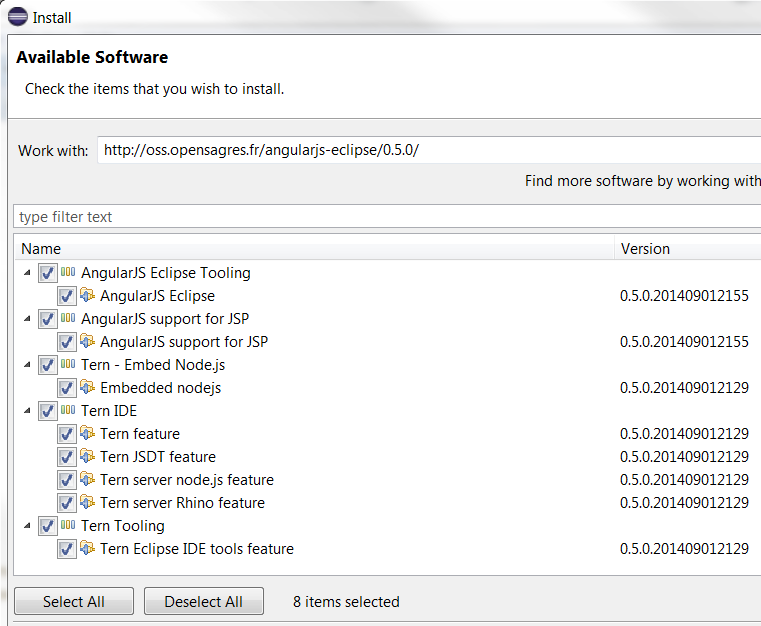
반응형
The answer is NO. The ng-app directive is used to auto-bootstrap an AngularJS application. And according to AngularJS Documentation, only one AngularJS application can be auto-bootstrapped per HTML document. I'd like to quote a section from the documentation here:
Only one AngularJS application can be auto-bootstrapped per HTML document. The first ngApp found in the document will be used to define the root element to auto-bootstrap as an application. To run multiple applications in an HTML document you must manually bootstrap them using angular.bootstrap instead. AngularJS applications cannot be nested within each other.
I'm going to show three approaches, latter two being similar, to deal with the issue.
Before that let's take a look what the actual problem is.
<!DOCTYPE html>
<html>
<body> <div ng-app="firstApp">
<div ng-app="secondApp">
<script src="angular.js"></script>
var secondApp = angular.module('secondApp', []);
As you can see, we defined two separate ng-app directives named firstApp and secondApp. And we also defined two controllers one for each ng-app module and each having its own scope variable name. As the documentation states, only the first ng-app module is auto-bootstrapped. So, in this case, only the firstApp module works as expected while the secondApp module does not. As a consequence, the browser renders the above page as follows:
1# I'm the first app.2# {{ name }}
Now that we discussed the problem, let's move ahead and see how to use alternatives.
Method 1: Injecting modules as dependencies of the root app
The idea here is to define only one top level ng-app in a root element like in <html> or <body>, define other two as modules and inject them as dependencies of the root app.
<!DOCTYPE html>
<html>
<body ng-app="rootApp">
<div id="firstApp">
<div id="secondApp">
<script src="angular.js"></script>
// passing the two modules as dependencies of the root module
var firstApp = angular.module('firstApp', []);
var secondApp = angular.module('secondApp', []);
</script>
This will give the desired result:
1# I'm the first app.2# I'm the second app.
Method 2: Manual bootstrapping the second module
In this method, we are going to leave the first ng-app as it is so that it is auto-bootstrapped by Angular. Whereas for the second ng-app, we're going to a manual bootstrapping method.
<!DOCTYPE html>
<html>
<body>
<!-- using id attribute instead of ng-app -->
<script src="angular.js"></script>
$scope.name = "I'm the first app.";
var secondApp = angular.module('secondApp', []);
$scope.name = "I'm the second app.";
// manually boostrapping the second app
angular.element(document).ready(function() {
Method 3: Manual bootstrapping both modules
As I already mentioned, this method is similar to the previous one. Here, we don't rely on Angular's auto-bootstrapping to initialize the modules. We'll use manual bootstrapping method to initialize both modules as depicted in the example below:
<!DOCTYPE html>
<html>
<body>
<!-- using id attribute instead of ng-app -->
<script src="angular.js"></script>
$scope.name = "I'm the first app.";
var secondApp = angular.module('secondApp', []);
$scope.name = "I'm the second app.";
var firstDiv = document.getElementById('firstApp');
// manually boostrapping the second app
Only one AngularJS application can be auto-bootstrapped per HTML document. The first ngApp found in the document will be used to define the root element to auto-bootstrap as an application. To run multiple applications in an HTML document you must manually bootstrap them using angular.bootstrap instead. AngularJS applications cannot be nested within each other. |
I'm going to show three approaches, latter two being similar, to deal with the issue.
Before that let's take a look what the actual problem is.
<!DOCTYPE html> <html> <head> <title>Multiple ngApp does not work</title> </head> <body> <div ng-app="firstApp"> <div ng-controller="FirstController"> <p> 1# {{ name }} </p> </div> </div> <div ng-app="secondApp"> <div ng-controller="SecondController"> <p> 2# {{ name }} </p> </div> </div> <script src="angular.js"></script> <script type="text/javascript"> var firstApp = angular.module('firstApp', []); firstApp.controller('FirstController', function($scope) { $scope.name = "I'm the first app."; }); var secondApp = angular.module('secondApp', []); secondApp.controller('SecondController', function($scope) { $scope.name = "I'm the second app."; }); </script> </body> </html> |
As you can see, we defined two separate ng-app directives named firstApp and secondApp. And we also defined two controllers one for each ng-app module and each having its own scope variable name. As the documentation states, only the first ng-app module is auto-bootstrapped. So, in this case, only the firstApp module works as expected while the secondApp module does not. As a consequence, the browser renders the above page as follows:
1# I'm the first app. 2# {{ name }} |
Now that we discussed the problem, let's move ahead and see how to use alternatives.
Method 1: Injecting modules as dependencies of the root app
The idea here is to define only one top level ng-app in a root element like in <html> or <body>, define other two as modules and inject them as dependencies of the root app.
<!DOCTYPE html> <html> <head> <title>Injecting modules as dependencies of the root app </title> </head> <body ng-app="rootApp"> <div id="firstApp"> <div ng-controller="FirstController"> <p>1# {{ name }}</p> </div> </div> <div id="secondApp"> <div ng-controller="SecondController"> <p>2# {{ name }}</p> </div> </div> <script src="angular.js"></script> <script type="text/javascript"> // passing the two modules as dependencies of the root module var rootApp = angular.module('rootApp', ['firstApp','secondApp']); var firstApp = angular.module('firstApp', []); firstApp.controller('FirstController', function ($scope) { $scope.name = "I'm the first app."; }); var secondApp = angular.module('secondApp', []); secondApp.controller('SecondController', function ($scope) { $scope.name = "I'm the second app."; }); </script> </body> </html> |
1# I'm the first app. 2# I'm the second app. |
Method 2: Manual bootstrapping the second module
In this method, we are going to leave the first ng-app as it is so that it is auto-bootstrapped by Angular. Whereas for the second ng-app, we're going to a manual bootstrapping method.
<!DOCTYPE html> <html> <head> <title>Manual bootstrapping the second module</title> </head> <body> <div ng-app="firstApp"> <div ng-controller="FirstController"> <p>1# {{ name }}</p> </div> </div> <!-- using id attribute instead of ng-app --> <div id="secondApp"> <div ng-controller="SecondController"> <p>2# {{ name }}</p> </div> </div> <script src="angular.js"></script> <script type="text/javascript"> var firstApp = angular.module('firstApp', []); firstApp.controller('FirstController', function($scope) { $scope.name = "I'm the first app."; }); var secondApp = angular.module('secondApp', []); secondApp.controller('SecondController', function($scope) { $scope.name = "I'm the second app."; }); // manually boostrapping the second app var secondDiv = document.getElementById('secondApp'); angular.element(document).ready(function() { angular.bootstrap(secondDiv, [ 'secondApp' ]); }); </script> </body> </html> |
Method 3: Manual bootstrapping both modules
As I already mentioned, this method is similar to the previous one. Here, we don't rely on Angular's auto-bootstrapping to initialize the modules. We'll use manual bootstrapping method to initialize both modules as depicted in the example below:
<!DOCTYPE html> <html> <head> <title>Manual boostrapping both modules</title> </head> <body> <!-- using id attribute instead of ng-app --> <div id="firstApp"> <div ng-controller="FirstController"> <p>1# {{ name }}</p> </div> </div> <!-- using id attribute instead of ng-app --> <div id="secondApp"> <div ng-controller="SecondController"> <p>2# {{ name }}</p> </div> </div> <script src="angular.js"></script> <script type="text/javascript"> var firstApp = angular.module('firstApp', []); firstApp.controller('FirstController', function($scope) { $scope.name = "I'm the first app."; }); var secondApp = angular.module('secondApp', []); secondApp.controller('SecondController', function($scope) { $scope.name = "I'm the second app."; }); var firstDiv = document.getElementById('firstApp'); var secondDiv = document.getElementById('secondApp'); // manually boostrapping the second app angular.element(document).ready(function() { angular.bootstrap(firstDiv, [ 'firstApp' ]); angular.bootstrap(secondDiv, [ 'secondApp' ]); }); </script> </body> </html> |
 .
.