poi를 이용하여 클라이언트의 엑셀문서를 서버에 업로드후 읽어내는 작업을 하려합니다.
작업의 목적은 화면상에 입력필드가 너무 많아서(대략 240여개 정도 됩니다),
일일이 입력하기에 불편함이 초래되어,엑셀로 다운받은 다음에 해당 입력값들을 엑셀에서 입력후,
입력한 값을 다시 화면상에 뿌려주려는 것입니다.
업로드 완료후 엑셀파일을 읽을때,
Error occurred : Invalid header signature; read 5789751444030890300, expected -2226271756974174256
java.io.IOException: Invalid header signature; read 5789751444030890300, expected -2226271756974174256
at org.apache.poi.poifs.storage.HeaderBlockReader.<init>(HeaderBlockReader.java:88)
at org.apache.poi.poifs.filesystem.POIFSFileSystem.<init>(POIFSFileSystem.java:83).......
위와 같은 에러가 발생합니다.해당 라인을 쫓아가보면,
POIFSFileSystem fs = new POIFSFileSystem(new FileInputStream(filePath + fileName));
이부분입니다.
읽으려 하는 엑셀은 jsp내에서,
response.setContentType("application/vnd.ms-excel;charset=euc-kr");
response.setHeader("Content-Disposition", "attachment; filename="+jspName+".xls");
response.setHeader("Content-Description", "JSP Generated Data");
을 이용해서 생성한것입니다.해당 엑셀파일을 일반 텍스트 에디터에서 열어보면,
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta http-equiv=Content-Type content="text/html; charset=ks_c_5601-1987">
<meta name=ProgId content=Excel.Sheet>
(이하 생략)
meta 태그내의 'content="text/html;' 부분이 의심이 갑니다만.
엑셀을 생성하는 jsp내의 meta 태그부분을 삭제해도,생성된 엑셀을 보면 해당부분이 들어가있는데요.
다시 처음으로 와서,content='text/html' 부분때문에 Invalid header signature...의 오류가 발생하는것인지요?
jsp에서 생성된 엑셀이 아닌 일반 엑셀문서로 테스트 해봤을때는 이상없이 제대로 실행됩니다.
제가 의심한 부분이 맞는것이라면, 해결책은 어떤것이 있을런지 조언 부탁드립니다.
Invalid Header라는 에러메시지의 의미가
파일 헤더가 엑셀타입이 아니라서 그런거 같습니다.
POI가 해석하는 엑셀파일은 MS OLE Compound로 생성된 파일포맷일 경우에만
해당됩니다..html의 header를 excel이라 조작해서 생성된 엑셀파일은
실제론 텍스트파일일뿐 OLE 타입이 아니라서요.
서버에서 생성시 jsp로 생성하지 말고 poi를 이용해서 서버측에 실제
엑셀파일을 생성한 후 클라이언트로 스트리밍을 통해 다운로드 해주는 방식을
택해야할 것같네요.
그렇군요.
실제로 jsp내에서 생성되는 엑셀을 다른이름으로 저장해서 'Micrisoft Excel 통합문서' 형식으로 저장하니,
정상적으로 실행이 되는군요.
충고해주신데로, poi를 이용해서 엑셀을 생성하는 쪽으로 다시 해봐야겠습니다.
답변 고맙습니다.좋은 주말 되세요.
addTo(java.lang.String email) or addTo(java.lang.String email, java.lang.String name)으로 받는 사람의 메일주소를, setFrom(java.lang.String email) or setFrom(java.lang.String email, java.lang.String name)으로 보내는 사람의 메일을 설정합니다
물론 addTo 함수의 추가로 여러 사람에게 메일을 보낼 수 있습니다.
가장 기본적인 setSubject(java.lang.String subject)와 setMsg(java.lang.String msg)로 메일 제목과 내용을 입력한 후 send() 함수로 전송합니다
② 파일 첨부하기
첨부파일과 같이 보낼려면 EmailAttachment 를 생성하여 파일 정보를 입력해 줍니다
파일경로와 파일형태, 파일 설명등을 추가하며 마지막으로 setName(java.lang.String name)을 통해 첨부되는 파일명을 설정합니다
그 후 MultiPartEmail 을 통해 SimpleEmail 처럼 기본 메일정보를 설정합니다
마지막으로 MultiPartEmail의 attach() 함수를 통해 첨부 파일을 추가하여 전송합니다
만약 첨부파일이 두개 이상이라면 EmailAttachment 를 여러개 생성하여 파일 정보를 설정 한 후 attach()를 통해 추가해 주기만 하면 됩니다
③ URL을 통해 첨부하기
파일 경로 정보를 setURL(java.net.URL) 으로 설정할 뿐 위의 첨부파일과 동일합니다
④ HTML 이메일 보내기
HtmlEmail 클래스는 setHtmlMsg()로 작성된 html을 보낼 수 있습니다
이미지 처리가 조금 까탈스럽네요
V. 인증처리
만약 SMTP 서버가 인증을 요구한다면 org.apache.commons.mail.Email 의 setAuthentication(java.lang.String username, java.lang.String password)를 통해 해결할 수 있습니다
이 함수는 JavaMail API의 DefaultAuthenticator 클래스를 생성하여 사용합니다
② 압축을 풀면 lucene-1.4.3.jar와 lucene-demos-1.4.3.jar 파일을 클래스 패스에 겁니다
"set" 명령으로 확인합니다
설치 끝 ~
IV. 데모I 실행하기
Lucene 데모에는 두가지 데모가 있습니다
하나는 일반적인 인덱싱, 및 검색이고 다른 하나는 웹에서 사용하기 위한 인덱싱 및 웹검색입니다
1) 데모I 실행
먼저 네이버나 야후같은 웹 검색엔진을 생각해 봅시다 수도없이 많은 문서들이 어떻게 해서 그렇게 빠릴 검색될까요? 바로 검색 전처리 작업을 하기 때문입니다 예를들어 간단하게 보자면 "love"라는 단어는 A문서, B문서, C문서에 포함되어 있다라는 정보를 미리 만들어 두는 것입니다 즉 인덱스를 만들어 두는 것이지요 그리고 웹로봇들이 문서를 수집해오면 추가된 문서들에 대해 하루에 몇번씩 배치작업으로 인덱스를 추가해 주겠지요 결과적으로 "love" 검색시 인덱스 정보를 뒤져서 A문서, B문서, C문서의 결과를 보여주는 겁니다
lucene도 마찬가지 입니다 인덱스를 먼저 만들어 주어야 합니다 먼저 일단 데모프로그램을 이용하여 인덱스를 만들어 보고 이를 이용하여 검색해 봅시다 내부 코딩은 일단 실행 이후에 살펴봅시다 ^_^ (눈에 먼저 보여야 멀 해도 잘되죵)
C:\lucene-1.4.3\src\ 는 데모을 위한 자바소스 파일입니다
① 인덱스 생성하기 다음 명령으로 인덱스를 생성해 봅시다 인덱스 생성 어플리케이션은 IndexFiles.java 이며 파라미터는 인덱스를 만들 소스파일들(검색대상파일들) 입니다 여기서는 lucene의 document를 index 처리해 보겠습니다
야호~ 인덱스가 생성되었습니다
C:\lucene-1.4.3\index 풀더를보면 다음 파일들이 생성된 것을 알수있습니다
② 검색하기 검색 어플리케이션은 SearchFiles.java 이며 실행 후 Query: 에 검색할 단어를 입력해 봅시다
와~ 성공! 엄청 빠릅니다!!
검색결과가 10개씩 리스팅되며 다음 리스트는 y버튼을 클릭하여 조회 할수 있습니다
2) 데모I 인덱싱 코드 분석
이 데모 프로그램은 가장 기본이 되는 프로그램으로 핵심 코딩만 되어 있으니 lucene을 사용하기 위해서는 꼭 알아 두어야 합니다
① Analyzer 선택
Analyer 는 문서를 인덱싱 하거나 검색할때 핵심이 되는 요소로서, 텍스트를 파싱할 때 사용합니다 Analyzer의 종류에는 다음 몇가지 들이 있습니다
② IndexWriter 생성 자 이제 Analyer를 선택했으면 IndexWriter를 생성하여 Index를 만들어봅시다
첫번째 파라미터는 index가 생성될 위치를 말하며 두번째 파라미터는 선택한 Analyzer를, 세번째 파라미터는 index를 초기화 하여 다시 생성할것인지 말것인지를 말합니다 즉 추가/삭제만 할 것인지(false) 새로 만들것인지(true)를 나타냅니다 문서가 많을경우 매번 새로 만들수 없으며, 또한 만약 몇개의 문서만 변경되었는데 모두 다시 인덱스를 만들수는 없기 때문입니다 (시간 상당히 걸림 --)
③ Index에 document 추가 다음으로 소스 디렉토리(검색대상 문서들)의 파일들을 읽어가며 Analyzer에 의해 파싱된 문서 정보를 인덱스에 추가합니다
④ index optimize 마지막으로 인덱싱한 정보를 하나의 파일로 merge 합니다 즉 검색에 적합하도록 파일을 하나로 합치는 겁니다
⑤ index close
사용후 받드시 close 합시다!
끝~ 간단하죠?
이제 전체 소스를 살펴봅시다
소스는 C:\lucene-1.4.3\src\demo\org\apache\lucene\demo 에 있습니다
org.apache.lucene.demo.IndexFiles.java
3) 데모I 검색 코드분석 검색은 인덱스를 만드는 코드보다 훨씬 쉽습니다
① IndexSearcher 생성 실질적으로 검색을 담당할 IndexSearcher를 생성해 봅시다 파라미터로는 index가 생성되어있는 위치를 입력합니다
② Query 생성 Query는 질의 문자열을 파싱해 줍니다 (즉 AND,OR,NOT,!,-등의 논리연산이나 와일드카드 *,?등을 파싱합니다)
첫번째 파라미터는 질의를, 두번째 파라미터는 검색 필드를, 세번째 파라미터는 인덱스를 만든 Analyzer와 동일한 Analyzer를 입력해 줘야 합니다
③ 검색 및 검색한 결과 저장
파싱된 쿼리를 가지고 검색하여 그 결과값을 반환 받습니다
반환된 Hits 클래스는 순위가 매겨진 문서들로 검색결과를 저장하고 유지합니다
④ IndexSearcher close 검색이 끝났으면 닫아줍시다
전체 소스를 살펴봅시다
org.apache.lucene.demo.SearchFiles.java
V. 질의 문법
질의 문법에 대해 알아봅시다
① A AND B
A와 B가 모두 포함된 문서를 검색한다
② A OR B
A혹은 B가 포함된 문서를 검색한다
③ A NOT B
A는 포함되고 B는 포함되지 않는 문서를 검색한다
A ! B, A - B와 동일하다
④ +A OR B
A OR B에서 A는 받드시 포함된 문서를 검색한다
⑤ A*
A로 시작하는 단어가 있는 문서를 검색한다
⑥ A?
A로 시작하는 두글자의 단어가 있는 문서를 검색한다
⑦ A~
A와 스펠링이 비슷한 글자를 지닌 단어가 있는 문서를 검색한다
⑧ (A OR B) AND C
논리연산의 그루핑 또한 지원한다
AND, OR, NOT등은 반드시 대문자로 입력해야 인식됩니다
다음 시간에는 두번째 데모 프로그램을 실행시켜 보고 lucene을 웹 어플리케이션에 달아 봅시다~
다운받은 파일의 압축을 풀고 환경변수 및 패스를 잡아줍니다 set ANT_HOME=c:\ant set JAVA_HOME=c:\jdk1.4.2 set PATH=%PATH%;%ANT_HOME%\bin
III. 간단한 Ant 예제
Ant를 이용하여 web application을 구성할 때 다음의 구조를 유지하기를 권장합니다
① build : src, web, docs에서 결과적으로 만들어진 산출물 디렉토리 ② dist : build를 배포하기 위한 배포 디렉토리 ③ docs : 배포판에 배포할 정적인 문서를 관리할 디렉토리 ④ src : /WEB-INF/classes 에 위치할 java 소스 디렉토리 ⑤ web : HTML, JSP, 이미지등의 컨텐트 디렉토리 (WEB-INF의 서브디렉토리 포함) ⑥ build.properties : build.xml에서 사용할 properties ⑦ build.xml : ant 명령으로 실행될 설정파일
src에 하나이상의 java 소스를 테스트로 넣어 놓으세요
자 이렇게 디렉토리를 설정하고 build.xml 을 다음 step에 따라 따라 해 BOA요 ^^&
STEP 1. build.xml 의 기본구조
xml을 기본적인 내용을 안다면 이해하기 쉽습니다
하나의 build 파일은 하나의 project로 구성되며 이는 다시 여러 target으로 구성됩니다
target 이란 빌드 과정중 수행해야 할 task들을 모아놓은 job 단위 라고 보면 됩니다
compile target이라 한다면 compile에 관련된 작업들을 모아놓은 그룹이라 생각하면 쉽게 이해 될겁니다
STEP 2. 시~작 Ant 맛보기~ ① build.xml에 다음을 입력한 후 저장 합니다
-. project
project는 하나 이상의 target을 정의 합니다 또한 하나의 target은 task의 집합입니다
ant를 실행할 시에 어느 타겟을 실행할 것인지 지정할 수가 있으며 (예: \ant clear)
지정하지 않았을 경우 디폴트로 설정된 값이 사용됩니다 이부분이 default="clear"입니다
-. property
전역변수 설정 혹은 그렇게 사용할 build.properties를 정의 합니다
build.properties에 catalina.home을 정의하였으며 여러 환경이 변하더라도 이 값만
변경해주면 build.xml을 수정없이 바로 실행 가능합니다
-. echo
message 내용을 출력 합니다
-. target
target 이란 task의 집합으로 실질적으로 실행될 코드들의 묶음입니다
여기서는 아무 task도 없습니다
② build.properties에 다음을 입력 후 저장합니다
catalina.home 은 변수로 사용할 것이며 그 값은 C:\Tomcat 5.0입니다
③ 실행
해당 디렉토리로 이동하여 도스창에서 ant 라고 칩니다
STEP 3. 사전작업 하기~
이번 단계에서는 컴파일 하기전 전역변수 선언이나 컴파일 시 클래스 패스 설정을 해봅시다
① build.xml
-. project
이번에는 default 값을 prepare로 하였습니다 고로 target은 prepare가 실행될 것입니다
-. property
역시나 build.properties를 정의하였고 여러 전역변수를 설정하였습니다
build.home 이란 변수에는 ${basedir}/build 값이 정의되었으며
build.home은 ${build.home}으로 사용할수 있습니다
궁금하면 <echo message="${build.home}"/> 등으로 출력해 봅시다~
-. path
${catalina.home} 은 build.properties에서 정의하였다는것을 기역하실겁니다
fileset은 파일들의 집합을 나타내는데 어떤 특정파일만 포함 할수 있거나 혹은 어느 특정파일만 제외할 수 있습니다
javadoc target의 javadoc 태스트를 보면 java 소스가 있는 소스디렉토리와
API를 생성할 타겟 디렉토리를 정해주면 알아서 API를 생성해 줍니다
만들어진 API는 배포버젼의 dist디렉토리로 해주면 더 좋겠지요
dist target은 배포파일인 war를 만듭니다
필요한 문서가 있으면 docs 디렉토리를 만들어 로 복사도 하도록 합시다
jar 태스크는 위의 방식과 같이 사용합니다
② 실행
VI. Ant 실행
① C:\예제\ant -help
ant [options] [target [target2 [target3] ...]]
Options : -help 이 메세지의 표시 -projecthelp 프로젝트 도움 정보의 출력 -version 버전 정보의 출력과 종료 -diagnostics diagnose 나 report 문제에 도움이 되는 정보의 출력. -quiet, -q 한층 더 메세지를 적게 -verbose, -v 한층 더 메세지를 많게 -debug 디버그 정보의 출력 -emacs adornments 없이 로그 정보의 생성(produce) -logfile <file> 로그를 지정 파일에 출력 -l <file> '' -logger <classname> 로그 생성을 실행하기 위한 클래스 -listener <classname> 프로젝트 청취자(listener) 역할의 class의 인스턴스를 추가 -buildfile <file> 지정된 빌드 파일의 사용 -file <file> '' -f <file> '' -D<property>=<value> 지정된 프로퍼티의 값의 사용 -propertyfile <name> 모든 프로퍼티를 파일로부터 로드 (-D프로퍼티보다 전에) -inputhandler <class> 입력 요청(requests)를 취급하는 클래스 -find <file> 파일시스템의 루트로 향해 빌드파일을 검색하고 그것을 사용
② C:\예제\ant
현재 디렉토리에 있는 build.xml 파일을 이용해, 디폴트 타겟으로 Ant 를 실행합니다.
③ C:\예제\ant compile
현재 디렉토리에 있는 build.xml이 실행되며 파라미터로 compile을 지정하면 project의 default 값을 무시하고 compile target을 실행합니다 물론 depends 가 있다면 먼저 실행합니다
④ C:\예제\ant -buildfile test.xml
현재 디렉토리에 있는 test.xml 파일을 이용해, 디폴트 타겟으로 Ant 를 실행합니다.
⑤ C:\예제\ant -buildfile test.xml dist
현재 디렉토리에 있는 test.xml 파일을 이용해, dist 라는 이름의 타겟으로 Ant 를 실행합니다.
이제는 데이터베이스 풀을 이용한 커넥션 풀을 사용하지 않는다는것은 상상조차 할 수 없게 되었다. 각 WAS의 벤더들은 오래전부터 자사제품에 대해 최적화된 커넥션 풀을 기본적으로 제공을 하기까지 이르렀다. 또한 한스버그의 커넥션 풀링이나 풀맨의 풀등 여러 오픈된 커넥션 풀 소스들이 돌아다기기도 하였다.
여기서는 Jakarta Commons에서 진행하고있는 Commons-dbcp project에 대해 알아보고 간단한 예제를 소개하기로 하겠다
II. 다운로드 및 설치
dbcp는 commons의 pool과 collection을 사용하기때문에 다음3가지를 모두 설치해야 정상적으로 dbcp를 사용할 수 있다.
Commons-Lang은 java.lang에 있는 클래스처럼 기능적으로 필요한 유틸리티들을 모아놓은 클래스들의 집합입니다. 아마도 여러분들 역시 직접 유틸리티 클래스들을 만들어 사용하고 있을겁니다. 즉 코딩을 하다보면 이렇거 있었으면 좋겠다 싶은것들이 Commons Lang에 다 있다고 생각하시면 됩니다 ^^
일반적으로 POI가 엑셀파일을 쓰는 컴퍼넌트로 알려져 있으나 POI는 프로젝트 이름입니다. 즉 POI는 Microsoft Format File을 액세스 할 수 있는 API를 제공합니다. (한마디로 자바에서 MS파일을 읽고 쓸수있도록 지원합니다.)
POI안에는 여러 컴퍼넌트들이 있습니다.
① POIFS Microsoft의 OLE2 포맷 형식의 문서를 자바로 읽고 쓸수 있는 컴퍼넌트입니다 기본적으로 POI의 모든 컴퍼넌트들이 POIFS를 사용합니다. ② HSSF Microsoft의 엑셀파일을 읽고 쓸수 있도록 지원하는 컴퍼넌트입니다. ③ HWPF Microsoft의 워드파일을 읽고 쓸수 있도록 지원하는 컴퍼넌트입니다. 이 컴퍼넌트는 디자인 초기단계입니다. ④ HPSF Microsoft의 OLE2 포맷 형식의 문서 속성을 어플리케이션에서 사용 할수 있도록 지원하는 컴퍼넌트입니다. 현재 읽기 기능만 제공합니다
엑셀을 읽고 쓸때 수식을 지원합니다. org.apache.poi.hssf.usermodel.HSSFCell의 setCellFormula("formulaString") 메쏘드는 스프레드시트에 수식을 추가하는데 사용되며 getCellFormula() 메쏘드는 수식을 대표하는 문자열을 해석하는데 사용됩니다. 하지만 엑셀에서 사용하는 수식을 모두 사용 할 수는 없습니다.
① 지원되는 부분 -. 셀 참조, 시트참조, 지역참조 -. 상대적 혹은 절대적 참조 -. 수연산 및 논리연산 -. 시트 혹은 매크로 함수
-. 수식 결과값 반환
② 부분적 지원 문자열을 포함하는 수식을 해석할 수는 있지만 문자열값을 반환하는 수식은 아직 지원하지 않습니다.
③ 지원되지 않는 부분
-. 배열 수식 -. 1진법 수식 -. 3D 참조 -. 에러 값 (cells containing #REF's or #VALUE's)
IV. 기본객체
가장 기본이되는 객체가 다음 4가지 입니다
이름에서 무엇을 뜻하는지 대강 짐작 할 수 있겠죵?
① HSSFWorkbook - 엑셀 워크북을 말합니다. ② HSSFSheet - 엑셀 쉬트를 나타냅니다. ③ HSSFRow - 엑셀에서 특정 행입니다. ④ HSSFCell - 엑셀에서 특정 행에대한 특정 셀입니다
위 4가지 객체는 앞으로 계속 나올겁니다. 눈여겨 미리 봐 둡시다. @.@
V. 엑셀 읽기 예제
① POSFS을 이용하여 엑셀 워크북을 생성합니다.
POIFSFileSystem fs = new POIFSFileSystem(new FileInputStream("excelfile.xls")); HSSFWorkbook workbook = new HSSFWorkbook(fs);
② 생성된 워크북을 이용하여 시트 수만큼 돌면서 엑셀 시트 하나씩을 생성합니다.
int sheetNum = workbook.getNumberOfSheets();
for (int k = 0; k < sheetNum; k++) { System.out.println("Sheet Number : "+k);
System.out.println(Sheet Name : " + workbook.getSheetName(k)); HSSFSheet sheet = workbook.getSheetAt(k);
}
③ 생성된 시트를 이용하여 그 행의 수만큼 돌면서 행을 하나씩 생성합니다.
int rows = sheet.getPhysicalNumberOfRows();
for (int r = 0; r < rows; r++) { HSSFRow row = sheet.getRow(r);
System.out.println("Row : "+row.getRowNum());
}
④ 역시나 생성된 행을 이용하여 그 셀의 수만큼 돌면서 셀을 하나씩 생성합니다.
int cells = row.getPhysicalNumberOfCells();
for (short c = 0; c < cells; c++) { <--!! short 형입니다. 255개가 max! HSSFCell cell = row.getCell(c);
SmartUpload, MultipartRequest, Commons fileupload등을 모두 사용해 보았지만 개인적으로 가장 애착이 가는 파일 업로드입니다.
아쉬운점은 Commons-fileupload는 지난 2003년 6월 1.0버젼으로 정식 릴리즈 되었지만 그 이후로 이렇다 할 패치나 보안이 전혀 안되었다는 것입니다. 이말은 파일 업로드 자체가 그리 복잡한 패키지가 아니며 첫 정식 버젼이 그만큼 완벽하다는 것을 반증하는 말이기도 하겠지요 ^^
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
try {
if (FileUpload.isMultipartContent(request)) {
DiskFileUpload fileUload = new DiskFileUpload(); fileUpload.setRepositoryPath(upload); fileUpload.setSizeMax(100*1024*1024); fileUpload.setSizeThreshold(1024*50);
List items = fileUpload.parseRequest(request);
Iterator iterator = items.iterator(); while (iterator.hasNext()) {
FileItem item = (FileItem) iterator.next();
if (!item.isFormField()) { if (fileItem.getSize() > 0) { //파일 이름을 가져온다 String filename = fileItem.getName().substring(fileItem.getName().lastIndexOf("\\")+1);
기본적으로는 Web Application을 테스팅 하는데 디자인 되었지만 다른 기능들도 테스트 할 수 있도록 확장되었답니다
그럼 Apache JMeter로 무엇을 할 수 있을까요?
JMeter는 정적인 것 뿐만 아니라 동적인 자원 (files, Servlet, Perl, Java Object, DataBase 와 Queries, FTP Servers 등) 둘다 성능을 테스트 하는데 사용됩니다. 즉 서버나 네트웍 혹은 Object에 스트레스를 가하여 다양한 형태의 상태에서 성능을 전반적으로 분석 할 수 있도록 도와준다는 겁니다.
그럼 JMeter의 특징을 간단히 살펴보죵.
-. HTTP나 FTP서버 뿐만 아니라 임의의 데이터베이스 쿼리도 성능을 테스트 할 수 있습니다.
-. 100% 순수 자바로 구현되었기 때문에 기종에 상관없이 실행 할 수 있습니다.
-. Swing 기반의 Componet를 지원합니다.
-. Multithreading 기능을 이용하여 동시에 많은 Thread를 발생 시킬수도 있으며 혹은 독립된 Thread를 연속적으로 발생시켜 테스팅 할 수도 있습니다
먼저 jdk 1.4 이상이어야 합니다. jdk 1.4.1 이하버젼에서는 GUI elements가 잘 작동하지 않는 다는 bug가 레포팅 되었습니다. 운영체제는 unix (solaris, linux) 및 Widnows 계열 모두 잘 작동합니다.
그럼 다운 받은 파일의 압축을 풀어봅시다. 제가 받은 파일은 2.0.2버젼이군요
잠깐 디렉토리 구조를 보지요.
/bin 에는 실행관련 파일들이 들어있습니다.
/docs 와 /printable_docs에는 사용자 매뉴얼과 데모가 들어있습니다.
/extras 는 JMeter를 ant로 바로 실행할수 있도록 하는 설명이 들어있고요
/lib에는 JMeter를 실행하면서 로딩해야할 다른 서드 파티 jar파일을 넣으면 됩니다 만약 JDBC 테스팅을 한다면 해당하는 벤더의 JDBC를 넣으면 되겠네요
ㅈ ㅏ ~ 그럼 실행해 봅시다 /bin/jmeter.bat 을 따블클릭 합니다.
IV. 테스트 계획 수립
테스트 시작 전 먼저 계획을 수립해봅시다 어떻게 해야 할까요?
그냥 쉽게 일반적으로 생각해 봅시다
1) 테스트 인원 및 몇번을 반복할 지 결정한다 2) 첫화면을 간다 3) 로그인 페이지로 간다 4) 500ms 정도 쉰다 (로그인 아이디, 패스워드 입력시간) 5) 로그인을 한다 6) 메뉴를 하나씩 클릭한다 7) 특별한 메뉴는 반복적으로 클릭한다. 8) 또한 어떤 메뉴는 딱 한번만 클릭해야 한다. 9) 또한 다른 메뉴는 랜덤하게 클릭한다. 등의 정도가 되겠지요..
그럼 이러한 작업들이 모두 JMeter로 가능한가? YES!!
V. 초간단 테스트 예제
자 그럼 먼저 간단한 예제를 한번 만들어 봅시다.
먼저 JMeter를 실행하면 다음과 같은 화면이 나올겁니다.
많이 보고 얼렁 익숙해 집시다.
왼쪽편에 'Test Plan'이라는 노드가 보이는데 이 노드는 테스트 계획을 나타낼 일련의 실행 코드 집합 이라고 보면 됩니다 (말이 좀 어렵낭?-_-?)
중간에 User Defined Variables 라고 나오는데 이건 뭔지 저도 잘 모루겠습니다 -_-;
암튼 분명한건 여기서 정의한 변수 및 값은 테스트 플랜 이하 노드에서 모두 상속받아 사용한다는 겁니다.
다음에 체크박스 두개가 있는데 첫번째 'Run each Thread..' 요놈은 Thread를 순차적으로 실행 하겠냐 아니면 동시에 실행하겠냐의 여부를 묻는데 체크하지 않으면 동시에 실행 하는걸로 되어 있습니다. 여기서 Thread란 조금 후에 설명 하겠습니다. 두번째 체크박스는 각 요청에대한 서버의 응답 데이터를 파일에 기록할 것인지 여부를 말하는 것인데 이걸 체크하면 성능이 확~ 떨어지니 왠만함 하지 말라고 되어있습니다.
자 이제 본격적으로 시작해 봅시다. 'Test Plan'을 오른쪽 마우스로 클릭해 봅시다
Thread Group 이란 테스트 계획을 수행할 수행 단위 그룹이라 보면 될것 같습니다. 이 Thread Group을 여러개 추가 할 수도 있으며 그럴 경우 위에서 언급한 체크박스로 동시에 실행 할 것인지 순차적으로 실행 할 것인지 결정 해야 합니다.
그럼 이름을 뭘로 할까요? 'Jakarta Project'라 하지요 -_-;
ㅈ ㅏ 이름을 'Jakarta Project'라 하였습니다 멋집니다 ;;
가운데 체크박스 3개가 있네요
이건 만약 테스트 수행도중 에러(테스트 대상의 에러)가 발생 한 경우 계속할 것인지 Thread만 멈출 것인지 아니면 테스트 자체를 멈출것인지를 선택합니다 여기선 그냥 'Continue'로 하지요
그다음 항목이 가장 중요하므로 잘 숙지해야 합니다.
Number Of Threads 란 이 Thread Group이 생성할 Thread갯수를 말하는데, 쉽게 말하면 이 그룹에서는 몇 사람으로 테스트 할 것이냐 라고 생각하면 됩니다.
Ramp-Up Period (in seconds)는 한 Thread가 시작 된 후 다음 Thread가 시작 될 때까지의 대기 시간을 의미합니다 예를 들어 보자면 10개의 Thread가 사용되고 Ramp-up Period가 50이라면 총 10개의 Thread가 모두 실행되려면 50초가 걸린다는 겁니다. 즉 평균적으로 보자면 한 Thread가 실행 후 다름 Thread까지 5(50/10)초정도 후에 실행 되다는 거지요 (휴 어렵다 =3)
Loop Count는 실행 횟수를 말합니다. forever에 체크하면 무한 루프를 돕니다. 이때는 사용자가 수동으로 STOP 시켜줘야 합니다.
이제 'Jakarta Project'에 마우스를 오른쪽으로 클릭 후 'Add -> Config Element -> HTTP Request Defaults'를 선택합니다.
이 'HTTP Request Defaults'는 HTTP request를 설정함에 있어서 이 노드 이하의 HTTP request는 모두 HTTP Request Defaults에서 설정한 값을 디폴트로 상속 받아 사용하겠다는 겁니다.
반드시 추가해야 할 필수 요소는 아닙니다만 이후의 추가해야 할 HTTP Request노드가 많다면 일일이 다 다음과 같이 세팅해야 함으로 이를 추가해 놓는 편이 좋습니다.
Protocol에는 당연히 웹이니 HTTP를 써야겠고 Server name or ip에는 연결할 서버의 이름이나 ip를 적습니다. 주의할것은 주소까지 모두 여기에 적으면 안됩니다. 나머지 부분은 path 부분에 적어야 합니다.
Commons DbUtils : 데이터베이스 사용에 있어서 단순노가다로 이루어지던 많은 작업을 편리하게 해준다. 그동안 "이거 귀찮은데 유틸로 뽑아놓을까?" 아니면 "우씨~ 이런 노가다" 하던 부분이 한방에 해결됐다. 단순한 유틸 패키지이기에 사용법도 간단하고 편리하다.
//1. JDBC 드라이버 로딩을 간략화(로딩 성공시 true 반환)
if (!DbUtils.loadDriver("com.mysql.jdbc.Driver")) {
몇 년전에 DbUtils와 비슷한 클래스를 만든 적이 있었는데, 그때도 좀 찾아볼 걸 그랬나봅니다. 그러고 보면 저도 apache commons에 이미 있는 것을 많이도 만들어본 삽질의 시간들을 겪었었습니다. 신입 때 commons beanutils하고 commons io에 포함된 것 비슷한 유틸리티 만들어 놓고 혼자서 뿌듯해 했었죠 -_-;
Spring 프레임워크 워크북 2장 : 이 장에서는 Spring 프레임워크의 가장 핵심적인 기능이라고 할 수 있는 Inversion of Control(이하 IoC) 기능에 대하여 중점적으로 다룬다. Spring 프레임워크가 지원하는 IoC기능은 Spring 프레임워크의 핵심 기능이며, 앞으로 다루게될 예제들의 기본이 되는 기능이라고 할 수 있다.
Spring 프레임워크 워크북 3장 : 이 장에서는 OOP가 가지고 있는 한계점을 극복하기 위한 대안으로 등장한 Aspect Oriented Programming(AOP)에 대하여 다룬다. AOP는 OOP와 경쟁관계에 있는 것이 아니라 상호 보완적인 관계로 새롭게 등장한 패러다임이다. 그러므로 AOP는 지금까지의 개발 방식인 OOP 기반하에서 OOP가 가지고 있는 문제점을 보완하는 역할을 해준다.
Spring 프레임워크는 상당히 방대한 기능을 제공하고 있으며, 빠른 속도로 발전하고 있다. 따라서 한권의 책에서 Spring 프레임워크가 가지고 있는 모든 기능을 다루기는 힘든 것이 사실이다. 따라서 이 위키를 통하여 Spring 프레임워크 워크북에서 다루지 못한 내용들을 하나씩 채워나갈 생각이다.
독자들 중 Spring 프레임워크의 기능 중 책에서 다루지 않고 있는 기능에 대하여 알고 싶은 부분이 있다면 게시판을 통하여 제안을 해주기 바란다. 시간이 허락하는 한도내에서 문서를 작성하고 정보를 제공할 예정이다.
Spring MVC에 HandlerInterceptor 사용하기 : 서블릿 2.3부터 제공하기 시작한 Servlet Filter는 다양한 곳에서 유용하게 사용되고 있다. Spring MVC내부에서 모든 Controller에 전처리 작업과 후처리 작업이 필요하다면 HandlerInterceptor를 이용하여 처리하는 것이 가능하다.
Spring MVC를 활용한 정적인 페이지 개발 : 6장의 Spring MVC를 단계적으로 추가적인 설명과 처음 Spring MVC를 이용하여 구현하고자 하는 개발자에게 도움이 될 만한 내용이 추가된다. 또한 책에서는 메인페이지를 처음으로 구현하고 있는데, 실제 예제소스에서는 이미 완성된 소스를 보이고 있음으로 단계적으로 개발하기에 부족함이 있는 듯 하여 직접 하나씩 구현해 보면서 예제소스를 만들어 가는 것으로 한다.
크기와부하의측면에서경량이고 1MB 크기의 jar파일로배포된다. 그리고스프링은침입적이지않다고한다. 무슨말인지..쩝스프링을도입한애플리케이션의객체가보통의경우스프링의특정클래스에대한의존성을갖지않는다는의미라고한다. 그냥 ejb에비해의존성이없다는얘기로이해하고넘어가야겠다
2.제어역행
제어역행(IoC, Inversion of Control)이라는기술을통해애플리케이션의느슨한결합을도모한다.
이말은기본개념은객체를생성하거나찾는대신, 구현되는 방법을 기술하는 것이다. 컴포넌트와 서비스들을 코드에 직접 연결하지는 않지만, 설정 파일에서 어떤 컴포넌트가 어떤 서비스를 요구하는지를 기술한다. 컨테이너(이 경우, Spring 프레임웍, IOC 컨테이너)는 이 모든 것을 연결한다.
3.관점지향
관점지향프로그래밍(AOP, Aspect-Oriented Programming)을위한풍부한지원을한다. 여기서 관점지향 프로그래밍이란 비즈니스로직을프로그램밍하게만한다는것이다. 트랜잭션과시스템감시같은것은관련모듈을이용하면된다.
Spring 프레임웍을 구성하는 각 모듈(또는 컴포넌트)은 독립적이거나, 다른 모듈들과 함께 구현된다. 각 컴포넌트의 기능은 다음과 같다.
코어 컨테이너(core container): Spring 프레임웍의 핵심 기능을 제공한다. 코어 컨테이너의 주요 컴포넌트는 BeanFactory(Factory 패턴의 구현)이다. BeanFactory는 Inversion of Control (IOC) 패턴을 사용하여 애플리케이션의 설정 및 의존성 스팩을 실제 애플리케이션 코드에서 분리시킨다.
Spring 컨텍스트(Spring context): Spring 프레임웍에 컨텍스트 정보를 제공하는 설정 파일이다. Spring 컨텍스트에는 JNDI, EJB, 국제화, 밸리데이션, 스케줄링 같은 엔터프라이즈 서비스들이 포함된다.
Spring AOP 모듈(Spring AOP): 설정 관리 기능을 통해 aspect 지향 프로그래밍 기능을 Spring 프레임웍과 직접 통합시킨다. 따라서 Spring 프레임웍에서 관리되는 모든 객체에서 AOP가 가능하다. Spring AOP 모듈은 Spring 기반 애플리케이션에서 객체에 트랜잭션 관리 서비스를 제공한다. Spring AOP에서는 EJB 컴포넌트에 의존하지 않고도 선언적 트랜잭션 관리를 애플리케이션과 결합할 수 있다.
Spring DAO: Spring JDBC DAO 추상 레이어는 다른 데이터베이스 벤더들의 예외 핸들링과 오류 메시지를 관리하는 중요한 예외 계층을 제공한다. 이 예외 계층은 오류 핸들링을 간소화하고, 예외 코드의 양도 줄여준다. Spring DAO의 JDBC 예외는 일반 DAO 예외 계층에 순응한다.
Spring ORM: 프레임웍은 여러 ORM 프레임웍에 플러그인 되어, Object Relational 툴 (JDO, Hibernate, iBatis SQL Map)을 제공한다. 이 모든 것은 Spring의 일반 트랜잭션과 DAO 예외 계층에 순응한다.
Spring Web module: 웹 컨텍스트 모듈은 애플리케이션 컨텍스트 모듈의 상단에 구현되어, 웹 기반 애플리케이션에 컨텍스트를 제공한다. Spring 프레임웍은 Jakarta Struts와의 통합을 지원한다. 웹 모듈은 다중 요청을 핸들링하고, 요청 매개변수를 도메인 객체로 바인딩하는 작업을 수월하게 한다.
Spring MVC framework: MVC 프레임웍은 완전한 기능을 갖춘 MVC 구현이다. MVC 프레임웍은 전략 인터페이스를 통해 설정할 수 있으며, JSP, Velocity, Tiles, iText, POI 같은 다양한 뷰 기술을 허용한다.
언제부턴가 블로그는 이미 우리 주위에 깊숙히 자리잡은 하나의 트렌드처럼 보인다. 하지만 너무나 익숙해져버린 탓에 네XX, 티XXX, 다X에 하나씩 둥지를 틀고 모두가 비슷한 모양의 블로그에 서로 경쟁하듯이 퍼가기를 일삼고 있다. 그 결과 정보가 생산되는 참여의 공간이 아니라 단지 바이러스처럼 퍼지기만하는 해적판 CD 시장 같은 생각이 든다.
꼭있다!! 이런 군상에서 고고한 학처럼 살고자 하는 사람들... 그래서 적지 않게 설치형 개인 블로그를 운영하는 사람들이 늘고 있다. 프로그래밍 실력만 있다면 자유로운 스킨 변환, 업로드 공간의 자유로움, 특수 기능의 매쉬업 등이 기존의 대형 블로그들과는 차이점이 있기 때문이다.
그래서, 회사에서 확인해 볼 사항도 있고하여 설치형 블로그의 대표 선수인 TextCube를 설치해 보았다. 잘 아시겠지만 이전에는 Tatter Tools(태터툴즈)라는 이름으로 유명했던 웹 블로그 플랫폼이다. 또한 다음과 제휴하여 제공되고 있는 Tistory의 기반 플랫폼이기도 하다. (대단한 녀석이지만 Tistory에 적용되면서 설치형 블로그로서의 장점이 많이 사라지기도 했다.)
아마도 많은 분들이 비슷한 작업을 시도할 것으로 생각되기에 설치 시에 삽질을 줄이기 위해 성공한 방법을 정리해서 공유하고자 한다. 남는 역량을 대한민국 IT 발전을 위해 써주길 바란다. ^^
2. 본인의 PC에 설치하기 (1) APM_Setup을 설치한다. http://www.apmsetup.com/ 윈도우 경우에는 이것을 설치하면 아무런 문제가 되지 않는다. 리눅스의 경우에는 mod_rewrite를 활성화 시켜서 apache를 재컴파일 해야 한다. (필요시 해당 부분 검색!)
(2) 소스 설치 textcube-1.x.x-expansion의 압축을 풀어 tc 폴더 아래의 내용을 APMServer/htdocs 아래에 풉니다. 디렉토리를 구분해서 다중 설치할 수 있어 보입니다. 그런데 설정에 미숙해서 인지 비정상적으로 설치됩니다. 아래와 같이 설치 후 플랫폼 설정 시 다중 사용자가 지원되니 큰 문제가 되지 않습니다.
1. 한마디로 엔터프라이즈 급의 웹 애플리케이션 개발을 위한 여러 기능(라이브러리)을 제공하는 프레임워크입니다.
2. 특징, 장점 - Lightweight Container - Dependency Injection Pattern 지원 - AOP(Aspect Oriented Programming) 지원 - POJO(Plain Old Java Object) 지원 - 일관된 Transaction 처리 방법 제공 - 다양한 Persistance 관련 API 제공 (JDBC, iBATIS, Hibernate, JPA, JDO...) - Restlet과 연동 가능 (요고는 내 입장에서 특징임)
4. 맺음말 Spring 프레임워크는 최근 가장 많이 사용되고 있는 웹 프레임워크 입니다. 제공하는 기능이 방대하면서도 그 사용은 용이하기 때문입니다. Spring이 제공하는 기능 중에 가장 강력한 기능은 물론 IoC(DI)와 AOP 입니다. 이는 이어지는 포스트에서 아주 자세하게 다루어질 예정입니다.
그리고 최근 주목받고 있는 REST 아키텍쳐의 자바 구현체인 Restlet과 같이 사용할 수 있기도 합니다. Restlet 만으로는 모든 웹서비스를 구현하기에는 불편한 것이 사실입니다. 하지만 다행이도 Spring과 결합 모델로 구현이 가능하다고 합니다. (이 부분은 관련 포스트에서 다룰 수 있을지 잘 모르겠습니다.)
프레임워크라는 것은 일종의 트렌드입니다. 최근에 가장 인기 있는 프레임워크에 대해서 공부해 두는 것 쯤은 개발자에게 도움이 되지 않을 까 생각됩니다. 이후의 포스트들이 지적 호기심 충족에 도움이 되길 바랍니다.
IoC는 Spring Framework의 장점을 꼽으라면 가장 먼저 언급되는 개념입니다. 한국어로 변역하면 '제어의 역행'! 한국어가 더 어려워 보입니다. 비슷한 말로 Dependency Injection(DI)라는 말고 있습니다. 한국말로는 의존성 삽입! 아하~ 조금 이해가 되시나요?
간단하게 이해하기 쉽게 같이 알아보지요.
1. 개념 객체 간의 의존관계를 객체 내부에 선언 또는 정의하지 않고, 외부의 조립기를 이용하여 의존 관계를 설명한다는 것
2. 예제 객체간의 연관성을 선언하는 3가지 방법을 보고, 문제점이 어떻게 IoC(DI)를 이용해서 해결되는 지 알아보지요.
1) 직접 선언하는 방법
public class WriteArticleServiceImpl { private ArticleDao articleDao = new MysqlArticleDao(); ... }
- 쉽습니다. - 하지만, 이를 테스트하기 위해서는 MySqlArticleDao가 정상적으로 동작해야 합니다. 어렵습니다. - 또한, OracleArticleDao를 사용하기로 바뀌었다면 코드를 고쳐야 하지요~ 물론 컴파일도 다시요. 귀찮습니다.
2) Factory 패턴, JNDI를 이용하는 방법
public class WriteArticleServiceImpl { private ArticleDao articleDao = ArticleDaoFactory.create(); ... }
- 조금 나아졌나요? 최소한 Oracle로 바뀌어도 코드 수정은 안해도 되겠네요~ ^^ - 근데 테스트 측면에서는 전혀! 나아진게 없어 보입니다. 올바르게 동작하는 Factory와 JNDI에 등록된 객체가 필요합니다.
3) 외부 조립자를 이용하는 방법
public class WriteArticleServiceImpl { private ArticleDao articleDao; public WriteArticleServiceImpl(ArticleDao articleDao) { this.articleDao = articleDao; } ... }
외부 설정 파일 (applicationContext.xml) <bean name="writeArticleService" class="com.sec.service.WriteArticleServiceImpl"> <constructor-arg><ref-bean="articleDao" /></constructor-arg> </bean>
- 외부 설정(applicationContext.xml)에서 객체간의 의존성을 설명하고 있다는 감이 오시지요? 바로 이겁니다. 외부에서 객체 의존성을 정의하고 있는 것이지요. 책에서는 조립한다고 설명하더군요. (Nice!) - 여기서는 생성자를 이용한 방법을 사용하지만 setter를 이용하는 방법도 있습니다. 요건 나중에 차차.. - 이제 위에서 말한 2가지 문제점이 다 해결되어 보이지요? 아하~ 굳입니다. ^^
Aspect Oriented Programming (AOP) in Spring Framework
작성자 : 김문규 최초 작성일 : 2008. 7.10
1. 정의 AOP는 Spring Framework의 중요한 특징 중 하나입니다. AOP란, 기능을 핵심 비지니스 로직과과 공통 모듈로 구분하고, 핵심 로직에 영향을 미치지 않고 사이사이에 공통 모듈을 효과적으로 잘 끼워넣도록 하는 개발 방법입니다. 공통 모듈은 보안 인증, 로깅 같은 요소들이 해당됩니다.
예를 들어 다시 설명하면, 로그를 찍기위해 로그 출력 모듈을 만들어서 직접 코드 사이사이에 집어 넣을 수 있겠지요? 이런건 AOP 적이지 않은 개발입니다. 반면에 로그 출력 모듈을 만든 후에 코드 밖에서 이 모듈을 비지니스 로직에 삽입하는 것이 바로 AOP 적인 개발입니다. 코드 밖에서 설정된다는 것이 핵심입니다.
2. 예제 1) AOP스럽지 못한 코드
public class InventoryController implements Controller {
protected final Log logger = LogFactory.getLog(getClass());
private ProductManager productManager;
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String now = (new java.util.Date()).toString(); logger.info("returning hello view with " + now);
return new ModelAndView("hello", "model", myModel); }
public void setProductManager(ProductManager productManager) { this.productManager = productManager; } }
로그를 찍고 싶은 지점에 로깅 코드를 직접 삽입하는 방법입니다. 물론 이렇게 하는 것이 효율적일 수도 있습니다. 하지만, 클래스 진입 시점마다 로그를 찍는 것과 같이 동일한 패턴이 있는 경우에는 rule을 정의하고 여기에 따라서 동일한 모듈이 호출된다고 하면 매우 직관적이고 간결하면서 유지 보수가 편하게 구현이 될것으로 생각됩니다. 이것을 지원하는 것이 바로 AOP이며 spring에서는 이를 지원하고 있습니다.
2) Spring에서 AOP를 사용하는 방법 Spring에서는 크게 - Spring API를 이용하는 방법 - XML schema을 이용하는 방법 - Annotation 기능을 이용한 방법 이 있습니다. 여기서는 2번째 XML schema를 이용하는 방법의 예제를 소개합니다. 전체 소스를 첨부합니다.
// pointcut method 종료 후에 실행 시킬 로깅 함수 public void afterLogging(JoinPoint joinPoint) { String methodName = joinPoint.getSignature().getName(); logger.info("finish call: " + methodName); } }
먼저 AOP 관련 용어를 설명하도록 하겠습니다. - advice : 언제 어떤 기능을 적용할 지에 대한 정의 - joinpoint : 공통 기능 적용 가능 지점 (spring에서는 메서드 호출만이 가능합니다.) - pointcut : joinpoint 중에 실제로 적용할 지점 - weaving : 핵심 로직에 공통 로직을 삽입하는 것 - aspect : 여러 객체에 공통으로 적용되는 공통 관심 사항
설정 정보는 아래의 구조로 생성합니다. <aop:config> <aop:aspect> : aspect를 설정 <aop:before> : method 실행 전 <aop:after-returning> : method 정상 실행 후 <aop:after-throwing> : method 예외 발생 시 <aop:after> : method 실행 후 (예외 발생 예부 상관 없음) <aop:around> : 모든 시점 적용 가능 <aop:pointcut> : pointcut 설정
pointcut 설정은 AspectJ의 표현식에 따릅니다.
execution( 수식어패턴 리턴타입패턴 패키지패턴.메소드이름패턴(파라미터패턴) )
이제 모든 설정은 끝났습니다. 그닥 힘들이지 않고 설정할 수 있습니다. 하지만 joinpoint에 해당되는 지점만 적용이 가능하기 때문에 사용해야 할 시점을 잘 선택해야 할 듯 합니다.
3. 맺음말 지금까지 필터같은 기술을 이용해서 이와 비슷한 기능을 구현 했었지요. 실제 대형 과제를 할 경우에는 더욱더 필요한 기능이 아닌가 싶습니다. 아무리 모듈화를 하고 그 모듈을 적용한다 하더라도 일일이 코드에 적용하는 것은 정말 귀찮은 일일뿐 아니라 오류의 소지도 많아지게 됩니다. 그렇기 때문에 AOP는 정말 유용한 기능이 아닐 수 없습니다. 개인적인 생각으로는 이거 하나만으로도 spring을 써야할 이유가 아닐까 합니다. 제가 드린 예제를 기반으로 꼭 여러분의 과제에 적용해 보시길 바랍니다. 감사합니다.
4. 참조 마지막으로 AOP를 이해하는 것에 많은 도움을 준 칼럼을 소개하고자 합니다. 한빛미디어에 김대곤님이 기고하신 글입니다.
본 기사는 Aspect Oriented Programming에 대해 간략한 소개글이다. 아직까지는 생소한 분야일 수 있겠지만, 점점 더 많이 듣게 되리라 생각된다. AOP를 설명하는데 있어서 자주 등장하는 네 개의 용어들(Aspect, Cross-cutting concern, Point-cut, Advice)를 설명함으로서 AOP가 왜 등장하게 되었으며, AOP가 제시하는 해결책에 대해 살펴볼 것이다. 먼저 "Aspect", "Oriented", "Programming"에서 생소한 단어는 단연 "Aspect"일 것이다. 야후 사전의 정의에 따르면, "Aspect"은 "사물의 면, 국면, 관점"으로 정의되어 있다. 소프트웨어 시스템은 여러가지 관점에서 바라볼 수 있다, 또는 여러 가지 단면을 가지고 있고 있다. 예를 들어, 자금 이체를 하는 프로그램을 작성한다고 생각해 보자. 출금계좌와 입금계좌, 그리고 이체금액을 입력받아 SQL 문장 또는 함수 한 번 돌리는 것으로 끝나는가? 절대 아니다. 먼저, 해킹을 방지하기 위해 사용자가 적절한 보안 프로그램을 설치했는지 점검하는 코드도 있어야 하고, 사용자가 인증되었는지 점검하는 코드도 써야 하고, 상대방 은행에서 적절하게 처리되었는지도 점점해야 하고, 혹시 사용자가 이체버튼을 두 번 누른 것은 아닌가 체크해야 하고, 시스템 로그도 남겨야 한다. 즉, 구현하려고 하는 기능 뿐 아니라 보안, 인증, 로그, 성능와 같은 다른 기능들도 녹아 있어야 한다. 어쩌면 이체를 위한 코드보다 잡다한 다른 측면의 문제들을 다루는 코드가 더 길어질 수 있다. 이런 코드들은 입금이나 출금 같은 다른 곳에서 들어가야 한다. 구현하려고 하는 비즈니스 기능들을 Primary(Core) Concern, 보안, 로그, 인증과 같이 시스템 전반적으로 산재된 기능들을 Cross-cutting concern이라고 부른다. AOP는 Cross-cutting concern를 어떻게 다룰 것인가에 대한 새로운 패러다임이라고 할 수 있다.
AOP는 구조적 방법론에서 객체지향 방법론으로 전환처럼 시스템 개발에 관한 전체적인 변화는 아니다. Object-Oriented Programming이 Aspect-Oriented Programming으로 대체되는 일은 없을 것이다. AOP는 구조적 방법론에도 적용될 수 있고, 다른 방법론에도 다 적용될 수 있지만, 주로 객체지향방법론이 가지는 단점을 보완하는 것으로 묘사되고 있다. 그러면 객체지향 프로그래밍이 또는 다른 이전의 프로그래밍 기법들이 Cross-cutting Concern를 어떻게 다루는지 알아보자. 매우 간단하다. Primary Concern를 구현한 프로그램에 함께 포함시켰다. 그것이 단 한 줄의 메소드 호출이라 하더라도. 많은 프로그래머들은 거의 모든 프로그램에 산재된 로그하는 단 한 줄의 코드를 찾아서 바꾸어 본 경험이 있을 것이다. 또는 간단하게 생각하고 프로그램을 수정하려고 했는데, 도데체 어디를 수정해야 되는지 모르게 코드가 길고, 알 수 없는 코드들이 자리를 차지하고 있을 때의 난감함. Primary concern, Cross-cutting concern이 하나의 프로그램 안에 들어가게 되면, 프로그램을 이해하기가 힘들고, Cross-cutting concern 코드가 여기저기에 산재되어 수정하기 힘들게 된다. 당연히 생산성 떨어지고, 품질 떨어지고, 유지보수 비용 많이 들게 된다.
그럼 AOP는 Cross-cutting concern를 어떻게 처리하는가? 이것도 매우 간단하다. 새로운 아이디어라고 할 수도 없다. Primary Concern 구현하는 코드 따로, Cross-cutting concern 구현하는 코드 따로 쓰고, 나중에 두 개 조합하게 완벽한 어플리케이션 만들겠다는 것이다. 기술 용어로 쓰면, Advice(Cross-cutting concern 구현한 코드)와 Primary concern 구현한 코드를 Point-cut 정보를 이용해서 Weaving(조합)하는 것이 AOP가 이 문제를 다루는 방법이다.
기술적 용어로서의 "Aspect"은 "Advice"와 "Point-cut"을 함께 지칭하는 단어이다. Point-cut은 어떤 Advice를 Code 어느 위치에 둘 것인가 하는 것이다. 예를 들면, 로그 기능을 구현한 Advice는 Code 속에 있는 모든 public 메소드가 수행되고 나면, 그 마지막에 실행되어라 라고 지정한 것이라 할 수 있다.
이전까지의 객체지향 프로그래밍은 Cross-cutting concern을 정적으로 어플리케이션에 결합시킨 반면 AOP는 동적으로 Cross-cutting concern를 다룬다고 표현하기도 합니다. 용어에서도 알 수 있듯이 AOP는 소프트웨어 엔지니어링 원칙 중에 하나인 "Separation of concern"를 구현하려고 하고 있습니다. 이러한 문제들을 다루고 있는 분야 중에 하나는 디자인 패턴할 수 있고, 예를 들어, Visitor 패턴은 정적인 구조를 동적으로 바꾸려고 합니다. AOP가 현재까지 나온 방법들 중에서 Cross-cutting concern를 다루는 가장 좋은 방법인가 하는 질문엔 아직 답하긴 힘들 것 같습니다. 그럼에도 분명 언제가는 책상 위에 관련 서적 한 권 있어야 할 것 같은 분야가 될 것 같습니다.
-------------------------------------------------------------------------------------------------- Developing a Spring Framework MVC application step-by-step
작성자 : 김문규 (MyMK) 최초 작성일 : 2008.07.22
다음의 내용은 spring framework 공식 홈페이지(www.springframework.org)의 튜토리얼을 정리한 것입니다. 저와 같은 spring 초보자를 위해서 개인적인 방식으로 재구성하였습니다. 처음 spring을 접하는 분들이 학습에 참고 자료로 활용하시길 바랍니다.
코드 자체의 세세한 부분은 다루지 않을 것입니다. spring 프레임워크을 이용해서 기본적인 웹 서비스를 구현하는 방법을 보여주는 것에 주력할 것입니다. 따라서, 이 글에서는 설정 파일의 작성에 대해서 중점적으로 논의하겠습니다. (이 글은 기본적인 자바 웹 개발에 경험이 있는 분을 기준으로 작성합니다.)
튜토리얼치고는 소스와 설정파일이 많은 편입니다. 이는 Spring 자체가 MVC를 지원하는 프레임워크이고 설정 파일도 논리적으로 분리하는 것을 권장하기 때문입니다. 튜토리얼에서도 이 개념은 유지하고 있습니다. 이는 차차 설명하기로 합니다.
1) 소스 구조 최상위 폴더는 아래와 같습니다. ┌ bin - 컴파일된 class 저장 ├ db - DB와 관련된 스크립트 ├ src - 말 그대로 소스들 └ war - WAS에 deploy될 것들 을 가리킵니다.
각각의 폴더에 대해 조금 더 자세히 알아보도록 하겠습니다. 조금 생소한 부분만 설명합니다. 너무 쉬운 부분은 넘어가도록 하겠습니다.
□ /src springapp은 최상위 package이고 여기에 domain, repository, service, web이라는 하위 package가 존재합니다. 아래의 기준으로 클래스 모듈을 위치 시킵니다. . domain - data 모델링 객체 . repository - DAO 과 관련된 객체 . service - 비지니스 로직 . web - web 프리젠테이션 관련 객체
□ /war . /WEB-INF/tld/spring-form.tld spring에서 사용할 수 있는 tag library의 정의입니다. tag library는 기존 jsp에서 사용하던 tag를 spring에서 재정의 한 것으로 좀 더 사용이 편합니다. . /WEB-INF/*.xml 설정 파일들입니다. 실질적으로 spring을 사용함에 있어 가장 먼저 이해하여야 할 부분입니다. 뒤에서 자세히 설명하도록 하겠습니다.
2. Configuration 관련 1) web.xml □ org.springframework.web.context.ContextLoaderListener . 계층별로 나눈 xml 설정파일을 web.xml에서 load되도록 등록할 때 사용. . 기본값으로 applicationContext.xml을 사용함 예시) <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <context-param> <param-name>contextConfigLocation</param-name> <param-value> /WEB-INF/mars-ibatis.xml /WEB-INF/mars-service.xml </param-value> </context-param>
□ <taglib> . spring tag library의 위치 설정
2) applicationContext.xml □ ContextLoaderListener(또는 ContextLoaderServlet)가 ApplicationContext를 만들 때 사용
□ ApplicationContext란, 웹에 독립적인 애플리케이션의 모든 영역(dao, service, manager, 기타 등등) 에 대한 정의를 말합니다.
□ connection pool에 대한 정의 . org.apache.commons.dbcp.BasicDataSource : datasource를 정의, db driver, 보안 정보등을 알림 . org.springframework.beans.factory.config.PropertyPlaceholderConfigurer : 읽어들일 property 파일에 대한 정보를 알림
□ transaction에 대한 지원을 위한 한 방법 이 부분은 나를 비롯한 spring 초보자의 입장에서 아직 이해하기 어려운 부분이기 때문에 아래의 코드가 AOP 기법을 활용하여 transaction을 지원하고 있다는 것만 알아두기로 하자.
3) springapp-servlet.xml □ DispatcherServlet이 WebApplicationContext를 만들 때 사용
□ WebApplicationContext이란, 특정 웹(DispatcherServlet)에 종속되는 영역(Controller 및 각종 웹관련 설정 bean들)에 대한 정의를 말합니다. (ApplicationContext과의 차이를 확인하세요.)
□ 주로 웹 페이지 리소스에 대한 핸들러 클래스 빈의 정의가 존재합니다.
□ org.springframework.context.support.ResourceBundleMessageSource . message.properties 파일에 정의된 속성 값을 사용할 수 있도록 함 . 국제화에 응용되면 아주 좋아 보입니다~
□ org.springframework.web.servlet.view.InternalResourceViewResolver . prefix와 suffix 값의 정의에 따라 리소스 표현을 축약할 수 있도록 함. 예시) <bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="viewClass" value="org.springframework.web.servlet.view.JstlView"></property> <property name="prefix" value="/WEB-INF/jsp/"></property> <property name="suffix" value=".jsp"></property> </bean> 라고 선언하면 /WEB-INF/jsp/testfile.jsp은 비지니스 로직 내부에서 testfile로 간단하게 표현 가능 함
3. Inside Code spring web service는 아래의 흐름을 가집니다. ①(사용자) jsp 호출 ②(웹서버) 설정 검색 ③(웹서버) 요청 처리 클래스 호출 ④(웹서버) 비지니스 로직 수행 ⑤(웹서버) view로 결과 반환 ⑥(사용자) jsp 화면
1) Controller □ 사용자에게 jsp가 호출되면 xxxxx-servlet.xml에 정의된 클래스 빈을 호출합니다.
□ 예제에는 DB에 있는 정보를 가져다가 저장하는 페이지와 원하는 값을 저장하는 페이지 두가지가 있습니다. hello.jsp가 전자에 해당하고 priceincrease.jsp는 후자에 해당합니다. 각 페이지를 확인하시고 각 페이지의 핸들러 클래스 빈을 springapp-servlet.xml에서 추적해 보시길 바랍니다.
□ 일반적인 controller의 사용 예 : springapp.web.InventoryController.java . 일단 기본적인 Controller의 예시로 Controller interface를 구현합니다. 대부분의 경우에 사용하면 되고, request에 대한 처리를 위해 handleRequest()로 진입합니다. . 여기서 비지니스 로직을 처리한 후, ModelAndView 객체를 반환합니다. 이 때 넘기고자 하는 데이터를 파라미터에 담아서 보낼 수 있습니다.
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String now = (new java.util.Date()).toString(); logger.info("returning hello view with " + now);
return new ModelAndView("hello", "model", myModel); }
□ 폼을 처리하는 controller의 예 : springapp.web.PriceIncreaseFormController.java . jsp가 폼을 다루고 있을 경우에는 SimpleFormController Class를 상속하여 확장합니다. . onSubmit()은 jsp에서 버튼이 눌려진 경우 콜백 지점을 가리키도 formBacjingObject는 폼에 기본값을 저장하고자 할 때 사용합니다. . formBackngObject는 domain에 존재하는 모델링 객체를 이용하고 있음에 주의합니다.
public ModelAndView onSubmit(Object command) throws ServletException {
int increase = ((PriceIncrease) command).getPercentage(); logger.info("Increasing prices by " + increase + "%.");
productManager.increasePrice(increase);
logger.info("returning from PriceIncreaseForm view to " + getSuccessView());
return new ModelAndView(new RedirectView(getSuccessView())); }
2) Model □ 비지니스 로직을 수행 중에 데이터를 읽고 쓰고 수정하고 삭제하기 위해 데이터 베이스에 대한 접근을 수행합니다. 해당 예제는 HSQLDB를 사용하고 있으며 이를 JDBC로 연결하고 있습니다.
□ JDBC와 관련하여 몇개의 클래스를 추가 지원하고 있지만 미미합니다. 실제로는 iBatis, Hibernate를 지원하고 있다는 것이 더 큰 특징이라 하겠습니다.
□ 간단한 예제를 확인하시길 바라며, 이 부분은 설명하지 않겠습니다.
3) View □ 예제에서는 JSTL(Java Server page Standard Tag Library)이라는 것을 사용하고 있기에 약간의 공부가 필요합니다. . 예를 들면, <input type='text' /> 이렇게 사용하던 것을 <form:input path="percentage"/> 이런식으로 사용합니다. . iteration, print 같은 주요 제어문과 폼이 tag로 정리되어 있습니다. . 더 자세한 내용은 http://java.sun.com/products/jsp/jstl/ 참조 바랍니다.
4. Ending 이 문서의 목적은 spring을 자세하게 설명하는 것이 아니라, 튜토리얼데로 spring MVC를 간단하게 한번 만들어 보는 것에 그 의의를 두고 있습니다. 튜토리얼과의 차별화를 위해 Top-down 방식을 취했으며 전체의 구성을 설명하고자 했습니다. 저도 약 2주전부터 틈틈히 공부하면서 알게된 것을 정리한 것이라 부족한 면이 많습니다. 시간이 나는데로 잘못된 부분은 수정하고 필요한 내용은 추가하겠습니다. 긍적적이고 발전적인 커멘트를 기다립니다. 감사합니다.
Spring에서 DB에 연결하는 방법에 대해서 알아보려 합니다. 다음과 같이 세가지 방법이 있습니다. - JDBC를 이용하는 방법 - JdbcDaoSupport 클래스를 이용해서 JDBC를 조금 편하게 템플릿화하는 방법 - SqlMapClientDaoSupport 클래스를 이용해서 iBatis Framework를 연동하는 방법
각 방법이 어떻게 다른지를 설명드리고 튜토리얼 수준의 예제를 보여드리겠습니다.
1. JDBC
일반적으로 JDBC를 이용할 경우 아래의 순서를 따라서 구현됩니다. - DriverManager에 해당 DBMS Driver를 등록 - 해당 Driver로 부터 Connection 객체 획득 - Connection 객체로부터 Statement 객체 획득 - Statement의 method를 이용하여 SQL실행 - ResultSet 으로 받아서 처리(executeUpdate 의 경우엔 제외) - 객체 close() (ResultSet, Statement, Connection)
여기서 실제로 개발자의 비지니스 로직이 들어가는 부분은 4번과 5번의 일부입니다. 나머지는 음... 기계적인 코드입니다. 실제 코드를 예로 들면 아래와 같습니다.
Connection.java
......... Connection con = null;
Statement st = null;
ResultSet rs = null;
try {
con=DriverManager("jdbc:mysql://localhost/dbname","root","1234"); // dbname에는 사용하는 database 이름, root 계정, 패스워드는 1234
Statement st=con.createStatement();
ResultSet rs=st1.executeQuery("select * form names");
if( rs.next() ) {
do {
// result set을 잘 정리합니다. 물론 일일이
...
// 비지니스 로직을 수행합니다.
...
} while( rs.next() )
}
} catch (Exception ex) {
// 적절한 예외 처리
} finally {
if( rs != null) rs.close();
if( st != null ) st.close();
if( con != null ) conn.close();
} .........
의외로 너무 많은 부분인 반복되는 느낌입니다. 이런 부분은 Spring을 사용하면 많이 줄어들게 됩니다. 다음절에서 확인해 보지요.
2. DaoSupport in Spring Framework
Spring에는 Template이라는 것을 이용해서 이 과정을 알아서 처리해 줍니다.
- JdbcTemplate
- NamedParameterJdbcTemplate
- SimpleJdbcTemplate
이를 편하게 사용하기 위해서 주로 아래의 Dao 클래스를 이용합니다.
- JdbcDaoSupport
- NamedParameterJdbcDaoSupport
- SimpleJdbcDaoSupport
여기서 가장 다양한 기능을 가진 SimpleJdbcDaoSupport 클래스의 사용법을 코드에서 확인해 보도록 하겠습니다. (전체 코드는 이전 4번 튜토리얼 분석 포스트에서 사용했던 예제를 보시면 됩니다.)
public class JdbcProductDao extends SimpleJdbcDaoSupport implements ProductDao {
public int selectCount() { return getSimpleJdbcTemplate().queryForInt( "select count(*) from products"); }
}
음..확실히 간편해 진것 같습니다.
하지만, 쿼리문이 코드 내부에 하드코딩되어 있다는 점이 약간 아쉬운 부분입니다. 쿼리문 변경 시에 코드도 같이 변경되고 재컴파일도 되어야 합니다. (뭐 솔직히 컴파일 하면 되긴 해요... ^^) 그리고 따로 설명하지 않겠지만 ParameterizeRowMapper 인터페이스를 이용해서 domain 객체와 결과를 연결하는 방법이 있는데 이 역시 하드코딩 되기 때문에 유지 보수의 유연성이 떨어지는 면이 없지 않습니다.
그래서, 쿼리 및 쿼리의 결과와 객체간의 연결을 외부에서 따로 관리하는 기능을 요구하게 되고 이런 기능을 가진 iBatis가 최근 많이 사용되고 있습니다. 다음 절에서 iBatis의 연동에 대해 알아보겠습니다.
3. Spring Framework와 iBatis 연동
1) iBatis
국내 SI 현실에 가장 잘 어울린다고 평가받고 있는 persistance framework 입니다. 그 이유는 SQL 쿼리문을 그대로 사용하기 때문에 기존 JDBC 개발자들에게 거부감이 덜하고 경험적(?)인 시스템의 이해가 빠르기 때문일 겁니다. 여타의 ORM framwork는 배우기도 힘들고 또는 제 3자 입장에서 이해하기도 힘들어서 우리나라 SI 업계처럼 개발팀이 이합집산하는 문화에는 어울리지 않는다는 군요.
각설하고 간단한 예를 보도록 하지요. iBatis에 대해서는 제가 따로 설명하지 않을 것입니다. 아래의 자료들을 보시면 간단하게 이해하실 수 있을 겁니다. 그리고, googling 하시면 JPetStore라는 예제가 있습니다. 이를 한번 실행시켜 보시는 것도 도움이 될 것입니다.
다음은 iBatis 관련해서 많은 자료를 만드신 이동국님의 Tutorial 변역본입니다. 8장밖에 안되지만 iBatis의 동작에 대해서 이해하는데 많은 도움이 되실 것입니다.
자~! 이제 iBatis의 사용법에 대해서 간단히 감을 잡으셨나요? 앞 절에서 언급한 것처럼 제 생각에는 2가지의 큰 장점을 가진다고 생각됩니다. (다른 장점이 있으시면 사알짝 좀 알려주세요~~) - SQL 쿼리문이 외부 설정 파일에서 관리된다. - domain 객체와 SQL result set의 연결이 외부 설정 파일에서 관리된다.
그런데 JDBC와 마찬가지로 iBatis에도 단순하게 기계적으로 반복되는 코드가 있습니다. 바로 SqlMapClient를 선언하는 부분이지요! (아래 코드 참조)
JDBC를 지원하기 위해 JdbcDaoSupport 클래스가 있지요? 그럼 SqlMapClient를 지원해 주는 것은? 네! SqlMapClientDaoSupport 클래스 입니다. 그럼 드디어 sqlMapClientDaoSupport 클래스에 대해 알아보겠습니다.
2) sqlMapClientDaoSupport
앞서 알아본 JdbcDaoSupport와 이름도 비슷하지만 사용법도 매우 유사합니다. 설정 파일과 관련된 자바 코드를 보시지요. applicationContext.xml - sqlMapConfig.xml - Product.xml 이 연쇄적인 관계를 가지고 있습니다. 여기서 applicationContext.xml은 spring 설정 파일이고 나머지는 iBatis 설정 파일입니다. 비지니스 로직 수행 중 iBatisMessageDao의 함수들이 요청될 것이고 이떄 Product.xml에 있는 쿼리문들을 호출해서 수행하게 됩니다. 주석문을 달고 색깔로 구분해 놓았습니다. 연관 관계에 유의하시면서 주의 깊게 확인하시길 바랍니다. (오랜만에 칼라풀한 포스트 입니다. ^^)
<!-- saveProduct --> // saveProduct와 관련된 입력 값의 형태를 정의합니다. <parameterMap id="saveProductParamMap" class="Product"> <parameter property="id" /> <parameter property="description" /> <parameter property="price" /> </parameterMap>
// parameter를 지정하는 방식에 유의 하시길 바랍니다. <update id="saveProduct" parameterClass="Product" > update products set description = (#description#), price = (#price#) where id = (#id#) </update> </sqlMap>
iBatisMessageDao.java
// 코드 내부에는 전혀 쿼리 문이 없습니다!! 여기에 별 5개 꼭 확인하세요! public class iBatisProductDao extends SqlMapClientDaoSupport implements ProductDao {
@SuppressWarnings("unchecked") public List<Product> getProductList() { List<Product> products = getSqlMapClientTemplate().queryForList("getProductList");
return products; }
public void saveProduct(Product prod) { getSqlMapClientTemplate().update("saveProduct", prod); } }
2절에서 설명한 JdbcDaoSupport 클래스의 사용법과 비교했을 때 iBatis는 이를 한단계 더 추상화 되어 있음을 알 수 있습니다. 모든 쿼리문과 해당 쿼리 결과와 객체간의 관계를 XML 외부 설정으로 따로 관리하고 있다는 것이죠. 그렇기 때문에, 앞에서 말씀드린데로 이 방법은 java 코드내에 하드코딩하는 것보다 개발의 유연성을 높이고 추후 관리시에 유리한 장점을 가집니다. (추상화란 처음에는 귀찮고 나중에는 편리한 것이지요!)
다음은 이전 4번째 spring 프레임워크 포스트에서 사용했던 튜토리얼을 iBatis로 연동시킨 예제입니다. 위에 설명드린 내용이 어떻게 적용되어 있는지 한번 더 확인하실 수 있을 것으로 생각됩니다.
휴..정말 긴 튜토리얼 리뷰였습니다. 매일 생각없이 JDBC로 개발하던 저에게는 참으로 재미난 것이 아닐 수 없었습니다. 물론 때에 따라서는 JDBC 자체가 빛나는 순간이 있겠지만, 대부분의 경우에는 iBatis가 우리를 편하게 해주지 않을까 생각됩니다. iBatis 관련 공부 중 이런 글이 있었습니다. "iBatis는 80%의 JDBC 기능을 20%의 자바 코드로 구현한 간단한 프레임워크이다." 맞습니다. 이는 만병통치약이 아닙니다. 다만 대부분에 경우에 잘 먹히는 고마운 녀석인 것이지요. 뭐 종합감기약 정도 ^^; 그렇기 때문에 여러분도 한번 직접 경험해 보시고 개인적인 판단을 세우시길 바랍니다. 여러분에게 맞지 않을 수 있으니까요. 이상입니다. 감사합니다.
5. 참고자료 1) 웹 개발자를 위한 스프링 2.5 프로그래밍 (가메출판사, 최범균 지음)










































 springapp - aop.zip
springapp - aop.zip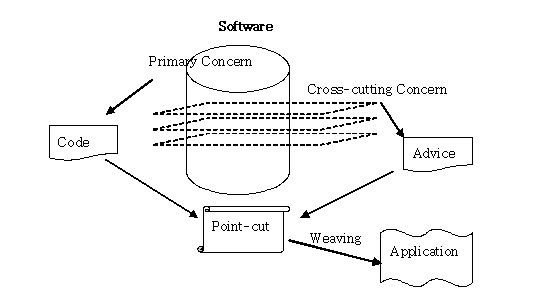
 iBATIS-SqlMaps-2-Tutorial_ko.pdf
iBATIS-SqlMaps-2-Tutorial_ko.pdf