable, 10g makes data refreshes quicker and more frequent so that analyzed data is available to end users sooner. This capability can also be used to publish data via offline media to different databases, regardless of their host systems. Using external table downloads the utility to move large quantities of data as an ETL tool is finally available to the end user.
10g의 테이블스페이스 전송 기능에 대한 자세한 설명은 Oracle Database Administrator's Guide의 Chapter 8, "Transporting Tablespaces Between Databases" 섹션을 참고하시기 바랍니다.
제 17 주
Automatic Shared Memory Management
오라클 인스턴스의 메모리 풀에 필요한 만큼의 메모리를 할당하는 작업 때문에 번거로우셨습니까? ? Automatic Shared Memory Management 기능을 이용하여 필요한 영역에 메모리를 자동으로 할당할 수 있습니다.
여러분이 초심자이든, 또는 숙련된 DBA이든 아래와 같은 에러를 최소한 한 번쯤은 경험해 보셨을 것입니다:
ORA-04031: unable to allocate 2216 bytes of shared memory ("shared pool"... ...
또는:
ORA-04031: unable to allocate XXXX bytes of shared memory
("large pool","unknown object","session heap","frame")
또는:
ORA-04031: unable to allocate bytes of shared memory ("shared pool",
"unknown object","joxlod: init h", "JOX: ioc_allocate_pal")
첫 번째 에러의 원인은 명백해 보입니다. shared pool에 할당된 메모리가 사용자 요청에 응답하기에 충분하지 못하기 때문입니다 (이 경우 shared pool의 크기가 문제가 아니라, 바인드된 변수를 사용하지 않는 데 따르는 과도한 파싱 작업으로 인해 발생한 fragmentation이 원인일 수도 있습니다. 이것인 필자가 즐겨 언급하는 주제이긴 하지만, 여기에서는 당면한 과제에 집중하기로 합시다.) 두 번째와 세 번째 에러는 각각 large pool과 Java pool의 공간이 충분하지 못한 것이 원인이 되어 발생합니다.
애플리케이션의 변경 작업을 거치지 않고 이 에러를 해결해야 합니다. 그렇다면 어떤 방법을 사용해야 할까요? 결국 사용 가능한 메모리를 오라클 인스턴스가 사용하는 모든 풀에 어떻게 분배할 것인가의 문제로 귀결됩니다.
어떻게 배분할 것인가?
오라클 인스턴스의 System Global Area (SGA)는 buffer cache, shared pool, Java pool, large pool, redo log buffer 등의 메모리 영역을 포함하고 있습니다. 각각의 풀은 고정된 크기의 운영체제의 메모리 공간을 점유하며, 그 크기는 초기화 매개변수 파일을 통해 DBA가 지정할 수 있습니다.
4종류의 풀(db block buffer cache, shared pool, Java pool, large pool)은 SGA 공간의 대부분을 차지합니다. (redo log buffer는 상대적으로 작은 공간을 사용할 뿐 아니라, 그 성격상 이 문서에서 논의되는 내용과 무관합니다.) DBA는 각각의 영역에 할당된 메모리가 충분한지 점검해야 합니다.
각 영역의 크기를 2GB, 1GB, 1GB, 1GB로 설정하기로 결정한 경우를 가정해 봅시다. 먼저 아래와 같이 초기화 매개변수를 설정하여 데이타베이스 인스턴스의 풀 사이즈를 변경합니다:
db_cache_size = 2g
shared_pool_size = 1g
large_pool_size = 1g
java_pool_size = 1g
이제 이 매개변수를 자세히 분석해 봅시다. 과연 설정된 값이 정확하다는 걸 보증할 수 있을까요?
아마 여러분 모두 나름대로 의심을 품고 있을 것입니다. 실제로 각각의 풀에 필요한 만큼의 공간이 정확히 할당되었다고 자신할 수 있는 이는 아무도 없습니다. 필요한 메모리 공간은 데이타베이스 내부 프로세싱에 따라 결정되며, 이는 시시각각으로 변화하기 때문입니다.
예제를 통해 설명해 보겠습니다. “전형적인” OTLP 데이타베이스 환경에 상대적으로 적은 용량의 메모리가 buffer cache에 할당되어 있습니다. 어느 날, 사용자가 일별 마감 보고서를 작성하기 위해 대규모의 테이블 스캔 작업을 실행합니다. Oracle9i Database는 온라인 상태에서 메모리 할당량을 변경하는 기능을 제공합니다. 전체 메모리 용량이 제한되어 있는 상황에서, DBA는 large pool과 Java pool에 할당된 일부 공간을 buffer cache로 돌리기로 결정합니다:
alter system set db_cache_size = 3g scope=memory;
alter system set large_pool_size = 512m scope=memory;
alter system set java_pool_size = 512m scope=memory;
이 방법은 일시적으로 그 효과를 발휘합니다. 하지만 large pool을 사용하는 RMAN 작업이 야간에 실행되면서 large pool의 용량이 부족해집니다. DBA가 이번에는 db cache의 용량 일부를 large pool에 할당합니다.
RMAN 작업은 완료되었지만, 다음에는 Java pool을 사용하는 배치 프로그램이 실행됩니다. Java pool에 관련한 에러를 확인한 DBA는 Java pool과 db cache의 용량을 확보하기 위해 아래와 같이 실행합니다:
alter system set db_cache_size = 2G scope=memory;
alter system set large_pool_size = 512M scope=memory;
alter system set java_pool_size = 1.5G scope=memory;
다음날 아침, OLTP 작업이 재개되고 DBA는 똑같은 과정을 다시 반복해야 합니다!
이러한 악순환의 고리를 끊어버리기 위해 각각의 풀에 최대한의 용량을 영구적으로 할당하는 방법을 고려할 수 있습니다. 하지만 사용 가능한 실제 메모리보다 많은 용량을 SGA 영역에 할당함으로써 스와핑과 페이징이 빈번하게 발생하는 위험을 감수해야만 합니다. 차라리 수작업으로 메모리를 재할당하는 방법이 (번거롭긴 하지만) 적절해 보입니다.
또 다른 방법으로 각 풀에 합리적인 선의 최소 용량을 할당하는 방법을 생각해 볼 수 있습니다. 하지만 요구되는 용량이 증가할 때마다 성능이 저하될 것입니다.
어떤 방법을 사용하든 SGA에 할당된 전체 메모리 용량은 변하지 않는 반면, 각각의 풀에 할당되는 용량은 자주 변경되어야 합니다. 그렇다면, RDBMS가 사용자의 요구를 감지하고 메모리를 자동으로 재할당한다면 작업이 훨씬 수월해지지 않을까요?
Oracle Database 10g의 Automatic Shared Memory Management가 바로 이러한 기능을 제공합니다. SGA_TARGET 매개변수를 통해 SGA의 전체 사이즈를 설정하고 나면, SGA 내부의 각 풀은 워크로드를 기준으로 다이내믹하게 관리됩니다. 결국 DBA가 해야 할 일은 SGA_TARGET 매개변수를 설정하는 것 밖에 없게 됩니다.
Automatic Shared Memory Management 설정
예를 통해 설명해 보겠습니다. 먼저, SGA의 전체 크기를 결정합니다. 현재 얼마나 많은 용량이 할당되어 있는지 확인하려면 아래와 같이 입력합니다:
SQL> select sum(value)/1024/1024 from v$sga;
SUM(VALUE)/1024/1024
--------------------
500
SGA의 현재 크기는 약 500MB로 설정되어 있으므로 이 수치를 SGA_TARGET에 적용하면 됩니다. 다음으로 아래와 같이 구문을 실행합니다:
alter system set sga_target = 500M scope=both;
위와 같이 설정함으로써, 각각의 풀에 대한 용량을 설정할 필요가 없게 됩니다. 이제 각각의 풀에 관련한 매개변수의 값을 0으로 설정하거나, 해당 항목을 완전히 삭제합니다.
shared_pool_size = 0
large_pool_size = 0
java_pool_size = 0
db_cache_size = 0
데이타베이스를 다시 시작하고 변경된 설정을 적용합니다.
같은 작업을 Enterprise Manager 10g에서 수행할 수도 있습니다. 데이타베이스 홈 페이지에서 “Administration” 탭을 선택한 후 “Memory Parameter”를 클릭합니다. 메모리 관련 매개변수가 수동 설정되어 있는 경우에는 설정된 항목별로 “Enable” 버튼이 표시될 것입니다. “Automatic Shared Memory Management” 옆에 있는 “Enable” 버튼을 눌러 Automatic Shared Memory Management 기능을 활성화합니다. 나머지 작업은 Enterprise Manager에 의해 자동 수행됩니다.
설정 작업을 마친 후 각 풀의 크기를 확인하려면 아래와 같이 실행합니다:
SQL> select current_size from v$buffer_pool;
CURRENT_SIZE
------------
340
SQL> select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
POOL MBYTES
------------ ----------
java pool 4
large pool 4
shared pool 148
설정 작업을 마친 후 각 풀의 크기를 확인하려면 아래와 같이 실행합니다:
그림 1: 초기 할당 결과
이제 오라클에서 사용 가능한 메모리 크기가 500MB에서 300MB로 줄었다고 가정해 봅시다. 먼저 SGA 영역을 위해 설정된 target size를 변경해야 할 것입니다:
alter system set sga_target = 300M scope=both;
다시 메모리 할당 현황을 점검하면 아래와 같은 결과를 확인할 수 있습니다:
SQL> select current_size from v$buffer_pool;
CURRENT_SIZE
------------
244
SQL> select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
POOL MBYTES
------------ ----------
java pool 4
large pool 4
shared pool 44
전체 사용 공간은 240+4+4+44 = 296MB로, 전체 용량(300MB)와 거의 일치합니다. SGA_TARGET을 변경한 후의 메모리 할당 내역이 그림 2와 같습니다.
그림 2: SGA size를 300MB로 변경한 후의 할당 결과
풀의 크기는 다이내믹하게 조정됩니다. 워크로드가 증가하면 그에 비례하여 풀의 크기도 증가하고, 다른 풀에 관련된 워크로드가 증가하는 경우에는 줄어들기도 합니다. 이러한 확장/수축 과정은 DBA의 개입 없이 자동적으로 수행됩니다. 앞부분에 설명한 예에서 대량의 large pool을 사용하는 RMAN 작업이 시작되는 경우, large pool은 자동적으로 4MB에서 40MB로 증가합니다. 그림 3에서 보여지는 것처럼, 추가로 필요한 36MB는 db block buffer에서 가져오고, 결과적으로 db block buffer는 줄어들 것입니다.
그림 3: large pool의 수요가 증가하는 경우의 자동 할당 결과
변경되는 풀의 크기는 워크로드에 따라 달라집니다. SGA의 전체 크기도 언제나 SGA_TARGET에서 지정한 최대치를 넘지 않으므로, 실제 메모리보다 많은 영역을 할당하여 과도한 페이징과 스와핑을 발생시키는 문제를 방지할 수 있습니다. SGA_MAX_SIZE 매개변수를 조정하면 SGA_TARGET의 값을 가능한 최대치인 SGA_MAX_SIZE까지 다이내믹하게 증가시킬 수 있습니다.
자동 튜닝을 지원하지 않는 Pool.
SGA에서 관리되는 풀 중 일부는 다이내믹한 변경을 허용하지 않으며, 따라서 명시적으로 설정되어야 합니다. 특히 비표준 블록 사이즈를 갖는 buffer pool과 KEEP / RECYCLE 풀의 경우가 그러합니다. 데이타베이스의 블록 사이즈가 8K인 환경에서, 2K, 4K, 16K, 32K 등의 블록 사이즈를 갖는 풀들을 구성하려면, 수작업으로 설정하는 방법 밖에 없습니다. 이렇게 설정된 풀의 크기는 고정된 값을 유지하며, 부하 수준에 따라 확장되거나 수축되지 않습니다. KEEP/RECYCLE 풀을 구성하는 경우에도 마찬가지입니다. log buffer 역시 다이내믹하게 조정되지 않습니다. 또한 log_buffer 매개변수를 통해 설정된 값은 고정된 값을 유지합니다. (10g에서는 “Streams pool”이라는 새로운 유형의 풀을 지원합니다. 이 풀은 streams_pool_size 매개변수를 통해 설정되며, 역시 자동 메모리 튜닝을 지원하지 않습니다.)
여기서 한 가지 의문이 생깁니다. 비표준 블록 사이즈를 갖는 풀을 설정하는 경우, 다른 풀들에 관련한 메모리 자동 관리 기능에는 어떤 영향이 있을까요?
자동 튜닝이 불가능한 매개변수(예: db_2K_cache_size)를 설정하는 경우, 데이타베이스는 SGA_TARGET에서 이 매개변수의 값을 차감한 후 남은 공간을 활용하여 자동 메모리 관리를 수행합니다. 예를 들어, 아래와 같이 설정된 경우를 가정해 봅시다:
sga_target = 500M
db_2k_cache_size = 50M
다른 풀 관련 매개변수는 설정되어 있지 않은 것으로 가정합니다. 이 경우, 2KB buffer pool에 할당된 50MB를 제외한 450MB가 default block size buffer pool(db_cache_size), shared pool, Java pool, large pool 등의 자동 관리에 이용됩니다. 자동 튜닝이 불가능한 매개변수에 변경이 발생하는 경우, 자동 튜닝에 사용되는 메모리 크기 역시 변경됩니다. 예를 들어, db_2K_cache_size의 값을 50MB에서 100MB로 변경하면, shared pool, large pool, default buffer pool에 사용되는 메모리 크기는 450MB에서 400MB로 자동 변경됩니다 (그림 4 참조).
그림 4: 자동 튜닝을 지원하지 않는 버퍼 매개변수를 변경한 경우
하지만 메모리가 충분하거나, 위에서 언급한 위험요소를 걱정할 필요가 없다면 Automatic Memory Management 기능을 사용하지 않아도 무방합니다. 이 경우 SGA_TARGET 매개변수를 정의하지 않거나 그 값을 (ALTER SYSTEM 명령을 통해서, 또는 매개변수 파일 편집을 통해서) 0으로 설정하면 됩니다. SGA_TARGET이 0으로 설정되면, 각 풀의 현재 크기가 매개변수 값으로 자동 설정됩니다.
Enterprise Manager의 활용
Enterprise Manager 10g을 이용해서 이 매개변수들을 조작할 수도 있습니다. 데이타베이스 홈 페이지에서 “Memory Parameters”를 클릭하면 그림 5와 같은 화면이 표시됩니다.
Enterprise Manager 10g을 이용해서 이 매개변수들을 조작할 수도 있습니다. 데이타베이스 홈 페이지에서 “Memory Parameters”를 클릭하면 그림 5와 같은 화면이 표시됩니다.
붉은색 원으로 표시된 항목을 참고하시기 바랍니다. 데이타베이스는 Automatic Shared Memory Management 모드로 동작하고 있으며 전체 메모리 크기는 564MB로, SGA_TARGET 매개변수에 설정된 값과 동일합니다. 이 화면에서 설정값을 수정하고 Apply 버튼을 누르면 매개변수 값이 자동으로 조정됩니다.
각 풀의 최소 메모리 크기 지정
SGA_TARGET을 600MB로 설정하고 Automatic Shared Memory Management를 이용하는 경우를 가정해 봅시다. 자동 설정된 풀의 크기가 아래와 같습니다:
풀 사이즈 (MB)
Buffer 404
Java 4
Large 4
Shared 148
Java pool과 large pool의 크기(각각 4MB)가 너무 작다고 판단되는 경우, 각 영역의 최소값을 (8MB, 16MB 등으로) 설정하여 온라인 상태에서 적용할 수 있습니다. 아래와 같이 ALTER SYSTEM 명령을 통해 최소값을 명시하면 그 결과가 다이내믹하게 적용됩니다:
alter system set large_pool_size = 16M;
alter system set java_pool_size = 8M;
이제 풀의 크기를 다시 조회하면 아래와 같이 달라진 것을 확인할 수 있습니다:
SQL> select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
POOL MBYTES
------------ ----------
java pool 8
large pool 16
shared pool 148
SQL> select current_size from v$buffer_pool;
CURRENT_SIZE
------------
388
재할당된 풀의 메모리 크기가 아래와 같습니다:
풀 사이즈 (MB)
Buffer 388
Java 8
Large 16
Shared 148
Java pool과 large pool은 각각 8MB, 16MB로 재조정되었고, 전체 SGA의 크기는 600MB 이하를 유지하고 있습니다 (buffer pool의 크기가 404MB에서 388MB로 감소했습니다). 물론 Automatic Shared Memory Management는 여전히 동작하고 있습니다. 방금 전에 설정한 값은 풀의 최소 크기를 정의한 것이며, 이제 Java pool과 large pool은 8MB, 16MB 이하의 크기로 줄어들지 않을 것입니다.
결론
Oracle SGA에서 관리되는 각 풀의 메모리 요구량은 시스템 상황에 따라 끊임없이 변화합니다. Oracle Database 10g의 Automatic Shared Memory Management 기능은 필요한 영역에 자원을 다이내믹하게 할당함으로써, 시스템 메모리 자원을 보다 효율적으로 이용할 수 있게 합니다. 이처럼 메모리 관리를 효율화함으로써 메모리 요구량을 줄이고, 하드웨어 비용을 절감할 수도 있습니다.
다음 주 주제: Automatic Database Diagnostic Monitor (ADDM) 의 Chapter 7을 참고하십시오.
제18 주
ADDM과 SQL Tuning Advisor
이제 Oracle Database가 직접 제공하는 SQL 튜닝 서비스를 활용해 보십시오! SQL Profile를 이용하여 쿼리 성능을 향상시키고 ADDM을 통해 일반적인 성능 문제를 쉽고 빠르게 해결하는 방법을 배워보십시오.
오늘은 조용한 하루입니다. 데이타베이스에도 문제가 없어 보입니다. DBA는 긴장을 풉니다. 미루어 두었던 RMAN 매개변수, 블록 사이즈 점검 작업을 하기에 좋은 날입니다.
갑자기 개발자 한 명이 DBA의 자리로 달려 옵니다. 그가 사용하는 SQL 쿼리의 성능이 저하되었습니다. 그가 말합니다. “가능한 한 빨리 해결해 주셨으면 좋겠습니다.”
어쩌면 긴장을 너무 빨리 풀었는지도 모릅니다. 데이타베이스의 성능과 보안을 향상시키려는 기존의 계획은 뒤로 밀리고, 오늘도 급한 불을 끄기 위해 하루를 보내야 합니다.
DBA는 반복적인 잡무에서 벗어나 좀 더 전략적인 과제에 집중할 수 있기를 원합니다. 그렇다면 반복적인 업무를 대신해 줄 조수를 하나 고용하면 좋지 않을까요?
Oracle Database 10g에 추가된 Automatic Database Diagnostic Monitor(ADDM)이 바로 이런 역할을 해 줍니다. ADDM은 데이타베이스 성능 통계에 대한 철저한 분석을 통해 성능 병목을 확인하고, SQL 구문에 대한 분석을 통해 성능 향상을 위한 조언을 제공합니다. 또 SQL Tuning Advisor와 연동된 기능을 제공하기도 합니다. 이번 연재에서는, ADDM을 이용한 성능 향상 방안에 대해 설명합니다.
Automatic Database Diagnostic Monitor (ADDM)
제 6 주 연재에서, Automatic Workload Repository (AWR)에 대해 설명한 바 있습니다. AWR은 데이타베이스로부터 상세한 성능 관련 지표를 주기적으로 수집하여 저장합니다. 스냅샷 생성 작업이 완료될 때마다, ADDM이 호출되어 서로 다른 스냅샷의 데이타와 성능 지표를 비교 분석하고 성능 향상을 위한 조언을 제공합니다. 문제가 발견된 후, ADDM은 다른 어드바이저 툴(SQL Tuning Advisor 등)을 호출하여 해결 방법을 찾아내기도 합니다.
예를 통해 ADDM의 기능을 설명해 보도록 하겠습니다. 원인이 확인되지 않은 성능 문제에 대한 진단 작업에 착수한 경우를 가정해 봅시다. DBA는 문제가 되는 SQL 구문이 무엇인지 확인해 둔 상태입니다. 그러나 실제 환경에서는 이와 같은 유용한 단서도 모를 경우도 있습니다.
10g에서 진단 작업을 수행하는 과정에서, drill-down분석을 위해 적절한 시간 간격을 두고 생성된 스냅샷들을 선택할 수 있습니다. Enterprise Manager 10g의 데이타베이스 홈 페이지에서 “Advisor Central”을 선택하고 “ADDM”을 클릭하면 그림 1과 같은 화면이 표시됩니다.
그림 1: ADDM 태스크의 생성
이 화면에서 ADDM을 이용한 분석 작업을 생성할 수 있습니다. 성능 문제가 오후 11시에 발생했음을 알고 있는 DBA는, “Period Start”와 “Period End”의 값을 설정하여 해당 시간 대의 스냅샷들을 선택합니다. (붉은색 원으로 표시된) 카메라 모양의 아이콘을 클릭하여 스냅샷 시작 시간과 종료 시간을 지정할 수도 있습니다. 시간대를 설정하고 난 뒤 “OK” 버튼을 누르면 그림 2와 같은 화면이 표시됩니다.
그림 2: ADDM 분석 결과
ADDM은 해당 시간대에 관련한 두 가지 성능 문제를 발견해 냈습니다. 일부 SQL 구문이 지나치게 많은 CPU 시간을 사용하고 있으며, 이로 인해 데이타베이스의 성능이 전체적으로 저하되었습니다. 발견된 내용을 근거로, ADDM은 해당 구문에 대한 SQL 튜닝을 수행할 것을 권고하고 있습니다.
각각의 문제 항목을 클릭하면 그림 3에서 보여지는 것과 같은 상세 정보를 얻을 수 있습니다.
그림 3: ADDM 분석 결과 상세 정보
위 화면에서 문제의 원인이 된 SQL 구문을 확인할 수 있습니다. ADDM은 SQL Tuning Advisor를 이용해 이 SQL 구문에 대한 분석 작업을 수행할 것을 권고하고 있습니다. “Run Advisor Now” 버튼을 클릭하면 SQL Tuning Advisor가 호출되어 분석 작업을 시작합니다.
그림 2 화면의 “View Report” 버튼을 참고하시기 바랍니다. 개별 웹 페이지 별로 권고 사항을 제시하는 것과 별도로, ADDM은 전체 분석 결과에 대한 텍스트 리포트를 생성합니다. Listing 1에서 생성된 텍스트 리포트의 내용을 확인하실 수 있습니다. 텍스트 리포트는 문제가 되는 SQL 구문과 그 hash value 등의 상세한 정보를 제공합니다. 또 텍스트 리포트의 SQL ID 정보를 이용하여 SQL Tuning Advisor 또는 커맨드 라인을 통한 분석 작업을 수행할 수 있습니다.
ADDM은 AWR 스냅샷이 생성될 때마다 호출되고, 가장 최근의 스냅샷과의 비교를 통해 권고사항을 제시합니다. 따라서 비교해야 할 두 스냅샷이 서로 인접한 경우에는 (이미 보고서가 생성되어 있으므로) 별도로 ADDM 태스크를 실행할 필요가 없으며, 스냅샷이 인접해 있지 않은 경우에만 ADDM 태스크를 실행할 필요가 있습니다.
ADDM의 기능이 단순히 SQL 구문의 분석에 한정되지 않는다는 사실을 명심하시기 바랍니다. 과거 연재에서 확인한 것과 같이, ADDM은 메모리 관리, 세그먼트 관리, redu/undo 등의 영역에 대한 다양한 분석 기능을 제공합니다. 제한된 지면을 통해 ADDM의 기능을 모두 설명하는 것은 어차피 불가능하므로, 지금부터는 SQL Tuning Advisor에 초점을 맞추어 설명을 진행하도록 하겠습니다.
SQL Tuning Advisor를 이용한 Access분석
오라클 데이타베이스의 옵티마이저(optimizer)는 가능한 액세스 경로를 여럿 생성한 뒤, 오브젝트 통계정보를 기준으로 가장 적은 비용이 드는 하나를 선택하는 방식으로 runtime optimization을 수행합니다. 하지만 옵티마이저는 (시간의 제약을 받는 만큼) SQL 구문의 튜닝이 필요한지, 통계가 정확한지, 새로운 인덱스를 생성해야 하는지 등의 여부를 판단하지 않습니다. 반면 SQL Tuning Advisor는 일종의 “전문가 시스템”과 같은 역할을 합니다. 옵티마이저가 “현재 가능한 대안 중 최적의 결과를 얻을 수 있는 것은 무엇인가?”라는 질문에 대한 답변을 제공한다면, SQL Tuning Advisor는 “사용자의 요구사항을 기반으로 고려했을 때, 성능을 향상시키기 위해 할 수 있는 일이 무엇인가?”라는 질문의 답을 제공합니다.
이러한 “전문가 시스템”으로서의 작업은 CPU 등의 자원을 많이 소모합니다. 이러한 이유로 SQL Tuning Advisor는 데이타베이스가 Tuning Mode로 설정된 경우에만 SQL 구문에 대한 분석작업을 수행합니다. Tuning Mode는 튜닝 태스크를 생성하는 과정에서 SCOPE 및 TIME 매개변수를 설정함으로써 지정됩니다. 사용자에 대한 영향을 최소화하려면 데이타베이스 활동이 적은 시간대를 선택하여 Tuning Mode를 사용하는 것이 바람직합니다.
이제 예를 통해 설명하도록 하겠습니다. 문제가 되는 SQL 구문이 아래와 같습니다:
select account_no from accounts where old_account_no = 11
실제로 튜닝하기 어렵지 않은 구문이지만, 이해를 돕기 위해 간단한 구문을 사용하였습니다. 어드바이저는 Enterprise Manager 또는 커맨드 라인을 통해 실행할 수 있습니다.
먼저, 커맨드 라인을 이용하는 방법을 알아봅시다. 아래와 같은 방법으로 dbms_sqltune 패키지를 호출하고 어드바이저를 실행합니다.
declare
l_task_id varchar2(20);
l_sql varchar2(2000);
begin
l_sql := 'select account_no from accounts where old_account_no = 11';
dbms_sqltune.drop_tuning_task ('FOLIO_COUNT');
l_task_id := dbms_sqltune.create_tuning_task (
sql_text => l_sql,
user_name => 'ARUP',
scope => 'COMPREHENSIVE',
time_limit => 120,
task_name => 'FOLIO_COUNT'
);
dbms_sqltune.execute_tuning_task ('FOLIO_COUNT');
end;
/
위 패키지는 FOLIO_COUNT라는 이름의 튜닝 태스크를 생성하고 실행합니다. 다음에는 아래와 같이 입력하여 태스크 실행 결과를 확인합니다.
set serveroutput on size 999999
set long 999999
select dbms_sqltune.report_tuning_task ('FOLIO_COUNT') from dual;
실행 결과는 Listing 2에서 확인할 수 있습니다. 어드바이저가 제공하는 권고 사항을 자세히 살펴보시기 바랍니다. 이 경우, 어드바이저는 OLD_ACCOUNT_NO 컬럼에 인덱스를 생성할 것을 권고하고 있습니다. 그 뿐 아니라, 인덱스가 생성된 경우의 비용을 계산하고, 기대되는 성능 향상 효과를 구체적인 형태로 제시하고 있습니다.
예로 든 구문 자체가 단순한 만큼, 굳이 어드바이저를 이용해서 이런 결과를 얻을 필요는 없었을 것입니다. 하지만 보다 복잡한 형태의 쿼리에 성능 문제가 발생한 경우라면, 어드바이저를 통해 수작업으로는 불가능한 성능 개선 효과를 얻을 수 있습니다.
중급 레벨 튜닝: Query Restructuring
조금 더 복잡한 쿼리를 분석하는 경우를 생각해 봅시다:
select account_no from accounts a
where account_name = 'HARRY'
and sub_account_name not in
( select account_name from accounts
where account_no = a.old_account_no and status is not null);
어드바이저는 다음과 같은 권고 사항을 제시하였습니다:
1- Restructure SQL finding (see plan 1 in explain plans section)
----------------------------------------------------------------
The optimizer could not unnest the subquery at line ID 1 of the execution
plan.
Recommendation
--------------
Consider replacing "NOT IN" with "NOT EXISTS" or ensure that columns used
on both sides of the "NOT IN" operator are declared "NOT NULL" by adding
either "NOT NULL" constraints or "IS NOT NULL" predicates.
Rationale
---------
A "FILTER" operation can be very expensive because it evaluates the
subquery for each row in the parent query. The subquery, when unnested can
drastically improve the execution time because the "FILTER" operation is
converted into a join. Be aware that "NOT IN" and "NOT EXISTS" might
produce different results for "NULL" values.
이번에는 인덱스 생성과 같은 오브젝트 구조 변경을 제안하는 대신, NOT IN 대신 NOT EXIST를 사용하도록 쿼리를 수정할 것을 제안하고 있습니다. 어드바이저는 근본적인 원인을 통해 권장 내용의 근거를 설명하고, 그 결정을 DBA의 판단에 맡깁니다.
고급 튜닝: SQL Profiles
옵티마이저는 쿼리가 사용하는 오브젝트 통계정보(object statistics)를 점검한 뒤 가장 적은 비용을 사용하는 경로를 선택함으로써 execution plan을 생성합니다. 쿼리가 두 개 이상의 테이블을 참조하는 경우, 옵티마이저는 관련된 테이블의 통계를 모두 점검한 뒤 가장 적은 비용을 사용하는 경로를 선택하지만, 테이블 간의 관계에 대해서는 아무 것도 이해하지 못합니다.
예를 들어, DELINQUENT(연체) 상태가 $1,000 이하의 balance를 갖는 한 account가 있다는 경우를 가정해 봅시다. ACCOUNTS 테이블과 BALANCES 테이블을 join하는 쿼리에 status가 DELINQUENT인 데이타만을 필터링하는 조건을 추가함으로써, 보다 적은 수의 결과를 얻을 수 있을 것입니다. 옵티마이저는 이러한 테이블 간의 복잡한 관계를 이해하지 못합니다. 하지만 어드바이저의 경우는 다릅니다. 어드바이저는 데이터로부터 이들 관계정보를 “수집”해 낸 뒤 SQL Profile의 형태로 이를 저장합니다. 이제 SQL Profile에 접근할 수 있게 된 옵티마이저는 테이블의 데이타 분포뿐 아니라 데이타 간의 관계까지도 이해할 수 있게 됩니다. 이렇게 추가로 제공되는 정보를 활용하면 보다 뛰어난 수준의 execution plan을 생성하고 성능을 향상시킬 수 있습니다.
SQL Profile을 이용하면, 쿼리 힌트를 코드에 삽입하는 형태의 SQL 구문 튜닝이 불필요해집니다. 따라서 SQL Tuning Advisor를 이용하여, 코드에 전혀 손을 대지 않고도 패키지 애플리케이션을 튜닝할 수 있습니다.
오브젝트 통계가 하나 또는 그 이상의 오브젝트에 매핑되는 반면, SQL Profile은 쿼리에 매핑됩니다. 같은 테이블(ACCOUNTS와 BALANCES)을 참조하더라도 쿼리가 다르면 프로파일도 달라집니다.
SQL Tuning Advisor는 실행 과정에서 프로파일을 생성한 뒤 이를 “Accept”할 것을 권고합니다. 사용자가 “Accept”하지 않는 이상 프로파일은 구문에 반영되지 않습니다. 아래와 같이 실행하면 아무 때나 프로파일을 accept할 수 있습니다:
begin
dbms_sqltune.accept_sql_profile (
task_name => 'FOLIO_COUNT',
name => 'FOLIO_COUNT_PROFILE'
description => 'Folio Count Profile',
category => 'FOLIO_COUNT');
end;
위 명령은 어드바이저가 생성한 FOLIO_COUNT_PROFILE을 위의 예에서 설명한 FOLIO_COUNT 튜닝 태스크에 연관된 구문에 연결합니다. (DBA가 직접 SQL Profile을 생성할 수는 없으며, 어드바이저만이 SQL Profile을 생성할 수 있음을 참고하시기 바랍니다. 사용자는 SQL Profile의 사용 여부만을 선택할 뿐입니다.)
DBA_SQL_PROFILES 딕셔너리 뷰를 통해 생성된 SQL Profile을 확인할 수 있습니다. SQL_TEXT 컬럼은 프로파일이 할당된 SQL 구문을, STATUS 컬럼은 프로파일의 활성화 여부를 표시합니다. (프로파일이 특정 구문에 연결되어 있는 경우라 하더라도, 활성화하기 전에는 execution plan에 반영되지 않습니다.)
ADDM과 SQL Tuning Advisor의 활용
위에 예로 든 세 가지 경우 이외에도, SQL Tuning Advisor는 쿼리에서 사용하는 오브젝트에 통계가 누락되어 있는지의 여부를 확인해 줍니다. 요약하자면, 어드바이저는 다음과 같은 네 가지 유형의 작업을 수행합니다.
최적화를 위한 오브젝트들의 유효하고, 사용 가능한 통계정보를 보유하고 있는지 확인합니다.
성능 향상을 위해 쿼리를 재작성하는 방안을 권고합니다.
접근 경로를 확인하고 인덱스, MV(materialized view) 등을 추가하여 성능을 향상시킬 수 있는 방법을 조사하고 제안합니다.
SQL Profile을 생성하고, 이를 특정 쿼리에 연결합니다.
ADDM과 SQL Tuning Advisor가 유용하게 활용되는 경우를, 다음과 같은 세 가지 시나리오를 기준으로 검토해 볼 수 있습니다.
사후조치적 튜닝(Reactive Tuning): 애플리케이션의 성능이 갑자기 저하됩니다. DBA는 ADDM을 사용하여 문제가 되는 SQL 구문을 확인합니다. ADDM의 권고사항에 따라 SQL Tuning Advisor를 실행하고 문제를 해결합니다.
사전예방적 튜닝(Proactive Tuning): 애플리케이션은 정상적으로 동작합니다. DBA는 유지보수를 위해 필요한 작업을 실행하고 쿼리를 좀 더 개선할 방법이 있는지 확인하고자 합니다. DBA는 스탠드얼론 모드로 SQL Tuning Advisor를 실행하고 가능한 대안을 검토합니다.
개발단계 튜닝(Development Tuning): QA 단계 또는 운영 단계보다는, 개발 단계에서 쿼리 튜닝을 수행하는 것이 상대적으로 용이합니다. 이때 어드바이저의 커맨드 라인 버전을 사용하여 개별 SQL 구문을 튜닝할 수 있습니다.
Enterprise Manager의 활용
앞의 예는 SQL Tuning Advisor를 커맨드 라인 모드에서 사용하는 방법을 기준으로 설명되었습니다. 커맨드 라인 모드는 태스크 실행을 위한 스크립트 생성이 용이하다는 장점이 있습니다. 하지만, 사용자에 의해 이미 문제가 보고된 경우라면 Enterprise Manager 10g를 이용하는 방법이 더 효과적일 수 있습니다.
(제 13주) 연재에서, 새롭게 개선된 Enterprise Manager 인터페이스에 대해 소개한 바 있습니다. 이번에는 EM을 활용하여 SQL 구문을 진단하고 튜닝하는 방법을 설명해 보겠습니다. 데이타베이스 홈 페이지 하단의 “Advisor Central” 링크를 클릭하면 다양한 어드바이저를 위한 메뉴를 제공하는 화면이 표시됩니다. 이 화면 상단의 “SQL Tuning Advisor”를 클릭합니다 (그림 4 참조).
그림 4: Enterprise Manager의 Advisor Central 화면
이제 SQL Tuning Advisor가 실행됩니다. 다음 화면에서 "Top SQL"을 클릭합니다 (그림 5 참조).
그림 5: SQL Tuning Advisor
그림 6에서 보여지는 것과 같은 화면이 표시되며, 이 화면에서 표시되는 그래프를 통해 다양한 wait class에 관련된 정보를 시간대 별로 확인할 수 있습니다.
그림 6: Top SQL 화면
그래프의 관심 영역은 회색 사각형으로 표시됩니다. CPU wait이 높게 나타나는 영역에 마우스를 드래그하여 관심영역을 조정합니다. 화면의 하단에는 해당 시간대에 수행된 SQL 구문 관련 정보가 표시됩니다 (그림 7 참조).
그림 7: SQL 구문의 Activity 정보
상단(붉은색으로 표시된 부분)에는 가장 많은 CPU 자원을 소모하는 SQL 구문들이 표시되고 있습니다. 각 구문의 SQL ID를 클릭하면 그림 8과 같은 화면이 표시됩니다.
그림 8: SQL Details 화면
위 화면을 통해 문제가 되는 SQL 구문을 확인할 수 있습니다. “Run SQL Tuning Advisor” 버튼을 클릭하면 어드바이저가 실행되고 그림 9와 같은 화면이 표시됩니다.
그림 9: SQL Tuning Advisor의 스케줄링
어드바이저 스케줄러 화면에서, 태스크의 유형과 분석의 심도를 결정할 수 있습니다. 위 화면에서는 “comprehensive” analysis를 선택하고 어드바이저를 바로 실행하도록 설정하였습니다. 어드바이저의 실행이 완료되면 그림 10과 같은 화면을 통해 어드바이저의 권고 사항을 확인할 수 있습니다.
그림 10: Advisor Recommendation 화면
EM을 이용한 SQL Tuning Advisor 실행 방법은, 앞에서 설명한 커맨드 라인 버전을 이용하는 경우와 유사합니다. 하지만, 발생된 문제를 확인하여 드릴다운을 수행하고, 권고사항을 생성한 후 이를 승인하는 전체 과정이, 실제 발생한 문제를 해결하기에 편리한 형태로 구성되어 있다는 점에서 차이가 있습니다.
결론
ADDM은 성능 지표를 자동적으로 분석하고 오라클 전문가가 구현한 베스트 프랙티스 및 방법론을 기반으로 권고사항을 제시해 주는 강력한 성능 관리 툴입니다. 이 기능을 활용하여 발생된 문제와 그 원인을 확인할 수 있을 뿐 아니라, 취해야 할 조치에 대한 조언을 얻을 수 있습니다.
ADDM과 SQL Tuning Advisor에 대한 자세한 정보는 기술백서 Oracle Database 10g: The Self-Managing Database 와 The Self-Managing Database: Guided Application & SQL Tuning, 그리고 Oracle Database 2 Day DBA 매뉴얼의 제 10장 및 Oracle Database Performance Tuning Guide의 6장 and 13장을 참고하시기 바랍니다.
제 19 주
Scheduler
dbms_job 패키지의 실행 주기 설정을 수작업으로 관리하는 것이 번거로우십니까? 이제 10g데이타베이스가 제공하는 Scheduler를 이용해 보십시오.
여러분들 중 일부는 백그라운드 데이타베이스 작업 스케줄을 설정하기 위해 dbms_job 패키지를 사용하고 있을 것입니다. 하지만 필자가 알기로는 대부분의 DBA들이 dbms_job 패키지를 사용하지 않고 있습니다.
이 패키지는 PL/SQL 코드 세그먼트만을 처리할 수 있으며, 데이타베이스 외부의 운영체제 파일 또는 실행 파일 이미지를 처리할 수 없다는 기능적 한계를 갖고 있습니다. 이 때문에 DBA들은 Unix의 cron, Windows의 AT 명령 등을 사용하여 운영 체제 레벨에서 스케줄링을 설정하는 방법을 선택합니다. 또는 그래픽 사용자 인터페이스를 제공하는 써드 파티 툴을 사용하기도 합니다.
그러나 dbms_job은 이들과 다른 장점들이 있습니다. 이 중 하나는 데이터베이스가 실행되고 있는 경우에만 활성화된다는 것입니다. 만약 데이터베이스가 다운되어 있다면 해당 Job들은 실행되지 않습니다. 데이터베이스 외부에 존재하는 툴들은 수작업을 통해 데이터베이스가 실행되고 있는지 조사되어야 하며, 복잡한 작업일 수 있습니다. Dbms_job의 다른 장점으론 데이터베이스 내부에 존재한다는 것입니다. 그러므로 SQL*Plus와 같은 유틸리티를 이용해 쉽게 접근 가능하다는 것입니다.
Oracle Database 10g Scheduler는 모든 종류의 작업을 지원하는 내장형 작업 스케줄러 유틸리티를 제공합니다. 10g Scheduler의 가장 큰 장점은, 데이타베이스에 포함된 형태로 제공되므로 추가적인 비용이 들지 않는다는 것입니다. 이번 연재에서는 Scheduler의 기능에 대해 자세히 살펴보기로 합니다.
Creating Jobs Without Programs
개념의 이해를 돕기 위해 예를 통해 설명하겠습니다. 아카이브 로그 파일을 다른 파일시스템으로 이동하기 위해 아래와 같은 이름의 셸 스크립트를 생성했다고 가정해 봅시다:
/home/arup/dbtools/move_arcs.sh
별도의 프로그램을 생성하지 않고도 작업 유형으로 “Executable”을 지정하고 스케줄링을 설정할 수 있습니다.
begin
dbms_scheduler.create_job
(
job_name => 'ARC_MOVE_2',
schedule_name => 'EVERY_30_MINS',
job_type => 'EXECUTABLE',
job_action => '/home/arup/dbtools/move_arcs.sh',
enabled => true,
comments => 'Move Archived Logs to a Different Directory'
);
end;
/
또 Schedule Name을 설정하지 않고 작업을 생성하는 것도 가능합니다.
begin
dbms_scheduler.create_job
(
job_name => 'ARC_MOVE_3',
job_type => 'EXECUTABLE',
job_action => '/home/arup/dbtools/move_arcs.sh',
repeat_interval => 'FREQ=MINUTELY; INTERVAL=30',
enabled => true,
comments => 'Move Archived Logs to a Different Directory'
);
end;
/
앞의 두 가지 예를 통해 dbms_job과 비교했을 때의 Scheduler의 장점을 확인할 수 있습니다. Scheduler를 이용하면 PL/SQL 프로그램뿐 아니라 OS 유틸리티와 프로그램을 실행하는 것이 가능합니다. 이러한 기능을 활용하여 범용적인 데이타베이스 작업 관리 환경을 구현할 수 있습니다. 또 Scheduler는 자연 언어(natural language)를 사용하여 실행 주기를 정의할 수 있다는 매우 중요한 이점을 제공합니다. 스케줄을 매 30분 단위로 실행하고자 하는 경우, (PL/SQL 문법 대신) 자연 언어 형식의 표현을 사용하여 REPEAT_INTERVAL 매개변수를 아래와 같이 정의할 수 있습니다:
'FREQ=MINUTELY; INTERVAL=30'
좀 더 복잡한 예를 들어 설명해 보겠습니다. 운영 중인 애플리케이션이 오전 7시에서 오후 3시까지의 시간대에 집중적으로 사용된다고 가정해 봅시다. Statspack을 실행하면 월요일~금요일 오전 7시 ~ 오후 3시의 시스템 통계를 수집할 수 있습니다. DBMS_JOB.SUBMIT을 사용하여 작업을 생성하는 경우라면, NEXT_DATE 매개변수는 아래와 같이 정의됩니다:
DECODE
(
SIGN
(
15 - TO_CHAR(SYSDATE,'HH24')
),
1,
TRUNC(SYSDATE)+15/24,
TRUNC
(
SYSDATE +
DECODE
(
TO_CHAR(SYSDATE,'D'), 6, 3, 1
)
)
+7/24
)
위의 코드가 이해하기 쉽습니까? 전혀 그렇지 않습니다.
이번에는 DBMS_SCHEDULER를 이용하는 방법을 살펴 보겠습니다. REPEAT_INTERVAL 매개변수는 아래와 같이 간단하게 정의됩니다:
'FREQ=DAILY; BYDAY=MON,TUE,WED,THU,FRI; BYHOUR=7,15'
이 매개변수를 이용해 실행 주기를 다양한 형태로 설정할 수 있습니다. 몇 가지 예가 아래와 같습니다:
매월 마지막 일요일:
FREQ=MONTHLY; BYDAY=-1SUN
매월 세 번째 금요일:
FREQ=MONTHLY; BYDAY=3FRI
매월 뒤에서 두 번째 금요일
FREQ=MONTHLY; BYDAY=-2FRI
마이너스(-) 기호는 숫자가 뒤에서부터 계산된다는 의미입니다.
설정된 실행 주기가 올바른지 확인하려면 어떻게 해야 할까요? 캘린더 문자열을 이용해서 날짜를 미리 확인할 수 있다면 편리하지 않을까요? EVALUATE_CALENDAR_STRING 프로시저를 이용하여 실행 예정 시각을 미리 검토할 수 있습니다. 위의 예 – 월~금7:00 AM ~ 3:00 PM Statspack 실행 – 에서 설정된 실행 주기를 확인하는 방법이 아래와 같습니다:
set serveroutput on size 999999
declare
L_start_date TIMESTAMP;
l_next_date TIMESTAMP;
l_return_date TIMESTAMP;
begin
l_start_date := trunc(SYSTIMESTAMP);
l_return_date := l_start_date;
for ctr in 1..10 loop
dbms_scheduler.evaluate_calendar_string(
'FREQ=DAILY; BYDAY=MON,TUE,WED,THU,FRI; BYHOUR=7,15',
l_start_date, l_return_date, l_next_date
);
dbms_output.put_line('Next Run on: ' ||
to_char(l_next_date,'mm/dd/yyyy hh24:mi:ss')
);
l_return_date := l_next_date;
end loop;
end;
/
실행 결과는 다음과 같습니다:
Next Run on: 03/22/2004 07:00:00
Next Run on: 03/22/2004 15:00:00
Next Run on: 03/23/2004 07:00:00
Next Run on: 03/23/2004 15:00:00
Next Run on: 03/24/2004 07:00:00
Next Run on: 03/24/2004 15:00:00
Next Run on: 03/25/2004 07:00:00
Next Run on: 03/25/2004 15:00:00
Next Run on: 03/26/2004 07:00:00
Next Run on: 03/26/2004 15:00:00
위 결과로 미루어 설정된 내용에 문제가 없음을 확인할 수 있습니다.
작업과 프로그램의 연계
위의 사례는 특정 프로그램과 연결되지 않은 작업을 생성하는 방법을 설명하고 있습니다. 이번에는 특정 OS 유틸리티를 사용하는 프로그램을 생성하고, 실행 주기를 정의한 스케줄을 설정한 뒤, 이 두 가지를 조합하여 새로운 작업을 생성하는 방법을 설명합니다.
먼저 작업 내에서 프로그램을 사용한다는 사실을 데이타베이스가 인지하도록 해야 합니다. 이 프로그램을 생성하려면, CREATE JOB 권한을 갖고 있어야 합니다.
begin
dbms_scheduler.create_program
(
program_name => 'MOVE_ARCS',
program_type => 'EXECUTABLE',
program_action => '/home/arup/dbtools/move_arcs.sh',
enabled => TRUE,
comments => 'Moving Archived Logs to Staging Directory'
);
end;
/
이제 named program unit을 생성하여, 그 유형을 “executable”로 지정하고 실행될 program unit의 이름을 정의하였습니다.
다음으로, 매 30분 간격으로 실행되는 EVERY_30_MIN이라는 이름의 스케줄을 생성합니다:
begin
dbms_scheduler.create_schedule
(
schedule_name => 'EVERY_30_MINS',
repeat_interval => 'FREQ=MINUTELY; INTERVAL=30',
comments => 'Every 30-mins'
);
end;
/
프로그램과 스케줄을 생성한 뒤, 이 두 가지를 연관시킴으로써 새로운 작업을 생성합니다.
begin
dbms_scheduler.create_job
(
job_name => 'ARC_MOVE',
program_name => 'MOVE_ARCS',
schedule_name => 'EVERY_30_MINS',
comments => 'Move Archived Logs to a Different Directory',
enabled => TRUE
);
end;
/
이제 매 30분마다 move_arcs.sh 셸 스크립트를 실행하는 작업이 생성되었습니다. 이 스케줄은 데이타베이스 내부의 Scheduler 기능을 통해 관리되며, 따라서 cron 또는 AT 유틸리티를 사용할 필요가 없습니다.
Classes, Plans, and Windows
작업 스케줄링 시스템에 효과적으로 활용하려면 작업의 우선순위 지정이 가능해야 합니다. 예를 들어 OLTP 워크로드가 실행 중인 시간대에 통계 수집 작업이 갑자기 실행되어 성능을 저하시킬 수 있습니다. 통계 수집 작업이 OLTP 성능에 영향을 미치지 않도록 하기 위해, Scheduler가 제공하는 job classes, resource plans, and Scheduler Windows기능을 활용할 수 있습니다.
Job class는 할당된 자원을 공유하는 “resource consumer group”으로 매핑됩니다. Job class를 생성하기 위해, 먼저 OLTP_GROUP이라는 이름의 resource consumer group을 정의해 보겠습니다.
begin
dbms_resource_manager.clear_pending_area();
dbms_resource_manager.create_pending_area();
dbms_resource_manager.create_consumer_group (
consumer_group => 'oltp_group',
comment => 'OLTP Activity Group'
);
dbms_resource_manager.submit_pending_area();
end;
/
다음에는 resource plan을 생성합니다.
begin
dbms_resource_manager.clear_pending_area();
dbms_resource_manager.create_pending_area();
dbms_resource_manager.create_plan
('OLTP_PLAN', 'OLTP Database Activity Plan');
dbms_resource_manager.create_plan_directive(
plan => 'OLTP_PLAN',
group_or_subplan => 'OLTP_GROUP',
comment => 'This is the OLTP Plan',
cpu_p1 => 80, cpu_p2 => NULL, cpu_p3 => NULL, cpu_p4 => NULL,
cpu_p5 => NULL, cpu_p6 => NULL, cpu_p7 => NULL, cpu_p8 => NULL,
parallel_degree_limit_p1 => 4,
active_sess_pool_p1 => NULL,
queueing_p1 => NULL,
switch_group => 'OTHER_GROUPS',
switch_time => 10,
switch_estimate => true,
max_est_exec_time => 10,
undo_pool => 500,
max_idle_time => NULL,
max_idle_blocker_time => NULL,
switch_time_in_call => NULL
);
dbms_resource_manager.create_plan_directive(
plan => 'OLTP_PLAN',
group_or_subplan => 'OTHER_GROUPS',
comment => NULL,
cpu_p1 => 20, cpu_p2 => NULL, cpu_p3 => NULL, cpu_p4 => NULL,
cpu_p5 => NULL, cpu_p6 => NULL, cpu_p7 => NULL, cpu_p8 => NULL,
parallel_degree_limit_p1 => 0,
active_sess_pool_p1 => 0,
queueing_p1 => 0,
switch_group => NULL,
switch_time => NULL,
switch_estimate => false,
max_est_exec_time => 0,
undo_pool => 10,
max_idle_time => NULL,
max_idle_blocker_time => NULL,
switch_time_in_call => NULL
);
dbms_resource_manager.submit_pending_area();
end;
/
마지막으로 앞에서 생성된 resource consumer group을 이용해 job class를 생성합니다.
begin
dbms_scheduler.create_job_class(
job_class_name => 'OLTP_JOBS',
logging_level => DBMS_SCHEDULER.LOGGING_FULL,
log_history => 45,
resource_consumer_group => 'OLTP_GROUP',
comments => 'OLTP Related Jobs'
);
end;
/
이 프로시저에서 사용된 매개변수들을 설명해 보겠습니다. LOGGING_LEVEL 매개변수는 해당 job class를 위해 얼마나 많은 로그 데이타를 기록할 것인지 정의하는데 사용됩니다. LOGGING_FULL은 job class에 포함된 작업의 모든 활동(생성, 삭제, 실행, 변경 등)을 로그에 기록함을 의미합니다. 로그는 DBA_SCHEDULER_JOB_LOG 뷰를 통해 확인할 수 있으며, LOG_HISTORY 매개변수에 저장된 대로 45일간 보관됩니다 (디폴트 값은 30일입니다). 이 class와 연관된 resource_consumer_group 도 정의되어 있습니다. DBA_SCHEDULER_JOB_CLASSES 뷰를 통해 정의된 job class들을 확인할 수 있습니다.
작업을 생성하는 과정에서, 필요한 경우 해당 작업을 job class에 할당할 수 있습니다. 예를 들어 collect_opt_stats() 저장 프로시저를 실행하여 옵티마이저 통계를 수집하는 COLLECT_STATS 작업을 생성하면서, 아래와 같이 job class를 할당할 수 있습니다.
begin
dbms_scheduler.create_job
(
job_name => 'COLLECT_STATS',
job_type => 'STORED_PROCEDURE',
job_action => 'collect_opt_stats',
job_class => 'OLTP_JOBS',
repeat_interval => 'FREQ=WEEKLY; INTERVAL=1',
enabled => true,
comments => 'Collect Optimizer Stats'
);
end;
/
위 명령을 실행하면 생성된 작업이 OLTP_JOBS 클래스에 할당됩니다. OLTP_JOBS 클래스에 적용되는 OLTP_GROUP resource plan을 통해 프로세스에 할당되는 CPU 자원, 다른 그룹으로 전환되기 전에 최대 실행 가능한 횟수, 전환되는 그룹 등을 설정할 수 있습니다. 동일한 job class에 할당된 작업은 동일한 resource plan의 적용을 받습니다. 이 기능을 활용하면 서로 다른 유형의 작업이 같은 리소스를 두고 경합을 벌이는 상황을 방지할 수 있습니다.
Scheduler Window는 특정 resource plan이 사용되는 시간대를 의미합니다. 예를 들어, 실시간 의사결정 작업에 관련한 업데이트 배치 작업이 주간에는 높은 우선순위를 갖는 반면 야간에는 낮은 우선순위를 갖는다고 가정해 봅시다. 이 경우 시간대별로 다른 resource plan을 정의하고, 정의된 내용을 Scheduler Window를 이용해 적용할 수 있습니다.
모니터링
실행 중인 작업의 상태는 DBA_SCHEDULER_JOB_LOG 뷰를 통해 확인할 수 있습니다. 이 뷰의 STATUS 컬럼은 작업의 현재 상태를 표시하는데 사용됩니다. 만일 STATUS 컬럼이 FAILED로 표시된다면, DBA_SCHEDULER_JOB_RUNS_DETAILS 뷰를 통해 그 원인을 확인할 수 있습니다.
관리
지금까지 여러 가지 유형의 오브젝트(program, schedule, job, job class 등)를 생성하는 방법에 대해 설명했습니다. 이렇게 생성된 오브젝트를 변경할 필요가 있다면, DBMS_SCHEDULER 패키지가 제공하는 API를 사용하면 됩니다.
Enterprise Manager 10g 홈 페이지에서 Administration 링크를 클릭하면, 그림 1과 같이 Administration 화면이 표시됩니다. Scheduler와 관련된 작업은 우측 하단의 “Scheduler” 항목에 표시됩니다 (그림의 붉은색 원 참조).
그림 1: Administration 페이지
이 페이지에서 제공되는 하이퍼링크를 활용하면 작업의 생성, 삭제, 관리와 같은 Scheduler 관련 작업을 쉽게 수행할 수 있습니다. 몇 가지 예를 들어 설명해 보겠습니다. 이미 작업을 생성해 둔 상태이므로, Job 탭을 클릭하면 그림 2와 같은 화면이 표시될 것입니다.
그림 2: 작업 스케줄의 확인
COLLECT_STATS 작업을 클릭하여 그 속성을 변경해 보도록 합시다. “Name” 필드를 클릭하면 그림 3과 같은 화면이 표시됩니다.
그림 3: 작업 매개변수
지금까지 확인한 것처럼, EM을 이용하면 작업, 스케줄, 옵션 등에 관련한 매개변수를 수정할 수 있습니다. 변경 작업을 완료한 뒤 “Apply” 버튼을 누르면 변경사항은 영구적으로 적용됩니다. “Apply” 버튼을 누르기 전에 “Show SQL” 버튼을 눌러 실행되는 SQL 구문을 확인하는 것도 가능합니다. 또 SQL 구문을 스크립트에 저장하여 나중에 실행하거나, 템플릿 용도로 활용할 수도 있습니다.
결론
Oracle Database 10g의 Scheduler는 dbms_job 인터페이스보다 훨씬 향상된 기능을 제공합니다. Scheduler에 대한 상세한 정보는 Oracle Database Administrator's Guide의 Chapter 25를 확인하시기 바랍니다.
제 20 주
그 밖의 유용한 기능
지금까지 소개한 기능 이외에도, Oracle Database 10g는 통계 자동 수집, undo 데이타 보존기간(undo retention)의 “guarantee”, 더욱 쉽고 강력해진 암호화 패키지 등의 유용한 기능을 제공합니다.
드디어 우리의 긴 여행도 막바지에 이르렀습니다. 지난 19주 동안 DBA의 작업을 쉽고 편하게 해 주는 다양한 툴, 팁, 테크닉을 소개해 드렸습니다.
지금까지 Oracle Database 10g의 특출한 기능이라 하더라도 DBA에게 많은 도움이 되지 않는다면 소개하지 않는 것을 원칙으로 했습니다. 마지막 연재도 Oracle 10g의 모든 기능을 섭렵하기에는 지면이 충분하지 않습니다. 이제 그간의 연재를 마무리하면서, 언급될 가치가 있는 Oracle 10g의 중요한 기능을 몇 가지 골라 소개하려 합니다.
자동적인 통계 수집
이미 많은 분들이 알고 계시겠지만, Oracle 10g에 오면서 마침내 Rules-Based Optimized(RBO)는 더 이상 지원되지 않는 (기능은 남아있지만) 것으로 결정되었습니다. Oracle9i Database를 사용하는 IT 조직은 Cost-Based Optimizer(CBO) 환경으로 업그레이드함으로써 계속적인 기술지원을 받을 수 있을 뿐 아니라 query rewrite, partition pruning과 같은 고급 기능을 활용할 수 있게 됩니다. 하지만 이 경우 통계(statistics)가 (정확히 말하면 통계의 부재가) 문제가 됩니다.
CBO가 최적의 실행 경로를 생성하려면 정확한 통계를 필요로 하며, DBA는 통계가 정기적으로 수집될 수 있도록 데이타베이스를 관리해야 합니다. 10g 이전의 환경에서는 (여러 가지 이유 때문에) 정확한 통계의 수집을 위한 DBA의 노력이 수포로 돌아가는 경우가 허다했습니다. 이러한 문제 때문에 CBO가 “제멋대로 동작한다”는, 다시 말해 임의적으로 실행 경로를 바꾸곤 한다는 이론이 제기되기도 했습니다.
10g는 통계의 자동적인 수집 기능을 제공하며, 따라서 이와 같은 문제를 상당부분 해결하였습니다. Oracle9i의 경우 테이블의 데이타가 얼마나 변경되었는지 확인하기 위해서는 테이블의 모니터링 옵션을 활성화하고 (ALTER TABLE... MONITORING) 해당 테이블에 대한 DBA_TAB_MODIFICATIONS 뷰를 조회해야 했습니다.
10g에서는 MONITORING 키워드가 사라진 대신, 초기화 매개변수 STATISTICS_LEVEL을 TYPICAL 또는 ALL로 설정함으로써 통계 수집을 자동화하는 기능을 제공합니다. (디폴트 값은 TYPICAL이며, 따라서 데이타베이스 설치 후 바로 통계 수집 작업이 자동 수행됩니다.) Oracle Database 10g는 사전 정의된 Scheduler (Scheduler에 대해서는 제 19 주에 설명했습니다) 작업 GATHER_STATS_JOB을 통해 통계 수집을 수행합니다. 이 작업은 STATISTICS_LEVEL 매개변수 값에 의해 활성화됩니다.
통계 수집 작업은 매우 많은 자원을 소모합니다. 따라서 이 작업으로 인해 운영 중인 애플리케이션의 성능이 저하되지 않음을 보장할 수 있어야 합니다. 10g는 통계 수집과 같은 자동 수행 작업을 위해 special resource consumer group인 AUTO_TASK_CONSUMER_GROUP을 정의하고 있습니다. 이 consumer group이 수행하는 작업은 디폴트 consumer group에 비해 낮은 우선순위를 가지며, 따라서 자동 수행되는 작업이 시스템의 성능을 저하시킬 가능성을 줄일 수 있습니다.
STATISTICS_LEVEL을 TYPICAL로 설정한 상태에서 통계가 자동 수집되지 않게 하려면 어떻게 해야 할까요? 간단합니다. 아래와 같은 명령을 사용하여 Scheduler 작업을 비활성화하면 됩니다.
BEGIN
DBMS_SCHEDULER.DISABLE('GATHER_STATS_JOB');
END;
그렇다면 굳이 이렇게 할 설정할 필요가 있을까요? 여러 가지 이유로 이러한 설정이 필요한 상황이 있을 수 있습니다. 첫 번째로 테이블 내의 많은 레코드가 변경되었지만 데이타의 분포는 변하지 않은 경우를 들 수 있습니다 (데이타 웨어하우스 환경에서 이러한 경우가 많이 발견됩니다). 이 경우 통계를 다시 수집할 필요가 없으며 이전의 통계를 그대로 사용해도 무방합니다. 두 번째로 partition exchange를 이용하여 materialized view(MV)를 refresh하는 환경에서도, exchanged table의 통계를 임포트해서 사용하므로 MV에 대한 통계에 대해 별도의 수집을 원치 않을 경우입니다. 또 전체 통계 수집 작업을 중단하는 대신, 특정 테이블에 대한 자동 통계 수집만을 선택적으로 비활성화하는 것도 가능합니다.
통계 히스토리
옵티마이저 통계 수집 과정에서 문제가 될 수 있는 상황의 하나로 execution plan이 변경되는 경우를 들 수 있습니다. 새로운 통계가 수집되기 전까지 정상적으로 수행되던 쿼리가, 새로운 통계를 기반으로 생성된 execution plan으로 인해 오히려 성능이 악화될 수 있습니다. 이러한 문제는 실제로 빈번하게 발생합니다.
이러한 문제를 방지하기 위해서는, 새로운 통계를 수집하기 전에 현재 통계 정보를 저장합니다. 이와 같이 함으로써, 문제가 생겼을 때 바로 예전의 통계로 복구하거나, 두 통계의 차이점을 분석해서 원인을 확인할 수 있습니다.
예를 들어 REVENUE 테이블에 대한 통계 수집 작업이 5월 31일 오후 10시에 실행된 이후 쿼리 성능이 악화되었다고 가정해 봅시다. 아래 명령을 사용하여 Oracle이 저장한 이전 통계로 복구될 수 있습니다.
begin
dbms_stats.restore_table_stats (
'ARUP',
'REVENUE',
'31-MAY-04 10.00.00.000000000 PM -04:00');
end;
위 명령은 (TIMESTAMP 데이타 타입을 통해 명시한 대로) 5월 31일 오후 10시 시점을 기준으로 통계를 복구합니다. 이와 같이 함으로써 새로운 통계로 인해 발생한 문제를 해결할 수 있습니다.
복구에 이용할 수 있는 과거 통계의 보존 기간은 매개변수를 통해 설정할 수 있습니다. 현재 설정된 보존 기간을 확인하려면 아래와 같이 질의합니다:
SQL> select DBMS_STATS.GET_STATS_HISTORY_RETENTION from dual;
GET_STATS_HISTORY_RETENTION
---------------------------
31
위 결과를 통해 31일간의 통계 정보를 보존할 수 있습니다. 단 이 기간이 반드시 보장되는 것은 아닙니다. 복구 가능한 정확한 시점을 확인하려면 아래와 같이 입력합니다:
SQL> select DBMS_STATS.GET_STATS_HISTORY_AVAILABILITY from dual;
GET_STATS_HISTORY_AVAILABILITY
---------------------------------------------------------------------
17-MAY-04 03.21.33.594053000 PM -04:00
위 결과는 현재 가장 오래된 통계가 5월 17일 오전 3시 21분에 생성된 것임을 알려주고 있습니다.
내장 함수를 이용하여 통계의 보존 기간을 변경할 수 있습니다. 보존 기간을 45일로 변경하려면 다음과 같이 입력합니다:
execute DBMS_STATS.ALTER_STATS_HISTORY_RETENTION (45)
Guaranteed Undo Retention
Oracle9i에서 처음 소개된 Automatic Undo Retention 기능은 ORA-1555 “Snapshot Too Old” 에러가 발생할 가능성을 상당 수준 줄여줍니다. 하지만 이 에러는 (많이 줄어들기는 했지만) 여전히 발생하고 있습니다. 왜일까요?
이 질문에 대답하기 위해서는, 먼저 undo segment가 동작하는 원리를 이해해야 합니다. 오라클 데이타베이스의 데이타가 변경되면, (SGA 내부의) 캐시에 있는 블록이 즉각적으로 변경되면서, 기존의 데이타 이미지(past image)는 undo segment에 저장됩니다. 트랜잭션이 커밋 되면, 기존의 이미지는 더 이상 불필요하며, 따라서 삭제가 가능합니다. 하지만 Undo segment의 모든 공간이 액티브 트랜잭션에 의해 사용되고 있다면 세그먼트 내에서 가장 오래된 익스텐트(extent)에 덮어 쓰기를 시도합니다 (이 과정을 “wrapping”이라 부르기도 하며, V$ROLLSTAT 뷰의 WRAPS 컬럼을 통해 확인됩니다). 하지만, 롱-러닝 트랜잭션(long-running transaction)이 사용되는 경우와 같은 특별한 상황에서, 데이타베이스는 액티브 트랜잭션을 위해 세그먼트를 확장하기도 합니다 (V$ROLLSTAT 뷰의 EXTENDS 컬럼을 통해 확인됩니다). 쿼리가 데이터의 일관성을 보장하기 위해서 undo segment의 익스텐트(extent)에 저장된 이미지를 요구했지만 해당 익스텐트가 이미 재사용된 경우, 쿼리는 ORA-1555 에러를 발생시킵니다.
초기화 매개변수 UNDO_RETENTION을 통해 undo 데이타가 보존되는 기간을 (초 단위로) 설정할 수 있습니다. 이처럼 보존 기간을 설정함으로써, inactive 상태의 undo extent라 하더라도 일정 기간 삭제되지 않음을 보장할 수 있습니다. 이 방법을 사용하면 inactive 상태의 익스텐트(extent)가 재사용되는 상황을 예방하고, 따라서 ORA-1555 에러가 발생할 가능성을 줄일 수 있습니다.
하지만 UNDO_RETENTION 매개변수로 ORA-1555의 발생 가능성을 근본적으로 제거할 수는 없습니다. 세그먼트의 확장이 불가능한 경우, 데이타베이스는 가장 오래된 inactive 익스텐트를 강제로 재사용합니다. 따라서 일부 롱-러닝 트랜잭션으로부터 ORA-1555 에러가 발생할 가능성은 상존합니다.
10g에서는 이러한 문제가 해결되었습니다. 이제는 undo 테이블스페이스를 생성하면서 undo retention “guarantee”를 설정할 수 있습니다. 그 예가 아래와 같습니다:
CREATE UNDO TABLESPACE UNDO_TS1
DATAFILE '/u01/oradata/proddb01/undo_ts1_01.dbf'
SIZE 1024M
RETENTION GUARANTEE;
마지막 부분의 “RETENTION GUARANTEE”는 undo tablespace로 하여금 만료되지 않은 undo 익스텐트의 보존을 “보장”하도록 설정합니다. 기존 undo tablespace는 ALTER 구문을 이용하여 아래와 같이 수정할 수 있습니다:
ALTER TABLESPACE UNDO_TS2 RETENTION GUARANTEE;
익스텐트의 보존을 “보장”하는 것을 원치 않는 경우(Oracle 9i 방식)에는 다음과 같이 입력합니다:
ALTER TABLESPACE UNDO_TS2 RETENTION NOGUARANTEE;
테이블스페이스에 undo retention이 “guarantee” 되고 있는지의 여부는 아래와 같이 확인할 수 있습니다.
SELECT RETENTION
FROM DBA_TABLESPACES
WHERE TABLESPACE_NAME = 'UNDO_TS1';
End-to-End Tracing
성능 문제를 진단하기 위한 방법의 하나로, sql_trace를 활성화하여 데이타베이스 쿼리를 추적하고 tkprof와 같은 툴을 사용하여 그 결과를 분석하는 방법이 자주 사용됩니다. 하지만, 이 방법은 공유 서버(Shared Server) 아키텍처 상에 구현된 데이타베이스 환경에서는 그 유용성이 심각하게 제한됩니다. 이러한 경우 사용자의 요구사항을 처리하기 위해서 여려 공유서버 프로세스(shared server process)들이 생성됩니다. 사용자 BILL이 데이타베이스에 접근하려는 경우, dispatcher는 사용 가능한 공유 서버 중 하나와 사용자를 연결합니다. 현재 사용 가능한 서버가 존재하지 않는 경우, 새로운 공유 서버가 생성됩니다. 이 세션이 트레이스(trace) 작업을 시작하면, 해당 공유 서버의 프로세스에 의해 호출된 작업들의 트레이스가 수행됩니다.
이제 BILL의 세션이 idle 상태가 되고 LORA의 세션이 active 상태가 되었다고 가정합시다. BILL에게 서비스를 제공하던 공유 서버는 LORA의 세션에 할당되었습니다. 이 시점 이후의 트레이스 정보는 BILL의 세션이 아닌 LORA의 세션을 추적합니다. LORA의 세션이 inactive 상태가 되면, 공유 서버는 다른 active 세션에 할당되며, 다시 BILL 또는 LORA의 세션과는 전혀 무관한 트레이스정보를 만들어 냅니다.
10g에서는 end-to-end tracing 기능을 통해 이러한 문제를 해결하였습니다. 10g에서의 트레이스 작업은 세션 단위로 수행되지 않고 client identifier와 같은 정보를 기준으로 수행됩니다. 새로 추가된 DBMS_MONITOR 패키지가 바로 이러한 목적을 위해 사용됩니다.
예를 들어, identifier “account_update”를 갖는 모든 세션을 트레이스하려는 경우를 가정해 봅시다. 먼저 트레이스를 설정하기 위해서 아래와 같이 입력합니다:
exec DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE('account_update');
위 명령은 “account_update”를 identifier로 하는 모든 세션에 대한 트레이스 작업을 활성화합니다. 데이타베이스에 연결하는 과정에서, BILL은 다음과 같은 명령을 통해 client identifier를 설정합니다:
exec DBMS_SESSION.SET_IDENTIFIER ('account_update')
“account_update”를 identifier로 하는 모든 세션을 트레이스 하도록 설정된 상황이므로, 위의 세션 역시 트레이스 되고 user dump destination 디렉토리에 트레이스 파일(trace file)이 생성됩니다. 다른 사용자가 데이타베이스에 연결하면서 client identifier를 “account_update”로 설정하는 경우, 새로운 세션 역시 자동으로 트레이스 됩니다. 결국 아래와 같은 명령을 통해 트레이스를 disable할 때까지, “account_update”를 client identifier로 하는 모든 세션이 트레이스 됩니다:
exec DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE('account_update');
생성된 트레이스 파일은 tkprof 툴을 통해 분석할 수 있습니다. 하지만 각각의 세션이 별도의 트레이스 파일을 생성하는 문제가 있습니다. 문제를 효과적으로 분석하려면, 통합된 형태의 트레이스 파일이 필요할 것입니다.
trcsess 툴을 이용하면 “account_update”를 client identifier로 하는 모든 세션의 트레이스 정보를 추출하여 하나의 파일에 저장할 수 있습니다. 트레이스 정보를 통합하려면 user dump destination 디렉토리로 이동하여 다음과 같이 실행합니다:
trcsess output=account_update_trc.txt clientid=account_update *
위 명령을 실행하면 account_update_trc.txt 파일이 생성됩니다. 이 파일은 일반적인 트레이스 파일과 같은 포맷을 가지며, tkprof 툴을 이용하여 분석될 수 있습니다.
이처럼 end-to-end tracing 기능을 활용하여 트레이스 정보를 보다 쉽게 수집할 수 있습니다. 또 세션 별로 alter session set sql_trace = true 명령을 사용하는 대신, client identifier를 기준으로 트레이스를 enable/disable할 수 있습니다. 같은 패키지를 통해 제공되는 SERV_MOD_ACT_TRACE_ENABLE 프로시저를 사용하면 dbms_application_info패키지를 이용해서 설정된 특정 서비스, 모듈, 또는 액션의 조합으로 트레이스를 수행하는 것도 가능합니다.
데이타베이스 사용 현황
오라클 데이타베이스의 파티셔닝(partitioning) 기능은 별도로 구매해야 하는 옵션입니다. 요즘처럼 예산이 제한되는 상황에서는, 구입을 결정하기 전에 파티셔닝이 정말로 사용자에게 효과적으로 활용되고 있는지 먼저 고민하지 않을 수 없습니다.
이 질문을 사용자에게 던지는 대신 데이타베이스에게 물어보십시오. Automatic Workload Repository(제 6 주 연재에서 설명한 바 있습니다)는 설치된 모든 기능의 사용 정보를 1주 1회의 단위로 수집합니다.
데이타베이스의 사용 패턴을 보여주는 중요한 뷰가 두 가지 존재합니다. 첫 번째로, DBA_HIGH_WATER_MARK_STATISTICS 뷰는 현재 데이타베이스에 사용되는 각 기능의 최대값을 보여줍니다. 실행 결과의 예가 아래와 같습니다.
NAME HIGHWATER LAST_VALUE DESCRIPTION
--------------- ---------- ---------- ----------------------------------------------------------
USER_TABLES 401 401 Number of User Tables
SEGMENT_SIZE 1237319680 1237319680 Size of Largest Segment (Bytes)
PART_TABLES 12 0 Maximum Number of Partitions belonging to an User Table
PART_INDEXES 12 0 Maximum Number of Partitions belonging to an User Index
USER_INDEXES 832 832 Number of User Indexes
SESSIONS 19 17 Maximum Number of Concurrent Sessions seen in the database
DB_SIZE 7940079616 7940079616 Maximum Size of the Database (Bytes)
DATAFILES 6 6 Maximum Number of Datafiles
TABLESPACES 7 7 Maximum Number of Tablespaces
CPU_COUNT 4 4 Maximum Number of CPUs
QUERY_LENGTH 1176 1176 Maximum Query Length
위에서 확인할 수 있는 것처럼, 이 뷰는 데이타베이스의 사용 패턴에 대한 몇 가지 중요한 정보를 제공합니다. 예를 들어 사용자가 최대 12 개의 partitioned table을 생성했지만, 현재는 하나도 사용되고 있지 않음(LAST_VALUE = 0)을 확인할 수 있습니다. 이 정보는 데이타베이스가 셧다운 되는 경우에도 그대로 유지되며, 마이그레이션 작업을 위한 계획 단계에서 매우 유용하게 활용될 수 있습니다.
하지만 위의 뷰가 제공하는 정보만으로는 부족한 부분이 있습니다. 위 결과를 통해 12개의 partitioned table이 생성되었다는 것을 확인할 수 있지만 이 기능이 마지막으로 사용된 시간은 알 수 없습니다. DBA_FEATURE_USAGE_STATISTICS 뷰를 사용하면 이러한 문제의 해답을 쉽게 찾을 수 있습니다. 파티셔닝 기능에 관련한 뷰의 조회 결과가 아래와 같습니다:
DBID : 4133493568
NAME : Partitioning
VERSION : 10.1.0.1.0
DETECTED_USAGES : 12
TOTAL_SAMPLES : 12
CURRENTLY_USED : FALSE
FIRST_USAGE_DATE : 16-oct-2003 13:27:10
LAST_USAGE_DATE : 16-dec-2003 21:20:58
AUX_COUNT :
FEATURE_INFO :
LAST_SAMPLE_DATE : 23-dec-2003 21:20:58
LAST_SAMPLE_PERIOD : 615836
SAMPLE_INTERVAL : 604800
DESCRIPTION : Oracle Partitioning option is being used -
there is at least one partitioned object created.
이 뷰를 통해 파티셔닝 기능이 현재 데이타베이스에서 사용되지 않고 있으며 (CURRENTLY_USED : FALSE), 마지막으로 액세스된 시간이 2003년 12월 16일 오후 9시 20분임을 알 수 있습니다. 사용 현황 정보의 샘플링은 매 604,800초 (7일) 단위로 수행되고 있습니다 (SAMPLE_INTERVAL 컬럼). 그리고 LAST_SAMPLE_DATE 컬럼은 사용 현황 정보가 마지막으로 샘플링 된 시점을 표시하고 있습니다.
커맨드 라인 인터페이스 대신 Enterprise Manager 10g를 사용해서 같은 정보를 확인할 수도 있습니다. 이를 위해 EM에서 Administration 탭으로 이동 한 후 Configuration Management 항목 아래의 “Database Usage Statistics” 링크를 클릭합니다 (그림 1과 2 참조).
그림 1: Database Usage Statistics 페이지
그림 2: Database Usage Statistics – 기능별 드릴다운
더 쉽고 강력해진 암호화 옵션
DBMS_OBFUSCATION_TOOLKIT (DOTK) 패키지를 기억하십니까? Oracle9i 및 이전 버전에서 암호화를 적용하려면 이 패키지를 사용하는 것 이외에 다른 대안이 없었습니다. DOTK 패키지는 대부분의 보안제품처럼 대부분의 데이타베이스 환경에 적절한 수준의 보안 환경을 제공했지만, 숙련된 해커의 공격에 쉽게 무력화되는 약점이 있었습니다. DOTK 패키지에 결여된 중요한 기능의 하나로, 기존의 DES(Digital Encryption Standard) 및 DES3 (Triple DES)보다 강력한 암호화 기능을 제공하는 Advanced Encryption Standard(AES)를 들 수 있습니다.
10g에는 보다 강력한 암호화 패키지인 DBMS_CRYPTO가 추가되었습니다. 이 내장 패키지는 DOTK에 구현되지 않은 암호화 기능을 모두 포함하고 있을 뿐 아니라, 기존 함수와 프로시저에 대해서도 보다 개선된 기능을 제공합니다. (한 예로, DBMS_CRYPTO에는 최신 암호화 기술인 256 비트 AES 알고리즘이 포함되어 있습니다.) DBMS_CRYPTO의 ENCRYPT 함수(프로시저로도 사용됩니다)는 아래와 같은 매개변수를 사용합니다:
매개변수 설명
SRC 암호화 대상이 되는 입력 데이타입니다. RAW 데이타 타입만을 지원하며, 다른 데이타 타입의 경우 먼저 변환 과정을 거쳐야 합니다. character 변수 p_in_val에 대해 변환작업을 수행하려면 다음과 같이 실행합니다:
utl_i18n.string_to_raw (p_in_val, 'AL32UTF8');
문자열을 character set AL32UTF8, 데이타 타입RAW로 변환하기 위해 UTL_IL8N 패키지가 사용됩니다. DOTK와 달리, DBMS_CRYPTO는 character 변수를 매개변수로 사용하지 않습니다. 또 DOTK 패키지에서 요구하던 것처럼, character에 대한 padding을 수행하여 그 길이를 16의 배수로 만들 필요가 없습니다. ENCRYPT 함수(또는 프로시저)는 자동으로 padding을 수행합니다.
KEY 암호화 키를 정의합니다. 키의 길이는 사용되는 알고리즘에 따라 달라집니다.
TYP 암호화 타입과 padding 방법을 정의합니다. 예를 들어 AES 256-bit 알고리즘, Cipher Block Chaining, PKCS#5 padding을 사용하려는 경우 아래와 같이 입력합니다:
typ => dbms_cryptio.encrypt_aes256 +
dbms_cryptio.chain_cbc +
dbms_cryptio.pad_pkcs5
The ENCRYPT ENCRYPT 함수는 암호화된 값을 RAW 데이타 타입으로 반환합니다. 반환된 결과를 문자열로 변환하려면 아래와 같이 실행합니다:
utl_i18n.raw_to_char (l_enc_val, 'AL32UTF8')
which is the reverse of the casting to RAW.
암호화된 결과를 해독하려면 DECRYPT 함수(또는 프로시저로도 사용됩니다)를 사용합니다. 이처럼 DBMS_CRYPTO 패키지를 사용하여. 데이타베이스 환경에 개선된 보안 모델을 구현할 수 있습니다.
결론
Oracle Database 10g가 제공하는 새로운 기능을 모두 설명하는 것은 불가능에 가깝습니다. 하지만 지난 20주에 걸쳐, DBA에게 가장 중요한 의미를 갖는 일부 기능을 선별하여 소개했으며, 이번 주에는 지난 19주 동안 소개되지 않았던 몇 가지 기능을 마지막으로 설명해 드렸습니다. 이번 연재가 여러분에게 유익했기를 바랍니다. 의견이 있으신 경우 언제든 보내주시기 바라며, 여러분이 가장 마음에 들어 하는 기능이 어떤 것이었는지 알려주시면 제게 많은 참고가 될 것입니다.
물리적인 백업은 데이터베이스 파일(데이터 파일, 컨트롤 파일)을 백업하는 것을 뜻하며, DB가 아카이브 모드에서 수행중인 경우에는 아카이브 리두 로그 파일이 자동적으로 생성되므로 데이터 파일, 컨트롤 파일, 아카이브 리두 로그 파일이 백업된다.
물리적 백업은 다음과 같이 두 가지가 가능하다.
• 오프라인 백업 • 온라인 백업
이 백업은 데이터 파일의 크기가 매우 큰 경우, 많은 시간이 소요될 수 도 있다. 그래서 오프라인 백업을 whole-backup 또는 cold-backup이라 한다.
$ sqlplus system/manager as sysdba ☜ DBA로 접속 SQL> select name from v$controlfile; ☜ 컨트롤 파일의 위치를 확인 NAME -------------------------------------------------------------------------------- /export/home/oracle/app/oracle/oradata/orcl/control01.ctl /export/home/oracle/app/oracle/oradata/orcl/control02.ctl /export/home/oracle/app/oracle/oradata/orcl/control03.ctl SQL> select file_name from dba_data_files; ☜ 데이터 파일의 확인 FILE_NAME -------------------------------------------------------------------------------- /export/home/oracle/app/oracle/oradata/orcl/users01.dbf /export/home/oracle/app/oracle/oradata/orcl/sysaux01.dbf /export/home/oracle/app/oracle/oradata/orcl/undotbs01.dbf /export/home/oracle/app/oracle/oradata/orcl/system01.dbf SQL> select group#,member from v$logfile; ☜ 리두 로그 파일을 확인 GROUP# MEMBER ---------- ------------------------------------------------------------ 3 /export/home/oracle/app/oracle/oradata/orcl/redo03.log 2 /export/home/oracle/app/oracle/oradata/orcl/redo02.log 1 /export/home/oracle/app/oracle/oradata/orcl/redo01.log SQL> SQL> shutdown normal; ☜ normal, transaction, immediate중 하나로 DB를 종료 Database closed. Database dismounted. ORACLE instance shut down. SQL> ! ☜ 쉘 프롬프트로 일시 복귀함 $ su ☜ root의 권한을 가짐 Password: # cp /export/home/oracle/app/oracle/oradata/orcl/control0*.ctl /export/home/work/.
☜ 컨트롤 파일 복사 # cp /export/home/oracle/app/oracle/oradata/orcl/redo*.log /export/home/work/.
☜ 리두 로그 파일 복사 # cp /export/home/oracle/app/oracle/oradata/orcl/*.dbf /export/home/work/.
☜ 데이터 파일 복사 # cp dbs/*.ora /export/home/work/.
☜ 파라미터 파일 복사 # ls -l /export/home/work
☜ 복사되었나 확인 -rw-r----- 1 root other 2867200 Jan 4 11:07 control01.ctl -rw-r----- 1 root other 2867200 Jan 4 11:07 control02.ctl -rw-r----- 1 root other 2867200 Jan 4 11:07 control03.ctl -rw-r--r-- 1 root other 8384 Jan 4 11:14 init.ora -rw-r--r-- 1 root other 12920 Jan 4 11:14 initdw.ora -rw-r----- 1 root other 10486272 Jan 4 11:09 redo01.log -rw-r----- 1 root other 10486272 Jan 4 11:09 redo02.log -rw-r----- 1 root other 10486272 Jan 4 11:09 redo03.log -rw-r----- 1 root other 2560 Jan 4 11:14 spfileorcl.ora -rw-r----- 1 root other 461381632 Jan 4 11:10 sysaux01.dbf -rw-r----- 1 root other 471867392 Jan 4 11:11 system01.dbf -rw-r----- 1 root other 20979712 Jan 4 11:11 temp01.dbf -rw-r----- 1 root other 26222592 Jan 4 11:11 undotbs01.dbf -rw-r----- 1 root other 5251072 Jan 4 11:11 users01.dbf # exit ☜ root 권한에서 빠져나옴 $ exit ☜ 쉘프롬프트에서 오라클 프롬프트로 복귀 SQL> startup ☜ Instance 기동 ORACLE instance started. Total System Global Area 289406976 bytes Fixed Size 778796 bytes Variable Size 99360212 bytes Database Buffers 188743680 bytes Redo Buffers 524288 bytes Database mounted. Database opened. SQL>
다음과 같이 오프라인 자동 백업 스크립트를 작성하여 실행한다. 1단계 : 오라클 인스턴스 종료 $ORACLE_HOME/bin/sqlplus system/manager as sysdba SHUTDOWN IMMEDIATE EXIT 2단계 : 데이터베이스와 관련된 모든 물리적 파일 복사 cp /export/home/oracle/app/oracle/oradata/orcl/*.ctl backup/ cp /export/home/oracle/app/oracle/oradata/orcl/*.dbf backup/ cp /export/home/oracle/app/oracle/oradata/orcl/*.log backup/ cp /export/home/oracle/app/oracle/oradata/orcl/*.ora backup/ 3단계 : 데이터베이스 다시 시작 $ORACLE_HOME/bin/sqlplus system/manager as sysdba STARTUP EXIT EOF
$ sqlplus '/as sysdba' SQL> select tablespace_name, file_name from dba_data_files; TABLESPACE_NAME FILE_NAME --------------- ------------------------------------------------------------ USERS /export/home/oracle/app/oracle/oradata/orcl/users01.dbf SYSAUX /export/home/oracle/app/oracle/oradata/orcl/sysaux01.dbf UNDOTBS1 /export/home/oracle/app/oracle/oradata/orcl/undotbs01.dbf SYSTEM /export/home/oracle/app/oracle/oradata/orcl/system01.dbf SQL> alter tablespace users begin backup;☜ 테이블스페이스내의 모든 객체에 대해 변경된 데이터들이 데이터 파일에 적용되고, 메모리 영역과 리두 로그 파일에 일시적으로 저장된다.
Tablespace altered. SQL> ! $ cp /export/home/oracle/app/oracle/oradata/orcl/users01.dbf bkup/. $ ls -l bkup total 10272 -rw-r----- 1 oracle oinstall 5251072 Jan 4 14:07 users01.dbf $ exit SQL> alter tablespace users end backup;☜ 복사후 sql문을 실행하여 데이터파일에 저장되었던 변경된 데이터를 실제 데이터 파일에 반영한다.
Tablespace altered.
SQL>
SQL> ALTER SYSTEM SWITCH LOGFILE;
☜ 인위적으로 로그 스위치를 실행하여 모든 데이터 파일 헤더에 저장되어 있는
체크포인트 번호를 통합
System altered.
SQL>
논리적 백업은 DB내의 논리적 객체들을 백업하는 방법으로, EXPORT 유틸리티를 사용하여 백업하고, IMPORT 유틸리티를 사용하여 복구한다.
EXPORT와 IMPORT 유틸리티가 백업/복구 이외에 다른 기능은 다음과 같다.
• 특정 사용자의 객체를 다른 사용자의 공간으로 이동시킬 수 있다. • 운영체제가 다른 DB 사이에 데이터를 이동시킬 수 있다. • 테이블, 뷰,인덱스 등을 백업하고 다시 복구함으로써 객체들의 구조가 재생성되어 단편화(fragmentation)를 감소시킨다.익스포트에서 사용 가능한 키워드는 EXP 유틸리티를 참조하고
| 데이터베이스 전체모드 | 테이블스페이스 모드 | 사용자 모드 | 테이블 모드 |
|---|---|---|---|
| •모든 테이블의 데이터 •인덱스 •테이블의 제약조건 •트리거 •클러스트 •시퀀스 •스냅샷 •스토어드 프로시저 •시노늄 •뷰 •프로파일/롤 •audit | •지정된 테이블스페이스의 테이블 •테이블의 데이터 •인덱스 •테이블의 제약조건 •트리거 •클러스트 •시퀀스 •스냅샷 •스토어드 프로시저 •시노늄 •뷰 •프로파일/롤 •audit | •정의된 사용자의 테이블 •테이블의 데이터 •사용자의 권한 •사용자의 인덱스 •테이블의 제약조건 •테이블의 트리거 •클러스트 •데이터베이스 링크 •스냅샷 •스토어드 프로시저 •시노늄 •뷰 | •정의된 사용자의 테이블 •테이블의 데이터 •사용자의 권한 •사용자의 인덱스 •테이블의 제약조건 •트리거 |
• 컨트롤 파일 뿐만 아니라 모든 데이터 파일을 복사하는 운영체제가 제공하는 유틸리티 • RMAN BACKUP DATABASE 명령어 • 데이터베이스 내의 각 데이터 파일에 대해 수행되는 RMAN COPY DATAFILE 명령어와 컨트롤 파일에 대해 실행되는 COPY CURRENT CONTROLFILE 명령어
SQL> select log_mode from v$database; ☜ 현제 DB의 아카이브 모드 확인 SQL> alter database archivelog; ☜ DB의 모드를 아카이브모드로 전환
1) 온라인 테이블스페이스 백업하기
테이블스페이스 백업은 테이블스페이스를 구성하는 데이터 파일을 백업하는 것으로, DB가 아카이브모드라면, 온라인 또는 오프라인 상태에서도 가능하다.
SQL> select tablespace_name, file_name from dba_data_files; TABLESPACE_NAME FILE_NAME --------------- ------------------------------------------------------------ USERS /export/home/oracle/app/oracle/oradata/orcl/users01.dbf SYSAUX /export/home/oracle/app/oracle/oradata/orcl/sysaux01.dbf UNDOTBS1 /export/home/oracle/app/oracle/oradata/orcl/undotbs01.dbf SYSTEM /export/home/oracle/app/oracle/oradata/orcl/system01.dbf SQL> alter tablespace users begin backup;2) 오프라인 테이블스페이스 백업하기
☜ users 테이블스페이스에 대해 백업 시작을 알림 Tablespace altered. SQL> ! $ cp /export/home/oracle/app/oracle/oradata/orcl/users01.dbf bkup/. $ exit SQL> alter tablespace users end backup;
☜ users 테이블스페이스에 대해 백업 종료를 알림 Tablespace altered. SQL> select * from v$backup; FILE# STATUS CHANGE# TIME ---------- ------------------ ---------- ------------ 1 NOT ACTIVE 0 2 NOT ACTIVE 0 3 NOT ACTIVE 0 4 NOT ACTIVE 2858563 04-JAN-06 SQL>
SQL> select tablespace_name, file_name from dba_data_files; TABLESPACE_NAME FILE_NAME --------------- ------------------------------------------------------------ USERS /export/home/oracle/app/oracle/oradata/orcl/users01.dbf SYSAUX /export/home/oracle/app/oracle/oradata/orcl/sysaux01.dbf UNDOTBS1 /export/home/oracle/app/oracle/oradata/orcl/undotbs01.dbf SYSTEM /export/home/oracle/app/oracle/oradata/orcl/system01.dbf SQL> alter tablespace users offline normal; Tablespace altered. SQL> ! $ cp /export/home/oracle/app/oracle/oradata/orcl/users01.dbf bkup/. $ exit SQL> alter tablespace users online; Tablespace altered. SQL>
SQL> select * from v$controlfile;
STATUS NAME IS_
------- ------------------------------------------------------------ ---
/export/home/oracle/app/oracle/oradata/orcl/control01.ctl NO
/export/home/oracle/app/oracle/oradata/orcl/control02.ctl NO
/export/home/oracle/app/oracle/oradata/orcl/control03.ctl NO
SQL>
컨트롤 파일을 백업하는 세가지 방법SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> ! $ cp /export/home/oracle/app/oracle/oradata/orcl/*.ctl bkup/. $ $ ls dbs/*.ora dbs/init.ora dbs/initdw.ora dbs/spfileorcl.ora initDB명.ore 파일에 복사된 컨트롤 파일을 추가 한다. ... CONTROL_FILES=(control01.ctl,..,control04.ctl) ... $ exit SQL> startup ORACLE instance started. Total System Global Area 289406976 bytes Fixed Size 778796 bytes Variable Size 99360212 bytes Database Buffers 188743680 bytes Redo Buffers 524288 bytes Database mounted. Database opened. SQL>방법2) spfile을 사용한 컨트롤 파일 백업
SQL> ALTER SYSTEM SET control_files= '/export/home/oracle/app/oracle/oradata/orcl/control01.ctl', '/export/home/oracle/app/oracle/oradata/orcl/control02.ctl', '/export/home/oracle/app/oracle/oradata/orcl/control03.ctl', SCOPE=SPFILE; SQL> SHUTDOWN SQL> ! # cp control01.ctl control04.ctl # exit SQL> STARTUP방법3) ALTER DATABASE 명령을 사용한 방법
ALTER DATABASE BACKUP CONTROLFILE TO TRACE;alter database 명령을 실행하여 컨트롤 파일을 백업하면 생성된 복사본은 바이너리 파일로 생성되는 대신 텍스트 형식으로 백업 파일을 저장한다. 만일 원본 컨트롤 파일과 복사본 컨트롤 파일 모두를 사용할 수 없다면, 이 파일을 사용하여 모든 컨트롤 파일을 재생성할 수 있다.
• ALTER DATABASE 명령어에 의해 db의 구조가 변경될 때 • CREATE TABLESACE 명령어에 의해 테이블스페이스가 추가 되거나 변경될 때 • DROP TABLESPACE 명령어를 사용하여 테이블스페이스가 삭제될 때
SQL> alter database backup controlfile to trace; Database altered. SQL> show parameter user_dump_dest; NAME TYPE VALUE ----------------- ----------- ------------------------------------------------ user_dump_dest string /export/home/oracle/app/oracle/admin/orcl/udump SQL>
|
프로그래밍 :: 자바 개발자들을 위한 Ajax: 구글 웹 툴킷(Google Web Toolkit) 연구 |
단일 자바 코드 베이스에서 Ajax 애플리케이션 개발하기
난이도 : 고급
Philip McCarthy, 소프트웨어 개발 컨설턴트, Independent
2006 년 8 월 11 일
최근에 출시된 구글 웹 툴킷은 거의 자바 코드로 표현된 동적 웹 애플리케이션을 생성하는 에이피아이 및 툴 세트입니다. 구글 웹 툴킷의 기능을 설명하고 여러분에게 맞는 것을 선택할 수 있도록 팁을 제시합니다.
GWT(참고자료)는 웹 애플리케이션 개발에 있어 독특한 방식을 사용한다. 클라이언트 측 및 서버측 코드 베이스의 활용보다는 컴포넌트 기반 GUI를 생성하고 사용자 웹 브라우저에 표시하기 위한 용도로 GUI를 컴파일 하도록 하는 자바 API를 제공한다. GWT를 사용하는 과정은 일반적으로 자바 애플리케이션 개발과 관련된 경험보다는 Swing 또는 SWT로 개발하는 과정과 훨씬 더 유사하다. GWT의 사용을 통해 HTTP 프로토콜 및 HTML DOM 모델을 추상화하려는 시도를 하고 있다. 사실, GWT 애플리케이션이 웹 브라우저에서 표현된다는 사실은 거의 우연같이 느껴진다.
GWT는 코드 생성을 통해 이와 같은 기능을 이룩하고 GWT 컴파일러는 서버측 자바 코드에서 JavaScript를 생성한다. GWT는 GWT 자체에서 제공하는 API와 함께 java.lang 및 java.util의 단편들로 이루어져 있다. 하지만 이 단편들은 해독하기 어려워, 컴파일 된 GWT 애플리케이션은 블랙박스(GWT의 자바 바이트코드에 해당)로 여겨진다.
이 글에서 필자는 원격 웹 API로부터 날씨 정보를 가져와 이를 브라우저에 표시하는 단순한 GWT 애플리케이션의 생성에 대해 설명한다. GWT의 기능들을 가능하면 간단히 설명하고 GWT 기능에서 발생하는 몇 가지 잠재적인 문제들을 언급하려 한다.
Listing 1은 GWT를 사용해 만들 수 있는 가장 단순한 애플리케이션의 자바 소스 코드를 나타낸다.
|
이는 Swing, AWT 또는 SWT에서 작성했을지도 모를 GUI 코드와 많이 유사하다. 추측했겠지만, Listing 1을 통해 클릭하면 "Hello World!" 라는 메시지를 디스플레이 하는 버튼을 생성하게 된다. 이 버튼은 HTML 페이지 본체 주위에 있는 GWT 래퍼인 RootPanel에 추가된다. 그림 1은 GWT 쉘 내에서 실행 중인 애플리케이션에 대해 나와 있다. 이 쉘은 디버깅 호스팅 환경으로 단순한 웹 브라우저를 포함하며 GWT SDK에 포함된다.
/* Weather Reporter 애플리케이션 구축하기 */
필자는 GWT를 사용해 단순한 Weather Reporter 애플리케이션을 생성하려 한다. 애플리케이션의 GUI는 사용자에게 ZIP 코드 및 온도를 나타내는 ℃및 ℉ 중 하나를 선택하여 입력하는 입력 상자를 제공한다. 사용자가 전송 버튼을 클릭하면, GWT 애플리케이션은 Yahoo! 무료 Weather API를 이용해 선택된 위치의 RSS-포맷 리포트를 얻게 된다. 이 문서의 HTML 부분이 선택되어 화면에 나타나 사용자들이 보게 된다.
GWT 애플리케이션은 모듈로 패키지화되어 있고, 특정 구조에 맞아야 한다. 이른바 module-name.gwt.xml -- 라는 이름의 설정 파일은 애플리케이션의 엔트리 포인트로 작용하는 클래스를 정의하고 기타 GWT 모듈로부터 리소스 승계 여부를 나타낸다. 반드시 이 설정 파일을 모든 클라이언트 측 자바코드가 있는 client라는 이름의 패키지와 이미지, CSS 및 HTML과 같은 프로젝트 웹 자원을 포함하는 public이라는 이름의 디렉토리와 같은 레벨에 있는 GWT 애플리케이션의 소스 패키지 구조에 위치시켜야 한다. 마지막으로 public 디렉토리는 meta태그가 모듈의 정식 이름을 포함한 상태에서 HTML 파일을 반드시 포함해야 한다.
GWT의applicationCreator는 엔트리-포인트 클래스의 이름이 주어진 상태에서, 이와 같은 기본 구조를 생성한다. 따라서
applicationCreator developerworks.gwt.weather.client.Weather를 불러오면 필자가 Weather Reporter 애플리케이션에 시작점으로 활용하는 프로젝트 개요를 생성한다. 이 애플리케이션에 대한 소스 다운로드 파일은 이 구조에 맞는 GWT 프로젝트와 같이 작용하는 유용한 타깃을 포함하는 Ant 구축파일(buildfile)을 포함한다. [Download]
먼저 임의의 기능 추가 없이, GWT 애플리케이션의 사용자-인터페이스 위젯에 관한 기본 레이아웃을 개발한다. GWT UI에서 표현할 수 있는 기능 중 거의 모든 기능을 나타내는 최고급 클래스는 widget(위젯)클래스다. Widgets(위젯)은 항상 panels(패널)에 포함되어 있고 panels 자체는 Widget이라 내포되어 있다. 여러 가지 다른 타입의 패널은 각기 다른 레이아웃 기능을 제공한다. 따라서 GWT panel(패널)은 AWT/Swing 에서의 레이아웃(Layout)또는 XUL에서의 박스(BOX)의 패널과 비슷한 기능을 한다.
모든 위젯 및 패널은 위젯 및 패널을 호스팅 하는 웹 페이지에 부가되어야 한다. Listing 1에서 보다시피, 위젯 및 패널을 직접 RootPanel. Alternatively, you can use RootPanel에 부가할 수 있다. 교대로 Rootpanel을 사용해, ID 또는 클래스 네임으로 식별되는 HTML 컴포넌트에 대한 레퍼런스를 얻는다. 이 경우 필자는 input-container 및 output-container라는 명칭의 각각의 HTML DIV 컴포넌트를 사용한다. 첫 번째 파일은 Weather Reporter에 관한 UI 제어 기능을 포함하며, 두 번째 파일은 Weather Report 자체를 보여준다.
Listing 2는 기본 레이아웃 설정 시 필요한 코드를 나타내는데 이 코드는 자가 설명적이어야 한다. HTML 위젯은 단순히 HTML 작성을 위한 상자에 불과하고 Yahoo! 날씨 정보에서 나온 HTML 출력 정보를 나타내는 곳이다. 이와 같은 모든 코드는 EntryPoint 인터페이스에서 제공되는 Weather 클래스의 onModuleLoad() 메소드 내부로 들어간다. weather 모듈을 둘러싸고 있는 웹 페이지를 클라이언트 웹 브라우저로 로드 할 때 이 메소드를 호출한다.
|
그림 2는 GWT 쉘에서 표현된 레이아웃을 나타내고 있다.
표현된 웹 페이지는 보기에는 상당히 볼품없지만, CSS 스타일링 규칙으로 웹 페이지는 상당히 세련된 기능을 갖춘다. GWT 애플리케이션을 스타일링 하는 두 가지 방식을 사용한다. 먼저, 각 위젯은 디폴트로, project-widget 형식의 CSS 클래스 네임을 갖는다. 예를 들어, gwt-Button 및 gwt-RadioButton은 중심적인 GWT 위젯의 클래스 네임들이다. 일반적으로 내포된 테이블이 뒤죽박죽 모인 타입으로 패널을 구현한다. 패널은 디폴트 클래스네임을 가지지 않는다.
디폴트 위젯-형식 당 클래스 네임 방식으로 애플리케이션 전체에 균일하게 여러 위젯에 이름을 붙이기 용이해진다. 물론 정상적인 CSS 선택자 규칙이 적용되고, 이 규칙을 이용해, 여러 가지 다른 스타일을 애플리케이션 컨텍스트에 따라 동일한 위젯 타입에 적용할 수 있다. 더 높은 가변성을 위해, 위젯의 setStyleName() 및 addStyleName() 메소드를 불러와 특정적으로, 위젯의 디폴트 클래스네임을 바꾸거나 확대한다.
Listing 3은 이와 같은 방식들을 결합해 여러 스타일을 Weather Reporter 애플리케이션의 입력 패널에 적용시키는 방식을 보여주고 있다. weather-input-panel 클래스 네임은 inputPanel.setStyleName("weather-input-panel");에 대한 호출을 통해, Weather.java에서 형성된다.
|
그림 3에서는 이와 같은 스타일이 적합한 상태에서 다시 Weather Reporter 애플리케이션에 대해 나와 있다.
애플리케이션의 기본 레이아웃 및 스타일링 기능이 행해졌으므로, 필자는 몇 가지 클라이언트 측 기능을 시작한다. 친숙한 리스너 패턴을 사용해 GWT에서의 이벤트 핸들링을 수행한다. GWT는 부가된 편의 기능의 몇 가지 어댑터 및 헬퍼-클래스 뿐만 아니라 마우스 이벤트, 키보드 이벤트 및 변경 이벤트 등의 리스너(Listener) 인터페이스를 제공한다.
일반적으로, Swing 프로그래머에게 친숙한 익명 내부-클래스 이디엄을 이용해 이벤트 리스너를 추가한다. 하지만 모든 GWT 리스너(Listener)의 첫 번째 매개변수는 이벤트 센더로 사용자가 대화하는 위젯이다. 이는 필요한 경우, 동일한 리스너(Listener) 인스턴스를 다중 위젯에 부가하고 센더 매개변수를 이용해 이벤트를 보내는 위젯이 어떤 것인지 결정한다는 것을 의미한다.
Listing 4는 Weather Reporter 애플리케이션에서의 두 가지 이벤트 리스너에 대한 구현을 나타낸다. 클릭 핸들러는 전송(Submit) 버튼에, 키핸들러는 TextBox에 각각 부가된다. TextBox를 중점적으로 볼 경우, 전송(Submit) 버튼을 클릭하거나, 엔터 키를 누르면 관련 핸들러에서 사설 validateAndSubmit() 메소드를 불러온다. Listing 4에 있는 코드뿐만 아니라, txBox 및 ucRadio는 Weather 클래스의 인스턴스 멤버가 되면서 확인 방법으로 처리된다.
|
Listing 5는 validateAndSubmit() 메소드 구현을 보여준다. 이 구현 과정은 상당히 단순하며, 확인 로직을 요약한 ZipCodeValidator 클래스에 따라 다르다. 사용자가 유효한 다섯 글자 ZIP 코드를 입력하지 않을 경우, validateAndSubmit() 메소드는 Window.alert()에 대한 호출로 GWT 세계에 표현된 경보 박스에 있는 에러 메시지를 나타낸다. ZIP 코드가 유효한 경우, ZIP 코드 및 ℃/℉가운데 사용자의 선택 단위 등이 fetchWeatherHtml() 메소드를 통과한다. 이에 대해선 나중에 다루기로 하겠다.
|
GWT 쉘이 자바 IDE에 있는 클라이언트 측 코드를 디버그 하도록 해주는 JVM 후크를 가진다는 사실을 언급하기 위해, 잠깐 주제에서 벗어난 얘기를 하겠다. 여러분은 웹 UI와 대화하고 클라이언트에서 실행되는 해당 JavaScript를 나타내는 자바 코드를 알 수 있다. 클라이언트 측에 생성되는 생성 JavaScript를 디버깅하는 것은 기본적으로 성공할 가망이 없기 때문에 이와 같은 기능은 상당히 중요한 기능이다.
Eclipse 디버그 태스크를 구성해 com.google.gwt.dev.GWTShell 클래스를 통해 GWT 쉘을 실행하는 것은 쉽다. 그림 4는 전송(Submit) 버튼을 클릭하는 과정 후에 validateAndSubmit() 메소드에 있는 중지점에서 정지된 Eclipse를 보여준다.
이제, Weather Reporter 애플리케이션에서 사용자 입력 정보를 수집해 정보를 확인했다. 서버에서 데이터를 꺼내오는 과정이 그 다음 단계다. 정상적인 Ajax 개발 과정에 있어, 이 단계는 JavaScript로부터 서버측 리소스를 불러오고 JavaScript 객체 표기법(JSON) 또는 XML로 코드화된 데이터를 다시 받는 과정을 수반한다. GWT는 자체의 원격 프로시저 호출 (RPC) 메커니즘 뒤에 있는 이와 같은 대화 과정을 추상화한다.
GWT 용어 측면에서 보면 클라이언트 는 웹 서버 상에서 실행되는 서비스와 대화한다. 이런 서비스를 나타내는 데 사용되는 RPC 메커니즘은 자바 RMI에서 사용하는 방식과 비슷하다. 이는 서비스 및 몇 가지 인터페이스의 서버측 구현 프로세스를 작성하기만 하면 된다는 것을 의미한다. 코드 생성 및 리플렉션 프로세스는 클라이언트 스텁 및 서버측 골격 프록시를 처리한다.
이에 따라 첫 번째 단계는 Weather Reporter 서비스에 대한 인터페이스를 정의하는 것이다. 이 인터페이스는 GWT RemoteService인터페이스를 확장시켜야 하고, GWT 클라이언트 코드에 나타나야 하는 서비스 메소드의 서명을 포함한다. GWT에서의 RPC 호출은 JavaScript 코드 및 자바 코드 사이에서 행해지기 때문에 GWT는 객체-직렬화 메커니즘을 도입해 언어 분할 (직렬화 가능 타입 사이드 바를 참조) 전체에 걸쳐 인수를 조정하고 값을 반환한다.
|
서비스 인터페이스를 정의하면, 이 인터페이스를 GWT의 RemoteServiceServlet 클래스를 확장하는 클래스에 구현하는 과정이 그 다음 단계다. 이름에서도 암시하듯, RemoteServiceServlet 클래스는 자바 언어의 HttpServlet을 특수화시킨 것으로, 임의의 servlet 상자에서 호스팅 된다.
여기서 언급될 만한 가치가 있는 GWT의 특성 중 하나는 서비스의 원격 인터페이스는 애플리케이션의 client패키지에 반드시 있어야 한다는 것이다. JavaScript 생성 과정에서 서비스 원격 인터페이스가 들어가야 하기 때문이다. 하지만 서버측 구현 클래스는 원격 인터페이스를 기준으로 하기 때문에, 자바 컴파일 타임 의존성은 서버측 코드 및 클라이언트 코드 사이에 존재한다. 이에 대한 필자의 솔루션은 원격 인터페이스를 client의 공통 하위 패키지 안으로 넣는 것이다. 그리고 난 뒤, 필자는 자바에서 공통 하위 패키지를 포함시키고, 나머지 client 패키지를 제외시킨다. 이렇게 하면, 클래스 파일이 JavaScript로만 변환되어야만 하는 클라이언트 코드에서 생성되는 것을 방지한다. 더 좋은 솔루션은 클라이언트 측 및 서버측 코드에 관한 두 가지 소스 디렉토리 전체에 걸친 패키지 구조를 분할한 뒤, 공통 클래스를 두 디렉토리로 복사하는 것이다.
Listing 6에서는 Weather Reporter 애플리케이션: WeatherService에서 사용되는 원격 서비스 인터페이스가 나타나 있다. 이 인터페이스는 입력 정보로 ZIP 코드 및 ℃/℉ 플래그를 취하고 HTML weather 설명을 포함하는 문자열을 반환한다. Listing 6에서는 또한 YahooWeatherServiceImpl의 개요를 보여준다. 이 개요는 Yahoo! weather API를 이용해 주어진 ZIP 코드에 대한 RSS weather정보를 얻고 그 정보로부터 HTML 설명을 뽑아낸다.
|
이 시점에서 표준 RMI 방식에서 벗어나기 시작한다. JavaScript로부터의 Ajax호출은 비동기식이므로, 서비스를 호출하기 위해 클라이언트 코드에서 사용하는 비동기식 인터페이스를 정의하는 부가적인 작업이 필요하다. 비동기식 인터페이스 메소드 서명은 원격 인터페이스 서명과는 다르기 때문에 GWT는 Magical Coincidental Naming에 의존한다. 즉, 비동기식 인터페이스 및 원격 인터페이스 사이에 정적인 컴파일-타임 관계가 존재하지 않는다. 하지만 GWT는 명명 협약을 통해 컴파일-타임 관계를 인지한다. Listing 7은 WeatherService에 대한 비동기식 인터페이스를 나타내고 있다.
|
알다시피, MyServiceAsync라 불리는 인터페이스를 생성하고, 각 메소드 서명에 대한 복사물을 제공한 뒤, 반환 (return) 타입을 제거하고, AsyncCallback타입에 관한 부가적 매개변수를 추가하는 것이 일반적인 개념이다. 비동기식 인터페이스는 원격 인터페이스와 같은 패키지에 존재해야 한다. AsyncCallback 클래스는 onSuccess() 및 onFailure() 등의 두 가지 메소드가 있다. 서비스에 관한 호출이 성공일 경우, 서비스 호출에 대한 반환 값으로 onSuccess()를 호출한다. 원격 호출이 실패할 경우, onFailure()를 호출하고, 서비스에 의해 생성되는 Throwable 타입이 통과되면서 오류 근원이 나타나게 된다.
WeatherService 및 WeatherServiceAsync의 비동기식 인터페이스가 적절한 상태에서 필자는 이제 Weather Reporter 클라이언트를 호출해 서비스를 호출하고 서비스에서 나온 응답을 다룬다. 이에 대한 첫 번째 단계는 단순히 반복 사용 설정 코드에 관한 것이다. 반복 사용 설정 코드는 GWT.create(WeatherService.class)를 불러내고 GWT.create(WeatherService.class)에서 반환하는 객체를 다운 캐스팅 해 weather 클라이언트가 사용하는 WeatherServiceAsync의 인스턴스를 생성한다. 그 다음 단계로, WeatherServiceAsync는 ServiceDefTarget에 캐스트 해 ServiceDefTarget상에 setServiceEntryPoint()를 불러올 수 있도록 해야 한다. setServiceEntryPoint()는 자체 해당 원격 서비스 구현 프로세스가 전개되는 URL에서의 WeatherServiceAsync 스텁을 가리킨다. 반복 사용 설정 코드는 효과적으로 컴파일 타임에서 하드 코드화된다. 이 코드는 웹 브라우저에서 전개되는 자바코드로 되기 때문에 런타임에서의 속성 파일에서부터 위 URL을 찾을 방법이 없어 확실히 컴파일 된 GWT 웹 애플리케이션의 이식성을 제한한다.
Listing 8에서는 WeatherServiceAsync 객체의 설정에 대해 나와 있으며 필자가 이전에 언급했던 fetchWeatherHtm()의 구현에 대해서도 나와있다. (클라이언트 측 기능 추가하기 참조)
|
서비스의 getWeatherHtml()에 대한 실질적인 호출 과정은 구현하기 쉽다. 익명 콜백 핸들러 클래스는 단순히 서버에서 나온 응답을 서비스의 getWeatherHtml()를 나타내는 메소드에 전한다.
그림 5는 Yahoo! weather API에서 가져온 날씨 정보를 나타내는 실행 중인 애플리케이션에 대해 나와있다.
GWT에서 클라이언트 측 코드 및 서버측 코드를 융합하는 것은 본질적으로 위험하다. GWT의 추상화 과정으로 클라이언트/서버 분할을 감춘 상태에서 자바 언어로 모든 프로그램을 작성하기 때문에, 클라이언트 측 코드를 런타임 시 신뢰할 수 있다고 착각하기 쉽다. 하지만 그런 생각은 잘못된 것이다. 웹 브라우저에서 실행하는 임의의 코드는 악의적인 사용자에 의해 변조되거나 완전히 우회될 가능성이 있다. GWT는 이런 문제를 줄일 수 있도록 악의적인 사용자들에게 고도로 혼란을 주는 기능을 제공한다. 하지만 GWT 클라이언트 및 클라이언트 서비스 사이를 이동하는 임의의 HTTP 트래픽 등의 2차 공격 시점은 여전히 존재한다.
여기서 필자가 Weather Reporter 애플리케이션의 약점을 이용하는 공격자라고 가정해 보자. 그림 6은 Weather Reporter 클라이언트에서 서버 상에서 실행하는 WeatherService까지 전송되는 요청을 가로채는 Microsoft의 Fiddler 툴에 대해 나와있다. 일단 요청을 가로채면 Fiddler 툴은 요청의 일부를 변경하도록 한다. 그림 6에서 강조된 텍스트를 통해 필자는 필자가 지정한 ZIP 코드가 요청 내에서 코드화된 곳을 발견했다는 사실을 보여주고 있다. 이 요청을 필자가 좋아하는 코드로 변경할 수 있다. 예를 들면 "10001"에서 "XXXXX"로 변경하는 것 등이다.
이제, YahooWeatherServiceImpl에 있는 고유 서버측 코드에서 ZIP 코드상에 있는 Integer.parseInt()를 불러온다고 가정하자. 결국에, ZIP 코드는 Weather's validateAndSubmit()로 통합된 확인 점검 기능을 우회해 통과한 것이 틀림없다. 그런가? 보다시피, 확인 점검 기능은 와해되고, NumberFormatException은 폐지된다.
이 경우 끔찍한 일이 발생되지 않고, 공격자는 클라이언트에서 에러 메시지를 받게 된다. 하지만 더 민감한 데이터를 다루는 GWT 애플리케이션에서 여전히 공격 당할 가능성은 존재한다. ZIP코드를 주문 추적 애플리케이션에서의 고객 ID번호라 가정해 보자. ZIP코드를 가로채 변경하면 다른 고객에 대한 민감한 재정 정보가 나오게 된다. 데이터베이스 쿼리에서 값을 사용하는 임의의 장소에서 이와 같은 동일한 방식을 사용하면 SQL 삽입 공격에 대한 가능성이 존재한다.
예전에 Ajax 애플리케이션으로 작업한 사람들이 이런 공격을 간단하게 하도록 내버려둬선 안된다. 서버 측의 입력 값을 재확인해 임의의 입력 값을 이중 점검하는 작업을 해야 한다, GWT 애플리케이션에서 작성하는 자바 코드는 런타임에서 본질적으로 신뢰할 만한 것이 아니라는 사실을 기억하는 것이 중요하다. 하지만 GWT는 장점도 있다. Weather Reporter 애플리케이션에서, 필자는 이미 클라이언트상에서 사용하기 위한 ZipCodeValidator를 작성해 ZipcodeValidator를 단순히 필자의 client.common 패키지로 이동시켜 서버 측에서 동일한 확인 과정을 다시 재사용했다. Listing 9에서는 YahooWeatherServiceImpl로 통합된 점검 기능에 대해 나와있다.
|
웹 애플리케이션에서 시각 효과 라이브러리가 점점 인기를 얻고 있다. 이 라이브러리 효과는 미묘한 사용자-상호작용 큐를 제공하거나 단순히 폴리시 기능을 추가하기 때문이다. 필자는 Weather Reporter 애플리케이션에 몇 가지 아이-캔디 기능을 추가하고 싶다. GWT는 이와 같은 타입의 기능을 제공하지 않지만 GWT의 JavaScript Native Interface(JSNI)는 이 기능에 대한 솔루션을 제공한다. JSNI로 GWT 클라이언트 자바 코드로부터 JavaScript를 호출하게 된다. 이는 예를 들어, 필자가 Scriptaculous 라이브러리 (참고자료)나 Yahoo! 사용자 인터페이스 라이브러리로부터 효과를 이용할 수 있다는 것을 의미한다.
JSNI는 특수 주석 블록에 포함된 자바 언어의 native(고유)키워드와 JavaScript를 조합한 타입을 사용한다. 이는 아마도 예를 통해 설명할 수 있을 것이다. Listing 10에서는 Element 상에 주어진 Scriptaculous 효과를 호출하는 메소드에 대해 나와있다.
|
이것은 컴파일러가 private native void applyEffect(Element element, String effectName); 만을 보기 때문에 완벽히 유효한 자바 코드이다. GWT는 주석 블록의 내용을 파싱하고 JavaScript를 출력한다. GWT는 window와 document 객체를 칭하는 $wnd 와 $doc 변수를 제공한다. 이 경우, 나는 상위 레벨에 있는 Effect 객체에 액세스 하고 JavaScript의 대괄호를 사용하여 콜러가 지정한 네임드 함수를 호출한다. Element 유형은 GWT에서 제공하는 마법과 같은 타입으로서 Widget의 기반 HTML DOM 엘리먼트를 자바와 JavaScript 코드로 나타낸다. String은 자바 코드와 JavaScript간 JSNI를 통해서 투명하게 전달될 수 있는 타입 중 하나이다.
이제 필자는 서버로부터 데이터를 반환할 시, 뚜렷이 나오는 날씨 정보를 가지게 되었다. 마지막으로 효과 종료 시 ZIP 코드인 TextBox를 재설정한다. Scriptaculous 효과는 비동기식 콜백 메커니즘을 사용해 리스너에 효과의 생명 주기에 관한 내용을 통보한다. 필자는 필자의 GWT 클라이언트 자바 코드 안으로 다시 JavaScript를 호출해야 하기 때문에, 여기서 상황이 조금 복잡해진다. JavaScript에서는 임의의 개수가 있는 인수들로 임의의 함수를 호출한다. 따라서 자바-스타일 메소드 과 부하는 존재하지 않는다. 이는 JSNI가 자바 메소드를 참조할 다루기 힘든 구문을 사용해 발생 가능한 과부하를 명확하게 해야 한다는 것을 의미한다. GWT 문서에서는 이 구문을 다음과 같이 기술한다.
|
instance-expr. 부분은 일종의 옵션이다. 객체 레퍼런스에 대한 필요 없이 정적 메소드를 호출해야 하기 때문이다. 또 다시, Listing 11에서 보면 예에서 설명된 효과 메소드를 알기가 가장 쉽다.
|
applyEffect() 메소드를 변경해 여분의 afterFinish 인수를 Scriptaculous 효과로 전송한다. afterFinish의 값은 효과를 실행할 때 호출되는 익명 함수다. 이 함수는 GWT의 이벤트 핸들러에 의해 사용되는 익명 내부-클래스 이디엄과 뭔가 비슷하다. 호출할 Weather 객체의 인스턴스서부터 시작해, Weather 클래스의 정식 이름, 호출할 함수의 명칭까지 지정해 실질적으로 자바 코드 안으로 다시 호출한다. 괄호의 첫 번째 공란은 인수가 없는 effectFinished()라는 명칭의 메소드를 필자가 불러들이고 싶다는 것을 의미한다. 두 번째 괄호 세트는 함수를 불러들인다.
여기서 로컬 변수인 weather에서 this reference. Because of the way JavaScript call semantics operate, the this 레퍼런스 사본을 보유하고 있다는 사실이 이상하다. JavaScript 호출 의미가 작동되는 방식 때문에 afterFinish 함수 내의 this 변수는 실제로 Scriptaculous 객체다. Scriptaculous객체에서 그 함수를 불러들이기 때문이다. 클로저 외부의 this 레퍼런스 사본을 만드는 것은 단순한 대안이다.
여기서 필자는 몇 가지 JSNI 기능에 대해 알아보았다. 필자는 Scriptaculous 효과 기능을 주문 GWT 위젯으로 요약하는 방식이 Scriptaculous 효과를 GWT로 통합하는 더 좋은 방식이라는 것을 지적하고 싶다. 이 방식이 Alexei Sokolov가 GWT 컴포넌트 라이브러리에서 행했던 바로 그 방식이다. (참고자료)
이제 필자는 Weather Reporter 애플리케이션에 대해 다 얘기했으므로, GWT로 웹 개발 시 몇 가지 장점 및 단점에 대해 설명하겠다.
예상한 바와는 달리, GWT 애플리케이션은 이상하게도 웹과 유사하지 않다. GWT는 기본적으로 경량 GUI 애플리케이션에 관한 런타임 환경으로 브라우저를 이용하기 때문에 정상적인 웹 애플리케이션 보다는 Morfik, OpenLaszlo 또는 심지어 Flash로 개발한 것과 훨씬 비슷한 결과가 나온다. 따라서, GWT는 단일 페이지 상에 풍부한 Ajax GUI로 존재하는 웹 애플리케이션에 가장 잘 맞는다. GWT 애플리케이션이 구글 캘린더 및 스트레드시트 애플리케이션과 같은 구글의 베타 릴리스의 일부를 특성화시키기 때문에, 우연의 일치는 아닌 듯 하다. GWT 애플리케이션은 대단하지만 이를 이용해 모든 비즈니스 상황을 해결할 수는 없다. 대부분의 웹 애플리케이션은 페이지 중심 모델에 완벽히 들어맞기 때문이다. Ajax는 필요한 경우, 더 풍부한 대화형 방식을 사용한다. GWT는 전통 페이지-중심 애플리케이션과 잘 들어맞지 않는다. GWT 위젯과 정상 HTML 타입의 입력 자료를 결합시키는 게 가능하지만 GWT 위젯 상태는 나머지 페이지와는 다르다. 예를 들어, GWT Tree 위젯으로부터 선택된 값을 정규 형식의 일부로 전송하는 간단한 방법이 없다.
|
GWT를 J2EE 애플리케이션 환경에서 사용하기로 결정한 경우, GWT 디자인은 통합 기능을 상대적으로 간단해야 한다. 이 상황에서 GWT 서비스는 단순히 웹 요청을 백 엔드 상의 비즈니스-로직 호출로 위임하는 얇은 중간층인 Struts에 있는 Action와 비슷한 것으로 여겨진다. GWT 서비스는 단순히 HTTP 서블릿이기 때문에 Struts 또는 SpringMVC로 쉽게 통합되고, 인증 필터 뒤에 위치한다.
하지만, GWT는 몇 가지 중대한 결점을 가지고 있다. 우선 첫 번째는 점진적인 성능 저하에 대한 대책이 없다는 것이다. 최근의 웹 애플리케이션 개발에 있어 가장 좋은 훈련은 JavaScript 없이 작동하는 페이지를 생성하는 것이다. 장식하는 데 유용한 곳에 JavaScript를 사용한 다음 여기에 여분의 기능을 추가하는 것이다. GWT에서 JavaScript를 이용할 수 없는 경우, UI를 얻지 못하게 된다. 웹 애플리케이션의 일정 클래스의 경우에 이런 상황은 곧장 거래를 불가능하게 만드는 요건이 된다. 국제화도 GWT의 주요 문제 중 하나다. GWT 클라이언트 자바 클래스는 브라우저에서 실행되기 때문에, 이 클래스는 런타임 시 로컬화 된 문자열을 얻는 속성 또는 리소스 번들에 대한 접근 기능이 없다. 각 로케일(참고자료)에 대해 생성되는 각 클라이언트 측 클래스의 하위 클래스를 요구하는 복잡한 대안이 유용하다. 하지만 GWT 엔지니어는 좀 더 실행 가능한 솔루션에서 작업한다.
아마도 GWT 아키텍처에서 이론의 여지가 있는 문제는 클라이언트 측에 대한 자바 언어로의 전환일 것이다. 자바 언어로 클라이언트 측을 작성하는 일이 본질적으로 JavaScript 작성보다 더 낫다고 제시하는 GWT 주창자들이 있다. 모든 사람들이 이런 관점에 다 공감하는 것은 아니다. 때로는 자바 개발 작업이 성가신 업무라 자바 언어의 가변성 및 표현성을 없애는 것을 상당히 주저하는 JavaScript 코더들이 많다. 경험이 있는 웹 개발자가 부족한 팀의 경우, 자바 코드에서 JavaScript로의 교체는 설득력을 얻는 상황이 된다. 하지만 그 팀이 Ajax 개발 프로젝트로 옮길 경우, 자바 코더들에게 의뢰해 전용 툴을 이용해 까다로운 JavaScript를 생성하는 것보다는 숙련된 JavaScript 프로그래머들을 고용하는 게 더 나을지도 모른다. GWT가 JavaScript, HTTP 및 HTML로 확장하는 추상화 과정에서의 누설로 인해 필연적으로 버그가 생성되고, 경험이 없는 웹 프로그래머들은 버그를 추적하느라 애를 먹는다. 개발자이자 블로거인 Dimitri Glazkov는 다음과 같이 말했다. "JavaScript를 다룰 수 없으면 웹 애플리케이션에 대한 코드를 작성하지 말아야 한다. HTTL, CSS 및 JavaScript는 이런 조류에 대한 필요 충분조건이다." (참고자료)
정적 타이핑 및 컴파일-타임 점검으로 인해 자바 코딩이 본질적으로 JavaScript 프로그래밍보다 오류에 덜 취약하다고 주장하는 사람들도 있다. 이는 상당히 불합리한 주장이다. 어떤 언어라도 나쁜 코드를 작성하는 일은 가능하다. 버그가 있는 자바 애플리케이션은 이를 잘 증명해주고 있다. 또한 GWT의 버그 없는 코드 생성에 의존할 수도 있다. 하지만 오프라인 구문-점검 과정 및 클라이언트 측 코드의 확인 작업은 분명 이로울 수 있다. 이와 같은 것은 Douglas Crockford의 JSLint (참고자료)의 타입으로 있는 JavaScript에서 가능하다. GWT는 단위 테스팅 기능면에서 우세하며 클라이언트 측 코드에 대한 JUnit 통합 기능을 제공한다. 단위 테스팅 지원 기능은 여전히 JavaScript에서 부족한 영역이다.
Weather Reporter 애플리케이션을 개발하는 데 있어 필자가 클라이언트 측 코드에서 가장 매력적으로 본 것은 두 층 사이에 동일한 확인 클래스를 공유하는 기능이었다. 이 기능으로 인해 분명 애플리케이션 개발 노력을 줄여준다. RPC 전체에 전송된 임의의 클래스인 경우에도 같은 상황이 적용된다. 이때, 클래스들을 코드화하기만 하면 된다. 그러면 클라이언트 측 코드 및 서버측 코드 둘 다 클래스를 이용할 수 있다. 하지만 불행히도, 이런 추상화 법칙은 새기 쉽다. 예를 들어, 필자의 ZIP 코드 밸리데이터에서, 필자는 정규식을 사용해 점검 기능을 수행했으면 했다. 하지만 GWT는 String.match() 메소드를 구현하지 않는다. 심지어 구현했다 하더라도, GWT에서의 정규식은 클라이언트 및 서버 코드로 전개했을 때 구문적 차이를 보인다. 이는 호스트 환경의 기초적인 regexp 메커니즘으로 인해 생기는 것이며, 불완전한 추상화로 생기는 문제를 보여주는 예를 나타낸다.
GWT에서 얻는 한 가지 큰 장점은 자체의 RPC 메커니즘 및 자바 코드 및 JavaScript 간의 객체의 고유 직렬화다. 이로 인해 일상적인 Ajax 애플리케이션에서 보는 수많은 작업들이 줄어든다. 하지만 전례가 없었던 건 아니다. 나머지 GWT 없이 이와 같은 기능을 원한다면, 자바 코드에서 JavaScript까지 객체를 동원하는 RPC를 제공하는 Direct Web Remoting은 고려해 볼만한 가치가 있다 (참고자료)
GWT는 또한 크로스-브라우저 비호환성, DOM 이벤트 모델 및 Ajax 호출하기 등 Ajax 애플리케이션 개발에 있어 몇 가지 최하위 기능을 추상화하는 좋은 기능이 있다. 하지만 Yahoo!, UI 라이브러리, Dojo, 및 MochiKit등 최근의 JavaScript 툴킷은 전부 코드 생성에 대한 필요성 없이도 비슷한 수준의 추상화 기능을 제공한다. 게다가 이런 모든 툴킷은 오픈 소스다. 따라서 이런 툴킷을 필요에 맞게 이용하거나 발생되는 버그를 수정할 수 있다. GWT의 블랙박스에서는 이런 일이 불가능하다. (라이센싱 사이드 바 참조)
GWT는 수많은 기능을 제공하는 광범위한 프레임웍이다. 하지만 GWT는 모 아니면 도 방식이 짙어 웹 애플리케이션 개발 시장에서 상당히 작은 영역에 국한되어 있다. GWT에 대한 간략한 소개의 글로 GWT의 기능 및 한계를 느꼈으리라 생각된다. 이 글이 모든 사람의 필요를 만족시킬 수는 없겠지만, GWT는 Ajax 애플리케이션을 설계할 시 엔지니어링 분야의 큰 업적이다. GWT에 관해선 필자가 설명한 것보다 훨씬 더 많은 영역이 있다. 따라서 GWT에 대해 자세한 내용을 원하면 구글 문서를 참조하거나 GWT 개발자 포럼 토론에 참석하기를 권한다. (참고자료)
Shift + 클릭 등으로 주소를 알아낸뒤..
view-source:http://싸이트주소 또는
http://hackersnews.org/view_source/index.html
에서 소스를 추출
마우스드래그 방지 소스 : onDragstaret="return false"
아우스오른쪽 버튼 사용금지 소스 : onContexrtmenu="return false"
영역의 선택 금지 소스 : onSelectstart="return false"
주로 바디태그에 있는 걸 보았소. 아뭏든 소스 제거하고 htm 파일로 저장
더 좋은 방법 알툴바가 있어야함
알툴바메뉴 -> 환경설정 -> 일반메뉴에서 "마우스 오른쪽버튼 제한 해제하기"를 체크
기능이 정상작동하지 않으면 해상 싸이트에서 다시 체크해제 체크를 반복해본다.
* 최종수정일 : 2008.11.06 <14:21>
① 오라클 데이터베이스 시작하기
Database 의 시작과 종료는 반드시!! Oracle 계정으로 수행해야 합니다.
[root@ora9 /]# su oracle
[oracle@ora9 /]$ source $HOME/.bash_profile
oracle 계정으로 로그인 후 oracle 계정의 환경설정을 reload 합니다.
(처음부터 오라클 계정으로 로그인 하였다면 이 과정은 불필요합니다.)
[oracle@ora9 /]$ sqlplus /nolog
SQL>connect / as sysdba
SQL> startup
오라클 데이터베이스를 시작하고 종료하기 위해서는 OS에서의 인증과 암호 파일을 생성하는
툴인 orapwd를 통해야 한다. 그리고 sys 스키마의 권한인 sysdba 권한과 public 스키마
권한인 sysoper 권한의 특별한 시스템 권한을 소유한 사용자이어야 한다.
· sysdba : 데이터베이스 시작/종료, 아카이브 및 복구 작업, ALTER DATABASE OPEN,
MOUNT, BACKUP, CHANGE, CHARACHER SET 절의 명령어 실행
· sysoper : 데이터베이스 시작/종료, 아카이브 및 복구 작업, ALTER DATABASE OPEN,
MOUNT, BACKUP 절의 명령어 실행
SQL> SELECT * FROM v$version;
현재의 오라클 데이터베이스 인스턴스의 버전 확인하기
② 오라클 데이터베이스 종료하기
[oracle@ora9 /]$ sqlplus /nolog
SQL> connect / as sysdba
SQL> shutdown immediate
③ oratab 파일 편집하기
오라클 데이터베이스를 /etc/rc.d/ini.d에 스크립트로 설정하여 자동으로 실행하게 하여봅시다.
[root@ora9 /]# vi /etc/oratab
다음 부분을 수정 ([SID], [ORACLE_HOME], [자동실행/종료 플래그]로 구성되어 있습니다.)
ora9:/opt/oracle/product/9.2.0.1.0:N e ora9:/opt/oracle/product/9.2.0.1.0:Y
④ Parameter 파일 링크 (xxxxxxxxxxxx은 일정치 않은 숫자 입니다.)
[root @ora9 /]# cp /opt/oracle/admin/ora9/pfile/initora9.ora.xxxxxxxxxxxx \
/opt/oracle/product/9.2.0.1.0/dbs/initora9.ora
⑤ /etc/rc.d/init.d 에 등록하기
oracle9i 스크립트를 /etc/rc.d/init.d 에 복사합니다.
[root@ora9 /]# cp /usr/local/src/oracle9i /etc/rc.d/ini.t/
oracle9i에 실행권한을 부여합니다.
[root@ora9 /]# chmod 755 /etc/rc.d/init.d/oracle9i
실행수준 2,3,4에 해당하는 데이테베이스를 실행시키기 위하여 심볼릭 링크를 한다.
[root@ora9 /]# ln -s /etc/rc.d/init.d/oracle9i /etc/rc.d/rc2.d/S99oracle9i
[root@ora9 /]# ln -s /etc/rc.d/init.d/oracle9i /etc/rc.d/rc3.d/S99oracle9i
[root@ora9 /]# ln -s /etc/rc.d/init.d/oracle9i /etc/rc.d/rc4.d/S99oracle9i
시스템을 재부팅하거나, 재실행 할 때에 데이터베이스를 중지하기 위하여 심볼릭 링크를 한다.
[root@ora9 /]# ln -s /etc/rc.d/init.d/oracle9i /etc/rc.d/rc0.d/K01oracle9i
[root@ora9 /]# ln -s /etc/rc.d/init.d/oracle9i /etc/rc.d/rc6.d/K01oracle9i
Oracle Database를 재시작 시켜본 후, LISTENER 데몬이 띄워져 잇는지 확인합니다.
[root@ora9 /]# /etc/rc.d/init.d/oracle9i restart
[root@ora9 /]# ps ax | grep LISTENER
리스너 간략정리
오라클 클라이언트에서 서버에 접속하기 위해서는 오라클 서버에 리스너(LISTENER)가 실행되어 있어야 됩니다.
◈ 리스너(Listener)란?
- 오라클 리스너는 네트워크를 이용하여 클라이언트에서 오라클 서버로 연결하기 위한
오라클 네트워크 관리자 입니다.
- 오라클에서 네트워크를 통한 연결은 모두 리스너가 담당하며 리스너와 연결되기
위해서는 클라이언트에 오라클 NET8이 설치되어 있고 이를 통해 오라클 서비스명이라는 것을
만들어 접속해야 합니다.
- 오라클 서버에서 리스너를 시작시켜줘야 클라이언트들이 접속할 수 있습니다.
- lsnrctl명령어로 리스너를 관리 할 수 있습니다.
-- 리스너 시작하기
C:\>lsnrctl
LSNRCTL for 32-bit Windows: Version 8.1.6.0.0 - Production on 01-MAY-2002 23:34:57
(c) Copyright 1998, 1999, Oracle Corporation. All rights reserved.
LSNRCTL에 오신 것을 환영합니다. 정보를 보시려면 "help" 를 입력하십시오.
-- start를 입력하면 리스너가 시작됩니다.
LSNRCTL>start
-- 리스너 관련 명령어들
시작시 : LSNRCTL> start
멈출 때 : LSNRCTL> stop
재시작시 : LSNRCTL> reload
서비스 상태보기 : LSNRCTL> status
명령어 보기 : LSNRCTL> help
오라클 서버/클라이언트간의 네트워크 설정을 하기위해서는 서버에서는 listener.ora파일을 그리고
클라이언트에서는 tnsnames.ora파일을 설정해 주어야 합니다.
◈ listener.ora
- 오라클 서버에서 클라이언트의 요청을 듣고, 클라이언트와의 통신을 환경을 설정하는 파일입니다.
- 오라클 서버에 존재하며, 오라클 클라이언트에서 서버로 접속할 때 필요한 프로토콜 및 포트정보등을 설정하는 파일 입니다.
- 프로토콜은 주로 TCP/IP가 많이 사용됩니다.
◈ tnsnames.ora
- 오라클 Client측에서 오라클 서버로 접속할때 필요한 프로토콜 및 포트번호, 서버주소, 인스턴스등을 설정해주는 파일로서 클라이언트에 위치 합니다.
* 참고
- listener.ora와 tnsnames.ora파일의 위치는 ORACLE_HOME/network/ADMIN/에 존재 합니다.
- linstener.ora와 tnsnames.ora는 둘다 오라클 설치시 Net8 configuration 작업을 해주면 생성이 됩니다.
[출처:SMBW]
At this section of our web site, you can download our products for free and try them.
Download Network Inventory Program - Network Inventory Explorer
Download Network Monitoring Program - LANState (Pro/Standard/Personal)
Download Connection Monitoring Program - Connection Monitor
Download Network File Searching Program - Network File Search (Pro/Standard)
Download Disk Cataloging Program - SearchMyDiscs
Download Apache Log Analyzing Program - Log-Analyzer
Download E-mail Removal Program - Junk Mail Remover
Download MP3 Searching Program - MP3-Scanner
| Product | |
|---|---|
|
10-Strike Network Inventory Explorer 2.51 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Main program: Download Link 1 Download Link 2 File Size: 1.7 Mb Optional Network Inventory Agent 2.4 for collecting data without WMI: Download Link 1 Download Link 2 File Size: 0.9 Mb Optional Network Inventory Client 2.5 for collecting data from offline PCs: Download Link 1 Download Link 2 File Size: 0.7 Mb |
|
LANState 4.12 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
LANState Pro: Download Link 1 Download Link 2 File Size: 3.6 Mb LANState Standard: Download Link 1 Download Link 2 File Size: 3.0 Mb LANState Personal: Download Link 1 Download Link 2 File Size: 3.0 Mb |
|
10-Strike Connection Monitor 1.51 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Download Link 1 Download Link 2 File Size: 1.0 Mb |
|
10-Strike Network File Search 1.5 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Network File Search Standard: Download Link 1 Download Link 2 File Size: 1.3 Mb Network File Search Pro: Download Link 1 Download Link 2 File Size: 1.3 Mb |
|
SearchMyDiscs 3.7 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Download Link 1 Download Link 2 File Size: 2.2 Mb |
|
10-Strike Log-Analyzer 1.51 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Download Link 1 Download Link 2 File Size: 0.8 Mb |
|
for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Download Link 1 Download Link 2 File Size: 0.9 Mb |
|
10-Strike MP3-Scanner 2.1 for Windows 95/98/Me/NT/2000/XP/2003/Vista |
Download Link 1 Download Link 2 File Size: 0.9 Mb |
"Download Link 1" is recommended for fast connections.
Please use "Download Link 2" if you get broken download on slow connections.
[에러의 내용]
해결책을 보니 서비스창에 들어가면 ICS를 실행 하는 곳이 있다는 군요..
허나 실행을 하면..
그래서 어느분의 조언에 따라
- Windows Firewall/Internet Connection Sharing (ICS)
- Network Connections
- Remote Procedure Call (RPC)
- Windows Management Instrumentation
이 시스템을 전부 키고 자동으로 해보았으나..
'
ICS만 실행이 안됨니다..
제가 해결한 방법은,
1. 내 네트워크 환경>속성>로컬영역>일반 에서
Microsoft 네트워크용 파일 및 프린터 공유 및 TCP/IP 를 제외한 Protocal 삭제
2. 컴 리부팅후
제어판>관리도구>서비스 에 보시면 ICS가 동작할것입니다.
3. 이 때 삭제했던 서비스랑 프로토콜 다시 설정해주시면 됩니다.
저는 이렇게 해결했습니다.
http://download.ahnlab.com/vaccine/v3virut.com
위의 링크를 클릭하시면 v3virut.com 이라는 프로그램 다운로드를 시도할 것입니다.
이 프로그램은 'win32.virtob.6.gen(v3에서는 win32/virut라고 뜰 것이다.)'만을 없애기 위한...
말하자면 'win32.virtob.6.gen' 에 특화된 백신입니다.
이런 종류의 웜바이러스는 백신의 치료속도보다 바이러스 감염속도가 더 빠르기 때문에
일반 백신 검사로는 잡기 힘든 바이러스입니다.
저도 Win.Dzan.GEN <- 요 백신으로 골머리 좀 썩혔습니다. (감염속도가 무섭더군요.)
다른 바이러스는 잡지 않고, win32.virtob.6.Gen 전용 치료 백신입니다. 혼돈하지 않으시길..
다운로드를 완료하셨으면 실행해주세요.
그러면 위같은 프로그램 창이 뜹니다.
이 상태에서 '검사시작'을 누르세요.
혹시 다른 하드디스크를 가지고 계시다면 같이 검사해주세요.
그리고 검사가 다 끝나면 '전체치료'를 누르세요.
아직 끝이 아닙니다.
그리고 이 프로그램을 한번 더 검사 => 전체치료 하세요.
왜냐하면 'win32.virtob.6.gen' 바이러스는 감염 속도가 매우 빠르기 때문입니다.
따라서 치료를 하고 있는 순간에도 어딘가로 자기 복제가 되고 있는 것입니다.
따라서 이 바이러스를 확실히 제거하기 위해서는 한번 더 검사가 필요한 것입니다.
검사 후, 알약으로 바이러스 검출이 되는지 다시 한번 검사해보시고 없다면 바이러스 제거 성공입니다.
축하드립니다.

|
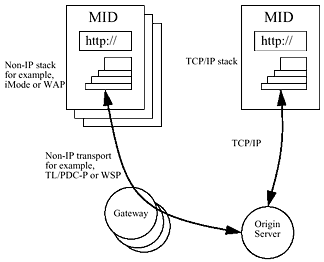



 invalid-file
invalid-file Chapter1,2 Visual Studio 2008 설치.pdf
Chapter1,2 Visual Studio 2008 설치.pdf chapter06 메소드와 클래스.ppt
chapter06 메소드와 클래스.ppt 과제 10문항 문제와 해답.hwp
과제 10문항 문제와 해답.hwp