'2008/08'에 해당되는 글 121건
- 2008.08.17 Spring 어플리케이션 프레임워크 모듈 구성
- 2008.08.17 Spring 이란?
- 2008.08.17 SpringFramework Helloworld 찍어보기
- 2008.08.17 톰켓을 사용하는데 필요한 20가지 Tips
- 2008.08.17 새로 보는 프로그래밍 언어
- 2008.08.17 Any_frame 샘플 레포트 화면
- 2008.08.17 Any_frame_설치완료 1
- 2008.08.17 Apache Ant 설치와 사용 (1.1 버전 기반)
- 2008.08.14 프로그래머가 되기 위한 방법
- 2008.08.12 We Solve Password Problems
- 2008.08.12 각종레퍼런스
- 2008.08.12 div 를 이용하여 가운데 배치하기
- 2008.08.12 Table 줄바꿈
- 2008.08.12 [css] 인쇄를 위한 스타일
- 2008.08.12 CSS & JAVASCRIPT 최적화 도구
- 2008.08.12 사용자 생성 및 계정 관리
- 2008.08.12 자바스크립트 그래프
- 2008.08.12 오른쪽 마우스 메뉴에 도스창 열기 추가하기
- 2008.08.12 Network Monitor(네트워크상의 트래픽보기)
- 2008.08.12 아파치 2.X 버전에서 mod_cband를 이용한 트래픽관리
- 2008.08.12 간단한 핸드폰게임 hex에디트 2
- 2008.08.12 효과적인 PE 파일 분석 도구 "PEiD" v0.94
- 2008.08.12 내컴에 깔려있는 프로그램 검색
- 2008.08.12 초간단 패킷 프로그램
- 2008.08.12 이더리얼 패킷분석
- 2008.08.12 패킷 분석 툴 ie 7 가능
- 2008.08.12 GWT(Google Web Toolkit)의 장점과 단점
- 2008.08.12 Google Web Toolkit
- 2008.08.12 개발자가 놓치기 쉬운 자바 의 기본원리
- 2008.08.12 Google Doctype
* 스프링이란?
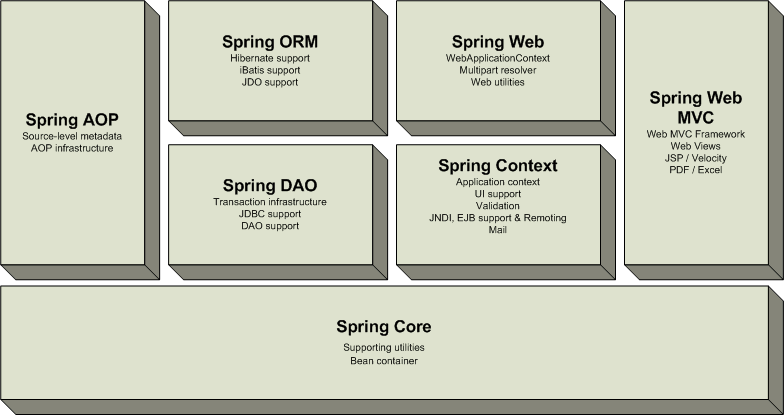
- 스프링(Spring)은 간단히 말하면 엔터프라이즈 어플리케이션에서 필요로 하는 기능을 제공
하는 프레임워크이다. 스프링은 J2EE가 제공하는 다수의 기능을 지원하고 있기 때문에,
J2EE를 대체하는 프레임워크로 자리 잡고 있다.
* 스프링 프레임워크 특징
- 스프링은 경량 컨테이너이다. 스프링은 자바 객체를 담고 있는 컨테이너이다. 스프링은 이들
자바 객체의 생성, 소멸과 같은 라이프 사이클을 관리하며, 스프링으로부터 필요한 객체를
가져와 사용 할 수 있다.
- 스프링은 DI(Dependency Injection) 패턴을 지원한다. 스프링은 설정 파일을 통해서 객체 간의
의존 관계를 설정할 수 있도록 하고 있다. 따라서 객체는 직접 의존하고 있는 객체를 생성 하거
나 검색할 필요가 없다.
- 스프링은 AOP(Aspect Oriented Programming)를 지원한다.스프링은 자체적으로 AOP를 지원
하고 있기 때문에 트랜잭션이나 로깅, 보안과 같이 여러 모듈에서 공통으로 필요로 하지만 실제
모듈의 핵심은 아닌 기능들을 분리해서 각 모듈에 적용할 수 있습니다.
- 스프링은 POJO(Plain Old Java Object)를 지원한다. 스프링 컨테이너에 저장되는 자바 객체
는 특정한 인터페이스를 구현하거나 클래스를 상속받지 않아도 된다. 따라서 기존에 작성한
코드를 수정할 필요 없이 스프링에서 사용할 수 있다.
- 트랙젝션 처리를 위한 일관된 방법을 제공한다. JDBC를 사용하든, JTA를 사용하든, 또는 컨테
이너가 제공하는 트랙잭션을 사용하든, 설정 파일을 통해 트랜잭션 관련 정보를 입력 하기
때문에 트랙잭션 구현에 상관없이 동일한 코드를 여러 환경에서 사용 할 수 있다.
- 영속성과 관련된 다양한 API를 지원한다. 스프링은 JDBC를 비롯하여 iBATIS, Hibernate,
JPA, JDO등 데이터베이스 처리와 관련하여 널리 사용되는 라이브러리와의 연동을 지원하고
있다.
- 다양한 API에 대한 연동을 지원한다. 스프링은 JMS, 메일, 스케쥴링 등 엔터프라이즈 어플리
케이션을 개발하는데 필요한 다양한 API를 설정 파일을 통해서 손쉽게 사용할 수 있도록 하고
있다.
* IoC(Inversion of Control)란?
- Spring 프레임워크가 가지는 가장 핵심적인 기능은 IoC(Inversion of Control)이다.자바가
등장한 최초에는 객체 생성 및 의존관계에 대한 모든 제어권이 개발자에 있었다. 그러나,
서블릿, EJB가 등장하면서 제어권이 서블릿과 EJB를 관리하는 서블릿컨테이너 및 EJB 컨테이
너에게 넘어가게 되었다. Spring 프레임워크도 객체에 대한 생성 및 생명주기를 관리할 수
있는 기능을 제공하고 있다. 이와 같은 이유때문에 Spring 프레임워크를 Spring 컨테이너,
IoC컨테이너와 같은 용어로 부르기도 한다.
: 물론 모든 객체에 대한 제어권을 컨테이너에게 넘겨버린 것은 아니다. 서블릿 컨테이너와 EJB
컨테이너에서도 서블릿과 EJB에 대한 제어권만 컨테이너가 담당하고 나머지 객체에 대한 제
어권은 개발자들이 직접 담당하고 있다. 이처럼 Spring 컨테이너 일부 POJO(Plain Old Java
Object)에 대한 제어권을 가진다. Spring컨테이너에서 관리되는 POJO는 각 계층의 인터페이
스를 담당하는 클래스들에 대한 제어권을 가지는 것이 대부분이다.
* Dependency Injection
- DI는 Spring 프레임워크에서 지원하는 IoC의 한 형태이다. DI를 간단히 말하면, 객체 사이의
의존관계를 객체 자신이 아닌 외부의 조립기(assembler)가 수행한다는 개념이다.
일반적인 웹어플리케이션의 경우 클라이언트의 요청을 받아주는 컨트롤러 객체, 비지니스
로직을 수행하는 서비스 객체, 데이터에 접근을 수행하는 DAO객체 등으로 구성된다.
만약, WriteArticleServiceImple클래스가 ArticleDao 인터페이스에 의존하고 있을 경우를 생각
해보자
의존관계를 형성하는 방법에는 아래와 같은 경우들이 있다.
첫번째, 코드에 직접 의존 객체를 명시하는 경우.
public class WriteArticleServiceImpl{
private Article articleDao = new MysqlArticleDao();
....
}
이 경우 의존하는 클래스가 변경되는 경우 코드를 변경해야 하는 문제가 있다.
두번째, Factory 패턴이나 JNDI등을 사용해서 의존 클래스를 검색하는 방법이 있다.
public class WriteArticleServiceImpl{
private ArticleDao articleDao = ArticleDaoFactory.create();
...
}
Factory나 JNDI를 사용하면 첫번째문제(즉, 의존 클래스가 변경되면 코드를 변경해야 하는
문제)를 없앨 수는 있지만, WriteArticleServiceImpl클래스를 테스트하려면 올바르게 동작하는
Factory또는 JNDI에 등록된 객체를 필요로 한다는 문제점이 있다.
세번째, DI패턴이다. 이 방식에서는 의존관계에 있는 객체가 아닌 외부 조립기(assembler)가
각 객체 사이의 의존 관계를 설정해준다.
WriteArticleServiceImpl클래스의 코드는 MysqlArticleDao 객체를 생성하거나 검색하기 위한
코드가 포함되어 있지 않다. 대신 조립기의 역할을 하는 Assembler가 MysqlArticleDao
객체를 생성한 뒤 WriteArticleServiceImpl객체에 전달해 주게 된다.
DI패턴을 적용할 경우 WriteArticleServiceImpl클래스는 의존하는 객체를 전달받기 위한 설정
메서드(setter method)나 생성자를 제공할 뿐 WriteArticleServiceImpl에서 직접 의존하는
클래스를 찾지 않는다.
* AOP(Aspect Oriented Programming)
- 로깅, 트랙잭션처리, 보안과 같은 핵심 로직이 아닌 cross-cutting concern(공통관심사항)을
객체 지향기법(상속이나 패턴등)을 사용해서 여러 모듈에 효과적으로 적용하는데 한계가 있었
으며, 이런 한계를 극복하기 위해 AOP라는 기법이 소개되었다.
공통관심사항(cross-cutting concern)을 별도의 모듈로 구현한 뒤, 각 기능을 필요로 하는 곳
에서 사용하게 될 경우, 각 모듈과 공통 모듈 사이의 의존관계는 복잡한 의존 관계를 맺게 된다.
AOP에서는 각클래스에서 공통 관심사항을 구현한 모듈에 대한 의존 관계를갖기보다는,
Aspect를 이용하여 핵심 로직을 구현한 각 클래스에 공통 기능을 적용하게 된다.
AOP에서는 핵심 로직을 구현한 클래스를 실행하기 전 후에 Aspect를 적용하고, 그 결과로
핵심 로직을 수행하면 그에 앞서 공통 모듈을 실행하거나 또는 로직 수행 이후에 공통 모듈을
수행하는 방식으로 공통 모듈을 적용하게 된다.
AOP에서 중요한 점은 Aspect가 핵심 로직 구현 클래스에 의존하지 않는다는 점이다. AOP에
서는 설정 파일이나 설정클래스 등을 이용하여 Aspect를 여러 클래스에 적용할 수 있도록
하고 있다.
스프링 공부를 하는데.. 아무리 이론을 봐도 무슨 말인지 하나도 모르겠고,
자바 처음 배우던 때를 떠올리며.. Helloworld를 찍어봐야겠다고 판단.
네이버에서 찾아 낸 Spring으로 Helloworld찍기.. 시킨대로 하니 화면에 뜨네. 휴.
자 그럼, 안 잊어 먹기 위해 나도 정리를 해놓자.
내 컴퓨터 환경은...
JDK1.5 + Tomcat 5.5 + SpringFramework 2.5.6 아 차,, + Eclipse는 Europa.
우선 스프링 프레임워크를 받으려면..
http://www.springframework.org/download 로 가서
spring-framework-2.5.6-with-dependencies 파일을 받는다.
뭘 받을지 모르겠음 멜 남기시고..
자 그럼 Eclipse 실행 시키고~ Dynamic Web Project를 만든다.
프로젝트 이름은 SpringHelloWorld 라고 지정.
Target Runtime은 Tomcat으로 하고 Finish.
lib폴더에 lib파일들을 넣는다.(제일 중요!!)
스프링 다운 받아서 압축 푼 폴더에 보면
spring-framework-2.5.6\dist\spring.jar 파일
: (스프링 프레임워크 lib파일)
spring-framework-2.5.6\lib\jakarta-commons\commons-logging.jar 파일
: (로그 사용을 위한 lib파일)
spring-framework-2.5.6\dist\modules\spring-webmvc.jar
: (컨트롤러 상속받기 위해서)
그리고 태그라이브러리 사용을 위한 jar파일을 받는다.
http://jakarta.apache.org/site/downloads/downloads_taglibs-standard.cgi
압축풀어 보면 standard.jar와 jstl.jar파일이있다.
이 아이들까지전부 lib폴더에넣는다..
그럼 web.xml파일부터 수정해보자.
<display-name>SpringHelloWorld</display-name>
<servlet>
<servlet-name>springapp</servlet-name>
<servlet-class>
org.springframework.web.servlet.DispatcherServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>springapp</servlet-name>
<url-pattern>*.htm</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
*.htm으로 들어오는 요청에 대해서 springapp서블릿을 사용하겠다는 얘기.
서블릿은 스프링 프레임워크에 있는 DispatcherServlet 이다.
DispatcherServlet의 제어 행위를 처리하는 설정 파일이 필요한데, 이것은 서블릿 이름에
-servlet.xml 을 붙여 작성한다. 그러니까 여기서는 springapp-servlet.xml 이겠지.
/WEB-INF/springapp-servlet.xml을 작성한다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="springappController" class="web.SpringappController"/>
<bean id="urlMapping"
class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
<property name="mappings">
<props>
<prop key="/hello.htm">springappController</prop>
</props>
</property>
</bean>
<bean id="viewResolver"
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass">
<value>org.springframework.web.servlet.view.JstlView</value>
</property>
<property name="prefix">
<value>/WEB-INF/jsp/</value>
</property>
<property name="suffix">
<value>.jsp</value>
</property>
</bean>
</beans>
잘 보면 beans태그안에 bean태그가 3개가있다.
첫 번째는 Controller인거 같고,,
두 번째는 urlMapping 시켜주는데 /hello.htm으로 요청이 들어오면 springappController에게
넘기라는 거 같다.
세 번째꺼는 선행자 후위자를 정한거네.
미리 써놓으면 항상 쓰이는 WEB-INF/jsp/파일이름.jsp 에서 앞 뒤 없이 이름만 써서 가능.
그럼 SpringappController.java를 작성해 보자.
이놈은 Controller라는 인터페이스를 상속받습니다.
web이라는 패키지를 생성 후 거기에다가 class를 생성합니다.
생성할 때 New Java Class화면에서 Interface부분에 Add버튼을 클릭해서
Controller를선택하고 추가 해주면 자동으로 생성됨.
package web;
import java.util.Date;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.mvc.Controller;
public class SpringappController implements Controller {
protected final Log logger = LogFactory.getLog(getClass());
public ModelAndView handleRequest(HttpServletRequest arg0,
HttpServletResponse arg1) throws Exception {
// TODO Auto-generated method stub
String now = (new Date()).toString();
logger.info("returning hello view with " + now);
return new ModelAndView("hello", "now", now);
}
}
시간을 리턴한다. new Date()로 시간을 생성해서 그걸 String변환 후 now 변수에 넣고,
로그를 기록한 후, return할때 now라는 변수는 now라는 이름으로 쓸 수 있게 hello파일에 넘김.
이 hello는 앞 뒤 합쳐서 /WEB-INF/hello.jsp 가 됨.
이제 /WEB-INF/jsp/hello.jsp 파일을 보자.
<%@ page language="java" contentType="text/html; charset=windows-31j"
pageEncoding="windows-31j"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=windows-31j">
<title>Hello :: Spring Application</title>
</head>
<body>
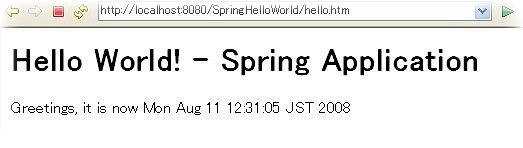
<h1>Hello World! - Spring Application</h1>
<p>Greetings, it is now <c:out value="${now}" /></p>
</body>
</html>
now라는 변수를 c:out태그로 출력한다. Controller에서시간을담아서 넘겨 받았다.
그리고 jsp파일을 WEB-INF폴더에 넣는 이유는 JSP파일접근에대한권한이 아마 우리한테 없고 Spring에게 넘겨서라고 내가 찾아 본 블로그 주인장은 말했다..
즉, 직접적으로 접근하지 못하도록 하려고?
was/SpringHelloWorld로 접속시 index.jsp를 실행하는데 파일이 없으니 하나 만들자.
폴더 위치 : WebContent/index.jsp
<head>와 </head> 사이에
<script>
location.href="hello.htm"
</script>
이렇게만 입력하면 자동으로 hello.htm으로 포워드 해준다.
그럼 실행!
이상.. Helloworld찍을 수 있게 도움 받은 블로그 Kyle's Home님께 감사드린다.
이 글의 내용도 Kyle's Home님의 글을 거의 그대로 옮겨 놓았다.
1. jdk 1.5이상이면 아래 설정을 JAVA_OPTS안에 추가한다면 YourKit을 가지고 힙덤프를 분석할 수 있다.
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/heapdump
2. Jasper 2 JSP Engine 지원을 위해 $CATALINA_BASE/conf/web.xml 설정 변경하라.
- development : false, genStringAsCharArray : true, modificationTestInterval : true, trimSpaces : true
- 자세한 건 여기를 참조하라.
3. 가용성 확보를 위해 Tomcat의 clustering/session replication을 사용하라.
- 사용방법은 여기를 참조하라.
4. error pages를 작성하여 적용하라.(web.xml)
- <error-page>
<error-code>404</error-code>
<location>/error/404.html</location>
</error-page>
5. 어플리케이션에서 System.out과 System.err를 제거하고 Log4j를 사용하라.
6. application마다 같은 라이브러리는 WEB-INF/lib에서 CATALINA_HOME/shared/lib로 옮겨서 공유하라.
- 메모리를 절약할 수 있다.
7. memory parameters를 잘 활용하라.
8. 불필요한 어플리케이션을 제거하라.
9. Manager서버의 보안을 강화하라.
- CATALINA_HOME/conf/tomcat-users.xml
<role rolename="manager">
<user username="darren" password="ReallyComplexPassword" roles="manager"></user>
</role>
- CATALINA_HOME/conf/server.xml에 IP 블럭킹 기능도 유용하다.
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="192.168.1.*"></Valve>
10. server.xml을 최적화 하라.
- 서버 환경에 맞는 CATALINA_HOME/conf/server-original.xml, CATALINA_HOME/conf/server-minimal.xml 선택하여 server.xml로 변경하라.
11. 톰켓 업그레이드는 설치디렉토리를 분리하여 적용하라.
12. Tomcat 서버는 root로 띄우지 마라.
- 자세한 내용은 여기를 참조하라.
13. Precompile JSPs (at build time)
- 자세한 내용은 여기를 참조하라.
14. 디렉토리 보이는 걸 막아라.
- CATALINA_HOME/conf/web.xml
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>false</param-value> <!-- make sure this is false -->
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
15. 듀얼 코어 CPU를 사용할 경우 쓰레드풀을 250개 이상 설정하라.
16. Tomcat MBeans이나 다양한 모니터링 도구를 활용하여 서버를 모니터링하라.
- 자세한 내용은 여기를 참조하라.
17. jdk1.5, 1.6이 성능이 좋다.
18. -server JVM option을 사용하라.
19. GZIP compression을 사용하라.
- <Connector>compression="on"
compressableMimeType="text/html,text/xml,text/plain,application/xml"
</Connector>
- 자세한 건 여기를 참조하라.
20. Security Manager를 잘 사용하라.
- 자세한건 여기를 참조하라.
출처 : http://blog.paran.com/pmang/21456729

개발자의 가치를 높이는 프로그래밍 언어 대백과
마이클 스콧 지음 | 민병호 김진혁 옮김 | 1004페이지 (부록CD 260페이지 추가수록)
45,000원 | 2008년 8월 21일 출간 예정
이 책을 한 마디로 표현해볼까요?
괴물!
프로그래밍 언어를 다룬 책 중에 여태까지 이런 책은 한 권도 없었습니다.
여기서 "이런"은 뭘 의미할까요? eRun? 자, 이제부터 차근차근 하나씩 설명해드리죠.
정말 몸값을 높이고 싶으신가요? 단지 코드 몇 줄을 잘 짠다고 몸값이 올라간다고 생각하시나요? 개발자로서 자신의 앎이 부족하다고 느끼신 적은 없으신가요? 학교에서 배우는 프로그래밍 언어론이 수박 겉핥기에 지나지 않는다고 느껴보신 적은 없습니까.
이 책의 원서 목차를 보고 난다긴다 하는 개발자분들이 모두 혀를 내두르셨습니다. 심지어 어떤 프로그래밍 언어를 전공하셨다는 일급 자바 개발자께선 "이런 '발칙한 책'을 봤나"라는 반응을 하실 정도였으니까요. (사실은 좀더 저급한 표현을 쓰셨지만, 여기서는 조금 정제해서 말씀드려야겠죠 -0-)


1부. 프로그래밍 언어의 기초에서는 컴파일러와 컴퓨터 아키텍처, 프로그래밍 언어 설계와 구현에 대한 기본기를 닦아줍니다. 2부. 프로그래밍 언어의 핵심요소에서는 명령형 언어 C와 C++등을 중심으로 프로그래밍 언어의 공통적인 사항과 기본 개념을 다룹니다. 이어지는 3부. 다른 관점에서 바라본 프로그래밍 모델에서는 함수형 언어, 논리형 언어, 병행 프로그래밍 등과 함께 이 책의 (원서) 개정판에서 추가된 내용으로 PHP, 루비, 파이썬 등 스크립팅 언어들까지 다루며 내용을 이어갑니다. 4부에서는 드디어 로우레벨 관점에서 바라본 프로그램 되짚기가 등장합니다. 중간언어 등을 훑어보며, 프로그램을 컴파일 후 기계어로 변환된 코드를 분석해 코드를 개선하는 프로그램 최적화까지 다루게 됩니다.
그야말로 프로그래밍 언어의 개념, 이론, 설계, 구현, 최적화 등 전체적인 프로그래밍 언어의 전반을 꿰뚫고 각 사례를 모든 프로그래밍 언어로 구현해 그 언어들의 강점과 취약점을 분석해줌으로써, 결국 개발자가 프로그래밍 과정에서 가장 적절한 언어를 어떻게 선택해내 얼마나 효율적인 프로그램을 만들 수 있을까를 알려주는 것을 최종 목표로 합니다.
이제 왜 책의 제목에 "새로 보는"이라는 수식어가 붙었는지 이해가 가세요? 저희도 처음엔 아주 쉽게 "완전정복"이라든가 "완벽 가이드" "총서" 등의 아주 식상한 문구를 생각했었습니다. 하지만 이 책은 기존에는 전혀 볼 수 없었던 프로그래밍 언어론에 대한 절대(!)적이고도 상식(!)적인 프로그래밍 언어 대백과라고 할 수 있습니다. 기존 관념을 깨고 혜안을 갖게 해주는, 프로그래밍 언어의 비밀을 한꺼풀 벗겨내는 책이거든요. 자, 이 정도면 왜 자신있게 여러분의 몸값을 높여주는 책이라고 큰 소리를 쳤는지 조금은 동의를 하시나요? 아직도 이해를 못 하시겠다면 8월 21일 서점에 가셔서 직접 확인하시기 바랍니다. :)
게다가 함께 제공하는 부록CD에는 책의 분량(이미 1004페이지, 천사에요. angel ^^)이 비대해지는 것을 막기 위해 중간중간 좀더 심도깊은 심화학습에 해당하는 내용을 옮겨 담았습니다. 260페이지에 달하는 분량인데요. 이것만 해도 웬만한 책 한 권 분량은 족히 됩니다. 부록 CD에는 그밖에도 공개 컴파일러와 해석기 링크 모음, 책에 나온 300개 이상의 코드의 완전한 소스파일 등이 가득가득 들어있습니다. 지금 CD 메뉴 내비게이션까지 한글로 옮겨내는 마무리 작업 중인데요. 독자를 감동시킬 만한 세심한 작업에 최선을 다하고 있습니다. 원서보다 나은 번역서, 에이콘 책이 늘 지향하는 바죠.
이 책을 번역한 역자 민병호님과 김진혁님은 강유님과 함께 『TCP/IP 완벽 가이드』를 공역하셨던 분들인데 드디어 이제 두 분만의 멋진 작품을 만들어내셨습니다. 그때만해도 대학원생 신분이셨는데 이제 한 분은 국방과학연구소에서 한 분은 삼성전자에서 열혈 근무중인 사회인이 되셨어요. 공교롭게도 이 분들의 번역 작품 두 권이 모두 1000페이지가 넘어가는 방대한 작업이었습니다. TCP/IP 완벽 가이드가 1,600쪽이었고, 이 책 『새로 보는 프로그래밍 언어』는 CD에 담긴 내용까지 합치면 1,260쪽을 넘어서니 정말 어마어마하죠. 그간 정말 고생 많으셨어요. TCP/IP 책을 마치고 출판사를 찾아오셔서 "한우 꽃등심 사주세요"하셨었는데, 이번에 책이 나오면 뭔가 미리 준비를 해둬야 할 것 같습니다. ㅎㅎ
제조물 책임법(Product Liability Law) 일명 PL법이라는 게 있습니다. "고양이를 렌지에 넣고 돌려 털을 말리지 마세요"(전자렌지)라든가 "에어콘에서 나오는 물은 마시지 마세요"(에어콘) 등 기상천외한 경고문을 삽입해둠으로써 소비자가 제품 오용으로 인한 피해를 막기 위하고 불가피한 소송을 피하기 위함이라고 하는데요. 정말 기상천외하고 황당한 경고문이 많습니다. 세상은 요지경이잖아요. 별의별 일이 다 일어나는 별천지 세상.
저희도 판권지쪽에 문구하나를 삽입해야 할까요?
"누워서 이 책을 읽으시다가 책을 놓치시면 머리에 심각한 상해를 입을 수 있습니다"
(대처법: 반드시 엎드려서 읽으세요!)
"베고 주무시다가 목 부분에 경련이 일어나 며칠간 고생을 할 수 있습니다"
(대처법: 좀더 얇은 다른 책을 고르세요.)
"책을 읽고 났는데도 가치가 높아지지 않았다구 느끼신다구요? 제대로 꼼꼼히 읽으셨는지 다시 한번 확인해보세요. 그럴 리가 없습니다. :) "
모두 열공하셔서 정말 훌륭한 개발자 되세요! 고고싱!!
- Apache Ant 설치와 사용 (1.1 버전 기반)
- Apache Ant는 Java기반의 빌드 도구이다.
- Ant의 주요 기능
자바 소스파일 컴파일
jar. war. ear. zip파일 생성
javadoc을 실행하여 도움말 생성
파일이나 폴더의 이동 및 복사, 삭제
각각의 작업에 대한 의존성 설정
유닉스에서 처럼 파일이나 폴더에 퍼미션 설정
파일의 변경 날짜를 설정하는 touch 기능
외부 프로그램의 실행
- Ant의 설치
다운로드 사이트 : http://ant.apache.org
zip파일을 적당한 디렉토리에 압축을 해제한다.
bin 디렉토리를 path에 추가합니다.
환경 변수 ANT_HOME을 Ant 인스톨된 장소의 디렉토리로 설정합니다.
추가로, 환경 변수 JAVA_HOME 을 설정합니다. 이것에는 JDK가 인스톨 된 장소의 디렉토리로 설정합니다.
- 시스템 요구사항
Ant 는, Linux, Solaris 나 HP-UX 라고 하는 상용 Unix, Windows 9x 및 NT, Novell Netware 6 , 그리고 MacOS X 등을 포함한 수많은 플랫폼에서 잘 사용되고 있습니다. Ant를 빌드해 사용하려면, 클래스 패스에 JAXP 호환의 XML 파서가 인스톨되어 이용 가능해야 합니다.
- PATH 설정하기
Windows OS :
설치된 디렉토리가 c:\ant\. 로 가정했을 경우에
set ANT_HOME=c:\ant
set JAVA_HOME=c:\jdk1.3.1
set PATH=%PATH%;%ANT_HOME%\bin
Unix(bash) OS :
export ANT_HOME=/usr/local/ant
export JAVA_HOME=/usr/local/jdk1.3.1
export PATH=${PATH}:${ANT_HOME}/bin
---------------------------------------------------------------------------------
FreeTTS Client/Server Demo 분석 중 실행에 필요한 Ant를 설치하느라고 네이버 블로거님들이 퍼나르던 좋은 정보를 필요한 부분만 발췌하였습니다.
1 도입 ¶
2.1.1 디버그 배우기 ¶
- 디버깅 도구 이용
- 프린트 줄 넣기(printlining) -- 프로그램을 임시로 고치는 것, 특히 필요한 정보를 프린트하는 줄을 추가하는 것
- 로그 기록 -- 로그 파일의 형태로 프로그램을 들여다볼 수 있는 영구적인 창을 만드는 것
2.1.2 문제 공간을 나눠서 디버그 하는 방법 ¶
2.1.3 오류를 제거하는 방법 ¶
2.1.4 로그를 이용해서 디버그 하는 방법 ¶
- 로그는 재현하기 힘든 (예를 들어, 개발 완료된 환경에서는 발생하지만 테스트 환경에서는 재현할 수 없는) 버그에 대한 유용한 정보를 제공할 수 있다.
- 로그는, 예를 들어, 구문(statement)들 사이에 걸리는 시간과 같이, 성능에 관한 통계와 정보를 제공할 수 있다.
- 설정이 가능할 때, 로그는 예기치 못한 특정 문제들을 디버그하기 위해, 그 문제들을 처리하도록 코드를 수정하여 다시 적용하지(redeploy) 않아도, 일반적인 정보를 갈무리할 수 있게 한다.
2.1.5 성능 문제를 이해하는 방법 ¶
2.1.6 성능 문제를 해결하는 방법 ¶
2.1.7 반복문을 최적화하는 방법 ¶
- 실수 연산(floating point operation)을 제거하라
- 필요 없이 메모리 블록을 새로 할당하지 말라
- 상수들을 미리 계산하라(fold together)
- I/O는 버퍼로 옮겨라
- 나눗셈을 피하라
- 쓸데없는 형변환(cast)을 피하라
- 첨자(index)를 반복 계산하는 것보다는 포인터를 옮기는 것이 낫다
2.1.8 I/O 비용을 다루는 방법 ¶
2.1.9 메모리를 관리하는 방법 ¶
2.1.10 가끔씩 생기는 버그를 다루는 방법 ¶
2.1.11 설계 기능을 익히는 방법 ¶
2.1.12 실험을 수행하는 방법 ¶
- 문서 내용에 부합하는지 검증하거나 (문서가 없다면) 시스템의 반응을 이해하기 위해 몇몇 표본들로 시스템을 검사하기
- 실제로 버그가 고쳐졌는지 알아보기 위해 코드의 바뀐 부분을 검사하기
- 시스템의 성능 특성을 완벽하게 알기 위해 두 가지 다른 조건에서 시스템의 성능을 측정하기
- 데이터의 무결성을 점검하기
- 어려운, 혹은 반복하기 힘든 버그 해결의 실마리를 얻기 위해 통계 자료를 수집하기
2.2.1 시간 추정이 중요한 이유 ¶
2.2.2 프로그래밍 시간을 추정하는 방법 ¶
2.2.3 정보를 찾는 방법 ¶
2.2.4 사람들을 정보의 원천으로 활용하는 방법 ¶
2.2.5 현명하게 문서화하는 방법 ¶
- 누군가 읽을 것이라는 사실을 염두에 두고 코드를 작성하기
- (앞에서 말한) 황금률을 적용하기
- 복잡하지 않은 해법을 선택하기 (다른 해법이 용케 더 빠르다 해도)
- 코드를 어지럽게 하는 사소한 최적화 시도는 포기하기
- 코드를 읽을 사람을 생각하면서 그 사람이 쉽게 이해할 수 있게 하기 위해 시간을 할애하기
- "foo", "bar", "doIt" 같은 함수명은 절대 쓰지 않기!
2.2.6 형편없는 코드를 가지고 작업하기 ¶
2.2.7 소스 코드 제어 시스템을 이용하는 방법 ¶
2.2.8 단위별 검사를 하는 방법 ¶
2.2.9 막힐 때는 잠깐 쉬어라 ¶
2.2.10 집에 갈 시간을 인지하는 방법 ¶
- 회사의 모든 사람들과 최대한 많이 대화하여 아무도 무슨 일이 일어나고 있는지에 대해 경영진을 현혹하지 못하게 하라.
- 시간을 추정하고 일정을 잡을 때 방어적이고 명백하게 하여, 모든 사람들이 일정이 어떻게 되고 현재 어디쯤 가고 있는지 잘 볼 수 있게 하라.
- 요구를 거부하는 법을 배우고, 필요하다면 팀이 함께 거부하도록 하라.
- 어쩔 수 없다면 회사를 그만두라.
2.2.11 까다로운 사람들과 상대하는 방법 ¶
3.1.1 의욕을 계속 유지하는 방법 ¶
- 그 일을 자랑스럽게 이야기한다.
- 새로운 기법, 언어, 기술을 적용할 기회를 찾는다.
- 각 프로젝트에서 아무리 작더라도 무엇인가를 배우거나 가르치려고 노력한다.
3.1.2 널리 신뢰받는 방법 ¶
3.1.3 시간과 공간 사이에서 균형을 잡는 방법 ¶
3.1.4 압박 검사를 하는 방법 ¶
3.1.5 간결성과 추상성의 균형을 잡는 방법 ¶
3.1.6 새로운 기능을 배우는 방법 ¶
3.1.7 타자 연습 ¶
3.1.8 통합 검사를 하는 방법 ¶
3.1.9 의사소통을 위한 용어들 ¶
3.2.1 개발 시간을 관리하는 방법 ¶
3.2.2 타사 소프트웨어의 위험 부담을 관리하는 방법 ¶
3.2.3 컨설턴트를 관리하는 방법 ¶
3.2.4 딱 적당하게 회의하는 방법 ¶
3.2.5 무리 없이 정직하게 반대 의견을 내는 방법 ¶
3.3.1 개발 시간에 맞춰 품질을 조절하는 방법 ¶
3.3.2 소프트웨어 시스템의 의존성을 관리하는 방법 ¶
- 그 구성요소에 있는 버그는 어떻게 고칠 것인가?
- 그 구성요소 때문에 특정 하드웨어나 소프트웨어 시스템만 사용해야 하는가?
- 그 구성요소가 기능을 완전히 상실한다면 어떻게 할 것인가?
3.3.3 소프트웨어의 완성도를 판단하는 방법 ¶
- 거품(vapor)은 아닌가? (약속만 있는 것은 완성도가 아주 떨어지는 것이다.)
- 그 소프트웨어에 대한 평판(lore)이 어떤지 알 수 있는가?
- 내가 첫 사용자인가?
- 개정판이 계속 나올 만한 충분한 동기(incentive)가 있는가?
- 유지 보수 노력이 계속되고 있는가?
- 현재 유지 보수 담당자가 없어도 사장되지 않을 것인가?
- 절반밖에 안 좋더라도 익숙한 다른 대안(seasoned alternatives)이 있는가?
- 부족(tribe)이나 회사에서 그것에 대해 알고 있는가?
- 부족이나 회사에서 추천할 만한가?
- 문제가 있어도 그것을 해결할 만한 사람을 채용할 수 있는가?
3.3.4 구입과 개발 사이에서 결정하는 방법 ¶
- 자신의 필요와 그 소프트웨어가 설계된 목적이 얼마나 잘 맞는가?
- 구입한 것 중 얼마만큼이 필요할 것인가?
- 통합의 가치를 검토하는 데 드는 비용은 얼마나 되는가?
- 통합하는 데 드는 비용은 얼마나 되는가?
- 구입하게 되면 장기적 유지 보수 비용은 증가할 것인가, 감소할 것인가?
- 그것을 구입함으로써 사업상 원치 않는 처지에 있게 되지는 않을 것인가?
3.3.5 전문가로 성장하는 방법 ¶
3.3.6 면접 대상자를 평가하는 방법 ¶
3.3.7 화려한 전산 과학을 적용할 때를 아는 방법 ¶
- 캡슐화가 잘 되어 있어서, 다른 시스템에 미칠 위험 부담이 적고, 복잡도나 유지 보수 비용의 증가가 적은가?
- 그 이득이 대단한가? (예를 들어, 기존의 것과 유사한 시스템이라면 두 배, 새로운 시스템이라면 열 배 정도의 이득)
- 그것을 효과적으로 검사하고 평가할 수 있을 것인가?
3.3.8 비기술자들과 이야기하는 방법 ¶
4.1.1 어려운 것과 불가능한 것을 구분하는 방법 ¶
4.1.2 내장 언어를 활용하는 방법 ¶
4.1.3 언어의 선택 ¶
- 서로 다른 표기법으로 작성된 구성요소들은 필연적으로 결합도(coupling)가 낮아진다. (깔끔한 인터페이스는 없겠지만)
- 각 요소들을 개별적으로 재작성함으로써 새로운 언어/플랫폼으로 발전시키기 쉽다.
- 실제로는 어떤 모듈들이 최신의 것으로 갱신되었기 때문일 수도 있다.
4.2.1 작업 일정의 압박과 싸우는 방법 ¶
4.2.2 사용자를 이해하는 방법 ¶
- 사용자는 일반적으로 짧게 말하고 끝낸다.
- 사용자는 자기 일이 따로 있다. 그들은 대개 제품이 크게도 아니고 약간 개선되었으면 좋겠다고 생각한다.
- 사용자는 그 제품 사용자들 전체를 볼 수 있는 눈이 없다.
4.2.3 진급하는 방법 ¶
4.3.1 재능을 개발하는 방법 ¶
4.3.2 일할 과제를 선택하는 방법 ¶
4.3.3 팀 동료들이 최대한 능력을 발휘하게 하는 방법 ¶
4.3.4 문제를 나누는 방법 ¶
4.3.5 따분한 과제를 다루는 방법 ¶
4.3.6 프로젝트를 위한 지원을 얻는 방법 ¶
4.3.7 시스템이 자라게 하는 방법 ¶
4.3.8 대화를 잘 하는 방법 ¶
4.3.9 사람들에게 듣고 싶어 하지 않는 말을 하는 방법 ¶
4.3.10 관리상의 신화들을 다루는 방법 ¶
- 문서는 많이 만들수록 좋다. (그들은 문서를 원하지만, 그들은 문서를 작성하는 데 시간을 쓰는 것을 원하지 않는다.)
- 프로그래머들은 다 같다. (프로그래머들도 천차만별로 다르다.)
- 지연되는 프로젝트에 새로운 자원을 투입해서 진척 속도를 높일 수 있다. (새로 들어온 사람들과 대화하는 데 드는 비용은 거의 항상 도움이 되기보다는 부담이 된다.)
- 소프트웨어 개발 시간을 확실히 추정하는 것이 가능하다. (이론적으로도 불가능하다.)
- 프로그래머의 생산성은 코드의 줄 수와 같은 간단한 척도로 측정될 수 있다. (간결한 것을 중시한다면 코드의 줄 수가 늘어나는 것은 좋은 것이 아니라 나쁜 것이다.)
4.3.11 조직의 일시적 혼돈 상태를 다루는 방법 ¶
5.1 책 ¶
5.2 웹 사이트 ¶
6.1 피드백 및 확장 요청 / Request for Feedback or Extension ¶
- 쉽게 읽을 수 있는 목록이 각 단락에 추가됨.
- 더 많은, 더 좋은 단락이 추가됨.
- 비록 단락 단위로 번역되는 한이 있더라도 다른 언어로 번역됨.
- 틀린 점이나 보충할 것이 추가됨.
- 팜(PDA의 한 종류) 문서나 더 나은 HTML 같이 다른 문서 형식으로 변환될 수 있게 됨.
6.2 원본 / Original Version ¶
6.3 원저자의 경력 / Original Author's Bio ¶
Subject: RE: Your essay translated into Korean! Date: Wed, 7 Jan 2004 09:28:48 -0600 From: <Read@hire.com> To: <*******> Thank you! I am thrilled and honored that this would be done. I hope it benefits some Korean speakers who do not read English well enough to enjoy the original. Unfortunately, I do not speak Korean---yet. I do plan to study it before I reach old age, but there are several other languages that I would like to master first. It is my understand that the Korean writing sysem (Han Gul?) is a great acheivement of human invention and the Korean people. -----Original Message----- From: ******* Sent: Wednesday, January 07, 2004 7:49 AM To: Rob Read Subject: Your essay translated into Korean! Thank you for your insightful essay, "How to be a Programmer." Finally it's been translated into Korean on a Wiki site. You can read it, if you can read Korean ;-), on http://wiki.kldp.org/wiki.php/HowToBeAProgrammer
Forgot your password? Need to regain access to password-protected files or systems? Passwords list destroyed?
Passware software recovers or resets passwords for Windows, Word , Excel, QuickBooks, Access, PDF and more than 100 document types.
|
Windows Key
Quickly and easily reset Windows login passwords in a matter of minutes – no need to reinstall the system.
|
||
|
Office Key
Recovers all types of passwords for MS Office documents: Excel, Word, Outlook, Access, PowerPoint and Visual Basic for Applications (VBA).
|
||
|
Passware Kit Enterprise
A complete password recovery solution that supports more than 100 document types.
|
Q : 파일 다운로드시 한글파일의 경우 다운로드 되지 않거나 글자가 깨집니다.
A : 익스플로러 "도구 > 인터넷 옵션 > 고급 "에서 고급 UTF8옵션 해제하시면 됩니다.
최종수정일자 : 2008.01.18 14:49:11
출처 : http://www.ihelpers.co.kr/programming/reference/index.php
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Vertically and Horizontally Centering a DIV</title>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-1" />
<script type="text/javascript" src="/mint/mint.js.php"></script>
<style type="text/css">
body {
font-size: 12px;
font-family: arial, helvetica, sans-serif;
color: #333;
}
p {
margin: 1em;
}
.comments {
background-color: #e3e3e3;
border-top: 1px solid #ccc;
border-bottom: 1px solid #ccc;
padding: 2px;
}
#mydiv {
position:absolute;
top: 50%;
left: 50%;
width:30em;
height:18em;
margin-top: -9em; /*set to a negative number 1/2 of your height*/
margin-left: -15em; /*set to a negative number 1/2 of your width*/
border: 1px solid #ccc;
background-color: #f3f3f3;
}
</style>
</head>
<body>
<div id="mydiv">
<p>This is a vertically and horizontally centered <div> tag. Try resizing your browser.</p>
<div class="comments">
<p><strong>Comments:</strong></p>
<p>Tested in: <span style="color: darkblue">Firefox, IE6, Opera 7, NN4.7, NN7, and Mozilla 1.2.</span><br />
Works in: <span style="color: darkblue">Firefox, IE6, Opera 7, NN7, and Mozilla 1.2.</span><br />
Doesn't work in: <span style="color: darkblue">NN4.7</span></p>
<p>© Copyright 2003, <a href="/">Infinity Web Design</a></p>
</div>
</div>
</body>
</html>
1. 소스
<html>
<head>
<title>Bizest 체험관 - KIS</title>
<meta http-equiv="Content-Type" content="text/html; charset=euc-kr">
<link rel="alternate" type="application/rss+xml" href="/rss/" title="RSS feed for Bizest KIS"/>
<link rel="stylesheet" type="text/css" href="/skin/x4/css/blue.css" />
<link rel="stylesheet" type="text/css" href="/skin/x4/css/layout.css" />
<link rel="stylesheet" type="text/css" href="/skin/x4/css/form.css" />
<link rel="stylesheet" type="text/css" href="/skin/x4/css/form.css" />
<link rel="stylesheet" media="print" type="text/css" href="/skin/x4/css/print.css" />
print.css
body {
/*
font-family:"Times New Roman", serif;
font-size:12pt;
*/
background:none;
margin-left: 20px;
margin-top: 10px;
margin-right: 20px;
margin-bottom: 10px;
}
#container {
width:100%;
}
#container_head {
DISPLAY: none;
}
#container_body .left {
DISPLAY: none;
}
#container_body {
width:100%;
}
#container_body .right {
width:100%;
}
#container_footer {
DISPLAY: none;
}
출처 : http://www.ihelpers.co.kr/programming/tipntech.php?CMD=view&TYPE=0&KEY=&SC=S&&CC=&PAGE=1&IDX=639
- JS Minifier
- JSMin
- JSLint : JavaScript Verifier
- Javascript compressor : JavaScript 압축 도구
- CSS & JavaScript Compressor : CSS & JavaScript 압축 도구
- ShrinkSafe : JavaScript 압축 도구
- Huffman JavaScript Compression
- SOC (Safe Obfuscator/Compressor)
- ANT 프로젝트 구축으로 로컬에서 자유자제로 JavaScript 압축 : 여기
- CSS OPTIMIZER : CSS파일의 사이즈를 압출해주는 툴
- CSS compressor : CSS 압축기
- ROBSON CSS COMPRESSOR : CSS 압축도구
- CSS DRIVE CSS COMPRESSOR : CSS 압축도구
- CSS Compressor from Lottery Post : CSS 압축기
- FLUMPCAKES CSS OPTIMIZER : CSS파일을 최적화 도구
- CSS ANALYZER : URL방식으로 CSS를 Validation
- CSS TIDY : open source 기반의 CSS parser와 optimizer
- 온라인으로도 최적화 사이트
- CLEAN CSS : CSS를 formatting하고 optimizing하는 온라인 도구
- CSSCHECK : URL기반으로 CSS파일을 기입하면 코드에 대한 피드백을 리포팅합니다. Warning과 에러 정보를 제공합니다.
- Code Beautifier (Based on CSS Tidy)
- CSS Optimizer : 다운로드 클라이언트를 사용하여 CSS를 최적화함
출처 : http://www.mimul.com/pebble/default/2008/01/29/1201616760000.html
사용자 생성 및 계정 관리
1. 계정 조회
현재 시스템에 로그인된 사용자 계정을 조회 / 사용자 계정에 대한 정보를 확인
cat –n /etc/passwd
root : x : o : o : root : /root : /bin/bash
1 2 3 4 5 6 7
1 : 사용자명
2 : 패스워드 (/etc/shadow 파일에 암호화되어 있음)
3 : 사용자 계정 uid
4 : 사용자 계정 gid
5 : 사용자 계정 이름 정보
6 : 사용자 계정 홈 디렉토리
7 : 사용자 계정 로그인 셀
cat –n /etc/shadow
root : #$%!234^x13 : 11535 : o : 99999 : 7 : : : :
1 2 3 4 5 6 7 8 9
1 : 사용자명
2 : 패스워드
3 : 패스워드 파일 최종 수정일
4 : 패스워드 변경 최소일
5 : 패스워드 변경 최대일
6 : 패스워드 만료 경고 기간
7 : 패스워드 파기 기간 (패스워드 파기 후 계정 비활성 기간)
8 : 계정 만료 기간
9 : 예약 필드
2. 계정 생성 및 암호 설정
useradd 생성할 계정명
passwd 생성한 계정명
useradd [옵션] 로그인 계정
-c comment : 사용자 이름 또는 정보
-d home_directory : 사용자 계정 홈 디렉토리
-e expire_date : 사용자 계정 유효 기간
-f inactive_time : 비활성 기간
-g initial_group : 기본 그룹
-G grout : 다음 그룹
-s shell : 기본 로그인 셀
-u uid : 사용자 계정 uid
3. 계정 변경
usermod [옵션] 로그인 계정
-c comment : 사용자 이름 또는 정보
-d home_directory : 사용자 계정 홈 디렉토리
-e expire_date : 사용자 계정 유효 기간
-f inactive_time : 비활성 기간
-g initial_group : 기본 그룹
-G grout : 다음 그룹
-s shell : 기본 로그인 셀
-u uid : 사용자 계정 uid
usermod –d /home/user –m user
usermod –e 2003-04-05 user
usermod –f 3 user
usermod –g users user
4. 계정 삭제
userdel –r 계정 (-r : 해당 계정자의 홈디렉토리까지 한 번에 삭제)
5. 그룹조회
cat –n /etc/group
6. 그룹생성
groupadd [-g GID [-o]] 그룹 id (-o : GID 499이하 값으로 지정)
[-r] 그룹 id 499이하 값으로 자동 지정
[-f] 강제로 생성
groupadd –g 900 toheart (900 – groupid / toheart – 그룹명)
7. 그룹변경
groupmod [-g gid [-o]] gid변경
[-n] 새로운 그룹명으로 변경
groupmod –g 700 toheart
groupmod –n kkum toheart
8. 그룹삭제
groupdel group group 제거
출처 : http://cafe.naver.com/frody.cafe?iframe_url=/BoardRead.do%3Farticleid=11
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title> obxGetColor, obxStickGraph</title>
<meta http-equiv="content-type" content="text/html; charset=euc-kr" />
<script>
IE=(window.showModalDialog) ? true : false;
function obxGetColor(color,gap) {
var rtn='',col,tmp;
for(var x=0;x <6; x+=2) {
col=parseInt(color.substr(x,2),16)+gap;
if (col > 255) col = 255;
else if (col < 0) col=0;
if(col < 10) rtn+='0'+col.toString(16);
else rtn+=col.toString(16);
}
return rtn;
}
function obxStickGraph(dsize) {
this.step=3;
this.speed=10;
this.total=0;
this.max=0;
this.dsize=dsize;
this.statictext=false;
this.item= new Object();
this.add = function (id,size,color,text) {
this.total += size;
this.max=Math.max(this.max,size);
this.item[id]= {'size' : size, 'color' : color.replace('#',''), 'text' : text}
}
this.draw = function (id,action) {
var dColor=obxGetColor(this.item[id].color,-20);
document.write("<div></div>");
//this.item[id].div=document.body.appendChild(document.createElement('div'));
var divs=document.getElementsByTagName('div');
this.item[id].div=divs[divs.length-1];
this.item[id].div.style.borderLeft="1px solid #"+dColor;
this.item[id].div.style.overflow="hidden";
this.item[id].div.style.height="11px";
if(!action) this.actDraw(id);
else this.actDraw(id,5);
}
this.getCss= function(width,height,color,bwidth,bcolor) {
if(width<1)width=1;
return "overflow:hidden;width:"+width+";height:"+height+";background-color:"+color+";border-right:"+bwidth+"px #"+bcolor+" solid";
}
this.actDraw= function(id,limit) {
var pp = this.item[id].size / this.total;
var sizep = this.item[id].size / this.max;
if(!limit) var size=this.dsize * sizep;
else size=limit;
var hit = Math.round(this.max/this.dsize*size);
var percent =(Math.round(this.max/this.dsize*size)/this.total*100).toString().match(/[0-9]*(?:\.[0-9][0-9])?/);
var text = (this.item[id].text) ? this.item[id].text.replace('#',hit).replace('$',percent) : percent + " %"
var Color=this.item[id].color;
var hColor=obxGetColor(Color,20);
var hhColor=obxGetColor(Color,30);
var dColor=obxGetColor(this.item[id].color,-20);
var add='',d;
if(IE || opera) d=new Array(3,2,1);
else d=new Array(3,4,5);
this.item[id].div.innerHTML= ''
+'<div style="'+this.getCss(size-d[0],1,hColor,1,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[1],2,hColor,3,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[2],2,hColor,5,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[2],1,hhColor,5,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[2],2,Color,5,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[1],2,Color,3,hhColor)+'"></div>'
+'<div style="'+this.getCss(size-d[0],1,dColor,1,hhColor)+'"></div>'
+'<span style="position:relative;top:'+(-11-IE)+'px;left:'+(((this.statictext)?this.dsize*sizep:size)+5)+'px;font:7pt verdana">'+text+'</span>'
if(limit)
if(this.dsize * sizep > limit) {
obxStickGraphRunObject=this;
setTimeout('obxStickGraphRunObject.actDraw("'+id+'",'+(limit+this.step)+');',this.speed);
}else{
setTimeout('obxStickGraphRunObject.actDraw("'+id+'");',this.speed);
}
}
}
grp=new obxStickGraph(200) ;
grp.add('id1',100,'F8CF7B');
grp.add('id2',200,'#D1D3D3');
grp.add('id3',500,'FDB480','# hit ($ %)');
grp.add('id4',300,'3399ff','# hit');
</script>
<style>
td {font: 11px gulim}
</style>
</head>
<body>
<table>
<tr>
<td>
항목 1
</td>
<td width="300">
<script>grp.draw('id1',true);</script>
</td>
<td>
동적 드로우, 기본출력
</td>
</tr>
<tr>
<td>
항목 2
</td>
<td>
<script>grp.draw('id2');</script>
</td>
<td>
정적 드로우, 기본출력
</td>
</tr>
<tr>
<td>
항목 3
</td>
<td>
<script>grp.draw('id3',true);</script>
</td>
<td>
동적 드로우, "# hit" 출력
</td>
</tr>
<tr>
<td>
항목 4
</td>
<td>
<script>grp.draw('id4');</script>
</td>
<td>
정적 드로우, "# hit" 출력
</td>
</tr>
</table>
<xmp>
생성 :
<script>
grp=new obxStickGraph(200) ;
//젤 긴게 200px 만하게 grp란걸 만든다 (그래프 길이"만" 입니다, 글자 때문에 더 깁니다.)
grp.add('id1',100,'F8CF7B');
//그 grp로 명령을 내립니다.
// "id1" 아이디로 100이란 값을 넣어준다 이때 색은 F8CF7B로
//색은 조금 어두운 부분(그래프 밑부분)색입니다
grp.add('id2',200,'#D1D3D3');
grp.add('id3',500,'FDB480','# hit ($ %)');
// 4번째 인자는 출력 문잡니다. #은 값으로 $는 퍼센트값으로 바뀝니다
grp.add('id4',300,'3399ff','# hit');
</script>
출력 :
<script>
grp.draw('id1',true);
//아이디에 해당되는 그래프를 출력합니다,
//이때 두번째 인자는 옵션이고 true로 해주면 동적으로 그립니다.(비추-_-;)
</script>
동적옵션코드 :
<script>
grp.step = 3;
grp.speed = 10;
//그려주기(grp.draw()) 전에 이런 코드를 넣어주셔도 됩니다.
//동적으로 그릴때 쓰는 옵션인데
//스텝은 한번에 늘어나는 길이(픽셀)고, 스피드는 한번 돌아가는;; 속도입니다. 적을수록 빠르고 0이 최소값입니다.
+yser님의 조언
grp.statictext=true
//텍스트 표시를 정적으로 합니다.
</script>
</xmp>
</body>
</html>
00 오른쪽 마우스 메뉴에 도스창 열기 추가하기
원문 : http://kkamagui.springnote.com/pages/392898
참고 : http://zextor.tistory.com/2669790
들어가기 전에...
- 이 글은 kkamagui에 의해 작성된 글입니다.
- 마음껏 인용하시거나 사용하셔도 됩니다. 단 출처(http://kkamagui.tistory.com, http://kkamagui.springnote.com)는 밝혀 주십시오.
- 기타 사항은 kkakkunghehe at daum.net 이나 http://kkamagui.tistory.com으로 보내주시면 반영하겠습니다.
1.추가 방법
DOS 시절부터 컴퓨터를 이용하였거나 프로그래머 개발자의 경우 아직도 Dos이용하고 있습니다.
하지만 DOS를 실행하고 원하는 폴더에 접근하기 위해서는 원도우키 + R 또는 [시작]→[실행] 후 “ CMD “ 를 입력 후 도스창이 실행되면 CD 명령어를 이용하여 원하는 폴더에 이동할 수 있습니다.
레지스트리를 수정하여 탐색기를 이용하여 먼저 가고자 하는 폴더에 접근 후 DOS를 실행 하여 바로 해당 폴더의 경로로 연결되어 사용하기 편리합니다.
1. [시작]→[실행]에서 “regedit “를 입력하고 레지스트리 편집기를 실행한 후, 다음 키 값을 찾는다. HKEY_CLASSES_ROOT\Directory\shell
2. Shell 키 위에서 마우스 오른쪽 마우스 클릭(또는 shell 키 선택 후 오른쪽 공백에서 오른쪽 마우스 클릭) 후 [새로 만들기(N)] → [키]를 선택합니다.
3. 새로운 키의 이름을 DOS(이름은 원하시는 이름으로 하셔도 됩니다.)로 수정합니다.
4. 만들어진 DOS 키를 클릭 후 오른쪽의 기본값을 더블 클릭하여 오른쪽 마우스에 표시될 이름을 입력하여 주십시오. ( 예를 들어 도스창이라 입력합니다. )
5. 다음 새로 만들어진 DOS에서 Shell 과 마찬가지로 새로운 키를 만들어 Command 이름으로 수정합니다. ( DOS 와는 달리 반드시 command 이름으로 하여야 합니다. )
6. 만들어진 Command 키를 클릭 후 오른쪽의 기본값을 더블 클릭하여 cmd.exe /k cd "%1" 이라는 문자열을 입력하여 주십시오.
7. 컴퓨터를 재 시작하여 탐색기 실행 후 가고자 하는 폴더를 선택 후 오른쪽 마우스 클릭 후 도스창을 클릭하시면 해당 폴더의 경로로 도스창이 열리는 것을 확인 할 수 있습니다.
본 자료는 (주)웰비아닷컴 의 커뮤니티 - 활용팁 에서 스크랩한 것입니다.
이 자료 외에도 많은 정보가 있으니 필요하신 분은 직접 방문해 보시길 바랍니다.
본 페이지에서는 재부팅 후에 사용할 수 있다고 기술하였지만 바로 사용하고 싶으시면 아래와 같이 해주시면 됩니다.
1. '시작' 이 있는 작업표시줄에 마우스 오른쪽 버튼을 눌러 작업관리자를 띄움니다.
2. 프로세스 탭에서 explorer.exe 를 선택하여 프로세스 끝내기를 합니다. 경고가 뜰 경우 그냥 "예" 를 선택하십시오.
3. 그럼 밑에 작업표시줄이 없어질 것 입니다.
4. 그럼 아까 작업관리자의 응용 프로그램 탭으로 이동한 후 새 작업을 클릭합니다.
5. 열기 옆에 있는 입력창에 "explorer" 를 입력합니다.
6. 이제 탐색기의 오른쪽 메뉴에 DOS를 사용할 수 있습니다.
Network Monitor (Netmon)는 네트워크 프로토콜 트래픽 분석 유틸리티입니다.
Network Monitor 3.1 을 사용해서 네트워크 프로토콜을 수집하는 몇 가지 방법을 정리하였습니다.
Netmon 2.x와 3.x의 가장 큰 변화는 캡쳐 필터링이라고 생각합니다.
캡쳐 필터링 옵션 변화에 따른 패킷 수집 방법을 사례 별로 아주 기본적인 테스트를 해 봅니다.
일반적으로 Netmon 트래픽을 수집하기 위해서는 Client와 Server 측에서 함께 로그 수집을 해야
문제 해결을 위한 보다 정확한 데이터를 얻을 수 있습니다.
아래 그림은 Netmon 3.1 인터페이스입니다.
Catpure Filter 제어, Frame Summary, Frame Details, Hex Details 값을 바로 확인할 수 있습니다.
Capture Filter 에 Filter 구문을 작성한 뒤 반드시 Verify, Apply 하여 체크 및 필터를 적용해야 합니다.
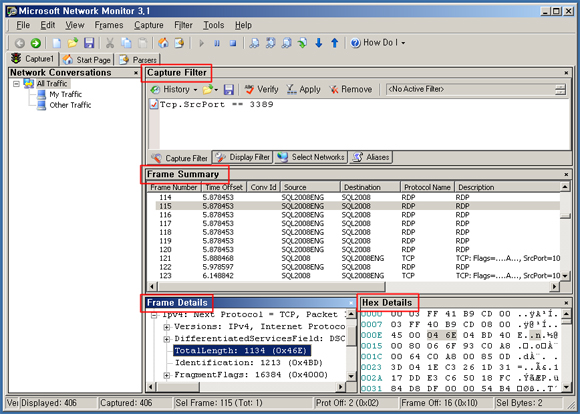
[환경]
Server : 192.168.0.100
Client : 192.168.0.133
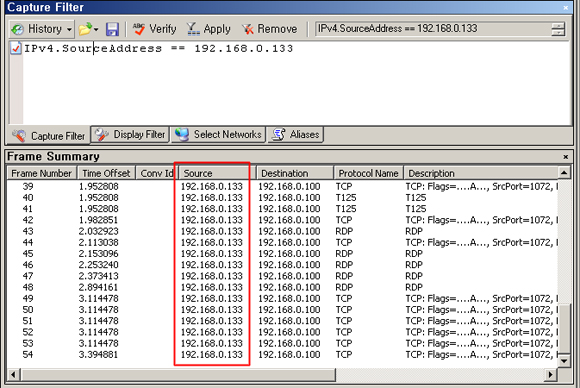
Case 1. 특정 Source IP Address(192.168.0.133) 에서 유입되는 Packet 확인
Client 에서 Server 로 터미널 서비스 접속을 시도 하였습니다.
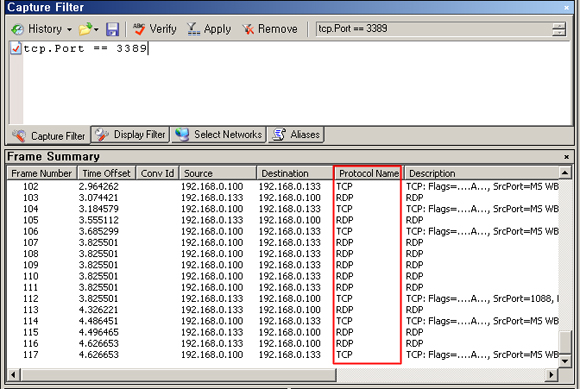
Case 2. TCP Source Port 가 3389인 frame 확인
Client 에서 Server 로 터미널 서비스 접속을 시도 하였습니다.
Case 3. 3389 port Packet은 캡쳐하지 않음
터미널 서비스 3389 포트 커넥션을 시도 하였으나 아래 그림과 같이 캡쳐되지 않습니다.
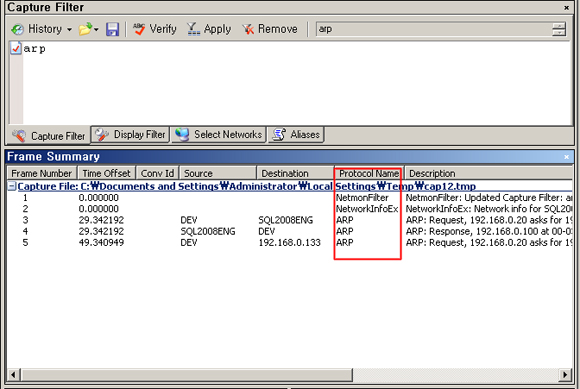
Case 4. ARP Packet 찾기
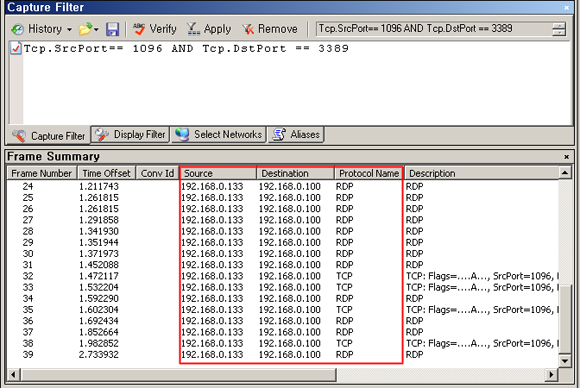
Case 5. Source Port 1096, Destination Port 3389 과 일치하는 Packet
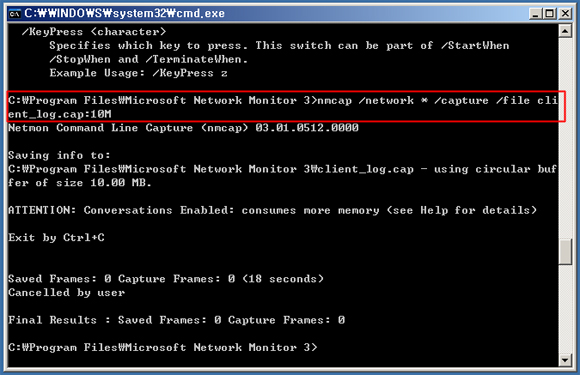
Case 6. Command 명령을 이용한 Packet 수집
수집이 완료되면 Ctrl + C 를 입력하여 수집을 중지합니다.
자, 수집을 하셨으니 이제 분석을 해야겠죠?
누가하죠? 어떻게?.... What?
약은 약사에게 패킷 분석은 과장님에게 ^^;
[참고자료]
Microsoft Network Monitor 3.1
http://www.microsoft.com/downloads/details.aspx?familyid=18b1d59d-f4d8-4213-8d17-2f6dde7d7aac&displaylang=en
The Basics of Reading TCP/IP Traces
http://support.microsoft.com/kb/169292/en-us
Explanation of the Three-Way Handshake via TCP/IP
http://support.microsoft.com/kb/172983/en-us
Into to Filtering with Network Monitor 3.0
http://blogs.technet.com/netmon/archive/2006/10/17/into-to-filtering-with-network-monitor-3-0.aspx
작성자 : Lai Go / 작성일자 : 2008.07.01
아파치 2.X 버전에서 mod_cband를 이용한 트래픽관리
mod_cband 이란?
Apache에서 개별홈페이지의 일hit수 제한 및 트래픽을 관리하기 위해 사용하는 모듈로서apache 2.x버전에서 사용할 수 있으며 apache를 Dos방식과 Static방식 중 어느 방식으로 설치했느냐에 따라 적재방법 또한 다릅니다. DOS방식의 mod_cband 모듈적재 및 설정 방법을 알아보도록 하겠습니다.
[주요기능]
Apache2용 가볍운 트래픽제한 모듈
* 사용자별 대역폭제한 기능
* 가상호스트별 대역폭 제한 기능
* 목적지별 대역폭 제한 기능
* 제한기능:
o 모든사용자 대역폭 제한
o 다운로드 속제 제한
o 초당요청수 제한
o 아이피대역별 제한
* Support for virtualhosts
* Support for defined users
* 제한결과 웹을 통한 확인 (/cband-status)
* 각 사용자별 제한 결과 확인(/cband-status-me)
( 1 ) 다운로드
http://freshmeat.net/redir/mod_cband/60304/url_tgz/mod-cband-0.9.7.5.tgz
http://cband.linux.pl/downloads
리눅스 쉘 명령어
① tar zxvf mod-cband-0.9.7.5.tgz 파일을 다운로드 합니다.
wget은 웹에서 자동적으로 파일을 받아오는데 사용되는 유틸리티이며 HTTP, HTTPS, FTP 프로토콜을 지원합니다.
[root@nextline bin]# wget
http://freshmeat.net/redir/mod_cband/60304/url_tgz/mod-cband-0.9.7.5.tgz

( 2 ) 압축해제
[tar 명령어 옵션]
tar 명령어는 파일을 묶거나 풀 때 사용되는 리눅스 명령어 입니다.
c : tar 파일을 생성할 때 사용합니다.(여러 개의 파일을 하나의 파일로 묶을 때)
v : 묶을 때나 풀어줄 때 파일들의 내용을 자세하게 보여줍니다.
z : gzip과 관련하여 압축이나 해제를 한꺼번에 하려고 할 때 사용합니다.
x : 주어진 이름의 파일에 대하여 추출합니다.
사용법 : tar [옵션] 파일명
리눅스 쉘 명령어
① 다운로드된 mod-cband-0.9.7.5.tgz 파일의 압축을 해제 합니다.
[root@nextline bin]# tar zxvf mod-cband-0.9.7.5.tgz

( 3 ) 컴파일
리눅스 쉘 명령어
① 압축 해제한 mod-cband-0.9.7.5 디렉토리로 이동 합니다.
[root@nextline bin]# cd mod-cband-0.9.7.5
② ./configure 명령을 실행합니다.
./configure 명령은 프로그램을 설치하기 위해 환경설정을 하는 것으로 ./configure 후Makefile파일이 생성됩니다. 모듈을 적재하기 위해 컴파일을 합니다.
[root@nextline mod_throttle-3.1.2]# ./configure

( 4 ) make
리눅스 쉘 명령어
① make 명령을 실행합니다.
make 명령은 대상 디렉토리의 Makefile이라는 이름을 가지고 있는 파일을 보고, 거기에 설정되어 있는 컴파일 명령을 shell을 통해서 실행하는 명령입니다. ./configure 작업에 의해 생성된 Makefile을 참조하게 되며 소스코드를 실제로 컴파일해서 bibary 파일을 생성합니다.
[root@nextline mod_throttle-3.1.2]# make

( 5 ) make install
① make install 명령을 실행합니다.
make 명령에 의해 생성된 binary 파일을 지정된 디렉토리로 이동시켜주며 실제 프로 그램 설치 작업이 이루어집니다.
[root@nextline mod_throttle-3.1.2]# make install

( 6 ) mod_cband.so 파일생성 확인
① ls 명령어를 이용하여 아파치 모듈들이 위치한 modules 디렉토리에 mod_cband.so 파일이 생성 되었는지 확인합니다.
[root@nextline mod-cband-0.9.7.5]# ls /usr/local/apache/modules/

( 7 ) 모듈적재 확인
[vi 에디터 사용법]
사용형식 : vi [옵션] [생성할 파일명/편집할 파일명]
vi 에디터는 입력모드, 명령모드, 실행모드로 구분됩니다.
입력모드 : vi 편집화면에서 문자를 입력할 수 있는 모드로서 입력모드로 진입하기 위해서는 i, a, o, I, A, O, R등이 있습니다. 즉 초기 vi 편집기 모드는 명령어 모드로 진입을 하기때문에 문자를 입력하기 전에 앞의 단축키중 하나를 먼저 입력해야 원하는 문자를 입력할 수 있습니다.
명령모드 : 커서이동/문자삭제/문자(열)교체/문자열검색 등을 할수 있는 모드로서 입력모드에서 편집이 완료되면 Esc키를 눌러 명령모드로 진입하면 됩니다.
실행모드 : 특별한 명령어를 실행하는 모드로서 명령어모드에서 ":"(콜론)를 누르면 vi 화면 하단 좌측에 vi 특수명령어를 입력할 수 있습니다.
실행모드의 일반적으로 쓰이는 특수 명령어
q : 수정 작업이 이루어지지 않은 상태에서 vi 편집기에서 빠져나옵니다.
q! : 수정 작업이 이루어진 부분을 적용시키지 않고 vi 편집기를 강제로 빠져나옵니다.
w : 수정된 작업을 저장합니다.
wq : 수정된 작업을 저장하고 vi 편집기에서 빠져나옵니다.
초기 명령어모드 -> 입력모드진입 -> 편집 -> 명령어모드 -> 실행모드 -> 종료
① httpd.conf파일에 모듈이 등록되었는지 확인합니다.
[root@nextline mod-cband-0.9.7.5]# vi /usr/local/apache/conf/httpd.conf
LoadModule cband_module libexec/mod_cband.so

( 8 ) httpd.conf파일의 메인 환경설정
메인 설정 부분은 가상호스트에도 공통으로 적용되는 설정으로 mod_cband 모듈을 적용시키기 위해 아파치 환경 설정파일인 httpd.conf을 수정합니다.
① vi 에디터를 이용하여 httpd.conf파일을 엽니다.
[root@nextline mod-cband-0.9.7.5]# vi /usr/local/apache/conf/httpd.conf
② 아파치에 cband 모듈을 적용시키기 위해 다음 라인을 추가 합니다.
<IfModule mod_cband.c>
<Location /cband-status>
SetHandler cband-status
</Location>
<Location /cband-status-me>
SetHandler cband-status-me
</Location>
<Location /~*/cband-status-me>
SetHandler cband-status-me
</Location>
<Location /cband-status>
Order deny,allow
Deny from all
Allow from all
</Location>
</IfModule>

③ 트래픽 관리자모드 접근 ip설정
<Location /cband-status>
Order deny,allow
Deny from all
Allow from all
</Location>
위 설정은 throttle로 분석된 일hit 및 일 트래픽 제한에 대하여 상황페이지를 볼 관리자페이지에 대한 접속제한 설정입니다. 즉 관리자PC 한곳에서만 분석된 결과페이지를 볼 수 있도록 하려면 아래와 같이 수정합니다.
관리자 PC 아이피 : XXX.XXX.XXX.XXX
<Location /cband-status>
Order deny,allow
Deny from all
Allow from XXX.XXX.XXX.XXX
</Location>
( 9 ) 가상호스트 환경설정
개별 홈페이지 트래픽 현황 및 관리를 하기 위해서는 httpd.conf <Virtual Hosts>부분에 홈페이지 별로 설정을 하여야 합니다.
nextline.co.kr 도메인에 하루에 300M(300*1024*1024byte)의트래픽을 제공하는 설정입니다. bit로 따지면, 2.4Gbit/일 트래픽을 제공하는 것입니다. 만약 하루에 300M를 초과했다면, 503 에러 페이지가 뜨게 됩니다.
① nextline.co.kr 도메인을 가진 가상호스트를 추가 하도록 하겠습니다.
<VirtualHost xxx.xxx.xxx.xxx>
DocumentRoot /home/nextline/public_html
Servername nextline.co.kr
ServerAlias www.nextline.co.kr
CBandLimit 300Mi
CBandPeriod 1D
</VirtualHost>
② httpd.conf 설정 후 적용시키기 위해 apache를 재 시작 시켜 줍니다.
[root@nextline mod-cband-0.9.7.5]# /usr/local/apache/bin/apachectl restart
( 10 ) 서버전체 cband 상황보기 (관리자모드)
일hit수 일전송량의 제한을 웹브라우즈로 확인하기 위하여 다음과 같은 URL로 확인하도록 하겠습니다. 먼저 서버전체의 제한사항을 관리자가 확인하기 위한 예입니다.
cband 페이지는 기본 15초마다 리플레쉬 합니다.
① 주도메인이 nextline.co.kr로 설정된 예입니다.
확인하는 방법 :http://IP주소/cband-status
② 개별사이트 cband 상황보기 (사용자모드)
확인하는 방법 : http://nextline.co.kr/cband-status-me
( 11 )지시자 및 단위설명
단위
전송속도 단위
kbps, Mbps, Gbps - bits per second:1024, 1024*1024 , 1024*1024*1024 bps
kb/s, Mb/s, Gb/s - bytes persecond: 1024, 1024*1024, 1024*1024*1024 b/s
기본 : kbps
트래픽 쿼터 단위
K, M, G - bytes: 1000, 1000*1000,1000*1000*1000 bytes
Ki, Mi, Gi - bytes: 1024, 1024*1024,1024*1024*1024 bytes
기본 : K
시간(기간) 단위
S, M, H, D, W - 초, 분, 시간, 일, 주
기본 : S
지시자들
이름 : CBandDefaultExceededURL
설명 : 제한을 초과했을때보여줄 URL (지정하지 않으면, 503 에러 페이지)
문맥 : Serverconfig
문법 :CBandDefaultExceededURL URL
이름 : CBandDefaultExceededCode
설명 : 제한을 초과했을시 보여줄 에러코드
문맥 : Server config
문법 :CBandDefaultExceededCode HTTP_CODE
예제 :CBandDefaultExceededCode 509
이름 : CBandScoreFlushPeriod
설명 : scoreboard 파일에기록할 요청수, mod_cband 의 성능에 영향을 준다.
기본값 : 1
문맥 : Server config
문법 :CBandScoreFlushPeriod 요청수
예제 :CBandScoreFlushPeriod 100 (매 100번의 요청에 한번씩 scoreboard 파일에 기록)
이름 : CBandSpeed
설명 : 가상호스트 도메인의 최대 속도,요청수, 접속수 설정
문맥 :<Virtualhost>
문법 : CBandSpeed kbpsrps max_conn
kbps - 초당 최대 전송속도
rps - 초당 최대 요청수
max_conn - 최대 동시 접속수
예제 : CBandSpeed 102410 30
최대 1024kbps전송속도로 제한, 초당 10개의 요청 처리, 동시 접속을 30개로 제한.
이름 : CBandRemoteSpeed
설명 : 접속자(IP)의 최대속도, 요청수, 접속수 제한 (접속자당 설정)
문맥 :<Virtualhost>
문법 : CBandRemoteSpeedkbps rps max_conn
kbps - 초당 최대 전송속도
rps - 초당최대 요청수
max_conn - 최대 동시 접속수
예제 : CBandRemoteSpeed20kb/s 3 3
접속자(ip)에대해 최대 20kb/s , 초당 3개의 요청, 동시 접속 3개로 제한.
이름 : CBandClassRemoteSpeed
설명 : 정의한 class(ip 범위)에대해 최대속도, 요청수, 접속수 제한
문맥 :<Virtualhost>
문법 :CBandClassRemoteSpeed class_name kbps rps
class_name - 이미 정의한 클래스 이름 (IP범위)
kbps - 초당 최대 전송속도
rps - 초당 최대 요청수
max_conn - 최대 동시 접속수
예제 : <CBandClassgooglebot_class>
CBandClassDst 66.249.64/24
CBandClassDst 66.249.65/24
CBandClassDst 66.249.79/24
</CBandClass>
CBandClassRemoteSpeedgooglebot_class 20kb/s 2 3
위에서 정의한클래스(googlebot_class)의 요청에는 20kb/s 의 전송속도,
초당 3개의 요청, 동시 접속 3개로 제한.
이름 : CBandRandomPulse
설명 : 속도 제한을 위해서 임의의파형을 생성한 다음 처리하는 mod_cband의 처리 방법이다. 부하가 많을 때는 자동 Off된다.
문맥 : Global
문법 : CBandRandomPulseOn/Off
이름 : CBandLimit
설명 : 제한할 전송량을 설정한다.(기간은 CBandPeriod 에서 설정)
문맥 :<Virtualhost>
문법 : CBandLimit limit
limit - 전송량, 사용단위: K (kilo), M (mega), G (giga), Ki (kibi), Mi (mebi),Gi (gibi)
예제 : CBandLimit 10M
전송양을 10M(10*1000*1000bytes)로 제한한다.
CBandLimit 10Mi
전송양을 10M(10*1024*1024bytes)로 제한한다.
이름 : CBandClassLimit
설명 : 정의한 class(ip범위)에대해 제한할 전송량 설정.
문맥 :<Virtualhost>
문법 : CBandClassLimitclass_name limit
class_name - 이미 정의한 클래스 이름(ip범위)
limit - 전송량, 사용단위: K (kilo), M (mega), G (giga), Ki (kibi), Mi (mebi),Gi (gibi)
이름 : CBandExceededURL
설명 : 제한을 초과했을시 보여줄URL, 지정하지 않으면 503 에러 발생
문맥 :<Virtualhost>
문법 : CBandExceededURLURL
이름 : CBandExceededSpeed
설명 : 전송양을 초과했을시 , 전송속도제한 설정.
문맥 :<Virtualhost>
문법 :CBandExceededSpeed kbps rps max_conn
kbps - 초당 최대 전송속도
rps - 초당 최대 요청수
max_conn - 최대 동시 접속수
이름 : CBandScoreboard
설명 : 가상호스트의 scoreboard파일 지정. (성능향상을 위해 필요)
문맥 :<Virtualhost>
문법 : CBandScoreboardpath
(path는 아파치(nobody또는 apache)권한으로 쓰기 가능해야 함)
이름 : CBandPeriod
설명 : 용량제한기간(이 기간이 지나면,측정되었던 용량은 지워진다.)
문맥 :<Virtualhost>
문법 : CBandPeriod period
period - 사용단위: S (초), M (분), H (시간), D (일), W (주)
예제 : CBandPeriod1W (1주일)
CBandPeriod 14D (14일)
CBandPeriod 60M (60분)
이름 : CBandPeriodSlice
설명 : 기간이 길때는 나눌 기간을명시한다.
기본값 : slice_len = limit
문맥 :<Virtualhost>
문법 : CBandPeriodSliceslice_length
예제 : CBandLimit 100G
CBandPeriod 4W
CBandPeriodSlice 1W
4주는 1주일 단위로 나뉜다(4W/1W = 4). 용량은 100G/4=25G
1주에 25G, 2주째 50G 이렇게 나눠 처리 된다.
이름 : <CBandUser>
설명 : 새로운 cband 가상 사용자설정
문맥 : Server config
문법 : <CBandUseruser_name>
이름 : CBandUserSpeed
설명 : cband 가상 사용자의 속도,요청수, 동시 접속수 제한
문맥 : <CBandUser>
문법 : CBandUserSpeedkbps rps max_conn
kbps - 초당 최대 전송속도
rps - 초당 최대 요청수
max_conn - 최대 동시 접속수
예제 : CBandUserSpeed100kb/s 10 5
이름 : CBandUserLimit
설명 : cband 가상 사용자의 저송용량 제한.
문맥 : <CBandUser>
문법 : CBandUserLimitlimit
limit - 사용용량, 사용단위: K (kilo), M (mega), G (giga), Ki (kibi), Mi (mebi),Gi (gibi)
예제 : CBandUserLimit 10M
CBandUserLimit 10Mi
이름 : CBandUserClassLimit
설명 : cband 가상 사용자의 정의한class(ip범위)에 대해 제한할 전송량 설정
문맥 : <CBandUser>
문법 :CBandUserClassLimit class_name limit
class_name - 지정한 class(IP범위)이름
limit -사용용량, 사용단위: K (kilo), M (mega), G (giga), Ki (kibi), Mi (mebi),Gi (gibi)
이름 : CBandUserExceededURL
설명 : cband 가상 사용자의,제한을 초과했을시 보여줄 URL,
지정하지 않으면 503 에러 발생 ( 가상호스트에서 )
문맥 : <CBandUser>
문법 :CBandUserExceededURL URL
이름 : CBandUserExceededSpeed
설명 : cband 가상 사용자의,전송양을 초과했을시 , 전송속도 제한 설정.
문맥 : <CBandUser>
문법 : CBandUserExceededSpeed kbps rps max_conn
kbps - 초당 최대 전송속도
rps - 초당 최대 요청수
max_conn - 최대 동시 접속수
이름 : CBandUserScoreboard
설명 : cband 가상 사용자의,scoreboard 파일 지정.
문맥 : <CBandUser>
문법 : CBandUserScoreboard path
(path는 아파치(nobody또는 apache)권한으로 쓰기가능해야 함)
이름 : CBandUserPeriod
설명 : cband 가상 사용자의, 용량제한기간(기간이 지나면, 측정되었던 용량은 지워진다.)
문맥 : <CBandUser>
문법 : CBandUserPeriodperiod
period - 사용단위: S (초), M (분), H (시간), D (일), W (주)
예제 : CBandUserPeriod 1W
CBandUserPeriod 14D
CBandUserPeriod 60M
이름 : CBandUserPeriodSlice
설명 : cband 가상 사용자의,기간을 나눌 기간 명시
기본값 : slice_len = limit
문맥 : <CBandUser>
문법 :CBandUserPeriodSlice slice_length
예제 : CBandUserLimit100G
CBandUserPeriod 4W
CBandUserPeriodSlice 1W
4주는 1주일 단위로 나뉜다(4W/1W = 4). 용량은 100G/4=25G
1주에 25G, 2주째 50G 이렇게 나눠 처리 된다.
( 12 ) 개별홈페이지 cband 정책 적용 예
① 자료실 속도제한
nextline.net 도메인에 대해서 속도를 1024kbps로 제한하며, 초당 10번의 연결, 동
시 접속자를 30으로 제한하는 예제입니다.
<VirtualHost xxx.xxx.xxx.xxx>
DocumentRoot /home/nextline1/public_html
Servername nextline.net
ServerAlias www.nextline.net
CBandSpeed 1024 10 30
CBandRemoteSpeed 20kb/s 3 30
</VirtualHost>

확인하는 방법 : http://nextline.net/cband-status-me 
② 사용자 일트래픽 제공 및 초과시 연결수 제한 nextline.com 도메인에 대해 하루에 100Mbyte의 트레픽을 제공하며, 100M를 초가했다면, 속도를 128bps로 제한, 초당 5번의 연결, 동시접속자를 15로 제한하는 예제입니다.
<VirtualHost xxx.xxx.xxx.xxx>
DocumentRoot /home/nextline2/public_html
Servername nextline.com
ServerAlias www.nextline.com
CBandLimit 100Mi
CBandExceededSpeed 128 5 15
CBandPeriod 1D
</VirtualHost>

확인하는 방법 : http://nextline.com/cband-status-me
( 13 ) 그 외 적용 예를 들어보겠습니다.
① 한 사용자에 여러 도메인을 운영할 때 입니다.
위 설정은 nextline이라는 가상 사용자를 지%E
준비물:
utra edit - 에디터 프로그램입니다. hex에디트까지 가능하게 해줍니다.
qpst - 꼭 qpst가 아니여도 좋습니다. 핸드폰에 파일을 다운로드, 업로드만 가능하게 해주면 됩니다.
공학계산기 - 윈도우의 계산기나 손에 들고 있는 계산기면 OK. 윈도우의 계산기일경우 보기->공학용 을 찾아서 클릭해주시면 됩니다.
1. 이론
hex란 무엇인가?
hex란 hexagonal 의 단축형으로써 16진법이라는 뜻입니다. 우리들이 흔히 쓰는 10진수는 decimal, 2진수는 binary, 8진수는 octal 이라고 표시합니다. 간단하게 축약해서 16진수-hex, 10진수-dec, 2진수는 bin, 8진수는 oct 입니다.10진수는 0부터 9까지 가 1의 자리를 나타내며, 9에서 1이 더해지는순간 십의 자리에는 1이 일의 자리에는 0이 오는 10이 됩니다. 2진수는 0과 1 뿐입니다. 1에서 1이 더해지는순간 십의 자리에 1이 오고 일의 자리에 0이 와서 10이 됩니다. 즉 0(0), 1(1), 10(2) 입니다. 괄호안은 10진수로 읽었을때입니다. 8진수도 0부터 8까지로 이루어져있습니다. 마지막으로 16진수는 0부터 F까지 이루어져 있습니다. 이는 0,1,2,3,4,5,6,7,8,9,A(10),B(11),C(12),D(13),E(14),F(15)로 이루어져 있는 것입니다. 즉 9라는 숫자에서 1이 더해져도 십의 자리에 1이 오지않고 A가 됩니다. 이후로 B, C, D, E, F로 넘어가서 F에서 1이 더해지는순간 십의 자리에 1이 오고 일의 자리에 0이 와서 10이라는 숫자가 됩니다. 컴퓨터에 데이터가 저장될때에는 2진수와 16진수로 저장이 됩니다. 우리가 2진수는 123라는 숫자를 입력하게 되면 1111011이라는 숫자로 저장이됩니다. 16진수의 경우에는 7B라는 숫자로 저장이 됩니다. 하지만 2진수는 컴퓨터가 빠르게 이해는 할지몰라도 사람이 보고 읽고 이해하기엔(이를 가독성이라고 합니다) 너무 어렵죠. 그때문에 16진수코드를 쓰게 되는겁니다.
게임에서 hex조작은 어떻게 하나?
파일을 hex코드로 열어서 해당관련 숫자를 찾아서 숫자를 바꾸어주시면됩니다. 엉뚱한 코드를 손을 대셨다가 게임이 엉망이 되는 경우도 많으니 조심하셔야합니다. 이제 실습에 들어가보겠습니다.
일단 QPST로 접속을 합니다. 그리고 원하는 게임폴더로 찾아갑니다. 저의 경우에는 제일 만만한 판타지포에버2를 예로 들겠습니다. (참고로 저는 SKT통신사며 쓰이는 핸드폰은 MS500입니다.)
게임이 저장된 forever0.db 파일을 다운받습니다.
만약 ultra edit가 hex로 열지 못한다면 편집->hex기능을 찾아서 클릭해주시면 됩니다.
그리고 게임에 접속해서 케릭터의 골드, 레벨, 경험치, 스킬포인트, 찍은 스킬 등등을 공책이나 컴퓨터의 메모장에다가 잘 적어둡니다.
저의 경우 골드가 15032216골드 입니다. 약 1500만골드군요. 이미 이전에 손을 써두었기에 저런 골드가 가능해졌습니다.
자 15032216이라는 숫자를 계산기에 입력을 합니다. 그리고 이상태로 Hex를 클릭해보세요.
E55F98이라는 숫자로 바뀝니다. 앞으로 숫자는 2개씩 끊어서 보기로 합시다.
E5 5F 98 입니다. 이숫자를 잘 기억해두었다가, 아까 ultra edit로 연 forever0.db파일에서 맞는 숫자를 찾아봅니다.
아! 찾았군요! E5 5F 98 잘보입니다. 이 숫자를 FF FF FF 로 변경하시면 금액이 변경됩니다. FFFFFF라는 숫자는 10진수로 16777215입니다. 즉 약 1600만골드입니다.
이번엔 케릭터의 레벨을 찾아가봅시다. 저의 경우 케릭터의 레벨은 81입니다. 81이라는 dec숫자를 계산기로 통해서 hex로 바꾸면 51이라는 숫자가 됩니다. 이또한 찾아봅시다.
아! 또 찾았군요! 이 숫자를 FF로 바꾸시면 255레벨로 바뀝니다. 하지만 일반적인 게임들이 보통 99레벨이 끝인것을 감안해봐서 99레벨로 바꾸기로 합시다. 99라는 dec숫자를 hex로 바꾸어보면 63입니다. 아까 찾은 51이라는 숫자 대신 63을 바꾸어 적습니다.
그리고 파일을 저장해서 다시 qpst로 핸드폰으로 저장합니다.
그리고 게임을 실행해보시면??
와우!! 놀랍네요. 전부적용이 되어있습니다. 이제 레벨노가다와 골드노가다는 안해도 되겠군요.
기타 제가 찾아서 쓰고 있는 주소들은
골드:0번 b,c,d라인
레벨: 1번 - 200번 4
2번 - 240번 7
3번 - 280번 a
스킬 : 1번 - 230 0 부터 240 0 까지
2번 - 270 3 부터 280 3 까지
3번 - 2b0 6 부터 2c0 6
exp : 200 a b
240 d e
290 0 1
스킬포인트 : 240 5
280 8
2c0 b
입니다.
위에 제가 적은것을 보는방법은 간단합니다. hex코드에서 왼쪽 끝을 보시면 해당 00000000h 라는 주소들과 위에는 0부터 f까지 주소가 있습니다. 이것을 찾아서 보시면 됩니다. 예를 들어 골드의 경우 00000000h의 주소의 b,c,d라인에 있다는 소리입니다.
이것으로 간단한 hex조작을 해보았습니다. 여러분들도 쉽게 하실수 있기를 기대하겠습니다. 만약 내용이 어렵다면 댓글을 주시면 빠르게 확인해서 답을 드리겠습니다
PE 파일이 어떤 컴파일러로 컴파일되었고,어떤 패킹 되었는지 알수있게 하는 프로그램입니다.
본 프로그램은 사용에 아무런 제한이 없는 프리웨어입니다.
EXE, DLL, SFX 등의 PE 파일을 분석해서 사용한 압축기, 암호화기, 컴파일러 정보를 표시하는 프로그램입니다. PE 파일 내의 470 개 이상의 서로 다른 기호들을 감지할 수 있습니다.
파일분석, 어셈블링, 디어셈블링 등을 하는 분들께 필요합니다.

본 프로그램은 사용에 아무런 제한이 없는 프리웨어입니다.
사용자PC에 설치되어 있는 프로그램에 대한 정보를 제공하고 사용자에게 설치된 프로그램의 용도 및 삭제 방법등을
제공합니다.
앞으로 더욱 더 양질의 리뷰를 제공할 예정입니다.
시작프로그램 관리기능
애니그레이를 통해서 사용자컴퓨터의 시작프로그램관리에 등제된 프로그램을 삭제 또는 관리하실수 있습니다.
사용자의 시작프로그램에 설치되어 있는 프로그램에 대해 애니그레이에 의뢰함으로서 시작프로그램에 등제된 프로그램에 대한 정보를 얻으실수 있습니다.
현재 실행중인 프로세스가 종료가 안될경우 애니그레이를 통해서 종료하실수 있습니다.
사용자가 애니그레이를 사용한 흔적을 히스토리를 통해서 확인하실수 있습니다.
애니그레이를 사용하기위한 기본지식을 얻으실수 있습니다
백신치료프로그램과는 개념이 다르며, 잘모르고 무턱대고 삭제되는 프로그램이나 사용자를 불편하게 하는 프로그램에 대한 정보를 제공하여, 사용자 스스로가 판단하고 삭제 또는 예방을 하도록 유도하는 프로그램입니다.
최소한 사용자PC의 레지스터리나 기타 시스템관련 파일을 거의 건드리지 않으며, 프로그램자체가 사용자가 편안하게 사용할수 있는 프로그램입니다.
앞으로 더욱더 연구하여 100% 프리웨어인만큼 사용자에게 유익한 프로그램이 되도록 연구개발하겠습니다.
다운로드 받은 파일을 실행하여 순서에 따라 설치 하시면 됩니다.
 AG_Setup_d.exe
AG_Setup_d.exe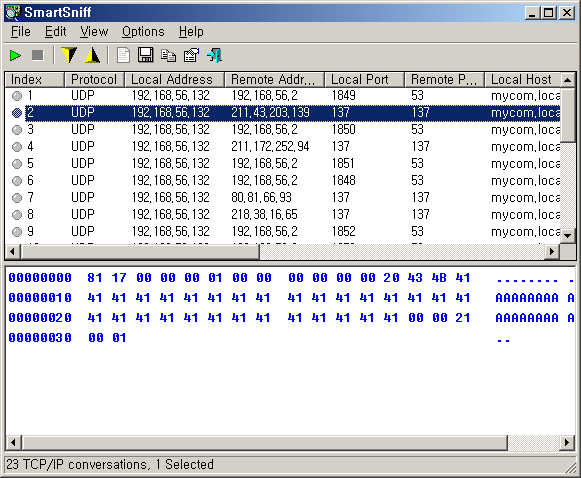
| |
|












- Java를 이용해 Rich Ajax 애플리케이션을 제작할 수 있는 오픈 소스 프레임워크.
- JavaScript/HTML 코드를 자동으로 생성해 냄.
- 모든 종류의 브라우저를 지원함.
- Pure JavaScript/DHTML at the client side.
- Pure Java at the server side.
2. GWT를 써야 하는 이유?
- No need to learn/use JavaScript language -> Leverage existing Java skills.
- No need to handle browser incompatibilities -> GWT handles them for you.
- No need to learn/use DOM APIs -> Use pure Java APIs.
- No need to handle forward/backward buttons -> GWT handles this for you.
- No need to build commonly used widgets -> GWT provides most of them.
3. GWT의 단점
- Java 1.4 버전까지만 지원.
- GWT로 자동 생성된 HTML과 JavaScript 코드는 꽤 무거움.
- Hosted 모드에서는 실행 속도가 느림.
- 다양한 Widget을 제공하지 않음.
- 동기식(Synchronization) RPC(Remote Procedure Call)를 지원하지 않음.
- Modal 대화창 개발에는 적합하지 않음.
- 클라이언트는 client 폴더의 하위 폴더에만 접근할 수 있음.
- 쓸만한 무료 UI 디자이너 툴을 제공하지 않음.
- 한글 처리 문제.
* 출처
- http://www.ibm.com/developerworks/kr/library/os-ad-gwt1/index.html
- http://www.ibm.com/developerworks/kr/library/os-ad-gwt2/index.html
- http://www.ibm.com/developerworks/kr/library/os-ad-gwt3/index.html
- http://www.devbg.org/seminars/seminar-GWT-26-september-2007/AJAX-Applications-with-Google-Web-Toolkit-Nakov-v1.0.pdf
- http://blog.dev.daewoobrenic.co.kr/tc/jcfblog/entry/Google-Web-ToolkiGWT-%EB%8B%A8%EC%A0%90-%EB%B0%8F-%EC%B0%B8%EC%A1%B0-%EB%A7%81%ED%81%AC
- http://factorystories.springnote.com/pages/1089916
- http://naucika.tistory.com/15
출처 : http://chocodonut.tistory.com/248
Google Web Toolkit, Apache Derby, Eclipse를 사용하여 Ajax 애플리케이션 구현하기, Part 1: 환상적인 프론트엔드 (한글)자바 프레임웍에서 Ajax 애플리케이션 구현을 위한 Google Web Toolkit |
난이도 : 중급 Noel Rappin, Senior Software Engineer, Motorola, Inc. 2007 년 2 월 06 일 Google Web Toolkit (GWT)은 동적 Java™Script의 생성에 혁신을 가져왔습니다. GWT를 사용하면, 개발자들은 익숙한 자바 기술을 사용하여 사용자 인터페이스(UI)와 이벤트 모델을 디자인하고 대다수의 브라우저에 익숙한 코드를 만드는 일을 하게 됩니다. 이 글을 통해, GWT의 기초를 설명하고, GWT에서 Asynchronous JavaScript + XML (Ajax) 애플리케이션을 만드는 방법과, 자바 언어로 코드를 작성하는 방법을 설명합니다. 또한 온라인에서 피자를 판매하는 Slicr라고 하는 Web 2.0 비즈니스 샘플을 가지고, GWT 애플리케이션을 생성 및 실행하는 방법을 설명합니다. GWT를 사용하여, 전통적인 자바 GUI 인터페이스를 구현하는 것 보다 훨씬 더 쉽게, 더욱 풍부한 Ajax 브라우저 클라이언트 인터페이스를 구현할 수 있다. GWT가 매우 놀랍기는 하지만, 전체 웹 애플리케이션을 이것 하나로 만들 수는 없다. 서버에 데이터 스토어가 있어야 하고, 데이터를 자바 객체로 변환하여, GWT가 서버에서 클라이언트로 전달할 수 있도록 하는 프레임웍이 있어야 한다. 본 기술자료 시리즈에서, 100% 순수 자바 데이터베이스인 Apache Derby를 사용하는 방법을 설명한다. 이 글에서는 GWT에 대한 중점적인 설명과 더불어, GWT를 설정하는 방법과 사용자 액션에 반응하는 간단한 클라이언트 인터페이스를 구현하는 방법을 설명한다. 후속 기술자료에서는 Derby 데이터베이스를 설치하고, GWT 프론트엔드를 Derby 기반 백엔드에 연결하는 방법을 설명한다. 마지막으로, 개발 환경 밖에서 시스템을 전개하는 방법도 배운다.
GWT를 사용하여, 자바 프로그래밍 언어로 Ajax 애플리케이션을 개발할 수 있다. Ajax 애플리케이션의 장점은 전통적인 UI 애플리케이션과 연결되는 풍부한 인터랙티브 환경일 것이다. 그림 1은 샘플 GWT 인터페이스로서 데스크탑 이메일 애플리케이션이다. 이 데모는 GWT 웹 사이트에서 볼 수 있다. 그림 1. GWT 이메일 데모  GWT의 가장 고유한 기능은 Ajax 애플리케이션을 만들 수 있고, 자바 언어로 코드를 작성할 수 있다는 점이다. 선호하는 자바 통합 개발 환경(IDE)을 사용하여, 클라이언트를 디버깅 할 수도 있다. 자바 객체를 사용하여 클라이언트와 서버간 통신도 가능하고, 모든 것이 자바 애플릿 보다 가볍다. GWT는 기본적으로 컴파일러이다. GWT는 자바 코드를 HTML 페이지에 삽입되어 실행될 수 있는 JavaScript 코드로 변환하여 클라이언트 측 애플리케이션을 실행하는데 사용된다. JavaScript 코드는 거의 모든 브라우저에서 지원되므로 여러분은 프로그램의 인터페이스와 인터랙션에 집중할 수 있다. 물론, GWT가 컴파일러일 뿐이라면, 거론하지 않았을 것이다. 다행히도, 그 이상의 기능을 한다. GWT는 컴파일러 메커니즘 뿐 만 아니라, 아래와 같은 부가적인 특징이 있다.
본 시리즈에서는 이러한 기능들을 설명할 것이다. 하지만 먼저, GWT를 다운로드 및 설치해야 한다. 이 글을 쓰고 있는 현재, GWT 최신 버전은 1.2이다. (참고자료) GWT는 Microsoft® Windows® XP, Windows 2000, Linux® 그리고, Mac OS X에서 실행되는 GTK+ 2.2.1 또는 그 이후 버전에서 완벽히 지원된다. 다운로드 한 압축 파일을 원하는 디렉토리에 압축을 푼다. 버전들마다 약간 다르지만, 기본 엘리먼트는 다음과 같다.
GWT를 사용할 때, 일부 파일들은 임시 파일들을 관리하기 위해 GWT 홈 디렉토리에 놓인다. 다운로드를 마치면, 가장 먼저 프로젝트를 만들어야 한다. 온라인에서 피자를 파는, Slicr라고 하는 새로운 Web 2.0 비즈니스의 온라인 사이트를 구축할 것이다. GWT 프로젝트를 설정하는 방법들은 IDE를 사용할 것인지의 여부에 따라 다르다. 여기에서는 GWT 명령행 유틸리티의 지원도 받는 무료 Eclipse를 사용하도록 하자. 명령행 유틸리티를 사용하여 Eclipse 프로젝트를 만든다.
<GWT_HOME>/projectCreator -eclipse slicr 이 명령어로는 GWT 프로젝트에 필요한 최소한의 것만 만든다. 새로운 src 하위 디렉토리와 새로운 .project와 .classpath 파일이 생겼다. 지금 바로 프로젝트로 시작할 수 있지만, GWT는 그 이상의 구조를 기대한다. 다음 명령어를 사용하여 설정할 수 있다. <GWT_HOME>/applicationCreator -eclipse slicr com.ibm.examples.client.Slicr
이 명령어는 몇 가지 파일을 생성한다. .java 파일은 메인 클래스이고, 해당 클래스에 동반된 패키지 명에 부합되게 부모 디렉토리 들이 생성된다. 여러분은 최하위 디렉토리에는 client와 public이 생성되어 있는 것을 확인 할 수 있다. 앞에서 거론한 public 디렉토리에는 Slicr.html와 Slicr.gwt.xml을 확인 할 수 있다. 또한, GWT는 eclipse가 사용하게 될 Slicr.launch파일과 두 개의 셀 스크립트 파일을 생성 한다.
이제 프로젝트를 Eclipse로 옮긴다.
이 프로세스를 통해, 코드를 Eclipse로 옮겨서 볼 수 있다. GWT는 세 개의 중요한 파일들을 만들었다. 첫 번째가 Listing 1. slicr.gwt.xml
여기에서 GWT 애플리케이션에 대한 모듈을 정의할 수 있다. 모듈(module)은 GWT 코드의 기본 단위이고, 클라이언트가 사용하는 HTML 페이지가 참조한다. 두 번째 파일은 퍼블릭 디렉토리에서 만들어진 Slicr.html 파일이다. 이것은 웹 애플리케이션의 프론트 페이지로서 클라이언트로 보내지는 .html 파일이다. 실제로 필요하지 않는 많은 코멘트들이 들어있다. Listing 2는 파일의 핵심 부분이다. Listing 2. Slicr.html
가장 중요한 것은 바로 위의 .html 파일이다. 원하는 어떤 HTML이라도 추가할 수 있다. 가장 중요한 것은 HTML 파일에 원하는 어떤 내용이라도 추가 및 변형 할 수 있다는 것이다. 단지, GWT는 아래 네 가지 엘리먼트에 의해서 실행된다.
GWT는 재사용이 가능한(boilerplate) 자바 시작 클래스도 Listing 3과 같이 만든다. Listing 3. 자바 시작 클래스
위의 자바 클래스는 위의 코드는 단순하다고 할 수 있다. 처음 두 라인에 버튼과 레이블을 정의한다. 그 다음 두 라인에서는, 위의 코드 라인들 사이에 Swing에서와 같이 이벤트를 묶는데 사용하는 것과 비슷한 방식을 사용하여 이벤트 리스너(eventListner)를 정의한다. 위의 경우, 버튼을 클릭하면
GWT가 만든 샘플 프로그램을 실행해 보자. GWT 프로그램을 실행하는 두 가지 방법이 있다. 바로 웹 모드(Web mode)와 호스트 모드(hosted mode)이다. 웹 모드는 완전한 전개 모드로서, GWT 프로그램을 JavaScript 코드로 컴파일 한 후에 실행한다. 호스트 모드는 개발하는 동안 사용된다. 호스트 모드란, 클라이언트와 서버 코드를 한번에 시뮬레이트 하면서, 개발하는 동안 전개를 단순화 시키는 일종의 에뮬레이터이다. (호스트 모드는 Mac OS X에서는 불가능하다.) 디버거와 함께 IDE를 사용한다면, 호스트 모드에서 GWT 프로그램을 실행할 수 있으며, JavaScript로 컴파일 될 코드 부분에서 중단점(breakpoint)을 지정하고 그의 변수(variable)의 변경사항을 알아낼 수 있다. 이러한 부분은 개발 시 매우 유용하며, GWT로 작업하게 되면, 대부분 호스트 모드를 사용하게 된다. 또한, 여러 가지 방법들로 호스트 모드를 실행할 수 있다. 이전에 실행했던 그림 2. 호스트 모드 호출하기  호스트 모드에서 실행할 때, 두 개의 창이 나타난다. (처음 실행할 경우, 호스트 모드 설정이 초기화되는 동안 1분여의 시간이 걸린다.) 그림 3에서 보이는 첫 번째 창의 이름은 Google Web Toolkit Development Shell / Port 8888.이다. 여기에는 GWT의 에러와 로그 메시지들이 들어있다. 툴바를 사용하여, 새로운 호스트 브라우저를 열 수 있고, 스크린상의 로그를 확장, 축소, 삭제할 수 있다. 그림 3. 호스트 모드 쉘 윈도우  그림 4에 보이는 두 번째 창은 브라우저 모습이다. 보다시피, slicr.html 페이지에서 생성된 정적 HTML과 Slicr.java EntryPoint 클래스에서 생성된 버튼 위젯이 있다. 버튼을 클릭하면 레이블이 선택된다. 설정 단계에서 오류가 있었다면, 이 창을 볼 수 없고 대신 쉘에 에러 메시지가 나타난다. 모든 이름들이 정확한지를 확인하라. (특히, .launch 파일에서, 정확한 프로젝트 디렉토리가 지정되었는지를 확인한다.) 그림 4. 호스트 모드 브라우저  이 글에서는 스크린상에서 위젯을 실행시키는 것에 초점을 맞추겠다. 그림 5에 보이는 스크린은 매우 단순해 보이지만, 꽤나 기능적이다. 그림 5. Slicr  페이지가 로딩될 때 이러한 위젯들을 생성시키려면, Listing 4. 모듈 로드 이벤트 핸들러
Listing 5. 메인 패널 초기화 하기
Listing 6. SOUTH (buttons) 패널
GWT pizza type 의 패널은 Listing 7과 같이 복잡하지 않다. GWT Listing 7. WEST (pizza types) 패널
HTML을 실행하는 레이블인 EAST 패널 (toppings) 만들기 topping 패널은 Listing 8처럼 좀더 복잡하다. 사용자가 다양한 토핑을 가진 피자를 만들 수 있도록 해야 한다. 토핑 버튼을 클릭하면 두 쪽 모두 체크되지만, 한 쪽만 체크되거나, 개별적으로 삭제될 수 있다. 모든 것의 줄을 맞춰야 하기 때문에 Grid를 사용한다. Listing 8. 토핑 그리드
위젯을 설정했다면, 두 개의 정의된 리스너를 보자. 두 개 중 더 단순한 것이 Clear 버튼에 대한 것이다. Listing 9와 같이 이 버튼은 Listing 9. Clear 버튼에 정의된 리스너
주: GWT에서, 토핑 버튼용 리스너는 더 복잡하다. 제휴 체크 박스들 중 어떤 것도 선택되지 않으면, 이 리스너는 두 개의 체크 박스 모두를 선택한다. 다른 상황에서는, 두 가지 모두를 지운다. Listing 10은 그 예이다. Listing 10. 버튼에 정의된 리스너
이번 글에서는 slicr 클라이언트를 구현해 보았다. 다음 글에서는 Derby 데이터베이스를 사용하여 서버 측에서 데이터 레이어를 구현하고, 데이터베이스에서 온 데이터를 GWT 클라이언트로 보내질 수 있는 자바 객체들로 변환하는 방법을 설명하겠다. 서버와 클라이언트를 연결하는 원격 프로시저 아키텍처도 설명한다. 서버 측이 개별적으로 실행되어야 한다면, 개발 및 실행 환경에 이를 전개하는 방법을 고려해야 한다. 또한, 인터페이스를 보기 좋은 모양으로 만드는 방법도 배울 것이다. 그 전에 GWT 다운로드 사이트에 가서 직접 실행해 보기 바란다. 교육
제품 및 기술 얻기
토론
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
개발자가 놓치기 쉬운 자바의 기본원리
- 전성호(커뮤니티본부 커뮤니티개발1팀), 2006년 10월
목차
-
- 1 객체지향의 구멍 static
- 2 Java는 Pointer언어이다? (Java에는 Pointer밖에 없다?)
- 3 상속과 interface의 문제점
- 4 package와 access 제어에 관한 이해
- 5 기타 Java 기능
- 6 이래도 Java가 간단한가?
- 7 Java 기능 적용 몇가지
- 8 Java 5.0 Tiger 에 대하여
-
- 8.1 Working with java.util.Arrays
- 8.2 Using java.util.Queue interface
- 8.3 java.lang.StringBuilder 사용하기
- 8.4 Using Type-Safe Lists
- 8.5 Writing Generic Types
- 8.6 새로운 static final enum
- 8.7 Using java.util.EnumMap
- 8.8 Using java.util.EnumSet
- 8.9 Convert Primitives to Wrapper Types
- 8.10 Method Overload resolution in AutoBoxing
- 8.11 가변적인 argument 개수 ...
- 8.12 The Three Standard Annotation
- 8.13 Creating Custom Annotation Types
- 8.2 Using java.util.Queue interface
- 8.1 Working with java.util.Arrays
- 9 The for/in Statement
-
- 9.1 for/in 의 자주 사용되는 형태
- 10 Static Import
-
- 10.1 static member/method import
- 11 References
1.1 Java는 객체지향 언어이다? #
- 오해1. "객체지향에서는 객체끼리 서로 메세지를 주고 받으며 동작한다." 라는 말을 듣고 다음과 같이 생각할 수 있다. "객체지향에서는 객체가 각각 독립하여 움직인다는 것인가, 그러면 각 객체에 독립된 thread가 할당되어 있단 말인가?" 그렇지 않다. "메세지를 보낸다"라는 것은 단순히 각 객체의 함수 호출에 불과하다.
- 오해2. "객체지향에서는 method가 class에 부속되어 있다"는 말을 듣고 다음과 같이 생각할 수 있다. "그러면 instance별로 method의 실행코드가 복제되고 있는 것이 아닌가?" 물론 이것도 오해다. method의 실행코드는 종래의 함수와 동일한 어딘가 다른곳(JVM의 class area)에 존재하며 그 첫번째 파라미터로 객체의 포인터 this가 건네질 뿐이다.
- 오해3. "그렇다면 각 instance가 method의 실행코드를 통째로 갖고 있지 않는 것은 확실하지만, method의 실행 코드의 포인터는 각 instance별로 보관하고 있는것이 아닌가?" 이것은 약가 애매한 오해이긴 하다. JVM 스펙에서는 class영역에 실행코드를 갖고 있으며, method 호출시 별도의 stack frame이 생성되어 실행되고 실행 완료시 복귀 주소를 전달한다.
1.2 전역변수 #
- (참고) final 초기화에서의 주의점. 예를 들어 다음과 같은 코드를 보았을때 우려되는 점은 무엇인가?
public final static Color WHITE = new Color(255, 255, 255);
- static field는 final의 경우와 달리 정말 "하나여도 되는지" 여부를 잘 생각해야 한다.
- static method는 주저하지 말고 쓰되 다음 두가지의 경우 매우 활용적이다.
- 다른 많은 클래스에서 사용하는 Utility Method 군을 만드는 경우. (주로 Utility Class의 method)
- 클래스 안에서만 사용하는 "하청 메소드(private method)". 이유를 예를 들어 설명하면, 아래와 같은 조금은 과장된 클래스가 있다고 하자.
public class T .. private int a; private int b; private int c; private int calc(){ c = a + b; return c * c; } ....other method or getter/setter... private static int calc(int a, int b){ int c = a + b; return c * c; }2.1 Java는 primitive형을 제외하곤 모두 Pointer이다 #
2.2 null은 객체인가? #
- null object의 instance method 호출
- null object의 field(member variables)에 대한 액세스 또는 그 값의 변경
- null의 길이를 배열처럼 취득할 경우
- null의 slot을 배열처럼 액세스 또는 수정
- null을 Throwable처럼 throw 할 경우
2.3 String에 대하여 #
String str = "111222"; String a = "111"; String b = "222"; String c = "111"; String d = b; String t = str.substring(0,3); //111
- str == (a + b) ==> 이것은 두개의 참조와 하나의 참조를 비교했으므로 당연히 false이다.
- a == b ==> 이것은 당연히 false
- d == b ==> 이것은 동일한 reference이므로 true
- a == t ==> a 와 t 는 둘다 값이 "111"이다. 하지만 이것은 서로 다른 참조를 가져 false이다. 그렇다면 다음 5번도 false일까?
- a == c ==> 이것은 true이다. 아.. 4번과 혼란스럽다. 이것이 참인 이유는? ==> 이것의 해답은 JSR 3.10.5에 다음과 같이 나와 있기 때문이다.
2.4 객체지향의 캡슐화 파괴 주의 #
//(참고)Member에는 두개의 field(Identity Class 형의 ID와 Family Class 형의 family)가 있다. /** shallow copy */ Member shallowCopy(){ Member newer = new Member(); newer.id = this.id; newer.family = this.family; return newer; } /** deep copy */ Member deepCopy(){ Member newer = new Member(); newer.id = new Idetity(this.id.getId(), this.id.getName()); newer.family = new Family(this.family.getFamilyName(), this.family.getFamilyInfo()); return newer; } - 모든 field(member variable)를 생성자(constructor)를 이용하여 초기화 한다.
- 모든 field는 private으로 선언하고, getter method는 만들되 setter는 기술하지 않는다.
2.5.1 배열은 object 인가? #
2.5.2 배열의 length는 왜 field(member variable)인가? #
2.5.3 final과 배열에 대하여... #
2.5.4 "Java에서의 다차원 배열은 존재하지 않는다." #
2.6.1 "Java에서 parameter(argument) 전달은 무조건 'call by value' 이다" #
2.6.2 "C와 같은 언어는 static linking이지만, Java는 dynamic linking이다." #
2.7.1 "Garbage Collection은 만능이 아니다." #
2.8.1 "결국 Java에는 pointer가 있는 것인가, 없는 것인가?" #
// 이부분에 대해 Object를 이해하시면 족히 이런 문제는 사라질것으로 봅니다.
// 클래스에 대한 인스턴스(object)들은 reference로 밖에 가질(참조될)수 없기 때문입니다.
// 컴파일러 입장이 아닌 언어 자체의 사상을 가지고 쉽게 이해시키는 것이 좋을것 같습니다.
3.1.1 상속에 있어서의 생성자(constructor) #
3.1.2 "down cast는 본질적으로 매우 위험하다" #
3.1.3 "추상클래스에 final이 있으면 compile error이다" #
3.2.1 "interface는 interface일뿐 다중 상속의 대용품이 아니다." #
3.3 상속 제대로 사용하기 #
- 상속에서는 슈퍼클래스가 허용하고 있는 조작을 서브클래스에서 모두 허용해야 하지만, composition과 delegation에서는 조작을 제한할 수 있다.
- 클래스는 결코 변경할 수 없지만, composition하고 있는 객체는 자유롭게 변경할 수 있다. 예를 들면 학생 클래스가 영원이 학생이 아니라 나중에 취직을 하여 직장인 클래스가 될수 있다.
- Shape(부모)의 공통된 내용을 구현한 구현 클래스(ShapeImpl)를 만든다.
- Polyline과 Circle 클래스에서 ShapeImpl을 composition하고 부모와 공통되지 않는 method를 각각 위임 받는다.
- ShapeImpl 클래스의 method를 추출한 ShapeIF interface를 작성하고 Polyline과 Circle에서는 implements 한다.
4.1.1 "package는 '계층구조' 인가?" #
4.1.2 "compiler 가 인식하는 class검색 순서(소스코드내 클래스가 발견될 경우 그 클래스의 위치를 찾는 순서)" #
- 그 class자신
- 단일형식으로 임포트된 class
- 동일한 패키지에 존재하는 다른 class
- 온디멘드 형식(..* 형태) 임포트 선언된 class
4.2.1 "interfacde member의 access 제어" #
4.2.2 그렇다면 interface를 다른 package에 대하여 숨기고 싶으면 어떻게 하는가? #
5.1.1 "Multi Thread에서는 흐름은 복수이지만 data는 공유될 수 있다." #
5.1.2 "Thread는 객체와 직교하는 개념이다." #
- Multi Thread에서는 Thread라는 처리 흐름이 2개 이상 존재할 수 있다.
- 어떤 Thread에서 움직이기 시작한 method가 다른 method를 호출 했을때 호출된 측의 method는 호출한 측의 method와 동일한 Thread에서 동작한다.
- Thread의 경계와 객체의 경계는 전혀 관계가 없다. 즉, Thread와 객체는 직교하고 있다.
5.1.3 "Synchronized 의 이해" #
synchronized void method1(){ ... } void method2(){ synchronized(this){ ... } }5.1.4 "Thread 사용법의 정석은?" #
- Runnable을 implements하고 Thread의 참조를 보유(composition) 하는 방법. 이경우는 단지 Runnable만 implement함으로서 해결되는 경우가 대부분이긴 하지만, 그 class 내에서 해당 class의 Thread를 조작하게 된다면 composition한 Thread 객체에 delegation하면 된기 때문이다.
- Thread class를 상속하는 방법. JDK의 소스를 보면 Thread class에는 Runnable을 implements 하고 있다. 그리고 run method는 native method이다. 따라서 Thread를 상속한 모든 클래스는 사실 Runnable을 implements하고 있는 것이다. run method는 abstract가 아니므로 구현되어 있고 우리는 이를 오버라이드하여 사용하고 있다. 이 방식을 사용하면 Thread의 method를 안팍으로 자유롭게 호출할 수 이지만, 이미 다른 class를 상속하고 있다면 이 방식을 사용할 수는 없다.
5.2.1 "finally 절은 반드시 어떠한 경우에도 실행되는가?" #
try{ ... System.exit(1); }catch(...){ }finally{ ... //이 부분은 실행되지 않는다. }
5.2.2.1 Error #
5.2.2.2 RuntimeException #
5.2.2.3 그밖의 Exception #
5.2.3 "OutOfMemoryError는 어떻게 처리해야 하는가?" #
5.3 Object Serialize #
5.3.1 "Serialize를 위해서는 marker interface인 java.io.Serializable interface를 implements해야한다." #
5.3.2 "super class는 Serializable이 아닌데 sub class만 Serializable인 경우의 문제점" #
5.3.3 "transient field의 복원(?)관련" #
private void writeObject(java.io.ObjectOutputStream out) throws IOException;private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
5.3.4 "Stack Overflow에 주의하라!" #
private synchronized void writeObject(java.io.ObjectOutputStream s) throws IOException { s.defaultWrtieObject(); //이 코드는 무조건 들어가게 되는데 이곳 소스의 System.arraycopy()에서 overflow발생한다. s.writeInt(size); //이부분이 실제 추가되어 Stack Overflow를 예방한다. for(Entry e = ...) s.writeObject(e.element); } ... } //readObject()도 이와 같은 개념으로 변경되어 있다.5.4.1 "중첩클래스의 개념" #
5.4.2 "내부클래스는 부모의 참조를 몰래 보유하고 있다." #
class Test{ class InnerClass { int i; ... } public static void main(String[] args){ InnerClass icls = new InnerClass(); ... } }5.4.3 "local inner class에 대하여" #
public class OuterClass { public int get(){ int i = 9; int id = 99; int id2 = 99; final int id3 = 100000; class LocalInnerClass { int id = 100; LocalInnerClass(){ System.out.println("LocalInnerClass"); } int getId(){ return id3 + id; } } LocalInnerClass lic = new LocalInnerClass(); return id + lic.getId(); } public static void main(String[] args){ OuterClass outer = new OuterClass(); System.out.println("id = " + outer.get()); //결과 값은 "100000(id3) + 100(LocalInnerClass.id) + 99(OuterClass.get())" 인 100199가 나온다. } }5.4.4 "anonymous class(무명클래스)에 대하여" #
class AnonymousTest { private interface Printable { void print(); } static void doPrint(Printable p){ p.print(); } public static void main(String[] args){ doPrint( new Printable(){ public void print(){ System.out.println("this is new Printable print()"); } }); } }6.1.1 "overload란 이름이 가고 인수가 다른 method에 compiler가 다른 이름을 붙이는 기능" #
//IFS.java interface IFS { public String getName(); } //Impl1.java class Impl1 implements IFS { public String getName(){ return "Impl1"; } } //Impl2.java class Impl2 implements IFS { public String getName(){ return "Impl2"; } } //main이 있는 OverloadTest.java public class OverloadTest { static void pr(int i){ System.out.println("pr_int : " + i); } static void pr(String s){ System.out.println("pr_string : " + s); } static void pr(IFS ifs){ System.out.println("pr_string : " + ifs.getName()); } static void pr_run(Impl1 i1){ System.out.println("pr_run : " + i1.getName()); } static void pr_run(Impl2 i2){ System.out.println("pr_run : " + i2.getName()); } public static void main(String[] args){ OverloadTest test = new OverloadTest(); test.pr(10); test.pr("Jeid"); IFS ifs1 = new Impl1(); test.pr(ifs1); IFS ifs2 = new Impl2(); test.pr(ifs2); //pr_run(ifs1); //pr_run(ifs2); } }OverloadTest.java:36: cannot resolve symbol symbol : method pr_run (IFS) location: class OverloadTest pr_run(ifs1); ^ OverloadTest.java:37: cannot resolve symbol symbol : method pr_run (IFS) location: class OverloadTest pr_run(ifs2); ^ 2 errors
6.1.2 "그렇다면 overload에서 실제로 혼동되는 부분은 무엇인가?" #
class OverloadTest2 { static int base(double a, double b){ ... } //method A static int count(int a, int b){ ... } //method B static int count(double a, double b){ ... } //method C static int sum(int a, double b){ ... } //method D static int sum(double a, int b){ ... } //method E }- base(3,4) 를 호출했을때 수행되는 method는? => 당연히 method A (3과 4는 정수라도 double이 되므로 정상적으로 수행됨)
- count(3,4) 를 호출했을때 수행되는 method는? => B와 C중 갈등이 생긴다. 이럴경우 JVM은 가장 한정적(more specific)한 method를 찾는다. 여기서 3과 4는 정수형에 가까우므로 method B 가 호출된다.
- count(3, 4.0) 을 호출했을때 수행되는 method는? => 이것은 4.0 이 double이므로 method C 가 더 한정적이므로 method C 가 호출된다.
- sum(3,4.0) 을 호출했을때 수행되는 method는? => 이것은 당연히 type이 일치하는 method D.
- sum(3,4) 를 호출했을때 수행되는 method는?? => 이런 코드가 소스내에 있으면 다음과 같은 compile 오류를 표출한다.
OverloadTest.java:48: reference to sum is ambiguous, both method sum(int,double) in OverloadTest and method sum(double,int) in OverloadTest match System.out.println("sum(3,4) = " + sum(3,4)); ^ 1 error6.1.3 (참고) 또다른 혼동, overload한 method를 override 하면? #
6.2.1 "Java class의 member 4 종류" #
- instance field
- instance method
- static field
- static method
6.2.2 "override시 method 이름에 대한 함정" #
6.2.3 "또다른 나의(?) 실수 - 말도 안되는 오타" #
public class Member { private int memberNo; public int getMemberNo(){ return this.memberNo; } public void setMemberNo(int menberNo){ this.memberNo = memberNo; } ...... }6.2.4 "static member를 instance를 경유하여 참조해서는 안 된다." #
ClassA a = new ClassA(); int i = a.AA; //instance를 경유하여 접근 int j = ClassA.AA; //올바르게 접근
6.2.5 "super keyword는 부모의 this" #
6.4.1 "생성자에 void 를 붙인다면?" #
public class ConstructorTest{ void ConstructorTest(){ System.out.println("Constuctor"); } ..... }6.4.2 "if / switch 의 함정" #
.... if( a < 5 ) b = 3; c = 10; //이부분은 나중에 추가된 라인이다. if( isStudent ) if( isFemale ) sayHello("Hi~~"); else sayHello("Hello Professor~");7.1.1 "interface 분리의 필요성" #
7.2 Java에서의 열거형 #
public static final int LEFT = 0; public static final int CENTER = 1; public static final int RIGHT = 2; ... label.setAlignment(Label.CENTER); ...
//LabelAlignment.java public class LabelAlignment { private LabelAlignment() {} //이는 생성자를 private으로 하여 다른데서는 만들지 못하도록 하기위함이다. public static final LabelAlignment LEFT = new LabelAlignment(): public static final LabelAlignment CENTER = new LabelAlignment(): public static final LabelAlignment RIGHT = new LabelAlignment(): } //변형된 Label.java 의 일부.. public synchronized void setAlignment(LabelAlignment alignment){ if( alignment == LabelAlignment.LEFT ){ ...//왼쪽으로 맞추기.. }else if( ... ... } } ... //LabelAlignment.java public class LabelAlignment { private int flag; private LabelAlignment(int flag){ this.flag = flag; } public static final LabelAlignment LEFT = new LabelAlignment(0): public static final LabelAlignment CENTER = new LabelAlignment(1): public static final LabelAlignment RIGHT = new LabelAlignment(2): public boolean equals(Object obj){ return ((LabelAlignment)obj).flag == this.flag; } } //변형된 Label.java 의 일부.. public synchronized void setAlignment(LabelAlignment alignment){ if( LabelAlignment.LEFT.equals(alignment) ){ ...//왼쪽으로 맞추기.. }else if( ... ... } } ...7.3 Debug write #
#ifdef DEBUG fprintf(stderr, "error...%d\n", error); #endif /* DEBUG */
if( Debug.isDebug ){ System.out.println("error..." + error); } // 1. GetCallerSecurityManager.java public final class GetCallerSecurityManager extends SecurityManager { public Class[] getStackTrace(){ return this.getClassContext(); } } // 2. GetCallerClass.java public final class GetCallerClass { private static GetCallerSecurityManager mgr; static{ mgr = new GetCallerSecurityManager(); System.setSecurityManager(mgr); } public static void writeCaller(String str){ Class[] stk = mgr.getStackTrace(); int size = stk.length; for(int i = 0; i < size; i++){ System.out.println("stk[" + i + "] = " + stk[i]); } String className = stk[2].getName(); System.out.println("className is " + className + " : " + str); } } // 3. GetCallerClassMain1 : 호출하는 클래스 예제 1 public class GetCallerClassMain1 { public static void main(String[] args){ GetCallerClass.writeCaller(", real is 1."); } } // 4. GetCallerClassMain1 : 호출하는 클래스 예제 2 public class GetCallerClassMain2 { public static void main(String[] args){ GetCallerClass.writeCaller(", real is 2."); } }className is GetCallerClassMain1 : , real is 1. className is GetCallerClassMain2 : , real is 2.
8.1 Working with java.util.Arrays #
package com.jeid.tiger;import java.util.Arrays;import java.util.Comparator;import java.util.List;public class ArraysTester { private int[] arr; private String[] strs; public ArraysTester(int size) { arr = new int[size]; strs = new String[size]; for (int i = 0; i < size; i++) { if (i < 10) { arr[i] = 100 + i; } else if (i < 20) { arr[i] = 1000 - i; } else { arr[i] = i; } strs[i] = "str" + arr[i]; } } public int[] getArr() { return this.arr; } public String[] getStrs() { return this.strs; } public static void main(String[] args) { int size = 50; ArraysTester tester = new ArraysTester(size); int[] testerArr = tester.getArr(); int[] cloneArr = tester.getArr().clone(); String[] testerStrs = tester.getStrs(); String[] cloneStrs = tester.getStrs().clone(); // clone test if (Arrays.equals(cloneArr, testerArr)) { System.out.println("clonse int array is same."); } else { System.out.println("clonse int array is NOT same."); } if (Arrays.equals(cloneStrs, testerStrs)) { System.out.println("clonse String array is same."); } else { System.out.println("clonse String array is NOT same."); } // 2부터 10까지 값 셋팅 Arrays.fill(cloneArr, 2, 10, new Double(Math.PI).intValue()); testerArr[10] = 98; testerStrs[10] = "corea"; testerStrs[11] = null; List<String> listTest = Arrays.asList(testerStrs); System.out.println("listTest[10] = " + listTest.get(10)); System.out.println("------- unsorted arr -------"); System.out.println("Arrays.toString(int[]) = " + Arrays.toString(testerArr)); System.out.println("Arrays.toString(String[]) = " + Arrays.toString(testerStrs)); Arrays.sort(testerArr); // Arrays.sort(testerStrs); //NullPointerException in sort method..(null이 없더라도 길이에 대한 크기 체크는 못함) Arrays.sort(testerStrs, new Comparator<String>() { public int compare(String s1, String s2) { if (s1 == null && s2 == null) { return 0; } else if (s1 == null && s2 != null) { return -1; } else if (s1 != null && s2 == null) { return 1; } else if (s1.length() < s2.length()) { return -1; } else if (s1.length() > s2.length()) { return 1; } else if (s1.length() == s2.length()) { return 0; } else { return s1.compareTo(s2); } } }); System.out.println("------- sorted arr -------"); System.out.println("Arrays.toString(int[]) = " + Arrays.toString(testerArr)); System.out.println("Arrays.toString(String[]) = " + Arrays.toString(testerStrs)); System.out.println("------------------------------------------------"); String[][] mstrs1 = { { "A", "B" }, { "C", "D" } }; String[][] mstrs2 = { { "a", "b" }, { "c", "d" } }; String[][] mstrs3 = { { "A", "B" }, { "C", "D" } }; System.out.println("Arrays.deepToString(mstrs1) = " + Arrays.deepToString(mstrs1)); System.out.println("Arrays.deepToString(mstrs2) = " + Arrays.deepToString(mstrs2)); System.out.println("Arrays.deepToString(mstrs3) = " + Arrays.deepToString(mstrs3)); if( Arrays.deepEquals(mstrs1, mstrs2)) { System.out.println("mstrs1 is same the mstrs2."); }else { System.out.println("mstrs1 is NOT same the mstrs2."); } if( Arrays.deepEquals(mstrs1, mstrs3)) { System.out.println("mstrs1 is same the mstrs3."); }else { System.out.println("mstrs1 is NOT same the mstrs3."); } System.out.println("mstrs1's hashCode = " + Arrays.deepHashCode(mstrs1)); System.out.println("mstrs2's hashCode = " + Arrays.deepHashCode(mstrs2)); System.out.println("mstrs3's hashCode = " + Arrays.deepHashCode(mstrs3)); }}8.2 Using java.util.Queue interface #
package com.jeid.tiger;import java.util.LinkedList;import java.util.PriorityQueue;import java.util.Queue;public class QueueTester { public static void main(String[] args) { System.out.println("---------- testFIFO ----------"); testFIFO(); System.out.println("---------- testOrdering ----------"); testOrdering(); } private static void testFIFO() { Queue<String> q = new LinkedList<String>(); q.add("First"); q.add("Second"); q.add("Third"); String str; while ((str = q.poll()) != null) { System.out.println(str); } } private static void testOrdering() { int size = 10; Queue<Integer> qi = new PriorityQueue<Integer>(size); Queue<String> qs = new PriorityQueue<String>(size); for (int i = 0; i < size; i++) { qi.offer(10 - i); qs.offer("str" + (10 - i)); } for (int i = 0; i < size; i++) { System.out.println("qi[" + i + "] = " + qi.poll() + ", qs[" + i + "] = " + qs.poll()); } }}8.3 java.lang.StringBuilder 사용하기 #
package com.jeid.tiger;import java.util.ArrayList;import java.util.Iterator;import java.util.List;public class StringBuilderTester { public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("str1"); list.add("str2"); list.add("str3"); String ret = appendItems(list); System.out.println("ret = " + ret); } private static String appendItems(List<String> list) { StringBuilder sb = new StringBuilder(); for (Iterator<String> iter = list.iterator(); iter.hasNext();) { sb.append(iter.next()).append(" "); } return sb.toString(); }}8.4 Using Type-Safe Lists #
package com.jeid.tiger;import java.util.Iterator;import java.util.LinkedList;import java.util.List;public class ListTester { public static void main(String[] args) { List<String> list = new LinkedList<String>(); list.add("str1"); list.add("str2"); list.add(new Integer(123)); // <-- String이 아니므로 compile error!! //Iterator에 String type을 명시하므로 정삭작동됨. for (Iterator<String> iter = list.iterator(); iter.hasNext();) { String str = iter.next(); System.out.println("srt = " + str); } //Iterator에 String type을 명시하지 않았으므로 아래 A 부분에서 compile 오류 발생!! for (Iterator iter = list.iterator(); iter.hasNext();) { String str = iter.next(); //A System.out.println("srt = " + str); } //byte, short, int, long, double, float 동시 사용 List<Number> lstNum = new LinkedList<Number>(); lstNum.add(1); lstNum.add(1.2); for (Iterator<Number> iter = lstNum.iterator(); iter.hasNext();) { Number num = iter.next(); System.out.println("num = " + num); } }}8.5 Writing Generic Types #
class AnyTypeList<T> {//class AnyTypeList<T extends Number> { // <-- 이는 Number를 상속한 type은 허용하겠다는 의미. private List<T> list; //private static List<T> list; // <-- 이는 정적이므로 compile error 발생!!! public AnyTypeList(){ list = new LinkedList<T>(); } public boolean isEmpty(){ return list == null || list.size() == 0; } public void add(T t){ list.add(t); } public T grap(){ if (!isEmpty() ) { return list.get(0); } else { return null; } }}8.6 새로운 static final enum #
package com.jeid.tiger;import com.jeid.BaseObject;import com.jeid.MyLevel;public class EnumTester extends BaseObject { private static long start = System.currentTimeMillis(); public static void main(String[] args) { try { test(); enum1(); } catch (Exception e) { e.printStackTrace(); } printEllapseTime(); } private static void test() throws Exception { byte[] b = new byte[0]; System.out.println(b.length); } private static void enum1() { //enum TestEnum { A, B }; //enum cannot be local!!! for(MyVO.TestEnum te: MyVO.TestEnum.values()){ System.out.println("Allow TestEnum value : " + te); } System.out.println("---------------------------------------"); MyVO vo = new MyVO(); vo.setName("enum1"); vo.setLevel(MyLevel.A); System.out.println(vo); System.out.println("isA = " + vo.isA() + ", isGradeA = " + vo.isLevelA()+ ", isValueOfA = " + vo.isValueOfA()); System.out.println("getLevelInKorean = " + vo.getLevelInKorean()); } private static void printEllapseTime() { System.out.println("==> ellapseTime is " + (System.currentTimeMillis() - start) + " ms."); }}package com.jeid.tiger;import com.jeid.BaseObject;import com.jeid.MyLevel;public class MyVO extends BaseObject { enum TestEnum { A, B }; // this is same public static final private int id; private String name; private MyLevel grade; // private List<T> list; public MyLevel getLevel() { return grade; } public void setLevel(MyLevel grade) { this.grade = grade; } public boolean isA() { return "A".equals(this.grade); } public boolean isValueOfA() { return MyLevel.valueOf("A").equals(grade); } public boolean isLevelA() { return MyLevel.A.equals(this.grade); } //A,B,C..대신 0,1,2... 도 동일함. public String getLevelInKorean() { switch(this.grade){ case A: return "수"; case B: return "우"; case C: return "미"; case D: return "양"; case E: return "가"; default: return "없음"; } } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; }}8.7 Using java.util.EnumMap #
package com.jeid.tiger;import java.util.EnumMap;public class EnumMapTester { private enum MyEnum { A, B, C }; // this is same the static final.. public static void main(String[] args) { MyEnum[] enums = MyEnum.values(); System.out.println("MyEnum is " + enums[0] + ", " + enums[1] + ", " + enums[2]); EnumMap<MyEnum, String> em = new EnumMap<MyEnum, String>(MyEnum.class); em.put(MyEnum.A, "수"); em.put(MyEnum.B, "우"); em.put(MyEnum.C, "미"); em.put(MyEnum.B, "가"); //key 중복은 HashMap과 동일하게 overwrite임. for (MyEnum myEnum : MyEnum.values()) { System.out.println(myEnum + " => " + em.get(myEnum)); } }}8.8 Using java.util.EnumSet #
package com.jeid.tiger;import java.util.EnumSet;public class EnumSetTester { private enum MyEnum { A, B, C, a, b, c }; // this is same the static final.. public static void main(String[] args) { MyEnum[] enums = MyEnum.values(); System.out.println("MyEnum is " + enums[0] + ", " + enums[1] + ", " + enums[2]); EnumSet<MyEnum> es1 = EnumSet.of(MyEnum.A, MyEnum.B, MyEnum.C); EnumSet<MyEnum> es2 = EnumSet.of(MyEnum.a, MyEnum.b, MyEnum.c); EnumSet<MyEnum> es3 = EnumSet.range(MyEnum.a, MyEnum.c); if (es2.equals(es3)) { System.out.println("e2 is same e3."); } for (MyEnum myEnum : MyEnum.values()) { System.out.println(myEnum + " contains => " + es1.contains(myEnum)); } }}8.9 Convert Primitives to Wrapper Types #
package com.jeid.tiger;public class AutoBoxingTester { public static void main(String[] args) { int i = 0; Integer ii = i; // boxing. JDK 1.4에서는 incompatible type error가 발생 했었으나 Tiger에서는 괜찮다. int j = ii; // unboxing for (ii = 0; ii < 5; ii++) { // Integer인데도 ++ 연산자 지원. } i = 129; ii = 129; if (ii == i) { System.out.println("i is same ii."); } // -128 ~ 127 사이의 수는 unboxing이 되어 == 연산이 허용되지만, // 그 범위 외의 경우 Integer로 boxing된 상태므로 equals를 이용해야함. // 이는 버그가 발생했을 경우 찾기 쉽지 않은 단점도 내포하고 있다.!! checkIntegerSame(127, 127); // same checkIntegerSame(128, 128); // Not same checkIntegerEquals(128, 128); // equals checkIntegerSame(-128, -128); // same checkIntegerSame(-129, -129); // Not same checkIntegerEquals(-129, -129); // equals System.out.println("--------------------------------------------"); Boolean arriving = false; Boolean late = true; String ret = arriving ? (late ? "도착했지만 늦었네요." : "제시간에 잘 도착했군요.") : (late ? "도착도 못하고 늦었군요." : "도착은 못했지만 늦진 않았군요."); System.out.println(ret); StringBuilder sb = new StringBuilder(); sb.append("appended String"); String str = "just String"; boolean mutable = true; CharSequence chSeq = mutable ? sb : str; System.out.println(chSeq); } private static void checkIntegerSame(Integer ii, Integer jj) { if (ii == jj) { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is same ii."); } else { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is NOT same ii!!"); } } private static void checkIntegerEquals(Integer ii, Integer jj) { if (ii.equals(jj)) { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is equals ii."); } else { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is NOT equals ii!!"); } }}8.10 Method Overload resolution in AutoBoxing #
package com.jeid.tiger;public class OverloadTester { public static void main(String[] args) { double d = 10; Integer ii = new Integer(10); doSomething(10); doSomething(1000); doSomething(ii); doSomething(d); } private static void doSomething(Integer ii) { System.out.println("This is doSomething(Integer)"); } private static void doSomething(double d) { System.out.println("This is doSomething(double)"); }}8.11 가변적인 argument 개수 ... #
package com.jeid.tiger;public class VarArgsTester { public static void main(String[] args) { setNumbers(1, 2); setNumbers(1, 2, 3, 4); setNumbers(1); // setNumbers(); //해당 되는 method가 없어 compile error!! System.out.println("=============================================="); setNumbers2(1, 2, 3, 4); setNumbers2(1); setNumbers2(); } // this is same setNumbers(int first, int[] others) private static void setNumbers(int first, int... others) { System.out.println("-----------setNumbers()----------- : " + first); for (int i : others) { System.out.println("i = " + i); } } // this is same setNumbers(int[] others) private static void setNumbers2(int... others) { System.out.println("-----------setNumbers2()----------- : " + (others != null && others.length > 0 ? others[0] : "null")); for (int i : others) { System.out.println("i = " + i); } }}8.12 The Three Standard Annotation #
//정상적인 사용 @Override public int hashCode(){ return toString().hashCode(); } //스펠링이 틀려 compile error!! @Override public int hasCode(){ //misspelled => method does not override a method from its superclass error!! return toString().hashCode(); }package com.jeid.tiger;public class AnnotationDeprecateTester { public static void main(String[] args){ DeprecatedClass dep = new DeprecatedTester(); dep.doSomething(10); //deprecated }}class DeprecatedClass { @Deprecated public void doSomething(int ii){ //deprecated System.out.println("This is DeprecatedClass's doSomething(int)"); } public void doSomethingElse(int ii){ System.out.println("This is DeprecatedClass's doSomethingElse(int)"); }}class DeprecatedTester extends DeprecatedClass { @Override public void doSomething(int ii){ System.out.println("This is DeprecatedTester's doSomething(int)"); }}package com.jeid.tiger;import java.util.ArrayList;import java.util.List;public class AnnotationSuppressWarningsTester { @SuppressWarnings({"unchecked", "fallthrough"} ) private static void test1(){ List list = new ArrayList(); list.add("aaaaaa"); } @SuppressWarnings("unchecked") private static void test2(){ List list = new ArrayList(); list.add("aaaaaa"); } //warning이 없는 소스. private static void test3(){ List<String> list = new ArrayList<String>(); list.add("aaaaaa"); }}8.13 Creating Custom Annotation Types #
package com.jeid.tiger;import java.lang.annotation.Documented;import java.lang.annotation.ElementType;import java.lang.annotation.Retention;import java.lang.annotation.RetentionPolicy;import java.lang.annotation.Target;@Documented@Target( { ElementType.TYPE, ElementType.FIELD, ElementType.METHOD, ElementType.ANNOTATION_TYPE })@Retention(RetentionPolicy.RUNTIME)public @interface MyAnnotation { String columnName(); String methodName() default "";}//사용하는 쪽..public class AnnotationTester { @MyAnnotation(columnName = "test", methodName = "setTest") private String test; @MyAnnotation(columnName = "grpid") public String grpid; ....}//위의 test 멤버의 경우 다음과 같이 접근 가능하다.Field testField = cls.getDeclaredField("test");if (testField.isAnnotationPresent(MyAnnotation.class)) { Annotatioin anno = testField.getAnnotation(MyAnnotation.class); System.out.println(anno.columnName() + ", method = " + anno.methodName());}9.1 for/in 의 자주 사용되는 형태 #
//1. 가장 단순한 형태인 배열(array)String[] strs = { "aaa", "bbb", "ccc" };for (String str : strs) { System.out.println(str);}//2. List by using IteratorList<Number> lstNum = new LinkedList<Number>();lstNum.add(1);lstNum.add(1.2);for (Iterator<Number> iter = lstNum.iterator(); iter.hasNext();) { Number num = iter.next(); System.out.println("num = " + num);}//3. List를 바로 사용List<String> lst = new LinkedList<String>();lst.add("aaaaa");lst.add("bbbbb");lst.add("ccccc");lst.add("ddddd");for (String str : lst) { System.out.println("str = " + str);}// 4. List of ListList[] lists = { lst, lst };for (List<String> l : lists) { for (String str : l) { System.out.println("str = " + str); }}10.1 static member/method import #
//예를 들어 System.out.println() 이라는 것을 사용하기 위해서는 다음의 import 문이 필요하다.import java.lang.System; //물론 java.lang 이기에 import 문이 필요없지만 예를 들자면 그렇다는 것이다.&^^//허나, Tiger에서는 다음과 같이 사용할수 있다.import static java.lang.System.out;...out.println(...);// method를 import 한다면..import static java.lang.System.out.println;...println(...);
11 References #
- http://java.sun.com/j2se/1.4.2/docs/index.html
- http://java.sun.com/j2se/1.5.0/docs/index.html
- SUN의 JLS
- http://java.sun.com/docs/books/jls/html/index.html
- Java 핵심원리 - 마에바시 가즈야 저 - 영진닷컴
- Java 1.5 Tiger - Brett McLaughlin 저 - O'Reilly
출처: http://dna.daum.net/technote/java/PrincipleOfJavaInternalForDeveloperEasyToLost
Welcome to Google Doctype. Written by web developers, for web developers.
What do you want to learn today?
Read HOWTO articles on
Dive into DOM objects, including
Style your pages with CSS
- CSS properties
- pseudo-classes and pseudo-elements
- at-rules
- colors
- ...and more on the way
Do you need help with an HTML element? We have an HTML reference from <a> to <xmp>.
